【菲尔兹学院夏令营】复杂网络4-高级操作
高级操作
- 图嵌入(Graph Embedding)
- 图半监督学习(SSL)
- 超图
图嵌入
Graph Embedding,也叫图表示学习(Network Representation Learning)
- 图嵌入的快速概述
- 一些算法:node2vec、LINE、Verse
- 比较嵌入算法的框架
- 示例
概述
目标:
-
将网络(节点)映射到向量(特征)空间
-
将相似节点映射到向量空间中的附近位置。“相似”可能有不同含义:
- 图拓扑上较近
- 图中相似的角色(例如:度相似)
- 相似的节点属性
应用实例:
- 特征学习(不是特征工程)
- 可视化
- 链接预测
- 社区检测
- 异常检测
- 网络演化(动力学)
形式化描述:
- 输入:G = (V , E)
- 输出:特征向量 z v ∈ R k , ∀ v ∈ V z_v ∈ \mathbb{R}^k, ∀v ∈ V zv∈Rk,∀v∈V
算法
——大部分算法基于随机游走和 用于词嵌入的 SkipGram 方法
- 词的语义由其上下文决定(A word can be characterized by the company it keeps)
- 相似上下文中的词(相近的词)具有相似的含义
- 考虑每个单词周围的窗口;构建“词向量”(例如:word2vec)
- 使用这些作为训练数据
SkipGram:
使用滑动窗口邻域对每个词上下文的相关词进行组合,构建“词向量”

DeepWalk(深度游走):
- 单词——对应于节点 v ∈ V v ∈ V v∈V
- 句子——对应于图 G 上的随机游走
- 句子中的词频呈现幂律分布——游走中的顶点也呈现幂律分布
node2vec:
- 定义了有偏随机游走(biased random walks)混合了广度和深度优先搜索
- 关键参数:
- p:控制重新访问同一节点的概率(留在附近)
- q:控制探索更远的概率
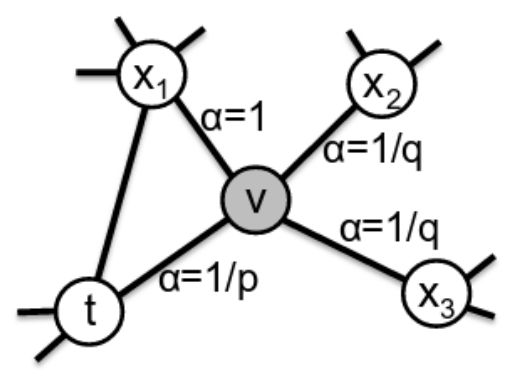

- 参数允许在以下之间进行权衡:
- 低 p:在本地探索;这将侧重于图形拓扑结构中的社区结构(同质性);
- 低q:探索更远;这允许捕获节点之间的一些结构相似性(例如:集线器hubs,网桥bridges);
其他算法:
统计表见课件
在我们的测试中使用了:
- node2vec:q=1,p各不相同
- VERSE:来自相似性度量(具有个性化page rank)的多功能图嵌入算法:使用默认参数
- LINE:Large-scale Information Network Embedding(大规模信息网络嵌入),它使用邻接矩阵的近似分解来尝试保留一阶和二阶邻近度
比较框架
- 我应该使用哪种嵌入算法?
- 如何选择参数?
- 我怎么知道这种嵌入算法对图的表示就好?
- GIGO:向量空间中的错误表示会导致错误的结果…
算法之间的结果可能会有很大差异,并且随着参数的选择也会有很大不同
核心:使用嵌入后的向量构建同分布随机图,比较随机图和原图的JS散度,若很小,说明相近,进而说明嵌入效果良好
概述
框架模型:
给定具有度分布 w = ( w 1 , . . . , w n ) w = (w_1, . . . , w_n) w=(w1,...,wn) 的 n 个顶点上图 G = (V , E) 及其顶点到 k 维空间的嵌入,$ ε : V → \mathbb R^k$。
- 我们的目标是为这个嵌入分配一个“分歧分数”(divergence score)。
- 分数越低,嵌入越好。这将使我们能够在不同的维度上比较多个嵌入的结果
总述:
-
非随机图表现出类似社区的结构,所以我们一般:
- 将节点分组为集群
- 测量簇之间和簇内的边缘密度
- 通过 计算散度分数 将其与嵌入(矢量)空间中空间模型的预测密度进行比较
- 选择得分最高的嵌入
-
我们的框架中有两个主要部分:
- 图拓扑视图:一个好的、稳定的图聚类算法;我们默认使用 ECG,但我们也尝试使用 Louvain 和 InfoMap
- 空间视图:我们引入了基于度分布 w 和嵌入 ε 的几何 Chung-Lu (GCL) 模型。
几何Chung-Lu(GCL) 模型
Chung-Lu 模型:(引子)
-
在原始的 Chung-Lu 模型中,每个集合 e = v i , v j , v i , v j ∈ V e = {v_i, v_j}, v_i, v_j ∈ V e=vi,vj,vi,vj∈V 被独立采样为边,概率为:
p i , j = { deg G ( v i ) deg G ( v j ) 2 ∣ E ∣ , i ≠ j deg G 2 ( v i ) 4 ∣ E ∣ , i = j p_{i, j}= \begin{cases}\frac{\operatorname{deg}_G\left(v_i\right) \operatorname{deg}_G\left(v_j\right)}{2|E|}, & i \neq j \\ \frac{\operatorname{deg}_G^2\left(v_i\right)}{4|E|}, & i=j\end{cases} pi,j={2∣E∣degG(vi)degG(vj),4∣E∣degG2(vi),i=ji=j
-
它产生的分布保留了每个顶点的预期度数
几何Chung-Lu(GCL) 模型:
考虑预期的度分布:
w = ( w 1 , . . . , w n ) = ( d e g G ( v 1 ) , . . . , d e g G ( v n ) ) w = (w_1, . . . , w_n) = (deg_G(v_1), . . . , deg_G(v_n)) w=(w1,...,wn)=(degG(v1),...,degG(vn))
以及节点$ ε : V → \mathbb R^k$ 的嵌入,以便我们知道所有距离:
d i , j = d i s t ( ε ( v i ) , ε ( v j ) ) d_{i,j} = dist(ε(v_i), ε(v_j)) di,j=dist(ε(vi),ε(vj))
模型应该满足 p i , j ∝ g ( d i , j ) p_{i,j} ∝ g(d_{i,j}) pi,j∝g(di,j),g为递减函数,因此长边的出现频率应该低于短边
-
我们使用以下归一化函数 g : [ 0 , ∞ ) → [ 0 , 1 ] g :[0, ∞) → [0, 1] g:[0,∞)→[0,1] 其中 α ∈ [ 0 , ∞ ) α ∈ [0, ∞) α∈[0,∞)是一个定值:
g ( d ) : = ( 1 − d − d min d max − d min ) α , d min = min { dist ( E ( v ) , E ( w ) ) : v , w ∈ V } d max = max { dist ( E ( v ) , E ( w ) ) : v , w ∈ V } \begin{gathered} g(d):=\left(1-\frac{d-d_{\text {min }}}{d_{\max }-d_{\min }}\right)^\alpha, \\ d_{\text {min }}=\min \{\operatorname{dist}(\mathcal{E}(v), \mathcal{E}(w)): v, w \in V\} \\ d_{\max }=\max \{\operatorname{dist}(\mathcal{E}(v), \mathcal{E}(w)): v, w \in V\} \end{gathered} g(d):=(1−dmax−dmind−dmin )α,dmin =min{dist(E(v),E(w)):v,w∈V}dmax=max{dist(E(v),E(w)):v,w∈V}
——我们使用裁剪(clipping)来强制 g ( d m i n ) < 1 g(d_{min}) < 1 g(dmin)<1 和/或 g ( d m a x ) > 0 g(d_{max}) > 0 g(dmax)>0- 当 α = 0 时,此模型退化为原始的 Chung-Lu 模型,忽略了节点对的距离
- 参数 α 越大,对长边的厌恶越大
- 因此,模型的唯一参数是 α ∈ [0, ∞)
- 在实践中,我们会尝试一系列值并保持最佳拟合。
-
GCL模型是基于顶点集 V = v 1 , . . . , v n V = {v_1, . . . , v_n} V=v1,...,vn 上的随机图 G ( W , E , α ) \mathcal G(\mathbf W, \mathcal{E}, α) G(W,E,α) 其中 vi, vj, 形成一条边的概率为:
p i , j = x i x j g ( d i , j ) p_{i,j} = x_ix_jg(d_{i,j}) pi,j=xixjg(di,j)- 权重选择: x i ∈ R + x_i ∈ \mathbb R_+ xi∈R+
-
顶点vi的度期望为:
w i = ∑ j p i , j = x i ∑ j x j g ( d i , j ) w_i=\sum_j p_{i, j}=x_i \sum_j x_j g\left(d_{i, j}\right) wi=j∑pi,j=xij∑xjg(di,j)
定理:当 G 中的最大度数小于所有其他顶点的度数之和时,仅有唯一的权重选择。
——由于 G 的每个连通分量都可以独立嵌入,我们可以假设 G 是连通的,因此 G 的最小度数至少为 1。因此,除非 G 是 n 个顶点上的星形,否则这个非常温和的条件是平凡的。
我们要做的,就是通过选择权重,使得度分布期望等于原图度分布。
解GCL模型
我们使用一个简单的数值近似程序
-
从任意向量开始 t 0 = ( t 0 1 , . . . , t 0 n ) = ( 1 , . . . , 1 ) \mathbf t_0 = (t_0^1 , . . . , t_0^n ) = (1, . . . , 1) t0=(t01,...,t0n)=(1,...,1)
-
给定 t s = ( t 1 s , . . . , t n s ) \mathbf t^s = (t^s_1, . . . , t^s_n) ts=(t1s,...,tns),如果我们以如下概率在 vi 和 vj 之间引入一条边:
p i , j s = t i s t j s g ( d i , j ) p^s_{i,j} = t^s_i t^s_j g(d_{i,j}) pi,js=tistjsg(di,j) -
那么 vi 的度期望将是:(这对应于上小节度期望)
s i s = ∑ j p i , j s = t i s ∑ j t j s g ( d i , j ) s_i^s=\sum_j p_{i, j}^s=t_i^s \sum_j t_j^s g\left(d_{i, j}\right) sis=j∑pi,js=tisj∑tjsg(di,j) -
通过用 t i s ( w i / s i s ) t^s_i (w_i/s^s_i) tis(wi/sis) 替换 t i s t^s_i tis 来调整权重,使 s i s s^s_i sis 与 w i w_i wi 匹配
- 这也会影响 s s \mathbf s^s ss 的其他值,并且 t \mathbf t t 其他部分的变化也会影响 s i s s^s_i sis自身。
- 因此,我们让每个顶点向正确的方向迈出一小步
- 这个过程很快收敛到理想状态:对于所有 i, s i s s^s_i sis 都非常接近 w i w_i wi。
-
迭代步骤:
-
对于每个 i,1 ≤ i ≤ n,我们定义
t i s + 1 = ( 1 − ϵ ) t i s + ϵ t i S ( w i / s i s ) = t i s + ϵ t i S ( w i / s i s − 1 ) t_i^{s+1}=(1-\epsilon) t_i^s+\epsilon t_i^S\left(w_i / s_i^s\right)=t_i^s+\epsilon t_i^S\left(w_i / s_i^s-1\right) tis+1=(1−ϵ)tis+ϵtiS(wi/sis)=tis+ϵtiS(wi/sis−1) -
重复调整过程直到 m a x i ∣ W i − s i s ∣ < δ max_i |\mathbf W_i − s^s_i | <δ maxi∣Wi−sis∣<δ
-
定义 ε = 0.1 、 δ = 0.001
-
分歧分数算法
计算嵌入分歧分数(embedding divergence score)的算法
给定 G = (V, E),它在 V 上的度分布 w,以及它的顶点的嵌入$ \mathcal E : V → \mathbb R^k$,我们将执行接下来详述的五个步骤
- 通过算法,我们获得 Δ E ( G ) ΔE(G) ΔE(G),嵌入的分歧分数
- 我们可以应用这个算法来比较几个嵌入算法的分歧分数指标,选出最好的(最小的)那个
第一步:
在 G 上运行一些稳定的图聚类算法以获得顶点集 V 的分区 C \mathbf C C ,一共产生 l l l 个社区 C 1 , . . . C l C_1, . . . C_l C1,...Cl。
此教程中使用ECG,其实任何稳定的算法都可以。
第二步:
令:
- c i c_i ci:两个端点都在 C i C_i Ci 中的边的比例
- c i , j c_{i,j} ci,j:一个端点在 C i C_i Ci 中且另一个端点在 C j C_j Cj 中的边的比例
定义:
c ‾ = ( c 1 , 2 , … , c 1 , ℓ , c 2 , 3 , … , c 2 , ℓ , … , c ℓ − 1 , ℓ ) , c ^ = ( c 1 , … , c ℓ ) \overline{\mathbf{c}}=\left(c_{1,2}, \ldots, c_{1, \ell}, c_{2,3}, \ldots, c_{2, \ell}, \ldots, c_{\ell-1, \ell}\right), \hat{\mathbf{c}}=\left(c_1, \ldots, c_{\ell}\right) c=(c1,2,…,c1,ℓ,c2,3,…,c2,ℓ,…,cℓ−1,ℓ),c^=(c1,…,cℓ)
——这些向量从 图 G 的角度表征分区 C,嵌入 E \mathcal E E 不影响 c ‾ \overline{\mathbf{c}} c 和 c ^ \hat{\mathbf{c}} c^
——接下来我们在 α 的一系列值上重复步骤 3-4
第三步:
给定 α ∈ R + α ∈ \mathbb R_+ α∈R+,使用 G ( W , E , α ) \mathcal G(\mathbf W, \mathcal{E}, α) G(W,E,α)的GCL 模型。
从这个模型,我们计算:
- b i b_i bi: C i C_i Ci 内边的比例期望
- b i , j b_{i,j} bi,j: C i C_i Ci 中一个端点和 C j C_j Cj 中另一个端点的边的比例期望
定义:
b ‾ E ( α ) = ( b 1 , 2 , … , b 1 , ℓ , b 2 , 3 , … , b 2 , ℓ , … , b ℓ − 1 , ℓ ) , b ^ E ( α ) = ( b 1 , … , b ℓ ) \overline{\mathbf{b}}_{\mathcal E}(\alpha)=\left(b_{1,2}, \ldots, b_{1, \ell}, b_{2,3}, \ldots, b_{2, \ell}, \ldots, b_{\ell-1, \ell}\right), \hat{\mathbf{b}}_{\mathcal E}(\alpha)=\left(b_1, \ldots, b_{\ell}\right) bE(α)=(b1,2,…,b1,ℓ,b2,3,…,b2,ℓ,…,bℓ−1,ℓ),b^E(α)=(b1,…,bℓ)
——这些向量从 嵌入 E \mathcal E E 的角度表征分区 C
第四步:
计算 c ‾ \overline{\mathbf{c}} c 和 b ‾ E ( α ) \overline{\mathbf{b}}_{\mathcal E}(\alpha) bE(α) 之间的距离,以及 c ^ \hat{\mathbf{c}} c^ 和 b ^ E ( α ) \hat{\mathbf{b}}_{\mathcal E}(\alpha) b^E(α) 之间的距离
我们使用 Jensen-Shannon 散度 (JSD):
Δ α = 1 2 ⋅ ( J S D ( c ‾ , b ‾ ( α ) ) + J S D ( c ^ , b ^ ( α ) ) ) \Delta_\alpha=\frac{1}{2} \cdot(J S D(\overline{\mathbf{c}}, \overline{\mathbf{b}}(\alpha))+J S D(\hat{\mathbf{c}}, \hat{\mathbf{b}}(\alpha))) Δα=21⋅(JSD(c,b(α))+JSD(c^,b^(α)))
——这是给定 α 的(分歧)分数。
第五步:
从重复的步骤 3-4,我们获得了一系列 Δ α Δ_α Δα
选择 α ^ = a r g m i n α ∆ α \hat α = argmin_α ∆_α α^=argminα∆α
将分歧分数定义为:
Δ E ( G ) = Δ α ^ \Delta_{\mathcal{E}}(G)=\Delta_{\hat{\alpha}} ΔE(G)=Δα^
总结:
- 为了比较同一个图 G 的多个嵌入,我们重复上面的步骤 3-5 并比较分歧分数(分数越低越好)。
- 步骤 1-2 只执行一次,因此我们对每个嵌入使用相同的图划分算法到 ℓ \ell ℓ 个社区
示例
- 空手道俱乐部:找到最适合嵌入的α值
- 足球比赛:使用分歧分数选择最合适的嵌入算法
- LFR 数据集:使用此方法选出的最好和最坏embedding算法效果
关系数据上的半监督学习
简介(转导学习)
我们使用一种转导学习(transductive learning)的方法:
- 没有显式地构造任何模型
- 学习是“基于数据”的
- 在图上使用正则化框架,正则化包含以下两种情况:
- 局部结构:与稀缺标记顶点一致
- 全局结构:所有顶点的平滑
形式化描述:
设 G = ( V , E ) G = (V, E) G=(V,E), ∣ V ∣ = n , E ⊂ V × V |V | = n, E⊂V × V ∣V∣=n,E⊂V×V
设函数 f : V → R f: V→\mathbb R f:V→R ,同时定义两个函数的内积: ⟨ f , g ⟩ = ∑ v ∈ V f ( v ) g ( v ) \left\langle f, g \right\rangle = \sum_{v \in V} f (v)g(v) ⟨f,g⟩=∑v∈Vf(v)g(v)
-
我们定义一个函数 f ∗ : V → R f^*: V→\mathbb R f∗:V→R 满足:
f ∗ = a r g m i n f ∈ H ( v ) ( Ω ( f ) + μ ∣ ∣ f − y ∣ ∣ 2 ) f^*=argmin_{f \in H(v)}(\Omega(f)+\mu ||f - y||^2) f∗=argminf∈H(v)(Ω(f)+μ∣∣f−y∣∣2)-
Ω ( f ) Ω(f) Ω(f)是一个依赖于G的泛函:平滑泛函
——取决于图的类型:无向、有向、联合链接(两者都有)
-
y y y 编码先验知识(顶点标签)
——取决于要解决的问题:
- 二进制分类: y ∈ − 1 , 0 , 1 y∈{−1,0,1} y∈−1,0,1
- 排序: y ∈ 0 , 1 y∈{0,1} y∈0,1
- 无监督: y ∈ 0 y∈{0} y∈0
-
μ \mu μ:平滑度(smoothness)和一致性(consistency)之间的权衡
-
应用-示例
- 给出一个包含一些“有趣”实体的大型图
- 求解 f ∗ f^* f∗以放大附近的顶点
最终可以:
- 获得未知实体的排名
- 能可视化关键子图
- 网络安全环境中的几个应用
- 异常检测
- 恶意软件检测
- 图和超图通常太大,不适合直接分析或可视化
无向图
图模型:
- 设无向图为 G = ( V , E ) G = (V, E) G=(V,E) W W W 是所有 ( u , v ) ∈ E (u, v)∈E (u,v)∈E 的边权 w ( u , v ) w (u, v) w(u,v) 的矩阵。
- 设D为节点度的对角线矩阵: d ( v ) = ∑ u ∼ v w ( u , v ) d(v)=\sum_{u\sim v}w(u,v) d(v)=∑u∼vw(u,v)
无监督N-cut问题:(回顾)
-
对于一个分割 V = S ∪ S c V=S \cup S^c V=S∪Sc
Ncut ( S , S c ) = V o l ∂ S V o l S + V o l ∂ S V o l S c \operatorname{Ncut}\left(S, S^c\right)=\frac{ Vol \partial S}{VolS }+\frac{ Vol \partial S }{VolS^c} Ncut(S,Sc)=VolSVol∂S+VolScVol∂S
其中:
∂ S = { e ∈ E ; ∣ e ∩ S ∣ = ∣ e ∩ S C ∣ = 1 } Vol ( S ) = ∑ v ∈ S d ( v ) Vol ( ∂ S ) = ∑ ( u , v ) ∈ ∂ S w ( u , v ) \begin{aligned} & \partial S=\left\{e \in E ;|e \cap S|=\left|e \cap S^C\right|=1\right\} \\ & \operatorname{Vol}(S)=\sum_{v \in S} d(v) \\ & \operatorname{Vol}(\partial S)=\sum_{(u, v) \in \partial S} w(u, v) \end{aligned} ∂S={e∈E;∣e∩S∣= e∩SC =1}Vol(S)=v∈S∑d(v)Vol(∂S)=(u,v)∈∂S∑w(u,v)
这可以被视为具有转移概率 P = D − 1 W P = D^{−1}W P=D−1W 的随机游走:
N c u t ( S , S c ) = P ( S ∣ S c ) + P ( S c ∣ S ) Ncut(S, S^c) = P(S|S^c) + P(S^c|S) Ncut(S,Sc)=P(S∣Sc)+P(Sc∣S) -
这个问题可以通过松弛实值来解决
f ∗ = argmin f ∈ R n Ω ( f ) ; f ⊥ D 1 / 2 ⋅ 1 , ∥ f ∥ 2 = vol ( V ) f^*=\underset{f \in \mathbb{R}^n}{\operatorname{argmin}} \Omega(f) ; f \perp D^{1 / 2} \cdot 1,\|f\|^2=\operatorname{vol}(V) f∗=f∈RnargminΩ(f);f⊥D1/2⋅1,∥f∥2=vol(V)
其中 Ω ( f ) = ⟨ f t , Δ f ⟩ \Omega(f)=\left\langle f^t, \Delta f\right\rangle Ω(f)=⟨ft,Δf⟩ 且:
Δ = I − D − 1 / 2 W D − 1 / 2 \Delta=I-D^{-1 / 2} W D^{-1 / 2} Δ=I−D−1/2WD−1/2
是(归一化)图拉普拉斯矩阵
——这被称为归一化谱聚类(normalized spectral clustering)
半监督问题:
概述:
-
拉普拉斯矩阵也出现在半监督问题中:
-
如果节点接近( w ( u , v ) w(u, v) w(u,v)很大),那么它们应该有相似的标签( f ( u ) ≈ f ( v ) f (u)≈f (v) f(u)≈f(v)),以保持 w ( u , v ) ( f ( u ) − f ( v ) ) 2 w(u, v)(f (u)−f (v))^2 w(u,v)(f(u)−f(v))2较小
-
在整个图上,这相当于保持 Ω ( f ) Ω(f) Ω(f)较小
-
这可以看作是找到一个“平滑”函数f,它在图的密集区域中变化很小,但在稀疏区域中变化更大。
形式化描述:
-
现在假设顶点上有一些初始(种子)值y:
-
将半监督问题定义为关于图拓扑的“平滑性”和关于y的一致性之间的权衡,例如:
f ∗ = argmin f ∈ R n ( Ω ( f ) + μ ∥ f − y ∥ 2 ) f^*=\underset{f \in \mathbb{R}^n}{\operatorname{argmin}}\left(\Omega(f)+\mu\|f-y\|^2\right) f∗=f∈Rnargmin(Ω(f)+μ∥f−y∥2)
令 Ω ( f ) = ⟨ f t , Δ f ⟩ \Omega(f)=\left\langle f^t, \Delta f\right\rangle Ω(f)=⟨ft,Δf⟩, 则有:
Ω ( f ) = 1 2 ∑ ( u , v ) ∈ E w ( u , v ) ( f ( u ) d ( u ) − f ( v ) d ( v ) ) 2 \Omega(f)=\frac{1}{2} \sum_{(u, v) \in E} w(u, v)\left(\frac{f(u)}{\sqrt{d(u)}}-\frac{f(v)}{\sqrt{d(v)}}\right)^2 Ω(f)=21(u,v)∈E∑w(u,v)(d(u)f(u)−d(v)f(v))2
若 y ≠ 0 y \neq 0 y=0, 且 μ > 0 \mu>0 μ>0,存在一个封闭式解:
f ∗ = μ ( Δ + μ I ) − 1 y = ( 1 − α ) ( I − α S ) − 1 y f^*=\mu(\Delta+\mu I)^{-1} y=(1-\alpha)(I-\alpha S)^{-1} y f∗=μ(Δ+μI)−1y=(1−α)(I−αS)−1y
其中:α = ( 1 + μ ) − 1 \alpha=(1+\mu)^{-1} α=(1+μ)−1
Δ = I − D − 1 / 2 W D − 1 / 2 \Delta=I-D^{-1 / 2} W D^{-1 / 2} Δ=I−D−1/2WD−1/2, 归一化图拉普拉斯矩阵
S = I − Δ S=I-\Delta S=I−Δ, 平滑矩阵
求解:
f ∗ f^* f∗可通过多种方式获得:
-
迭代方法:
-
从 f ( v ) = y f (v) = y f(v)=y开始,
-
迭代 f ( v ) ← α ( S f ) ( v ) + ( 1 − α ) y , ∀ v f (v)←α(Sf)(v) +(1−α)y,∀v f(v)←α(Sf)(v)+(1−α)y,∀v
-
-
它可以写成一个 对角占优 的线性问题,其反演技术存在,且复杂度为 O ( m 1.31 ) O(m^{1.31}) O(m1.31),其中m为非零项的个数
-
通过共轭梯度法
-
map-reduce框架具有良好的可伸缩性
其他图
有向图
形式化描述:
-
定义进出节点度:
d − ( v ) = ∑ u w ( u , v ) , d + ( v ) = ∑ u w ( v , u ) d_{-}(v)=\sum_u w(u, v), \quad d_{+}(v)=\sum_u w(v, u) d−(v)=∑uw(u,v),d+(v)=∑uw(v,u). -
V V V 上的然随机游走的转换概率为:
p ( u , v ) = { w ( u , v ) d + ( u ) , ( u , v ) ∈ E 0 , else. p(u, v)=\left\{\begin{array}{cc} \frac{w(u, v)}{d^{+}(u)}, & (u, v) \in E \\ 0, & \text { else. } \end{array}\right. p(u,v)={d+(u)w(u,v),0,(u,v)∈E else. -
设 π \pi π 为唯一平稳分布,即:
π ( v ) = ∑ u → v π ( u ) p ( u , v ) . \pi(v)=\sum_{u \rightarrow v} \pi(u) p(u, v) . π(v)=u→v∑π(u)p(u,v).
这需要定义一个传送随机游走(teleporting random walk)——用于描述随机游走的概率 -
考虑泛函:
Ω ( f ) : = 1 2 ∑ e = ( u , v ) π ( u ) p ( u , v ) ( f ( u ) π ( u ) − f ( v ) π ( v ) ) 2 \Omega(f):=\frac{1}{2} \sum_{e=(u, v)} \pi(u) p(u, v)\left(\frac{f(u)}{\sqrt{\pi(u)}}-\frac{f(v)}{\sqrt{\pi(v)}}\right)^2 Ω(f):=21e=(u,v)∑π(u)p(u,v)(π(u)f(u)−π(v)f(v))2 -
正则化问题和之前一样
Δ = I − S , S = Π 1 / 2 P Π − 1 / 2 + Π − 1 / 2 P t Π 1 / 2 2 \Delta=I-S, S=\frac{\Pi^{1 / 2} P \Pi^{-1 / 2}+\Pi^{-1 / 2} P^t \Pi^{1 / 2}}{2} Δ=I−S,S=2Π1/2PΠ−1/2+Π−1/2PtΠ1/2
其中 P P P 是转移概率的矩阵, Π \Pi Π 平稳概率的对角矩阵。(和无向图的差别在平滑矩阵S上) -
和之前一样: f ∗ = ( 1 − α ) ( I − α S ) − 1 y f^*=(1-\alpha)(I-\alpha S)^{-1} y f∗=(1−α)(I−αS)−1y.
——这是对无向情况的推广。对于无向图,随机游走的概率是固定的:
π ( v ) = d ( v ) ∑ u d ( u ) \pi(v)=\frac{d(v)}{\sum_u d(u)} π(v)=∑ud(u)d(v)
——此时平滑矩阵退化为无向图情况:
S = D − 1 / 2 W D − 1 / 2 S=D^{-1 / 2} W D^{-1 / 2} S=D−1/2WD−1/2
枢纽/权威型网络
Hubs&Authorities graphs
概述:
考虑顶点 v ∈ V v∈V v∈V的两种可能角色:
- 具有高“入度”的权威(authority)
- 具有高“出度”的枢纽(hub)
对于有向图 e = ( u , v ) e = (u, v) e=(u,v), u是“枢纽”,v是“权威”
平滑矩阵:
-
权威型:
定义节点 u u u 和 v v v 相对于节点 h h h 的权威距离为:
C h ( u , v ) = w ( h , u ) w ( h , v ) d + ( h ) C_h(u, v)=\frac{w(h, u) w(h, v)}{d_{+}(h)} Ch(u,v)=d+(h)w(h,u)w(h,v)
由此我们建立了平滑矩阵:
S A ( u , v ) = ∑ h ∈ V C h ( u , v ) d − ( u ) d − ( v ) S_A(u, v)=\sum_{h \in V} \frac{C_h(u, v)}{\sqrt{d_{-}(u) d_{-}(v)}} SA(u,v)=h∈V∑d−(u)d−(v)Ch(u,v) -
枢纽型
我们同样定义相对于节点 a a a 的枢纽距离为:
C a ( u , v ) = w ( u , a ) w ( v , a ) d − ( a ) C_a(u, v)=\frac{w(u, a) w(v, a)}{d_{-}(a)} Ca(u,v)=d−(a)w(u,a)w(v,a)
平滑矩阵:
S H ( u , v ) = ∑ a ∈ V C a ( u , v ) d + ( u ) d + ( v ) S_H(u, v)=\sum_{a \in V} \frac{C_a(u, v)}{\sqrt{d_{+}(u) d_{+}(v)}} SH(u,v)=a∈V∑d+(u)d+(v)Ca(u,v)
求解模型:
令 Ω A ( f ) = ⟨ f t , Δ A f ⟩ \Omega_A(f)=\left\langle f^t, \Delta_A f\right\rangle ΩA(f)=⟨ft,ΔAf⟩ ,其中 Δ A = I − S A \Delta_A=I-S_A ΔA=I−SA, 我们可以得到:
Ω A ( f ) = 1 2 ∑ u , v ∑ h C h ( u , v ) ( f ( u ) d − ( u ) − f ( v ) d − ( v ) ) 2 \Omega_A(f)=\frac{1}{2} \sum_{u, v} \sum_h C_h(u, v)\left(\frac{f(u)}{\sqrt{d_{-}(u)}}-\frac{f(v)}{\sqrt{d_{-}(v)}}\right)^2 ΩA(f)=21u,v∑h∑Ch(u,v)(d−(u)f(u)−d−(v)f(v))2
对于枢纽型我们可以类似地得到 Ω H ( f ) \Omega_H(f) ΩH(f).
令:
Δ γ = γ Δ A + ( 1 − γ ) Δ H \Delta_\gamma=\gamma \Delta_A+(1-\gamma) \Delta_H Δγ=γΔA+(1−γ)ΔH
我们可以像以前一样解决正则化问题:(带入平滑矩阵求解即可)
f ∗ = argmin f ∈ H ( V ) ( Ω γ ( f ) + μ ∥ f − y ∥ 2 ) f^*=\underset{f \in H(V)}{\operatorname{argmin}}\left(\Omega_\gamma(f)+\mu\|f-y\|^2\right) f∗=f∈H(V)argmin(Ωγ(f)+μ∥f−y∥2)
对于一个无向图: Δ H = Δ A = Δ γ \Delta_H=\Delta_A=\Delta_\gamma ΔH=ΔA=Δγ.
混合图
我们可以将平滑泛函推广为
Ω β , γ ( f ) = β ⋅ Ω ( f ) + ( 1 − β ) ⋅ Ω γ ( f ) \Omega_{\beta, \gamma}(f)=\beta \cdot \Omega(f)+(1-\beta) \cdot \Omega_\gamma(f) Ωβ,γ(f)=β⋅Ω(f)+(1−β)⋅Ωγ(f)
其中 Ω ( f ) \Omega(f) Ω(f) 基于随机游走, Ω γ ( f ) \Omega_\gamma(f) Ωγ(f) 是“枢纽&权威”平滑
这允许3种衡量顶点“接近”的方式:
- 存在一条短路径
- 指向几个公共顶点
- 由几个公共顶点指向
——2和3对于无向图是一样的
超图
模型
符号说明:
对于(无向)超图,定义:
- E E E:超边集合——超边 e e e为节点子集 e ⊂ V e⊂V e⊂V
- w ( e ) w(e) w(e):超边权值
- d ( V ) = ∑ e ; V ∈ e w ( e ) d(V) = \sum_{e; V∈e} w(e) d(V)=∑e;V∈ew(e) :节点度
- δ ( e ) = ∣ e ∣ ≥ 2 δ(e) = |e|≥2 δ(e)=∣e∣≥2:“超边度”
- H : ∣ V ∣ × ∣ E ∣ s.t. h ( v , e ) = 1 iff v ∈ e H: |V | × |E | \space \text{s.t.} \space h (v, e) = 1 \space \text{iff} \space v∈e H:∣V∣×∣E∣ s.t. h(v,e)=1 iff v∈e 关联矩阵
- W = d i a g ( w ( e ) ) W = diag(w(e)) W=diag(w(e)) 权重矩阵,
- D v = d i a g ( d ( V ) ) D_v = diag(d(V)) Dv=diag(d(V)) 节点度矩阵,
- D e = d i a g ( δ ( E ) ) D_e = diag(δ(E)) De=diag(δ(E)) 超边度矩阵。
Ncut问题可以推广到超图:
-
超图体积
对于一个分割 V = S ∪ S c V=S \cup S^c V=S∪Sc,令:
∂ S = { e ∈ E ; e ∩ S ≠ ∅ , e ∩ S c ≠ ∅ } VolS = ∑ v ∈ S d ( v ) Vol ∂ S = ∑ e ∈ ∂ S w ( e ) ∣ e ∩ S ∣ ⋅ ∣ e ∩ S c ∣ ∣ e ∣ \begin{aligned} & \partial S=\left\{e \in E ; e \cap S \neq \emptyset, e \cap S^c \neq \emptyset\right\} \\ & \text { VolS }=\sum_{v \in S} d(v) \\ & \text { Vol } \partial S=\sum_{e \in \partial S} w(e) \frac{|e \cap S| \cdot\left|e \cap S^c\right|}{|e|} \end{aligned} ∂S={e∈E;e∩S=∅,e∩Sc=∅} VolS =v∈S∑d(v) Vol ∂S=e∈∂S∑w(e)∣e∣∣e∩S∣⋅∣e∩Sc∣
——对于最后一个表达式,如果e被映射到分割的两端,分子是将被切割的“边”的数量。(就是转为普通图以后的割边数)可以再次通过随机游走来说明:
p ( u , v ) = ∑ e ∈ E w ( e ) h ( u , e ) d ( u ) h ( v , e ) ∣ e ∣ p(u, v)=\sum_{e \in E} \frac{w(e) h(u, e)}{d(u)} \frac{h(v, e)}{|e|} p(u,v)=e∈E∑d(u)w(e)h(u,e)∣e∣h(v,e)
通过定义节点转移的平稳分布 π ( v ) = d ( v ) V o l V . π(v) = \frac{d(v)}{VolV} . π(v)=VolVd(v). 得到以下结果:
VolS VoIV = ∑ v ∈ S π ( v ) Vol ∂ S VoIV = ∑ u ∈ S ∑ v ∈ S c π ( u ) p ( u , v ) \begin{aligned} & \frac{\text { VolS }}{\text { VoIV }}=\sum_{v \in S} \pi(v) \\ & \frac{\text { Vol}\partial \text{S }}{\text { VoIV }}=\sum_{u \in S} \sum_{v \in S^c} \pi(u) p(u, v) \end{aligned} VoIV VolS =v∈S∑π(v) VoIV Vol∂S =u∈S∑v∈Sc∑π(u)p(u,v) -
超图拉普拉斯矩阵
解松弛后的问题得到与用图相同的形式,但是有
Δ = I − D v − 1 / 2 H ⊤ W D e − 1 H D v − 1 / 2 \Delta=I-D_v^{-1 / 2} H^{\top} W D_e^{-1} H D_v^{-1 / 2} Δ=I−Dv−1/2H⊤WDe−1HDv−1/2
当所有 ∣ e ∣ = 2 |e|=2 ∣e∣=2 时,有:
Δ = 1 2 ( I − D v − 1 / 2 W D v − 1 / 2 ) \Delta=\frac{1}{2}\left(I-D_v^{-1 / 2} W D_v^{-1 / 2}\right) Δ=21(I−Dv−1/2WDv−1/2)
也就是拉普拉斯矩阵的一半,因此 Δ \Delta Δ可以定义为超图拉普拉斯矩阵 -
问题定义
我们定义了与图相同的半监督问题:
f ∗ = argmin f ∈ R n ( Ω ( f ) + μ ∥ f − y ∥ 2 ) f^*=\underset{f \in \mathbb{R}^n}{\operatorname{argmin}}\left(\Omega(f)+\mu\|f-y\|^2\right) f∗=f∈Rnargmin(Ω(f)+μ∥f−y∥2)
其中:
Ω ( f ) = ⟨ f , △ f ⟩ = 1 2 ∑ e ∈ E 1 δ ( e ) ∑ ( u , v ) ∈ e w ( e ) ( f ( u ) d ( u ) − f ( v ) d ( v ) ) 2 \Omega(f)=\langle f, \triangle f\rangle=\frac{1}{2} \sum_{e \in E} \frac{1}{\delta(e)} \sum_{(u, v) \in e} w(e)\left(\frac{f(u)}{\sqrt{d(u)}}-\frac{f(v)}{\sqrt{d(v)}}\right)^2 Ω(f)=⟨f,△f⟩=21e∈E∑δ(e)1(u,v)∈e∑w(e)(d(u)f(u)−d(v)f(v))2
以上问题的解又下式给出:
f ∗ = ( 1 − α ) ( I − α S ) − 1 y , α = ( 1 + μ ) − 1 , S = I − Δ f^*=(1-\alpha)(I-\alpha S)^{-1} y, \alpha=(1+\mu)^{-1}, S=I-\Delta f∗=(1−α)(I−αS)−1y,α=(1+μ)−1,S=I−Δ -
随机游走模型1
- 从顶点u,随机选取 u ∈ e u∈e u∈e 的超边e
- 随机选取一个顶点 v ∈ e v∈e v∈e,然后跳转到v
我们可以将上面的超图视为一个加权邻接矩阵为 A ~ = ( a i j ) \tilde{A}=\left(a_{i j}\right) A~=(aij) 的普通图,其中:
a i j = ∑ e ; ( v i , v j ) ∈ e w ( e ) ∣ e ∣ , a i i = ∑ e ; v i ∈ e w ( e ) ∣ e ∣ a_{i j}=\sum_{e ;\left(v_i, v_j\right) \in e} \frac{w(e)}{|e|}, a_{i i}=\sum_{e ; v_i \in e} \frac{w(e)}{|e|} aij=e;(vi,vj)∈e∑∣e∣w(e),aii=e;vi∈e∑∣e∣w(e)
行和为:
a i . = ∑ e ; v i ∈ e w ( e ) = ∑ e ∈ E w ( e ) h ( e , v i ) = d ( v i ) a_{i .}=\sum_{e ; v_i \in e} w(e)=\sum_{e \in E} w(e) h\left(e, v_i\right)=d\left(v_i\right) ai.=e;vi∈e∑w(e)=e∈E∑w(e)h(e,vi)=d(vi)-
如果所有 ∣ e ∣ = 2 |e|=2 ∣e∣=2, 我们有 a i i = ∑ e : v i ∈ e w ( e ) / 2 = d i / 2 a_{i i}=\sum_{e: v_i \in e} w(e) / 2=d_i / 2 aii=∑e:vi∈ew(e)/2=di/2
-
而对于 e = ( v i , v j ) e=\left(v_i, v_j\right) e=(vi,vj) 我们有 a i j = w ( e ) / 2 a_{i j}=w(e) / 2 aij=w(e)/2, 所以
A ~ = 1 2 ( D V + A ) \tilde{A}=\frac{1}{2}\left(D_V+A\right) A~=21(DV+A)
其中A是这个超图的图表示的(加权)邻接矩阵
因此,对于此随机游走模型,将G视为图和将G视作超图,转导学习问题的解将有所不同
——需要进一步改进
-
随机游走模型2(改进)
我们定义一个新的随机游走如下:
- 从顶点u,随机选取 u ∈ e u∈e u∈e 的超边e
- 随机选取一个顶点 v ∈ e v∈e v∈e, v ≠ u v \neq u v=u,然后跳转到v
我们可以将上面的图视为一个加权邻接矩阵为 A ~ = ( a i j ) \tilde{A}=\left(a_{i j}\right) A~=(aij) 的普通图,其中:
a i j = ∑ e ; ( v i , v j ) ∈ e w ( e ) ∣ e ∣ − 1 , a i i = 0 a_{i j}=\sum_{e ;\left(v_i, v_j\right) \in e} \frac{w(e)}{|e|-1}, \quad a_{i i}=0 aij=e;(vi,vj)∈e∑∣e∣−1w(e),aii=0
行和为:
a i . = ∑ e ; v i ∈ e w ( e ) = d ( v i ) a_{i .}=\sum_{e ; v_i \in e} w(e)=d\left(v_i\right) ai.=e;vi∈e∑w(e)=d(vi)
邻接矩阵表达式为: A ~ = H ⊤ W D ~ e − 1 H − D v \tilde{A}=H^{\top} W \tilde{D}_e^{-1} H-D_v A~=H⊤WD~e−1H−Dv其中 D ~ e \tilde{D}_e D~e 是对角阵,其元素为: 1 ∣ e ∣ − 1 \frac{1}{|e|-1} ∣e∣−11.
在这种情况下,调整后的超图Laplacian矩阵采用以下形式:
Δ = I − S with S = D v − 1 / 2 A ~ D v − 1 / 2 − I \Delta=I-S \text { with } S=D_v^{-1 / 2} \tilde{A} D_v^{-1 / 2}-I Δ=I−S with S=Dv−1/2A~Dv−1/2−I- 如果所有 ∣ e ∣ = 2 |e| = 2 ∣e∣=2,我们得到 A ~ = A \tilde{A}=A A~=A,其中A是这个超图的 图表示 的(加权)邻接矩阵
-
有向超图的情况
我们可以推广到有向超图,其中:
e = e t ∪ e h ∀ e ∈ E , ∣ e t ∣ > 0 , ∣ e h ∣ > 0 e=e_t \cup e_h \forall e \in E,\left|e_t\right|>0,\left|e_h\right|>0 e=et∪eh∀e∈E,∣et∣>0,∣eh∣>0
表示每个超边缘的尾部(tail)和头部(head)向多个收件人发送电子邮件是有向超边的一个例子
分类数据(应用)
超图可以用来对分类数据建模
- 示例:“蘑菇数据集”(UCI ML存储库):
- 22个分类属性,23个物种的8124个观察值
- 目标:二分类——可食用或可能不可食用
- 每个分类属性建模为一个超边
- “帽形=钟形”
- “帽形=圆锥形”
学生作业:
- 用Python编写超图转导学习代码
- 在分类数据上验证已发表的结果——与图模型进行比较
- 研究权衡参数α的影响
- 提出并探索顶点嵌入框架
说明:
-
转导学习
- 颜色代表蘑菇的分类:能不能吃
- 参数α对结果值的量级有较大影响
- 排序结果基本相同
-
嵌入
- 顶点嵌入是一个热门话题
- 尝试从不同初始值运行TL(转导学习)过程
- 生成多维顶点表示
- 和随机游走类似
超图模块度和聚类
- 普通图聚类:模块度和Chung-Lu模型
- 超图的模块度
- 超图Chung-Lu模型
- 严格超图模块度
- 其他超图模块度
- 超图聚类
普通图聚类(回顾)
模块度:
我们可以把图G的划分 A \mathbf A A 的模块度写成:
q G ( A ) = ∑ A i ∈ A ( e G ( A i ) ∣ E ∣ − ( v o l ( A i ) ) 2 4 ∣ E ∣ 2 ) = 1 ∣ E ∣ ∑ A i ∈ A ( e G ( A i ) − E G ∈ G ( e G ( A i ) ) ) \begin{aligned} q_G(\mathbf{A}) & =\sum_{A_i \in \mathbf{A}}\left(\frac{e_G\left(A_i\right)}{|E|}-\frac{\left(v o l\left(A_i\right)\right)^2}{4|E|^2}\right) \\ & =\frac{1}{|E|} \sum_{A_i \in \mathbf{A}}\left(e_G\left(A_i\right)-\underset{G \in \mathcal{G}}{\mathbb{E}}\left(e_G\left(A_i\right)\right)\right) \end{aligned} qG(A)=Ai∈A∑(∣E∣eG(Ai)−4∣E∣2(vol(Ai))2)=∣E∣1Ai∈A∑(eG(Ai)−G∈GE(eG(Ai)))
e G ( A i ) = ∣ { e ∈ E : e ⊆ A i } ∣ e_G\left(A_i\right)=\left|\left\{e \in E: e \subseteq A_i\right\}\right| eG(Ai)=∣{e∈E:e⊆Ai}∣ 叫做边贡献(edge contribution)——社区内的边相连的数量
E G ∈ G ( e G ( A i ) ) \mathbb{E}_{G \in \mathcal{G}}\left(e_G\left(A_i\right)\right) EG∈G(eG(Ai)) 叫做度税(degree tax)——社区节点相关的边在随机图的数量
Chung-Lu模型:
-
只需要 O ( ∣ E ∣ ) O(|E|) O(∣E∣)的时间复杂度,更常用
-
在顶点V中选择 ∣ E ∣ |E| ∣E∣条边, e = ( u 1 , u 2 ) e = (u_1, u_2) e=(u1,u2)
-
u i u_i ui根据多项式分布从V独立采样:
p ( v i ) = d e g G ( v i ) / v o l ( V ) p(v_i) = deg_G(v_i)/vol(V ) p(vi)=degG(vi)/vol(V) -
边可以重复,所以我们得到的是预期的边数而不是概率
-
我们将 C L 2 ( G ) \mathcal{C} \mathcal{L}_2(G) CL2(G)定义为使用模型2获得的图的分布:
其中图 G ′ G' G′为获得的新随机图: G ′ ( V , E ′ ) ∼ C L 2 ( G ) G'(V, E')\sim\mathcal{C} \mathcal{L}_2(G) G′(V,E′)∼CL2(G)
- 新图的度期望为:
E G ′ ∼ C L 2 ( G ) ( deg G ′ ( v i ) ) = deg G ( v i ) , 1 ≤ i ≤ n \mathbb{E}_{G^{\prime} \sim \mathcal{C} \mathcal{L}_2(G)}\left(\operatorname{deg}_{G^{\prime}}\left(v_i\right)\right)=\operatorname{deg}_G\left(v_i\right), 1 \leq i \leq n EG′∼CL2(G)(degG′(vi))=degG(vi),1≤i≤n
-
我们总是有 ∣ E ′ ∣ = ∣ E ∣ |E'|=|E| ∣E′∣=∣E∣
-
允许存在多条边
-
也允许有自环
——引理:图G的模块度函数中的 度税 是图 G ′ ( V , E ′ ) ∼ C L 2 ( G ) G'(V, E')\sim\mathcal{C} \mathcal{L}_2(G) G′(V,E′)∼CL2(G) 上 边贡献 的期望值。
我们能把这个模型推广到超图吗?
超图模块度
超图表示
背景:
- 存在比图更复杂的关联关系——涉及多个实体
- 传统图经常以两两之间的关系表示——丢失信息
超图:
- 超图 H = ( V , E ) H = (V, E) H=(V,E)其中 ∣ V ∣ = n |V | = n ∣V∣=n, ∣ E ∣ = m |E| = m ∣E∣=m
- 超边 e ∈ E e∈E e∈E 其中 e ⊆ V e⊆V e⊆V,$ |e|≥2$
- 边可以有权重
- 我们考虑无向超图
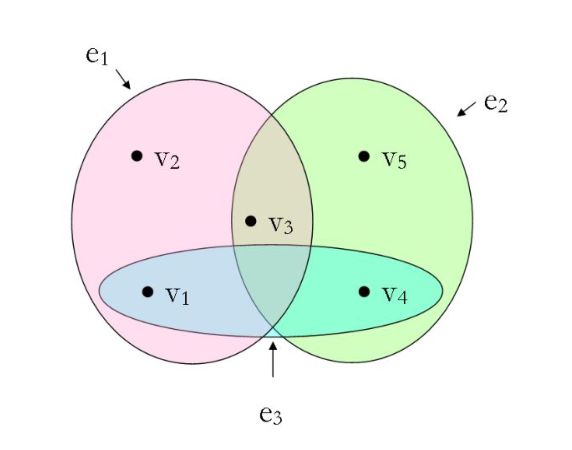
——有些数据更适合用超图建模:电子邮件交换、跟踪主机代管、分类数据建模、数值线性代数
然而在实际操作中:
- 数据科学中,很少有基于超图的算法
- 它们通常比较慢
- 有些有等效的普通图表示
——问题:我们能在超图上定义模块度函数吗?
超图Chung-Lu模型
符号说明:
考虑一个超图 H = ( V , E ) H=(V, E) H=(V,E) 其中节点为: V = { v 1 , … , v n } V=\left\{v_1, \ldots, v_n\right\} V={v1,…,vn}.、
超边 e ∈ E e \in E e∈E 是节点数大于1的节点集合 V V V 的子集:
e = { ( v , m e ( v ) ) : v ∈ V } e=\left\{\left(v, m_e(v)\right): v \in V\right\} e={(v,me(v)):v∈V}
m e ( v ) ∈ N ∪ { 0 } m_e(v) \in \mathbb{N} \cup\{0\} me(v)∈N∪{0} e e e中顶点 v v v 的多重性(权值)
∣ e ∣ = ∑ v m e ( v ) |e|=\sum_v m_e(v) ∣e∣=∑vme(v) 是超边 e e e 的大小
deg ( v ) = ∑ e ∈ E m e ( v ) \operatorname{deg}(v)=\sum_{e \in E} m_e(v) deg(v)=∑e∈Eme(v), 是节点的度
vol ( A ) = ∑ v ∈ A deg ( v ) \operatorname{vol}(A)=\sum_{v \in A} \operatorname{deg}(v) vol(A)=∑v∈Adeg(v) 是节点集合的体积
生成概率:
设 F d F_d Fd 是大小为 d d d 的节点集的集合,即:
F d : = { { ( v i , m i ) : 1 ≤ i ≤ n } : ∑ i = 1 n m i = d } . F_d:=\left\{\left\{\left(v_i, m_i\right): 1 \leq i \leq n\right\}: \sum_{i=1}^n m_i=d\right\} . Fd:={{(vi,mi):1≤i≤n}:i=1∑nmi=d}.
随机模型中的超图是通过独立随机实验生成的。 对于每个 d d d 使 ∣ E d ∣ > 0 \left|E_d\right|>0 ∣Ed∣>0, 产生 e ∈ F d e \in F_d e∈Fd 的概率为:
P H ( e ) = ∣ E d ∣ ⋅ ( d m 1 , … , m n ) ∏ i = 1 n ( deg ( v i ) vol ( V ) ) m i . P_{\mathcal{H}}(e)=\left|E_d\right| \cdot\left(\begin{array}{c} d \\ m_1, \ldots, m_n \end{array}\right) \prod_{i=1}^n\left(\frac{\operatorname{deg}\left(v_i\right)}{\operatorname{vol}(V)}\right)^{m_i} . PH(e)=∣Ed∣⋅(dm1,…,mn)i=1∏n(vol(V)deg(vi))mi.
其中 m i = m e ( v i ) m_i=m_e\left(v_i\right) mi=me(vi).
度期望:
E H ′ ∼ H [ deg H ′ ( v i ) ] = ∑ d ≥ 2 d ⋅ ∣ E d ∣ ⋅ deg ( v i ) vol ( V ) = deg ( v i ) , with vol ( V ) = ∑ d ≥ 2 d ⋅ ∣ E d ∣ . \begin{aligned} & \qquad \mathbb{E}_{H^{\prime} \sim \mathcal{H}}\left[\operatorname{deg}_{H^{\prime}}\left(v_i\right)\right]=\sum_{d \geq 2} \frac{d \cdot\left|E_d\right| \cdot \operatorname{deg}\left(v_i\right)}{\operatorname{vol}(V)}=\operatorname{deg}\left(v_i\right), \\ & \text { with } \operatorname{vol}(V)=\sum_{d \geq 2} d \cdot\left|E_d\right| . \end{aligned} EH′∼H[degH′(vi)]=d≥2∑vol(V)d⋅∣Ed∣⋅deg(vi)=deg(vi), with vol(V)=d≥2∑d⋅∣Ed∣.
——我们使用Chung-Lu模型的这种泛化(超图Chung-Lu)作为零模型(度税)来定义超图模块度
超图模块度
设 H = ( V , E ) H = (V, E) H=(V,E), A = A 1 , … A k \mathbf A = {A1,…Ak} A=A1,…Ak,是V的一个分区方案。对于尺寸大于2的边,可以使用几个定义来量化给定A的边贡献,例如:
- 一条边的所有顶点都必须属于其中一个社区——这是一个严格的定义
- 一条边的大多数顶点属于其中的一个社区
- 一条边的至少2个顶点属于同一社区——当我们用超图的2段图表示代替超图时,隐式地使用了这种方法
严格超图模块度:
A i ⊆ V A_i \subseteq V Ai⊆V 的边贡献为:
e ( A i ) = ∣ { e ∈ E ; e ⊆ A i } ∣ . e\left(A_i\right)=\left|\left\{e \in E ; e \subseteq A_i\right\}\right| . e(Ai)=∣{e∈E;e⊆Ai}∣.
A \mathbf{A} A 在 H \mathrm{H} H上的严格模块度定义为标准模块度的自然延伸,如下所示:
q H ( A ) = 1 ∣ E ∣ ∑ A i ∈ A ( e ( A i ) − E H ′ ∼ H [ e H ′ ( A i ) ] ) . q_H(\mathbf{A})=\frac{1}{|E|} \sum_{A_i \in \mathbf{A}}\left(e\left(A_i\right)-\mathbb{E}_{H^{\prime} \sim \mathcal{H}}\left[e_{H^{\prime}}\left(A_i\right)\right]\right) . qH(A)=∣E∣1Ai∈A∑(e(Ai)−EH′∼H[eH′(Ai)]).
也可以写成:
q H ( A ) = 1 ∣ E ∣ ( ∑ A i ∈ A e ( A i ) − ∑ d ≥ 2 ∣ E d ∣ ∑ A i ∈ A ( vol ( A i ) vol ( V ) ) d ) q_H(\mathbf{A})=\frac{1}{|E|}\left(\sum_{A_i \in \mathbf{A}} e\left(A_i\right)-\sum_{d \geq 2}\left|E_d\right| \sum_{A_i \in \mathbf{A}}\left(\frac{\operatorname{vol}\left(A_i\right)}{\operatorname{vol}(V)}\right)^d\right) qH(A)=∣E∣1(Ai∈A∑e(Ai)−d≥2∑∣Ed∣Ai∈A∑(vol(V)vol(Ai))d)
和超图Chung-Lu模型的关系:
我们将Chung-Lu模型II推广到超图上:
-
对于每个d,选取 ∣ E d ∣ |E_d| ∣Ed∣ 个边 e = ( u 1 , . . , u d ) e = (u_1, .., u_d) e=(u1,..,ud),其中每个 u i u_i ui 独立地从V中采样,且 p ( v i ) ∝ d e g ( v i ) p(v_i)∝deg(v_i) p(vi)∝deg(vi)
-
我们将 C L 2 ( H ) \mathcal{C} \mathcal{L}_2(H) CL2(H)定义为使用上述模型获得的超图的分布:
其中超图 H ′ H' H′为获得的新随机图: H ′ ( V , E ′ ) ∼ C L 2 ( H ) H'(V, E')\sim\mathcal{C} \mathcal{L}_2(H) H′(V,E′)∼CL2(H)
-
新超图的度期望为:
E H ′ ∼ C L 2 ( H ) ( deg H ′ ( v i ) ) = deg H ( v i ) , 1 ≤ i ≤ n \mathbb{E}_{H^{\prime} \sim \mathcal{C} \mathcal{L}_2(H)}\left(\operatorname{deg}_{H^{\prime}}\left(v_i\right)\right)=\operatorname{deg}_H\left(v_i\right), 1 \leq i \leq n EH′∼CL2(H)(degH′(vi))=degH(vi),1≤i≤n -
我们总是有 ∣ E d ′ ∣ = ∣ E d ∣ |E_d'|=|E_d| ∣Ed′∣=∣Ed∣
-
允许存在多条边
-
在一条边内可以有重复的顶点
-
——引理:超图 H H H 的模块度函数中的 度税 是超图 $ H’(V, E’)\sim\mathcal{C} \mathcal{L}_2(H)$ 上 边贡献 的期望值。
其他超图模块度:
-
我们可以根据边贡献的许多自然定义来调整度税,例如多数定义
在这种情况下 ( vol ( A ) / vol ( V ) ) d (\operatorname{vol}(A) / \operatorname{vol}(V))^d (vol(A)/vol(V))d 改成了只要大于边内节点数的一半即可
——这相当于 P ( Bin ( d , vol ( A ) / vol ( V ) ) = d ) \mathbb{P}(\operatorname{Bin}(d, \operatorname{vol}(A) / \operatorname{vol}(V))=d) P(Bin(d,vol(A)/vol(V))=d) 变成了 P ( Bin ( d , vol ( A ) / vol ( V ) ) = d / 2 ) \mathbb{P}(\operatorname{Bin}(d, \operatorname{vol}(A) / \operatorname{vol}(V))=d / 2) P(Bin(d,vol(A)/vol(V))=d/2)
超图划分的多数模块度函数为:
1 ∣ E ∣ ( ∑ A i ∈ A e ( A i ) − ∑ d ≥ 2 ∣ E d ∣ ∑ A i ∈ A P ( Bin ( d , vol ( A i ) vol ( V ) ) > d / 2 ) ) \frac{1}{|E|}\left(\sum_{A_i \in \mathbf{A}} e\left(A_i\right)-\sum_{d \geq 2}\left|E_d\right| \sum_{A_i \in \mathbf{A}} \mathbb{P}\left(\operatorname{Bin}\left(d, \frac{\operatorname{vol}\left(A_i\right)}{\operatorname{vol}(V)}\right)>d / 2\right)\right) ∣E∣1(Ai∈A∑e(Ai)−d≥2∑∣Ed∣Ai∈A∑P(Bin(d,vol(V)vol(Ai))>d/2)) -
将H分解为d-uniform 超图 H d H_d Hd,得到如下的度无关模块度函数:
q H D I ( A ) = ∑ d ≥ 2 ∣ E d ∣ ∣ E ∣ q H d ( A ) q_H^{D I}(\mathbf{A})=\sum_{d \geq 2} \frac{\left|E_d\right|}{|E|} q_{H_d}(\mathbf{A}) qHDI(A)=d≥2∑∣E∣∣Ed∣qHd(A)
这和以前一样,但是对于每个 ∣ E d ∣ > 0 |E_d| > 0 ∣Ed∣>0的d,将通过 H H H计算的体积替换为通过 H d H_d Hd计算的体积最后,我们可以推广模块化函数,以允许加权超边
超图聚类
概述
我们在超图上寻求一个划分 A = { A 1 , … , A k } ∈ P ( V ) \mathbf{A}=\left\{A_1, \ldots, A_k\right\} \in \mathcal{P}(V) A={A1,…,Ak}∈P(V), 使严格超图模块度 q H ( ) q_H() qH() 最大化.
集合 P ( V ) \mathcal{P}(V) P(V) 对于节点集 V V V 的所有划分来说是巨大的.
令 S ( H ) = { H ′ = ( V , E ′ ) ∣ E ′ ⊆ E } \mathcal{S}(H)=\left\{H^{\prime}=\left(V, E^{\prime}\right) \mid E^{\prime} \subseteq E\right\} S(H)={H′=(V,E′)∣E′⊆E} 并定义:
p : S ( H ) → P ( V ) p: \mathcal{S}(H) \rightarrow \mathcal{P}(V) p:S(H)→P(V)
这个函数将 H H H 的一个子超图映射到其连通分量在 V V V 上划分的函数.
我们定义一个等价关系:
H 1 ≡ p H 2 ⟺ p ( H 1 ) = p ( H 2 ) H_1 \equiv_p H_2 \Longleftrightarrow p\left(H_1\right)=p\left(H_2\right) H1≡pH2⟺p(H1)=p(H2)
并定义一个商集 S ( H ) / ≡ p \mathcal{S}(H) / \equiv_p S(H)/≡p.
商集(quotient set)是集合论的基本概念之一,指由集合和该集合上的等价关系导出的集合。设~是非空集合A的一个等价关系,若把以A关于~的全部等价类作为元素组成一个新的集合B,则把集合B叫做A关于~的商集合,简称为商集,记作B=A/~.
定义规范表示映射:
f : S ( H ) / ≡ p → S ( H ) f: \mathcal{S}(H) / \equiv_p \rightarrow \mathcal{S}(H) f:S(H)/≡p→S(H)
它将等价类映射到类中最大的成员: f ( [ H ′ ] ) = H ∗ f\left(\left[H^{\prime}\right]\right)=H^* f([H′])=H∗.
设 P ∗ ( V ) \mathcal{P}^*(V) P∗(V) 是 p p p 在正则表达式 H ∗ H^* H∗ 上的像(也就是输入 H ∗ H^* H∗ 输出的值域区间).
我们将证明最优解在 P ∗ ( V ) \mathcal{P}^*(V) P∗(V)中,它是一个子集,规模最大为 2 ∣ E ∣ 2^{|E|} 2∣E∣ .
示例
上述5节点的超图,对其进行划分, P ( V ) \mathcal{P}(V) P(V) 共有B5 = 52种可能
而 P ∗ ( V ) \mathcal{P}^*(V) P∗(V) 只有7种,远小于52中——缩小了搜索范围

证明
引理1:设 H = ( V , E ) H=(V, E) H=(V,E) 为超图, A = { A 1 , … , A k } \mathbf{A}=\left\{A_1, \ldots, A_k\right\} A={A1,…,Ak} 是 V V V 的分区. 如果存在 H ′ ∈ S ( H ) H^{\prime} \in \mathcal{S}(H) H′∈S(H) 使得 A = p ( H ′ ) \mathbf{A}=p\left(H^{\prime}\right) A=p(H′), 则 q H ( A ) q_H(\mathbf{A}) qH(A) 的边贡献为 ∣ E ∗ ∣ m \frac{\left|E^*\right|}{m} m∣E∗∣, 其中 E ∗ E^* E∗ 是 [ H ′ ] \left[H^{\prime}\right] [H′] 的典型代表 H ∗ H^* H∗ 的边集。——即部分子集超边的比例。
引理2:设 H = ( V , E ) H = (V, E) H=(V,E) 是一个超图, A \mathbf A A 是 V V V 的任意划分。如果 B \mathbf B B 是 A \mathbf A A 的细化, B \mathbf B B 的度税小于等于 A \mathbf A A 的度税,当且仅当 A = B \mathbf A = \mathbf B A=B 时取等号。
——我们证明了对任意分区,存在某个 H ∗ ∈ P ∗ ( V ) H^* \in \mathcal{P}^*(V) H∗∈P∗(V) 使得 p ( H ∗ ) p (H^∗) p(H∗) 是该分区的一个细化,且具有相同的边贡献。
定理:设 H = ( V , E ) H=(V, E) H=(V,E) 为超图, 如果 A ∈ P ( V ) \mathbf A∈\mathcal P(V) A∈P(V) 使模块度函数 q H ( ⋅ ) q_H(·) qH(⋅) 最大化,则 A ∈ P ∗ ( V ) \mathbf A∈\mathcal P^*(V) A∈P∗(V)
算法
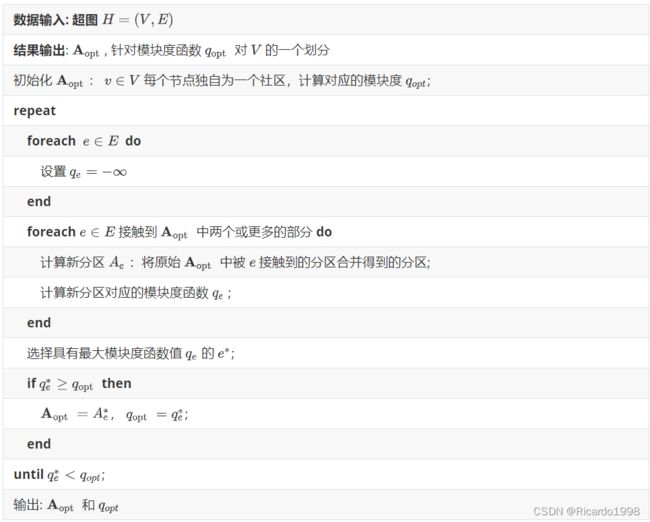
前面的结果给出了定义启发式算法的步骤:
-
循环遍历 E ′ ⊆ E E^{\prime} \subseteq E E′⊆E ,令 H ′ = ( V , E ′ ) H^{\prime}=\left(V, E^{\prime}\right) H′=(V,E′)
-
找到 H ∗ = [ H ′ ] = ( V , E ∗ ) H^*=\left[H^{\prime}\right]=\left(V, E^*\right) H∗=[H′]=(V,E∗) 并计算 q H ( ) q_H() qH() 的边贡献
-
找到 A = p ( H ∗ ) \mathbf{A}=p\left(H^*\right) A=p(H∗) 并计算 q H ( ) q_H() qH() 的度税
在 E ′ ⊆ E E^{\prime} \subseteq E E′⊆E 中寻找合适组合的简单方法:
- 贪婪随机: 把超边随机重新排列,当 q H ( ) q_H() qH() 增加时,将其按顺序添加到 E ′ E^{\prime} E′ ; 重复这一操作;
- 类CNM: 在每一步中寻找添加到 E ′ E^{\prime} E′ 的最佳边。
Hypergraph-CNM算法:
实验
——好用吗?得到的模块度是最大模块度吗?
小demo:
- 建立超图,有3个社区,20个顶点,50条边,大小为2≤d≤5
- 添加3≤k≤60条相同大小的随机边
- 在k值范围内多次运行随机算法(重复25次)
- 对于每个k,计算平均调整兰德指数;
——结果:随着添加随机边的增加,聚类结果逐渐变差,但在随机边数小于30时,聚类效果还是OK的
合成超图:
-
在不同坡度的平面上沿3条线生成噪声点
-
添加一些随机点
-
选择3或4个点的集合(超边)
- 都来自同一条线(“信号”)
- 不来自同一条线(“噪声”)
-
采样超边,其中点对齐良好,因此预期的信号与噪声的比例为2:1
我们考虑3种不同的情况:(i)主要是3-边,(ii)主要是4-边,(iii)在3和4-边之间平衡。
在(加权)普通图上通过鲁汶聚类顶点。——我们观察到相比于普通图模块度,Hcut(不相交超边的数量)和超图模块度相关性更高
DBLP超图:
——引文网络
- 小型合著者超图,有1637个节点和865个大小为2到7的超边。
- 我们比较了鲁汶(超过2-section)和超图-cnm(严格模块化)两种算法
——与Louvain算法相比,基于超图模块度 q H ( ) q_H() qH() 的算法倾向于切割更少的大边,代价是切割更多的2节点边
总结:
已有工作:
- 超图的广义Chung-Lu模型
- 超图的广义模块度函数
- 超图聚类算法的步骤
- 两种简单的启发式算法:贪婪随机和超图CNM
未来工作:
- 更直观地理解模块化函数
- 更好的、可伸缩的聚类算法
- 真实数据集实验