【爬虫】5. Ajax数据爬取
Ajax数据爬取
文章目录
- Ajax数据爬取
-
- 1. 什么是Ajax?
- 2. 基本原理
- 3. Ajax分析方法
- 4. Ajax分析和爬取实战
-
- 4.1. 准备工作
- 4.2. 爬取目标
- 4.3. 分析页面的加载逻辑
- 4.4. 用requests实现Ajax数据的爬取
有时候我们用requests抓取页面得到的结果,可能和在浏览器中看到的不一样:在浏览器中可以看到正常显示的页面数据,而使用requests得到的结果中并没有这些数据。这是因为requests获取的都是原始的HTML文档,而浏览器中的页面是JavaScript处理数据后生成的记过,这些数据有多种来源:可能是通过Ajax加载的,可能是包含在HTML文档中的,也可能是经过JavaScript和特定算法计算后生成的。
对于第一种来源——Ajax加载。数据加载时一种异步加载方式,原始页面最初不会包含某些数据,党员是页面加载完后,会再向服务器请求某个接口来获取数据,然后数据才会经过处理从而呈现在网页上,这其实时发送了一个Ajax请求。按照目前的发展形式,这种页面越来越多,数据都是通过Ajax统一加载后呈现出来的,这样使得Web开发做到前后端分离,减少服务器直接渲染带来的压力。
1. 什么是Ajax?
Ajax,全称为Asynchronous JavaScript and XML,即异步的JavaScript和XML。它不是一门编程语言,而是利用JavaScript在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页内容的技术。 想象一下你正在一个在线购物网站上浏览商品列表,突然你想要查看某个商品的详细信息。如果没有Ajax,你点击该商品,整个页面都会重新加载,你需要重新浏览商品列表,然后再找到你之前看到的位置。但是,如果使用了Ajax,当你点击商品时,只会请求获取这个商品的信息,然后将它显示在当前页面,而不会刷新整个页面。 在浏览一些网页时候,我们会发现很多网页都有“下滑查看更多”的选项,这个下滑而出现新内容的过程其实就是Ajax加载的过程。换句话说,Ajax让网页能够在不打断你的浏览的情况下,与服务器进行数据交换,使用户体验更加流畅和快速。这有助于创建更具动态性的网页,而不是每次都要刷新整个页面。
2. 基本原理
当你打开一个网页并与服务器进行交互时,通常是通过HTTP请求来获取或发送数据。传统的方式是在浏览器中点击链接或提交表单时,整个页面会重新加载,这会导致用户体验不流畅。
Ajax的基本原理是利用JavaScript来在后台发送HTTP请求,然后使用这些请求来更新页面的一部分内容,而不需要重新加载整个页面。这使得用户可以在不中断他们的操作的情况下获取或发送数据。
下面是Ajax的基本步骤:
-
触发事件: 通常是用户与页面上的元素进行交互,比如点击按钮、填写表单等。这个事件会触发JavaScript代码的执行。
-
创建XMLHttpRequest对象: JavaScript代码会创建一个XMLHttpRequest对象,这个对象允许浏览器与服务器进行通信,发送和接收数据。
-
发送请求: 使用XMLHttpRequest对象,JavaScript会发送HTTP请求到服务器。这个请求可以是GET请求(用于获取数据)或POST请求(用于发送数据)。
-
与服务器通信: 服务器收到请求后,会处理请求并返回相应的数据,通常以JSON、XML或HTML等格式。
-
更新页面: 一旦浏览器收到来自服务器的响应,JavaScript代码会解析响应数据,并将其用于更新页面的特定部分,而不是整个页面。
这可以归类于三个过程:发送请求、解析内容、渲染网页。
3. Ajax分析方法
分析样例:首先,我们用Chrome打开https://weibo.com/,然后在页面中点击鼠标右键,从弹出的菜单中选择“检查”工具进入开发者工具,接着选择Network面板如下图所示:
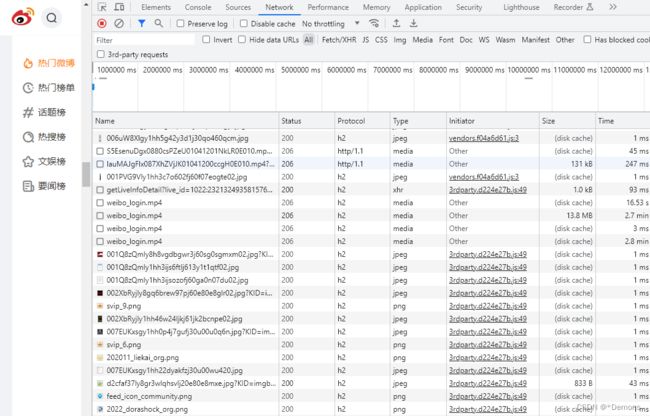
这里展示的是页面的加载过程中,浏览器和服务器之间发送请求和接收响应的所有记录。事实上,Ajax有特殊的请求类型,叫做xhr,在上图中,我们可以发现有一行请求的Type是xhr,意味着这是一个Ajax请求。
点击这个请求,可以查看里面的信息,其中Request Headers中有一个信息为X-Requested-With:XMLHttpRequest,这就标记了此请求是Ajax请求。
随后点击一下Preview,就能看到响应的内容,如下图所示,这些内容是JSON格式的,这里Chrome为我们自动做了解析:

JavaScript接收到这些诗句时候,再执行相应的渲染方法,整个页面就渲染出来了
另外,也可以切换到Response选项卡,从中观察真实的返回数据,如下图所示:

所以说,微博界面呈现给我们的真实数据并不是最原始的页面返回的,而是执行JavaScript后向后台发送Ajax请求,浏览器拿到服务器返回的数据后进一步渲染得到的。
4. Ajax分析和爬取实战
4.1. 准备工作
- 安装好Python3(最低为3.6)版本,并成功运行Python程序。
- 了解并掌握Python HTTP请求库的基本用法。
- 了解Ajax基础知识和分析Ajax的基本用法
4.2. 爬取目标
我们以一个示例网站来实战一下:https://spa1.scrape.center/, 该示例网站的数据请求时通过Ajax完成的,页面内容时通过JavaScript渲染出来的,我们需要分析页面的加载逻辑,用requests实现Ajax数据的爬取,将每一部电影分别保存到JSON文件中。
4.3. 分析页面的加载逻辑
我们先用requests直接提取页面,看看是怎么样的结果:
import requests
url = "https://spa1.scrape.center/"
response = requests.get(url)
print(response.text)
DOCTYPE html><html lang=en><head><meta charset=utf-8><meta http-equiv=X-UA-Compatible content="IE=edge"><meta name=viewport content="width=device-width,initial-scale=1"><link rel=icon href=/favicon.ico><title>Scrape | Movietitle><link href=/css/chunk-700f70e1.1126d090.css rel=prefetch><link href=/css/chunk-d1db5eda.0ff76b36.css rel=prefetch><link href=/js/chunk-700f70e1.0548e2b4.js rel=prefetch><link href=/js/chunk-d1db5eda.b564504d.js rel=prefetch><link href=/css/app.ea9d802a.css rel=preload as=style><link href=/js/app.17b3aaa5.js rel=preload as=script><link href=/js/chunk-vendors.683ca77c.js rel=preload as=script><link href=/css/app.ea9d802a.css rel=stylesheet>head><body><noscript><strong>We're sorry but portal doesn't work properly without JavaScript enabled. Please enable it to continue.strong>noscript><div id=app>div><script src=/js/chunk-vendors.683ca77c.js>script><script src=/js/app.17b3aaa5.js>script>body>html>
通过上面的结果我们可以发现源码再引用一些JavaScript和CSS文件,并没有观察到任何关于电影的信息。这说明我们看到的整个页面都是通过JavaScript渲染出来的,浏览器执行了HTML中引用的JavaScript文件,JavaScript通过调用一些数据加载和页面渲染方法,才最终呈现了我们所看到的网页。这些电影数据一般是通过Ajax加载的,而且我们用前面的方法查看Type为xhr的请求发现也的确是通过Ajax加载的,JavaScript在后台调用Ajax数据接口,得到数据之后渲染出来,所以想爬取这个界面我们直接爬取Ajax接口,再获取数据就行了。
打开开发者工具,切换到Network面板切换到XHR选项卡作筛选,接着重新刷新界面再切换到第2页、第3页、第4页,我们可以监听到其他的Ajax请求,这些请求时我们切换页面所接收到的请求,点开每一个Ajax请求,观察URL、参数、和响应内容时怎么样的。
https://spa1.scrape.center/api/movie/?limit=10&offset=0
https://spa1.scrape.center/api/movie/?limit=10&offset=10
https://spa1.scrape.center/api/movie/?limit=10&offset=20
https://spa1.scrape.center/api/movie/?limit=10&offset=30
通过上述链接,我们可以发现limit和offset这两个参数的值有规律的发生改变,分析略,之后代码用好这两个参数就行了。
接着我们来观察里面的内容,这里以第1页的Response的部分为例(未截全):
{
"count": 102,
"results": [
{
"id": 1,
"name": "霸王别姬",
"alias": "Farewell My Concubine",
"cover": "https://p0.meituan.net/movie/ce4da3e03e655b5b88ed31b5cd7896cf62472.jpg@464w_644h_1e_1c",
"categories": [
"剧情",
"爱情"
],
"published_at": "1993-07-26",
"minute": 171,
"score": 9.5,
"regions": [
"中国内地",
"中国香港"
]
},
{
"id": 2,
"name": "这个杀手不太冷",
"alias": "Léon",
"cover": "https://p1.meituan.net/movie/6bea9af4524dfbd0b668eaa7e187c3df767253.jpg@464w_644h_1e_1c",
"categories": [
"剧情",
"动作",
"犯罪"
],
"published_at": "1994-09-14",
"minute": 110,
"score": 9.5,
"regions": [
"法国"
]
},
{
"id": 3,
"name": "肖申克的救赎",
"alias": "The Shawshank Redemption",
"cover": "https://p0.meituan.net/movie/283292171619cdfd5b240c8fd093f1eb255670.jpg@464w_644h_1e_1c",
"categories": [
"剧情",
"犯罪"
],
"published_at": "1994-09-10",
"minute": 142,
"score": 9.5,
"regions": [
"美国"
]
},
}
我们要注意的是results字段,和里面的id数据,其中id的值正好对应了每一部电影的顺序。所以我们点开电影的详情界面,发现它们的链接也是有规律的:
https://spa1.scrape.center/detail/1
https://spa1.scrape.center/detail/2
https://spa1.scrape.center/detail/3
最后就是分析电影详情页面的数据了。点开第一部电影的详情数据,我们发现监视窗里出现了一个1/为名字的请求,点开就是电影详情界面的json数据了,而且请求名正好是电影的顺序名。
所以现在就分析完成了。
4.4. 用requests实现Ajax数据的爬取
下面是代码示例:
import requests
import logging
import json
from os import makedirs
from os.path import exists
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s: %(message)s')
INDEX_URL = 'https://spa1.scrape.center/api/movie/?limit={limit}&offset={offset}'
DETAIL_URL = 'https://spa1.scrape.center/api/movie/{id}'
LIMIT = 10
TOTAL_PAGE = 10
RESULTS_DIR = 'results'
exists(RESULTS_DIR) or makedirs(RESULTS_DIR)
def scrape_api(url):
logging.info('scraping %s...', url)
try:
response = requests.get(url)
if response.status_code == 200:
return response.json()
logging.error('get invalid status code %s while scraping %s',
response.status_code, url)
except requests.RequestException:
logging.error('error occurred while scraping %s', url, exc_info=True)
def scrape_index(page):
url = INDEX_URL.format(limit=LIMIT, offset=LIMIT * (page - 1))
return scrape_api(url)
def scrape_detail(id):
url = DETAIL_URL.format(id=id)
return scrape_api(url)
def save_data(data):
name = data.get('name')
data_path = f'{RESULTS_DIR}/{name}.json'
json.dump(data, open(data_path, 'w', encoding='utf-8'),
ensure_ascii=False, indent=2)
def main():
for page in range(1, TOTAL_PAGE + 1):
index_data = scrape_index(page)
for item in index_data.get('results'):
id = item.get('id')
detail_data = scrape_detail(id)
logging.info('detail data %s', detail_data)
save_data(detail_data)
if __name__ == '__main__':
main()
这里我来解释一下下面这部分是做什么的:
RESULTS_DIR = 'results'
exists(RESULTS_DIR) or makedirs(RESULTS_DIR)
这行代码的作用是:如果名为 'results' 的目录不存在,就创建这个目录,用于保存爬取到的结果文件。如果目录已经存在,这行代码则不会执行任何操作。这样可以确保在开始爬取之前,确保结果保存的目录是存在的,以免出现问题。