Flink的checkpoint是怎么实现的?
分析&回答
Checkpoint介绍
Checkpoint容错机制是Flink可靠性的基石,可以保证Flink集群在某个算子因为某些原因(如 异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保证应用流图状态的一致性。Flink的Checkpoint机制原理来自“Chandy-Lamport algorithm”算法。
Barriers
flink 分布式快照的核心元素是 stream barriers,这些barriers被注入到流中,并作为流的一部分,随着流流动。barriers将数据流的记录分为进入当前快照的记录和进入下一个快照的记录,每个barriers都携带了快照的ID,快照的数据在barriers的前面推送。barriers非常轻量级,不会中断流的流动。同一时间,会有多个checkpoint在并发进行。
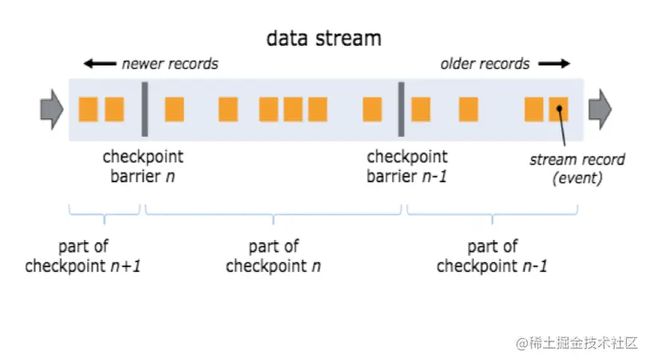
barrier被注入到并行流的数据源,注入快照n (称为Sn)的barriers 是数据源中个一个位置,在kafka 就是某个分区的最后一条记录的offset。这个位置Sn后续会汇报给JM的checkpoint coordinator(协调checkpoint功能)。 barrier随着流向下游流动,当中间的operator从他所有的输入流中收到checkpoint n 的barrier时,该operator会将barrier发送给他的下游operator。一旦到达DAG的末端,sink会将这条流的state handle汇报JM的checkpoint coordinator,当sink从他所有的输入流中接收到了checkpoint n barrier ,Jm 会返回一个completed checkpoint meta, 然后checkpoint 标记为完成,状态存储到相应的state backend中。
barrier 对齐

当一个opeator有多个输入流的时候,checkpoint barrier n 会进行对齐,就是已到达的会先缓存到buffer里等待其他未到达的,一旦所有流都到达,则会向下游广播,exactly-once 就是利用这一特性实现的,at least once 因为不会进行对齐,就会导致有的数据被重复处理。
checkpoint 数据结构
当一个operator接收到所有上游发送的 checkpoint n barrier 向下游发送之前,会对状态进行一次快照,将offset state 等值保存起来,默认情况下是保存在Jm的内存中,由于可能会比较大,可以存在状态后端中,生成中建议放hdfs.

到最终checkpoint 快照的完整数据结构类似与一个表格,每个opeator经过处理后填写属于自己的那部分,最后会将其存到state backend中供failover时使用。
反思&扩展
Flink 的容错机制(checkpoint) 内部实现
每个需要Checkpoint的应用在启动时,Flink的JobManager为其创建一个 CheckpointCoordinator(检查点协调器),CheckpointCoordinator全权负责本应用的快照制作。
CheckpointCoordinator(检查点协调器),CheckpointCoordinator全权负责本应用的快照制作。

CheckpointCoordinator(检查点协调器) 周期性的向该流应用的所有source算子发送 barrier(屏障)。
当某个source算子收到一个barrier时,便暂停数据处理过程,然后将自己的当前状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自己快照制作情况,同时向自身所有下游算子广播该barrier,恢复数据处理
下游算子收到barrier之后,会暂停自己的数据处理过程,然后将自身的相关状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自身快照情况,同时向自身所有下游算子广播该barrier,恢复数据处理。
每个算子按照步骤3不断制作快照并向下游广播,直到最后barrier传递到sink算子,快照制作完成。
当CheckpointCoordinator收到所有算子的报告之后,认为该周期的快照制作成功; 否则,如果在规定的时间内没有收到所有算子的报告,则认为本周期快照制作失败。
RocksDB实现增量checkpoint原理:
state backend中提供了一种RocksDb存储checkpoint ,它是Flink提供的唯一可以实现增量checkpoint的方法。原理是每次生成checkpoint是会生成sst文件(不会再修改了),会和之前的文件进行对比,每次上传新增的sst文件即可,大概就是这样。
喵呜面试助手:一站式解决面试问题,你可以搜索微信小程序 [喵呜面试助手] 或关注 [喵呜刷题] -> 面试助手 免费刷题。如有好的面试知识或技巧期待您的共享!