GO如何编写一个 Worker Pool
作者:JustLorain
https://juejin.cn/post/7244733519948333111
前言
池化技术是一种资源管理技术,它通过提前创建和维护一组可重用的资源实例池,以便在需要时快速分配和回收这些资源。协程(goroutine)是 Go 语言中一种更加轻量级的 “线程”,然而大量的 goroutine 还是非常消耗资源的。Worker Pool 通过池化技术可以维护一定数量的 goroutine,只让这些 goroutine 去执行任务,减少了资源的浪费。
本文将通过介绍 Worker Pool 的一种实现思路并通过分析一个常用的 Worker Pool 的源码 gammazero/workerpool( https://github.com/gammazero/workerpool ) 并在最后自己实现一个类似的 Worker Pool VIOLIN( https://github.com/B1NARY-GR0UP/violin ) 来帮助更好的了解 Worker Pool。
如何编写一个 Worker Pool?
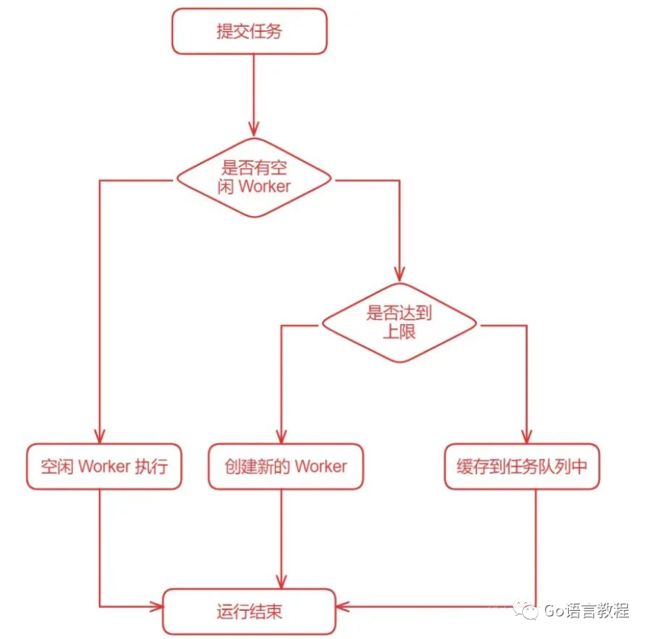
通过前言中对 Worker Pool 的简单介绍,我们知道了要实现一个 Worker Pool 就只需要维护一定数量的 goroutine 并由这些 goroutine 去处理提交的任务(task / job)的即可。于是 Worker Pool 的编写思路就变得非常简单了:
-
为 Worker Pool 设置一个具体的 goroutine 数量上限,Worker Pool 维护的 goroutine 的值不能超出这个值;
-
提交一个任务时从 Worker Pool 中分配一个 goroutine 去执行
-
如果有空闲 Worker(goroutine)就交给空闲 Worker 执行,否则查看是否达到设置的 goroutine 数量上限
-
达到上限就将任务缓存到一个队列中(或者其他处理方式),没有达到上限就创建一个新的 Worker 去执行
具体的逻辑可以查看以下示意图,何时消费缓存队列中的任务会在源码解析部分讲解。
源码分析
大概理清了 Worker Pool 的工作思路我们就可以开始写代码了,这里我们先阅读一个非常好用的 Worker Pool 的开源实现(GitHub 1.1k Star),项目地址:https://github.com/gammazero/workerpool。
主结构体 WorkerPool
我们先看一下这个 Worker Pool 的主结构体:
type WorkerPool struct {maxWorkers inttaskQueue chan func()workerQueue chan func()stoppedChan chan struct{}stopSignal chan struct{}waitingQueue deque.Deque[func()]stopLock sync.MutexstopOnce sync.Oncestopped boolwaiting int32wait bool}
我们重点关注以下几个属性:
-
maxWorkers:Worker Pool 所维护的最大 goroutine 数目(也就是 Worker 数);
-
taskQueue: 任务队列,提交任务时将任务提交到任务队列中;
-
workerQueue: Worker 队列,Worker 会从 Worker 队列中获取具体需要执行的任务;
-
waitingQueue: 等待队列,在没有空闲 Worker 并且当前 Worker 数达到设置的最大值时缓存待执行任务的队列;
需要注意的点为:
-
三个 Queue 中存储的具体元素的数据类型都为 func() ,也就是提交的任务的数据类型,理解为一个函数即可;
-
这里使用了 taskQueue 和 workerQueue 两个队列,提交的任务时先提交到 taskQueue 中,再从 taskQueue 中传入 workerQueue 给 Worker 去执行的,而不是直接让 Worker 消费 taskQueue 中的任务;
-
waitingQueue 的数据类型为 workerpool 作者自己实现的数据结构,当做一般的队列(FIFO)理解即可。后面我们自己实现的时候可以替换成现有的数据结构,比如 chan,list.List 等;
New
接下来我们来看一下 New 函数,也就是创建 WorkerPool 对象的函数。
func New(maxWorkers int) *WorkerPool {// There must be at least one worker.if maxWorkers < 1 {maxWorkers = 1}pool := &WorkerPool{maxWorkers: maxWorkers,taskQueue: make(chan func()),workerQueue: make(chan func()),stopSignal: make(chan struct{}),stoppedChan: make(chan struct{}),}// Start the task dispatcher.go pool.dispatch()return pool}
可以看到整体还是非常清晰的,开头的判断条件保证 WorkerPool 中至少维护一个 goroutine;然后初始化 WorkerPool 对象,需要注意的是 taskQueue 和 workerQueue 属性都为无缓冲的 channel;然后开启一个协程运行 WorkerPool 的核心方法 pool.dispatch ;最后返回 WorkerPool 对象。
Submit
在看核心方法 pool.dispatch 之前我们先来看几个简单的方法提高一下信心。
func (p *WorkerPool) Submit(task func()) {if task != nil {p.taskQueue <- task}}
Submit 就是我们用来提交任务需要调用的方法,直接判断不为 nil 后传入 taskQueue 即可。顺便码一下如果往 chan 中传 nil 的情况,虽然可以正常接收 nil 但是运行的话会报空指针异常。
func main() {ch := make(chan func())go func() {ch <- nil}()res, ok := <-chfmt.Println(res, ok) //true res() // panic: runtime error: invalid memory address or nil pointer dereference}
SubmitWait
Submit 的孪生方法,不同的是提交任务后会阻塞等待提交的任务执行完毕。
func (p *WorkerPool) SubmitWait(task func()) {if task == nil {return}doneChan := make(chan struct{})p.taskQueue <- func() {task()close(doneChan)}<-doneChan}具体实现是对提交的 task 包装一次通过再通过 channel 来实现,非常巧妙。
dispatch
WorkerPool 的核心方法,包含了前面分析的 Worker Pool 处理的完整流程。
这是一个非常长的方法,为了便于讲解和理解这里我先列出完整的方法然后接下来会逐个代码段的解释,读者可以自己 clone 这个项目对照的阅读也可以直接看下面的代码段解析。
func (p *WorkerPool) dispatch() {defer close(p.stoppedChan)timeout := time.NewTimer(idleTimeout)var workerCount intvar idle boolvar wg sync.WaitGroupLoop:for {// As long as tasks are in the waiting queue, incoming tasks are put// into the waiting queue and tasks to run are taken from the waiting// queue. Once the waiting queue is empty, then go back to submitting// incoming tasks directly to available workers.if p.waitingQueue.Len() != 0 {if !p.processWaitingQueue() {break Loop}continue}select {case task, ok := <-p.taskQueue:if !ok {break Loop}// Got a task to do.select {case p.workerQueue <- task:default:// Create a new worker, if not at max.if workerCount < p.maxWorkers {wg.Add(1)go worker(task, p.workerQueue, &wg)workerCount++} else {// Enqueue task to be executed by next available worker.p.waitingQueue.PushBack(task)atomic.StoreInt32(&p.waiting, int32(p.waitingQueue.Len()))}}idle = falsecase <-timeout.C:// Timed out waiting for work to arrive. Kill a ready worker if// pool has been idle for a whole timeout.if idle && workerCount > 0 {if p.killIdleWorker() {workerCount--}}idle = truetimeout.Reset(idleTimeout)}}// If instructed to wait, then run tasks that are already queued.if p.wait {p.runQueuedTasks()}// Stop all remaining workers as they become ready.for workerCount > 0 {p.workerQueue <- nilworkerCount--}wg.Wait()timeout.Stop()}
其实整个方法看下来还是非常清晰的,作者也很贴心的在主要的逻辑分支处补充了注释。
-
我们先来看这个方法开头的变量声明部分:
defer close(p.stoppedChan)timeout := time.NewTimer(idleTimeout)var workerCount intvar idle boolvar wg sync.WaitGroup-
timeout:WorkerPool 为维护的 Worker 设置了空闲超时时间,即如果一个空闲的 Worker 可以存活的最大时间,避免空闲的 Worker 一直占用系统资源,并且这个时间已经在内部声明死了,为 2 秒(2 * time.Second);
-
workerCount:用于记录当前运行的 Worker 数量,和配置的允许维护的最大 Worker 数量进行比对;
-
idle:超时标记位,初始为 false,如果有 Worker 超时置为 true,创建新 Worker 或将任务添加到缓存队列后置为 false;
-
wg:每创建一个新的 Worker 加 1,阻塞等待直到所有的 Worker 结束销毁。
-
-
方法接下来就是一个巨大的 for 循环,其中还有 select 的嵌套,我们先跳过对 waitingQueue 的判断逻辑,直接看主要的 select 部分:
LOOP:for {// ... (暂时跳过的部分)select {case task, ok := <-p.taskQueue:if !ok {break Loop}// Got a task to do.select {case p.workerQueue <- task:default:// Create a new worker, if not at max.if workerCount < p.maxWorkers {wg.Add(1)go worker(task, p.workerQueue, &wg)workerCount++} else {// Enqueue task to be executed by next available worker.p.waitingQueue.PushBack(task)atomic.StoreInt32(&p.waiting, int32(p.waitingQueue.Len()))}}idle = falsecase <-timeout.C:// Timed out waiting for work to arrive. Kill a ready worker if// pool has been idle for a whole timeout.if idle && workerCount > 0 {if p.killIdleWorker() {workerCount--}}idle = truetimeout.Reset(idleTimeout)}}// ...-
for 进来的第一个 select 的两个 case 一个为接收到任务,另一个为 Worker 超时即两秒种没有接收到新任务;
-
先看接收到任务的 case,首先判断是否实际接收到 task,如果 ok 为 false,说明 taskQueue 这个 channel 已经被 close 了,直接退出循环,这里使用 label 的原因是在 for-select 嵌套的 select 中,如果直接 break 只会退出当前的 select,继续执行 for 以内 select 以外的代码并继续下次 for 循环,不会直接退出外面的 for 循环,如果想退出外面的 for 循环,则需要借助 label 来实现。
然后再通过一个 select ,如果有空闲的 Worker 就将任务分配给他即 p.workerQueue <- task,否则判断当前运行的 Worker 数是否达到上限,没有的话就开启一个新的 goroutine 即 Worker,并把刚开始声明的 workerCount 和 sync.WaitGroup +1,dispatch 方法也不会有并发问题所以可以直接加。Worker 数量达到上限的话就将当前任务缓存到队列中,并保存当前的等待任务数。p.waiting 是共享资源所以需要通过原子操作来保证并发安全。
-
超时的 case 先判断 idle 为是否为 true 并且 Worker 数量大于 0,所以第一次超时不会去 kill 一个 Worker,只会把 idle 位置为 true 并且重置计时器,值得一提的是这里的 p.killIdleWorker 方法不一定会真正 kill 一个 Worker,只是去尝试做,并将结果返回,如果成功则将 Worker 数减一。
-
-
现在我们看刚刚跳过的部分,也就是 for 循环一进来:
if p.waitingQueue.Len() != 0 { if !p.processWaitingQueue() {break Loop}continue}这一部分就是对缓存的任务进行消费,p.processWaitingQueue 方法会消费一个缓存的任务或者将进来的新任务进行缓存。同样进行判断如果 taskQueue 被关闭了直接 break Loop 退出循环。
-
最后一部分是 for 循环外的收尾代码:
// If instructed to wait, then run tasks that are already queued.if p.wait {p.runQueuedTasks()}// Stop all remaining workers as they become ready.for workerCount > 0 {p.workerQueue <- nilworkerCount--}wg.Wait()timeout.Stop()这里的 p.wait 位是在 Stop 的时候使用的标记位我们可以先不用看,下面的就是停止所有的 Worker 并停止 timer。
worker
WorkerPool 通过 go worker(task, p.workerQueue, &wg) 开启一个新的 Worker,可以看到方法的形参为需要执行的 task,workerQueue 和 WaitGroup。在判断 task 不为 nil 后执行 task 并阻塞接收新的 task,直到收到的 task 为 nil 结束循环并将信号减一。非常巧妙,我自己写的话肯定想不到这种写法ww
// worker executes tasks and stops when it receives a nil task.func worker(task func(), workerQueue chan func(), wg *sync.WaitGroup) {for task != nil {task()task = <-workerQueue}wg.Done()}
以上就是对 workerpool 的核心源码解析,接下来我们可以自己实现一个 Worker Pool。
自己实现
VIOLIN是我参考 gammazero/workerpool 思路写的一个 Worker Pool,提供了更加丰富的 API 和选项,欢迎 Star :)
WorkerNum
WorkerNum 是 VIOLIN 提供的获取当前运行 Worker 数量的接口,将 Worker 的数量变为主结构体的一个属性进行维护而不是类似 workerpool 中将 workerCount 作为 dispatch 方法的一个局部变量;但相对的,需要使用原子操作来保证并发安全,所以会带来性能上的损耗。
type Violin struct {options *optionsmu sync.Mutexonce sync.OnceworkerNum uint32taskNum uint32waitingTaskNum uint32status uint32workerChan chan func()taskChan chan func()waitingChan chan func()dismissChan chan struct{}pauseChan chan struct{}shutdownChan chan struct{}}
Functional Options 模式
Functional Options 是我个人非常喜欢使用的一种编程模式,VIOLIN 通过 Functional Options 模式提供了三种配置选项并有对应的默认值,具体如下表所示:
| 选项 | 默认值 | 描述 |
|---|---|---|
| WithMaxWorkers | 5 | 设置 Worker 数量上限 |
| WithWaitingQueueSize | 64 | 设置任务缓存队列大小 |
| WithWorkerIdleTimeout | time.Second * 3 | 设置空闲 Worker 超时时间 |
-
可以看到相比 workerpool 设置死的 2 秒 Worker idleTimeout ,VIOLIN 允许用户自己进行配置;
-
并且 VIOLIN 将任务缓存队列的数据结构从队列换成了 Channel,所以需要用户设置 Channel 的大小或者直接使用默认值;后续应该也会换成队列实现,不再限制缓存队列的大小;
Status
VIOLIN 在主结构体维护 status 字段方便用户和内部获取 VIOLIN 所在的状态,一共有如下 4 个状态:
const (_ uint32 = iotastatusInitializedstatusPlayingstatusCleaningstatusShutdown)
-
statusInitialized:初始化
-
statusPlaying:正常运行
-
statusCleaning:调用 ShutdownWait 后等待缓存任务队列中的任务执行完
-
statusShutdown:Shutdown 关闭
用户可以通过提供的 IsPlaying,IsCleaning 和 IsShutdown 方法来判断 VIOLIN 的状态。
遇到的问题
以下是一个我在编写 VIOLIN 时遇到的问题,其实很多都是逻辑搞的复杂了然后自己脑测不过来,导致的很多并发或者流程问题;比如 send on closed channel,data race 等
if int(v.WorkerNum()) < v.MaxWorkerNum() {_ = atomic.AddUint32(&v.workerNum, 1)go v.recruit(wg)}
这是判断当前运行 Worker 数量小于设置的最大数量时就创建一个新的 Worker 的逻辑。初版的代码中通过原子操作将 workerNum 增加 1 的代码放在了 recruit 函数里,这就导致了有时候会出现实际运行的 Worker 数量超出最大值几倍的现象。找了半天后发现是这里的执行顺序问题。
解决方案就是判断逻辑后立刻增加值,否则因为循环的速度大于启动 goroutine 再在 recruit 函数里原子性 +1 的速度,导致一次相同的判断却创建多个 goroutine。
总结
以上就是本篇文章的所有内容了,我们从编写 Worker Pool 的思路出发,到阅读一个 Worker Pool 的开源实现再到自己实现一个 Worker Pool,希望可以对你理解和使用 Worker Pool 有所帮助。如果哪里写错了或者有问题欢迎评论
参考列表
-
https://github.com/gammazero/workerpool
-
https://github.com/B1NARY-GR0UP/violin