【Spark】PySpark的RDD与DataFrame的转换与使用
RDD与DataFrame
- RDD
-
- 1. SparkSession
- 2. RDD
- 2.1 创建RDD
-
- 2.1.1 读取文本文件
- 2.1.2 通过parallelize和range
- 2.2 操作RDD
-
- RDD的两类算子:
- RDD的持久化储存
- 2.2.1 取值操作
- 2.2.2 map() 与 flatMap()
- 2.2.3 reduce()与reduceByKey()
- 2.2.4 键值对
- 2.2.5 filter()
- 2.2.6 join()
- 2.2.7 union() 与 intersection()
- 累加器和广播变量
- DataFrame
-
- 1. 生成DataFrame的方法
- 2. 生成新的一列
- 3. 常用API
- DataFrame与RDD之间的转换
- 在RDD中对非结构化数据进行操作
RDD
1. SparkSession
使用Spark核心API的应用以SparkContext对象作为程序主入口,而Spark SQL应用则以SparkSession对象作为程序主入口,在Spark2.0发布之前,Spark SQL应用使用的专用主入口是SQLContext和HiveContext。SparkSession把它们封装为一个简洁而统一的入口。
SparkSession 与 SparkContext 初始化:
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local").appNmae("example").getorCreate()
sc = spark.sparkContext
2. RDD
RDD为弹性分布式数据集。RDD是Spark的基本数据对象,无论是最初加载的数据集,还是中间运算结果的数据集,还是最终的结果数据集,都是RDD。
大多数Spark对从外部加载数据到RDD,然后对已有的RDD进行操作生成新的RDD,这些操作是转化操作,最终输出操作为止,这种操作是行动操作。
弹性:RDD是有弹性的,如果某个RDD丢失了,Spark可以通过记录的RDD谱系重新建立。
分布式:RDD是分布式的,RDD中的数据至少被分到一个区中,在集群上跨工作节点的保存在内存中。
数据集:RDD是由记录组成的数据集。记录是数据集中可以唯一区分的数据的集合。
常见的RDD基础操作属性函数如下表所示:

2.1 创建RDD
| 文件系统 | URL结构 |
|---|---|
| 本地文件系统 | file:///本地文件路径 |
| HDFS | hdfs:///hdfs路径 |
| Amazon S3* | s3://bucket/path |
2.1.1 读取文本文件
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
# 读取整个目录下的内容
logs = sc.textFile("hdfs:///user/data/")
# 读取单个文件
logs = sc.textFile("hdfs:///user/data/Log_Partition_001.txt/")
# 使用通配符读取文件
logs = sc.textFile("hdfs:///user/data/*_001.txt")
# 把整个目录的内容加载为键值对
logs = sc.textFile("hdfs:///user/data/")
spark.stop()
2.1.2 通过parallelize和range
from pyspark.sql import SparkSession
spark = sparkSession.builder.master("local").appName("test").getOrCreate()
sc = spark.sparkContext
# 通过parallelize
rdd = sc.parallelize([1,2,3,4,5,6,7])
# 通过range
rdd = sc.range(1,8,1,2) # sc.range(start,end=None,step=1,numslices=None),numslices指定所需分区数量
spark.stop()
2.2 操作RDD
RDD的两类算子:
- 变换(transformations)
特点:懒执行,变换一些指令集并不会马上执行,只有等到action的时候才会计算结果
如: map() flatMap() groupByKey() reduceByKey() - 操作(action)
特点:立即执行
如:count() take() collect() top() first()
RDD的持久化储存
cache和persist:能够使RDD在初次执行Action的时候计算RDD,第二次使用的时候action的时候Spark不会重新刷新RDD。
2.2.1 取值操作
collect : 将RDD里的元素以列表形式返回
from spark.sql import sparkSession
spark = spark.builder.master("local").appName("test").getOrCreate()
sc = spark.sparkContext
rdd = sc.parallelize([1,2,3,4,5,6,7])
print(rdd.collect())
spark.stop()
其他RDD元素取值操作:
-
take(n) 返回前n个元素
-
top(n) 返回最大的n个元素
-
first() 返回第一个元素
-
lookup(key) 返回某键值下的所有值
-
collectAsMap()返回的是一MAP形式的串行化结果
-
count 与 countByKey() 返回的是每一键组内的记录数

2.2.2 map() 与 flatMap()
map()类似于Python中的map,针对RDD对应的列表的每一个元素,进行map()函数里面每个元素的lambda对应操作,返回仍然是RDD对象。
flatMap()将所有元素进行操作,数量只会大于或等于原始元素数量。
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local").appName("test").getOrCreate()
sc = spark.sparkContext
rdd1 = sc.parallelize([1,2,3,4,5,6,7])
rdd2 = rdd1.map(lambda x:x**2)
print(rdd2.collect())
输出:

2.2.3 reduce()与reduceByKey()
reduce()是针对RDD对应的列表中的元素,递归地选择第一个和第二个元素进行操作,操作的结果作为一个元素用来替换这两个元素,注意,reduce返回的是一个Python可以识别的对象,非RDD对象。

reduceByKey是对元素为键值对的RDD中的key相同的元素的Value进行Reduce操作,因此,Key相同的元素会生成一个新的键值对,去除重复见值。
2.2.4 键值对
- zip() 合并两个列表,并按索引应对值
- rdd.keys() 返回的是键
- rdd.values() 返回的是值

2.2.5 filter()
用于删除/过滤,删除不满足条件的元素,使用lambda函数的形式传入filiter()函数中,返回rdd对象。

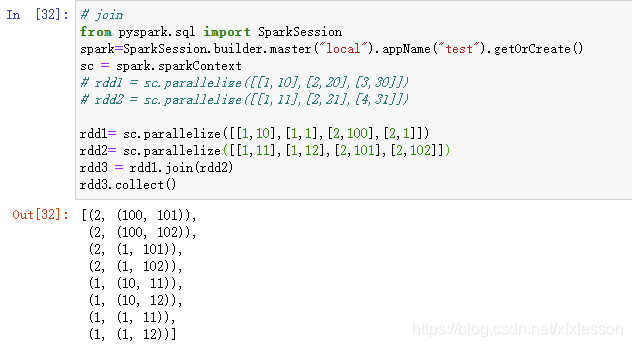
2.2.6 join()
用于匹配元素,类似sql中的leftjoin
2.2.7 union() 与 intersection()
union:求两个RDD对象元素的并,不去掉重复元素
intersection:求两个RDD对象元素的交集
subtract(): 返回在a中出现,并且不在b中出现的元素,不去重
Cartesian(): 该函数返回的是Pair类型的RDD,计算结果是当前RDD和other RDD中每个元素进行笛卡儿计算的结果。最后返回的是CartesianRDD。(笛卡儿计算会消耗大量内存,慎用)

累加器和广播变量
DataFrame
1. 生成DataFrame的方法
- RDD生成DataFrame
- 通过pyhton对象
- 通过读取JSON文件
- 通过读取csv文件
- 通过读取文本文件
# RDD
from pyspark.sql import SparkSession
spark=SparkSession.builder.master("local").appName("test").getOrCreate()
sc=spark.sparkContext
rdd= sc.parallelize([('a',1),('b',2)])
dataframe=spark.createDataFrame(rdd,['a','b'])
print(dataframe.collect())
# python对象
data = [('a',1),('b',2)]
df = spark.createDataFrame(data,['a','b'])
print(df.collect())
# 通过读取JSON文件
data=spark.read.json(".../data.json")
# 读取csv文件
data=spark.read.csv(path="file:///.../data.csv",schema=None,sep=",",header=True)
# 读取文本文件
data = spark.read.text(path="hdfs:///.../data_001.txt")
# [Row(a='a', b=1), Row(a='b', b=2)]
2. 生成新的一列
withColumn:
df = df.withColumn('new_column',
IF fruit1 == fruit2 THEN 1, ELSE 0. IF fruit1 IS NULL OR fruit2 IS NULL 3.)
3. 常用API
默认与pandas.df中的操作一样
- show()
- select()
- drop()
- distinct()
- drop()
df3=df1.join(df2,on='name',how='left_outer')#按name字段匹配
- orderBy()
- groupBy()
DataFrame与RDD之间的转换
转载: https://blog.csdn.net/helloxiaozhe/article/details/89414735
在RDD中对非结构化数据进行操作
在项目过程中的特征会通过使用非结构化数据节省空间,对数据的存储采用非结构话的数据,如何将非结构化的数据取出并生成结构化的DataFrame进行使用,方便数据处理
# rdd内转换生成dataframe
# 读取本地的数据
import findspark
findspark.init()
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
import numpy as np
from pyspark.sql.functions import udf, col, split
import pandas as pd
dir_ = "hdfs:///home/.../part-00000-testdata1"
# 生成dataframe的格式
# logs = spark.read.text(dir_)
# 生成RDD格式
sc = spark.sparkContext
logs = sc.textFile(dir_)
deal_logs = logs.map(lambda x:parse_line(x))
def parse_line(line):
line = line.strip().split("\t")
tdid = line[0]
dict_da = dict([('tdid', tdid)] + [c.split(':') for c in line[1:] if ':' in c])
for var in ['测试特征1','测试特征2']:
if var not in dict_da.keys():
dict_da[var] = np.nan
return dict_da
spark_df = spark.createDataFrame(deal_logs)
spark_df.show()
附上官网:http://spark.apache.org/docs/latest/api/python/reference/pyspark.sql.html