数据挖掘导论学习笔记(四)
第五章 分类:其他技术
基于规则的分类器:
每一个分类规则可以表示为如下形式:
ri: (条件i) ----> yi
规则: (条件i)
规则前件或前提:规则左边
规则后件:规则右边,包含预测类yi
分类规则的质量衡量 :
给定数据集D和分类规则 r:A---->y
(1)覆盖率:D中触发规则r的记录所占比例
(2)准群率或置信因子:触发r的记录中类标号等于y的记录所占比例。
基于规则的分类器的工作原理:
确保分类器能对记录做出可靠的预测,基于规则的分类器所产生的规则集的两个性质:
(1)互斥规则
如果规则集R中不存在两条规则被同一条记录触发,则称规则集R 中的规则是互斥的。
这个性质确保每条记录至多被R中一条规则覆盖。
(2)穷举规则
如果对属性值的任一组合,R中都存在一条规则加以覆盖,则称规则集R是穷举覆盖。
两条性质保证数据集中的每一条记录被切仅被一条记录覆盖。
如果规则集不是穷举,那么必须田建一个默认规则来覆盖未被覆盖的记录。前件为空,后件是默认类。
如果规则集不是互斥,那么一条记录可能被多个规则覆盖。解决办法:
(1)有序规则
规则表中规则按照优先级降序排列,优先级的定义有很多种方法(覆盖率,准确率等等)。
一个有序的规则集也称为一个决策表。
(2)无序规则
允许一条测试记录触发多条分类规则,把每条被触发规则的后件看做是对应类的一次投票,然后计票确定测试记录的类标号。
利弊:
(1)无序规则方法在分类一个测试记录时,不易受由于选择不当的规则而产生错误的影响。
(2)建立模型的开销也相对较小,因而不必维护规则的顺序。
(3)对测试记录分类是一件繁重的任务,因为测试记录的属性要与规则集中的每一条规则的前件作比较。
规则的排序方案:
(1)基于规则的排序方案
这个方案一句规则质量的某种度量对规则排序,这种阿脾虚方案确保每一个测试记录都是由覆盖他的“最好的”规则阿里分类。
(2)基于类的排序方案
属于同一个类的规则在规则集R中一起出现。
如何建立基于规则的分类器
需要提取一组规则来识别数据集的属性和类标号之间的关键联系。提取分类规则的方法有两大类:
(1)直接方法:直接从数据中提取分类规则
(2)间接方法:从其他分类模型(决策树和神经网络)中提取分类规则
规则提取的直接方法:
顺序覆盖算法经常被用来直接从数据中提取规则,规则基于某种评估度量以贪心的方式增长。
该算法从包含多个类的数据集中一次提取一个类的规则。
算法开始时,决策表R为空,接下来用函数Learn-One-Rule提取类y的覆盖当前训练记录集的最佳规则。
提取规则时,类y的所有训练记录被看做是正例,而其他类的训练记录则被当做反例。如果一个规则覆盖大多数正例,没有覆盖或极少覆盖反例,那么规则时可取的。
Learn-One-Rule函数
Learn-One-Rule函数的目标是提取一个分类规则,该规则覆盖大多数正例,没有覆盖或极少覆盖反例。然而,由于搜索空间呈指数大小,要找到最佳的规则计算开销很大。通过以一种贪心的方式增长规则来解决指数搜索问题。
规则增长策略:
1 从一般到特殊:
先建立一个初始规则 r:{ }–>y,其中左边是空集,右边包含目标类。
接着加入新的合取项来提高规则的质量。
继续该过程,直至满足终止条件为止,例如加入的合取项已经不能提高规则的质量。
2 从特殊到一般
随机选择一个正例作为规则增长的初始种子。
通过删除规则的合取项,使其覆盖更多的正例来泛化规则。
重复求精步骤,直至满足终止条件为止,例如当规则开始覆盖反例为止。
由于规则以贪心的方式增长,以上方法可能会产生次优规则,为了避免这种问题,可以采用束状搜索。
算法维护k个最佳候选规则,各候选规则各自在其前件中增加或删除合取项而独立增长。评选候选规则的质量,选出k个最佳候选项进入下一轮迭代。
规则评估:在规则增长的过程中,需要一种评估度量来确定应该添加(或删除)哪个合取项。
(1)使用统计检验剪除覆盖率较低的规则
用似然比统计量
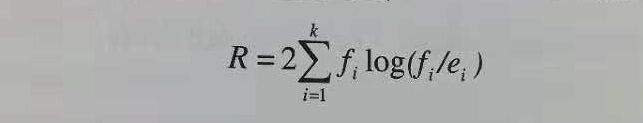
其中,k是类的个数,fi是被规则覆盖的类i的样本观测频率,ei是规则作随机猜测的期望概率。
(2)使用一种考虑规则覆盖率的度量
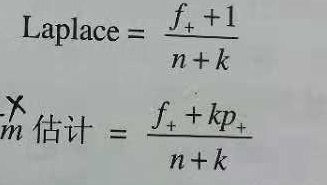
n是规则覆盖的样例数,f+是规则覆盖的正例数,k是类的总数,p+是正类的先验概率。
(3)使用的评估度量是考虑规则的支持度技术的评估度量。
FOIL信息增益
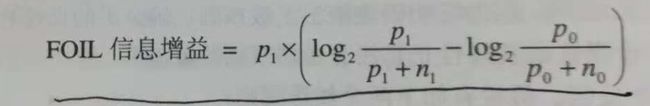
原规则覆盖p0个正例和n0个反例,扩展后规则覆盖p1个正例和n1个反例。
规则剪枝
1 根据确定集的误差
2 根据规则的悲观误差
顺序覆盖基本原理:
规则提取来之后,顺序覆盖算法必须删除规则所覆盖的所有正例和反例。
RIPPER算法
广发使用的规则归纳算法。
优点:复杂度几乎线性的随训练样例的数目增长
很好地处理噪声数据集
1 规则增长
一般到特殊的规则增长
FOIL信息增益来选择最佳合取项添加到规则前件
用(p-n)/(p+n)确定是否剪枝,p,n分别为规则覆盖的正例和反例数。
2 建立规则集:一个规则生成后,他所覆盖的正例和反例都要被删除。
规则提取的间接方法:
规则产生:决策树中从根节点到叶节点的每一条路径都产生一条规则。
规则排序
基于规则的分类器的特征:
(1)规则集的表达能力几乎等价于决策树,因为决策树可以用互斥和穷举的规则集表示。
(2)基于规则的分类器通常被用来产生更易于解释的描述性模型,而模型的性能却可与决策树分类器相媲美。
(3)被很多基于规则的分类器所采用的基于类的规则定序方法非常适用于处理类分布不平衡的数据集。
积极学习方法:决策树,基于规则的分类器
消极学习方法:Rote分类器
最近邻分类器
最近邻:和测试样例的属性相对接近的所有训练样例。
可以通过邻近性度量确定是否为临近,方法有SMC,Jccard,余弦等等。找出k个临近点。
对于k值:
太小,则最近邻分类器容易受到由于训练数据集中的噪声而产生过分拟合的影响
太大,最近邻分类器可能会误分类测试样例,因为最近邻列表中可能包含远离其最近额临近点。
最近邻分类器的特点
使用具体的训练样例进行预测,需要一个临近性度量来确定实例间的相似性和距离,还需要一个分类函数根据测试实例与其他实例的邻近性返回测试实例的预测类标号。
最近邻分类器不需要建立模型,因为是消极学习方法
最近邻分类器基于局部信息进行预测,对噪声非常敏感。
可以生成任一形状的决策边界,能提供更加灵活的模型表示。增加最近邻的数目可以降低这种可能性。
除非采用适当的邻近性度量和数据预处理,否则最近邻分类器可能做出错误的预测。