Netty 入门
打广告不费电。本文结合右侧文章服用更佳 IO 的五种模型
基于 TCP 和 UDP协议实现的 Socket 网络通信
是怎样的一个流程

基于 TCP 协议实现的 Socket 通信是有连接的,而传输数据是要通过三次握手来实现数据
传输的可靠性,且传输数据是没有边界的,采用的是字节流模式。
基于 UDP 协议实现的 Socket 通信,客户端不需要建立连接,只需要创建一个套接字发送
数据报给服务端,这样就不能保证数据报一定会达到服务端,所以在传输数据方面,基于
UDP 协议实现的 Socket 通信具有不可靠性。UDP 发送的数据采用的是数据报模式,每个
UDP 的数据报都有一个长度,该长度将与数据一起发送到服务端
通过对比,我们可以得出优化方法:为了保证数据传输的可靠性,通常情况下我们会采用
TCP 协议。如果在局域网且对数据传输的可靠性没有要求的情况下,我们也可以考虑使用
UDP 协议,毕竟这种协议的效率要比 TCP 协议高。
问题:什么是 I/O?为什么需要这些 I/O 模型?
所谓的I/O 就是计算机内存与外部设备之间拷贝数据的过程
串行设计
:服务端在接收消息之后,存在着编码、解码、读取和发送等链路操作。如果这些
操作都是基于并行去实现,无疑会导致严重的锁竞争,进而导致系统的性能下降。为了提升
性能,Netty 采用了串行无锁化完成链路操作,Netty 提供了 Pipeline 实现链路的各个操
作在运行期间不进行线程切换。
零拷贝
我们提到了一个数据从内存发送到网络中,存在着两次拷贝动作,先
是从用户空间拷贝到内核空间,再是从内核空间拷贝到网络 I/O 中。而 NIO 提供的
ByteBuffer 可以使用 Direct Buffers 模式,直接开辟一个非堆物理内存,不需要进行字节
缓冲区的二次拷贝,可以直接将数据写入到内核空间
一些问题
什么是进程和线程,
什么是虚拟内存和物理内存,
什么是用户空间和内核空间,
线程的阻塞到底意味着什么,
内核又是如何唤醒用户线程的。
回复: 同步异步可以理解为谁主动,同步就是A问B要东西,总是A主动”伸手“问B要。异步就是A向B注册一个需求,货到了B主动“伸手”把货交给A。阻塞队列在阻塞一个线程时,会有系统调用,有系统调用内核就要参与,只是这里的阻塞跟IO的阻塞是两回事。
线程的同步一般指对共享变量的互斥访问。IO模型的同步是指应用和内核的交互方式。
NIO 和 NIO.2 最大的区别是,一个是同步一个是异步。异步最大的特点
是,应用程序不需要自己去触发数据从内核空间到用户空间的拷贝。
为什么是应用程序去“触发”数据的拷贝,而不是直接从内核拷贝数据呢?这是因为应用程
序是不能访问内核空间的,因此数据拷贝肯定是由内核来做,关键是谁来触发这个动作。
是内核主动将数据拷贝到用户空间并通知应用程序。还是等待应用程序通过 Selector 来查
询,当数据就绪后,应用程序再发起一个 read 调用,这时内核再把数据从内核空间拷贝到
用户空间。
那pipeline,eventloop,channel之间的关系呢?
回复:
pipeline:工厂的流水线
eventloop: 操作流水线工序的实际干活的工人
channel: 多套流水线,一个channel配一套流水线(pipeline)。
工人(eventloop)共享。
信号驱动式 I/O与其他io模型的有啥不一样?
回复: 可以把信号驱动io理解为“半异步”,非阻塞模式是应用不断发起read调用查询数据到了内核没有,而信号驱动把这个过程异步化了,应用发起read调用时注册了一个信号处理函数,其实是个回调函数,数据到了内核后,内核触发这个回调函数,应用在回调函数里再发起一次read调用去读内核的数据。所以是半异步。
问题:为什么不选择异步 IO ?
通过上面的分析,异步 IO 才是最牛的 IO 模型,那么,我们为什么不选择异步 IO 呢?
回答:因为异步 IO 在 linux 上还不成熟,而我们的服务器通常都是 linux ,所以现在大部分框架都不是很支持异步IO ,包括 Netty 之前实现了一版,但是后面给废弃掉。
问题:什么是 NIO?
回答:NIO 模型中的 N 一般指代 Non-blocking ,即非阻塞的意思, NIO 即非阻塞 IO 的意思。
广义上来说, NIO 包括 Non-blocking IO (非阻塞 IO )、 IO Multiplexing ( IO 多路复用)、 Signal-DrivenIO (信号驱动 IO )。
狭义上来说, NIO 仅指 Non-blocking IO 。
Java NIO 中的 N 是指 New ,即新的意思, Java NIO 即新的 IO ,是相对于 OIO (Old IO) 或者 BIO(Blocking IO) 来说的,在 Java 的实现中是基于 IO Multiplexing 模型实现的。
补充:本文背景里所提及的 NIO,是狭义的NIO,指 Non-blocking IO。
New IO , Java 中使用 IO 多路复用技术实现,放在 java.nio 包下, JDK1.4 引入
多路复用的概念:
多个 IO 操作共同使用一个 selector (选择器)去询问哪些 IO 准备好了, selector 负责通知那些数据准备好了的 IO ,它们再自己去请求内核数据。
问题:什么是 Selector?
回答:Selector 是一个多路复用器
补充:Selector 和 Channel 是一对多的关系,一个 Selector 可以为多个 Channel 服务,监听它们准备好的事件。
selector 选择器概念细化
选择器 selector 是什么呢 ? 选择器 和通道 的关系又是什么?
简单来说:选择器的使命是完成IO的多路复用。一个通道代表一条连接通路,通过选择器可以同时监控多个通道的IO(输入输出)状况。选择器和通道的关系,是监控和被监控的关系。
选择器需要提供独特的API,能够让调用方选择 select 所 监控的通道拥有哪些已经准备好的,就绪的IO操作时间。 选择器 等价于 一个 监视者。
一般而言,一个单线程处理一个选择器,一个选择器可以监控很多的通道。通过选择器,一个单线程可以处理数百,数千,数万,甚至更多的通道。在极端情况下(数万个连接),只用一个线程就可以处理所有的通道,这样会大量减少线程之间上下文切换的开销。
通道和选择器之间的关系,通过 register 的方式完成。 调用通道的 Channel.register(Selector sel , int ops) 方法。可以将通道实例注册到一个选择器中。 register 方法有两个参数, 第一个参数指定通道注册到的选择器实例, 第二个参数,指定选择器要监控的IO的事件类型。
IO事件类型, 可读 , 可写, 连接, 接收。 是一种 就绪状态。
什么是IO事件?
这里是指 通道 channel 中的 某个IO操作的一种就绪状态,表示通道 具备完成某个 IO操作的条件。
一个通道,并不一定要支持所有的四种IO事件。例如服务器监听通道ServerSocketChannel,仅仅支持Accept(接收到新连接)。而 SocketChannel 传输通道不支持该事件。
先来点开胃菜, Java NIO 热热身。Java NIO浅析
简单再回顾下 NIO 编程的大致过程:
1 先是启动 ServerSocketChannel ,并注册 Accept 事件;
2 轮询调用 Selector 的 select () 方法, select () 方法还有两个兄弟 ——selectNow () , select (timeout) ;
3 调用 Selector 的 selectedKeys () 方法,拿到轮询到的 SelectionKey ;
遍历这些 selectedKeys ,处理它们感兴趣到的事件;
4 如果是 Accept 事件,则从 SelectionKey 中取出 ServerSocketChannel ,并 accept () 出来一个SocketChannel ;
5 把这个 SocketChannel 也注册到 Selector 上,并注册 Read 事件;
Java NIO 编程的 坑
1.API 复杂难用,尤其是 Buffer 的指针切来切去的,反人类设计
2 需要掌握丰富的知识,比如多线程和网络编程
3 可靠性无法保证,断线重连、半包粘包、网络拥塞统统需要自己考虑
4.空轮询 bug , CPU 又 100% 了,一直未根除此问题
补充一些小知识:
Tomcat
2005 年前后, BIO 时代的霸者 ——Tomcat ,意识到了 Grizzly 带来的危机,逆势发布了 6.0 版本,它也开始支持 NIO 了,同样使得它的性能有了质的飞跃。 但是, Tomcat 的 NIO 通信层并没有从它本身的代码中解耦出来,形成了一种 “ 老奶奶裹脚,又臭又长 ” 的代码,这 也使得它在 NIO 的浪潮中只能保住自己的一亩三分地,并不具有进攻他人的属性。
补充一个写的不错的文章 : Selector
读完种种,我们 需要弄明白java NIO 的 几个概念
1.channel 是什么
2.Buffer 是什么
3.selecor 是什么
4.channel buffer selector 三者的关系是什么 ,如何联合使用?
如果只能记住一件事,记住这点: Java 中的 NIO 使用的是 IO 多路复用技术实现的。
再来点广东的老火汤润润。我们如何理解Reactor 呢?Netty与Reactor模式
大牛的讲解 Doug Lea大神(不知道Doug Lea?看看JDK集合包和并发包的作者吧)在《Scalable IO in Java》
如果觉得,文章太长不想看的话,来张非常简单的图。 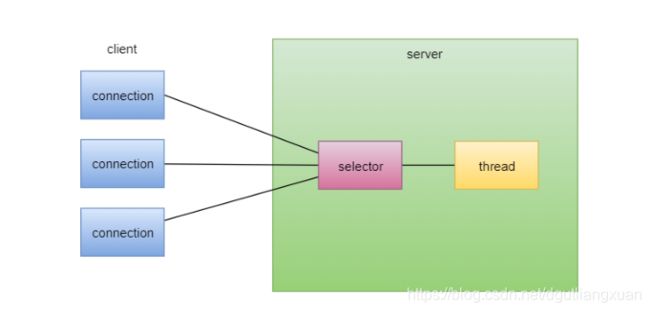
一个重要但不是很紧急的概念 :内核空间 和用户空间
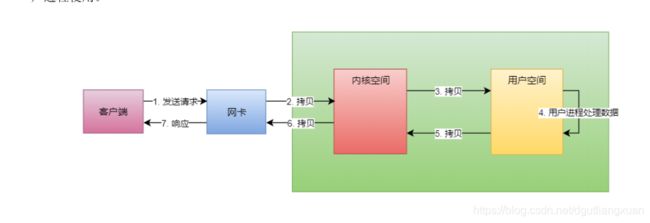
操作系统的核心是内核,它独立于普通的应用程序,可以访问受保护的内核空间,也有访问底层硬件设备的所有权限。为了保护内核的安全,现在操作系统一般都强制用户进程不能直接操作内核,所以操作系统把内存空间划分成了两个部分:内核空间和用户空间。
所以,当我们使用 TCP 发送数据的时候,需要先将数据从用户空间拷贝到内核空间,再由内核操作将数据从内核空间发送出去;当我们使用 TCP 读取数据的时候,数据先在内核空间准备好,再从内核空间拷贝到用户空间供用户进程使用。
这就好比,当我们在饭店吃饭的时候,先在客厅点好菜,再由服务员把我们的菜单传递进厨房;当厨房做好了菜,再从厨房由服务员传递到客厅一样。
所以,一次 IO 的读取操作分为两个阶段(写入操作类似):
1 等待内核空间数据准备阶段
2 数据从内核空间拷贝到用户空间
Netty 时代: 为什么用Netty
回答:
Netty做的更好之处:1.规避JDK NIO bug 2.API更友好更强大
3.隔离变化,屏蔽细节 1.帮你解决协议编解码问题
2 解决传输过程粘包半包问题 3流量控制 4帮你解决各种异常
现在这个时代是属于 Netty 的,大家越来越喜欢 Netty ,以前使用 MINA 等其它通信框架的也在逐步转换为 Netty ,说 Netty 统一了 Java 领域中的网络通信一点也不为过,在很多领域都能见到它的身影:
1 框架, gRPC 、 Dubbo 、 Spring WebFlux 、 Spring Cloud Gateway
3 大数据, Spark 、 Hadoop 、 Flink
2 消息队列, RocketMQ 、 ActiveMQ
4 搜索引擎, Elasticsearch
5 分布式协调器, Zookeeper
6 数据库, Cassandra 、 Neo4j
7 工具类, async-http-client
8 日志, Graylog
9 负载均衡, Ribbon
Netty的三大块:其各个核心模块主要的职责如下:
1 内存管理主要高效的内存管理,包含内存分配,内存回收。
2 网通通道复制网络通信,例如实现对NIO、OIO等底层JAVA API 的封装,简化网络编程模型。3 线程模型提供高效的线程协作模型。
启示: 如果我们设计一个网络工具包,我们是否可以有如此好的架构设计和模块设计呢? 本文主要是侧重解决线程模型。我们初期设计不好,也不要气馁,本质的知识点。掌握了,自然就会飞速成长。
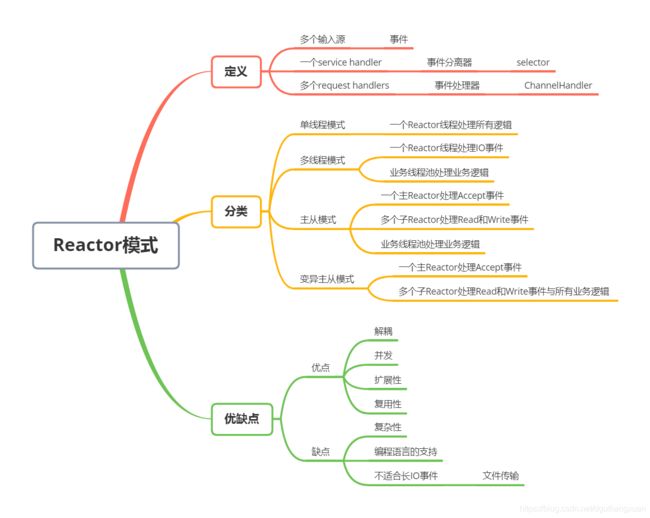
Reactor反应器模式
反应器模式由:Reactor 反应器线程 Handler处理器两大角色组成
1.Reactor反应器线程的职责:负责响应IO事件,并且分发到Handler处理器
2.Handler处理器的职责:非阻塞的执行业务处理逻辑。
反应器模式 和 生产者消费者模式 对比
相似之处:在生产者消费者模式中,一个或者多个生产者将事件加入到一个队列中,一个或多个消费者主动地从这个队列中提取(Pull)事件来处理
不同之处在于:反应器模式是基于查询的。没有专门的队列去缓冲存储IO事件。查询到IO事件之后。反应器会根据不同IO选择器(事件)将其分发给对应Handler处理器来处理
反应器模式 和 观察者模式 对比
相似之处:在反应器模式中,当查询到IO事件后,服务处理程序使用 单路/多路 分发(Dispatch)策略,同步地分发这些IO事件。观察者模式 也被称作 发布/订阅模式。它定义了一种依赖关系。让多个观察者同事监听某一个主题。这个主题对象在状态发生变化时候,会通知会有观察者。他们能够执行相应的处理
不同之处:在反应器模式中,Handler 处理器实例 和 IO事件 (选择键)的订阅关系。基本上是一个事件绑定到一个 Handler处理器中; 每一个IO事件(选择键)被查询后。
上面铺垫完,开始说我们的 Reactor 反应堆
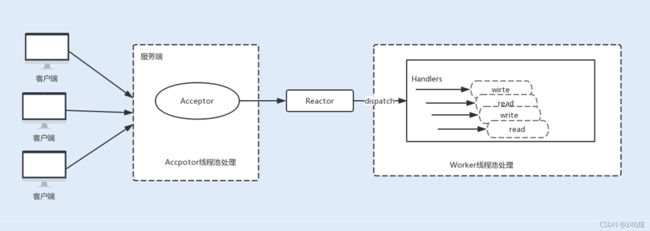
Reactor 单线程模式
Reactor 单线程模式应运而生,使用一个线程就可以处理大量的事件。
 Reactor 单线程模式,就像一个饭店只有老板一个人一样,既要负责接待客人,又要当厨师,又要当服务员,一个人干所有的事,效率势必非常低下。在服务端,对于网络请求有三种不同的事件: Accept 事件、 Read 事件、 Write 事件,对应于上图中的 acceptor 、read 、 send
Reactor 单线程模式,就像一个饭店只有老板一个人一样,既要负责接待客人,又要当厨师,又要当服务员,一个人干所有的事,效率势必非常低下。在服务端,对于网络请求有三种不同的事件: Accept 事件、 Read 事件、 Write 事件,对应于上图中的 acceptor 、read 、 send
Connect 事件属于客户端事件。
为什么 acceptor ( Accept 事件处理器)是双向箭头,而 read 和 send 是单向箭头呢?因为服务端启动的时候是先注册 Accept 事件到 Reactor 上,当收到客户端连接时,也就是 Accept 事件时,才会注册 Read 和 Write事件,所以 acceptor 是双向的, Reactor 不仅要向 acceptor 分发 Accept 事件, acceptor 也要向 Reactor 注册 Read 和 Write 事件
一个 Reactor 就相当于一个事件分离器,而单线程模式下,所有客户端的所有事件都在一个线程中完成,这就出现了一个新的问题,如果哪个请求有阻塞,直接影响了所有请求的处理速度,所以,自然而然就进化出了 Reactor 的多线程模式。
早期都是单核 CPU ,一个请求阻塞会影响所有请求,注意,是阻塞,而不是处理缓慢,处理缓慢是有大量的计算,这时候即使启动多个线程也无法提高其它请求处理的速度
Reactor 多线程模式
Reactor 多线程模式,还是把 IO 事件放在 Reactor 线程中来处理,同时,把业务处理逻辑放到单独的线程池中来处理,这个线程池我们称为工作线程池( Worker Thread Pool )或者业务线程池
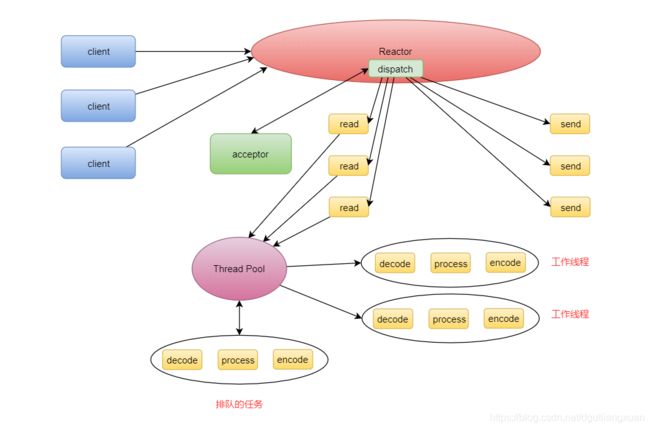 此时,如果业务处理逻辑中有 IO 阻塞,则不会影响其它请求的处理,能很大程度提高系统的并发量。Reactor 多线程模式,就像饭店中老板只负责主要事务,比如,接待客人、接收客人的下单请求等,具体的事务交给服务员去处理。
此时,如果业务处理逻辑中有 IO 阻塞,则不会影响其它请求的处理,能很大程度提高系统的并发量。Reactor 多线程模式,就像饭店中老板只负责主要事务,比如,接待客人、接收客人的下单请求等,具体的事务交给服务员去处理。
问题:但是,这种模式还不够完美,一个客户端连接过程需要三次握手,是一个比较耗时的操作,将 Accept 事件和 Read事件与 Write 事件放在一个 Reactor 中来处理,明显降低了 Read 和 Write 事件的响应速度。而且,一个 Reactor只有一个线程,也无法利用多核 CPU 的性能提升。因此,又自然而然的出现了 Reactor 主从模式。简单来说:这里是为了解决两个问题, 1.accept事件耗时 2.分工问题。
Reactor 主从模式
Reactor 主从模式把 Accept 事件的处理单独拿出来放到主 Reactor 中来处理,把 Read 和 Write 事件放到子Reactor 中来处理,而且,像这样的子 Reactor 我们可以启动多个,充分利用多核 CPU 的资源。这里我不是很认同。我觉得是逻辑分工的问题。这个给读者自己分辨。
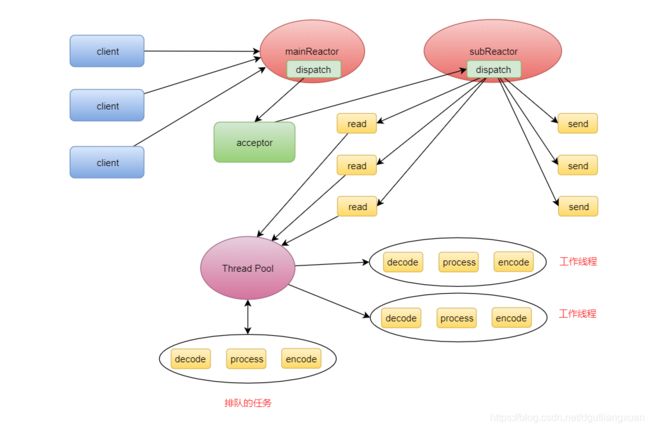
Reactor 主从模式,就像饭店中的老板只负责客人接待这一件事,其它事务全部交给服务员来处理,而且服务员也可以按区域划分,比如 1 号服务员负责 1 到 5 号包厢, 2 号服务员负责 6 到 10 号包厢,极大地提高了效率。
在 Reactor 主从模式中,我们依然把业务逻辑的处理放到业务线程池中来处理,但是,既然子 Reactor 本身就可以启动多个,所以,我们直接让子 Reactor 池化,利用子 Reactor 本身的线程来处理业务逻辑,可不可以呢?
Reactor 变异主从模式的使用
Reactor 变异主从模式,业务线程池和子 Reactor 池合并为一,所以,在 Netty 中, Handler 放在子 Reactor 池中处理即可,默认情况, Netty 也是使用的这种模式。
EventLoopGroup bossGroup = new NioEventLoopGroup(1); // 一个主 Reactor
EventLoopGroup workerGroup = new NioEventLoopGroup(); // 多个子 Reactor
ServerBootstrap serverBootstrap = new ServerBootstrap();
serverBootstrap.group(bossGroup, workerGroup);
问题:如何理解 Netty Reactor主从多线程模式的实现
回答:首先,主从按selector是否分开来区分(而不是用是否共用一个线程来划分)比较容易理解点:主,接受连接,从,处理连接上的事;
主一般现在只绑定一个端口所以是单线程,但是,从是多线程,所以还是叫主从多线程.
补充:关于多线程reactor的理解,区别主从最大的区别是,接受连接的处理是不是独立线程处理的,还是和其他事件混合的。会发现有三套线程了。一套是接受连接的.一套是收发数据的,一套是具体业务处理了。
延伸问题:main reactor只能用到一个线程的话是不是代表bossGroup只有一个在工作,那么这样和多线程reactor不就一样了吗?
回答: bind几个端口启动,就用到几个,所以一般确实只能用到1个。主从reactor, 也是reactor,也是多线程(因为worker线程肯定有,所以至少2个),但是区别在于,主从reactor是有分工的多线程,非主从的,线程没有角色分工,都是所有的事情都做。
问题:为什么只能有一个主 Reactor 呢?启动多个主 Reactor 可不可以呢
回答:TODO
Reactor 模式的优点和缺点
好了, Reactor 的几种模式介绍完了,但是, Reactor 并不是一剂万能药,所以我们有必要了解它的的优点和缺点,综合对比,我们才能决定要不要使用它。
首先,我们来看看它的优点,也是 Reactor 的主要卖点:
- 能够解耦模块,将 IO 操作与业务逻辑解耦;
- 能够提高并发量,充分利用 CPU 资源;
- 可扩展性好,简单地增加子 Reactor 的数量就能很好地扩展;
- 可复用性好, Reactor 框架本身不与具体的业务逻辑挂钩,复用性好;
等等。然而 ,同样地,它也有一些缺点 - 相比于传统的简单模式, Reactor 增加了一定复杂度,增加了学习成本、试错成本和调试成本;
- 需要编程语言支持事件分离器,比如 Java 中的 Selector ,如果自己实现不现实;
- 多个客户端共用同一个 Reactor ,如果有文件传输这种耗时的 IO 操作, 不适合使用 Reactor 模式。
问题:maingroup为什么一个线程解释有点模糊呐??
回复: 可以换个思路理解,main group相当于迎宾,一个门就需要一个迎宾站岗就行了。这里的门就是服务器监听的端口。大多服务器不都是只监听一个端口么?所以只有一个门,只有一个迎宾(线程)服务就行了。而worker group才是干活的人,要多线程。
有些问题想请教一下:
1 netty实现的Nio并非是完全非阻塞的io模型。
2 请问这句话怎么理解呢?
3 如果这句话说的对,那阻塞发生在哪呢?
4 经常听到select多路复用,请问这又如何理解呢?
回复: 感觉这个说法有点较真,如果非说是对的,只能这么理解,比如NIO当中select本身就是阻塞的;再比如关闭socket,如果so_linger开启时,也可能会阻塞会等等。
多路复用从特征上看:多个channel能复用一个线程来处理,区别于多路不复用:多个channel,每个channel,一个线程来处理。
从本质上看,就是NIO的事件注册,扫描,处理的一套机制了。
问题:对socketchannle, bossgroup, workergroup 和 迎宾的例子没办法完全匹配起来。
回答:boss迎宾或者老板,worker服务员或者员工,前者相当于给后者接活,对于到netty里面就是:boss处理连接,连接好了后,让worker服务于这个连接,这个连接本身就是socket.相当于客人。
问题:一个reactor线程能同时最多管理多少个socket或channel , 即一个eventloop绑定的channel有没有上限。
回答:没有限制,这个event loop的没消费的任务的最大数倒是可以通过参数控制,本身它没限制绑定多少channel.
问题:给Channel 分配NIOEventLoop,有其它Channel在使用,会出现什么情况?
回答:没关系,nio event loop里面就一个线程在用,可以理解就是单线程的,本来设计就是一个event loop 给多个channel用,否则一个人一个,那最终不就爆炸了么,和传统的那个一个连接一个线程就一样了,那个loop单词很形象,单线程,死循环。处理绑定上它上面的多个channel的事件。
问题:为什么有channel 还需要Pipe。
回答:做的事情不一样,pipe是通过包含两个channel一个读一个写(一个本地的tcp连接),来做了一个管道,作用是运输了数据。,你仅仅一个channel做不了这个效果,所以pipe相当于借助了channel来提供了一个好用的功能给大家。所以pipe需要channel.所以你说的问题是为什么还需要pipe.等于说我有晾袜子的小夹子,为什么还需要买那种上面有很多小夹子的那种圆盘式的晾晒的(应该都买了吧),能干掉别的事,比如二个小夹子可以加个小衣服什么的,不知道我可解释清楚了。
Netty是如何解决上面的问题呢?
看看此篇:Netty 的线程模型是什么
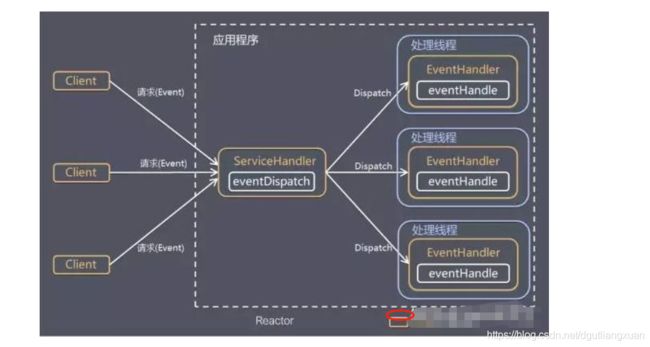
综上所述,简单理解Reactor 一图胜过千言 , Reactor 模型 如下 。 切记,Reactor 与Netty 是不相关的,是两种不同的东西。
我们来看看一个简单的 Netty Demo
/*
* Copyright 2012 The Netty Project
*
* The Netty Project licenses this file to you under the Apache License,
* version 2.0 (the "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at:
*
* https://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
* WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
* License for the specific language governing permissions and limitations
* under the License.
*/
package io.netty.example.echo;
import io.netty.bootstrap.ServerBootstrap;
import io.netty.channel.ChannelFuture;
import io.netty.channel.ChannelInitializer;
import io.netty.channel.ChannelOption;
import io.netty.channel.ChannelPipeline;
import io.netty.channel.EventLoopGroup;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.SocketChannel;
import io.netty.channel.socket.nio.NioServerSocketChannel;
import io.netty.handler.logging.LogLevel;
import io.netty.handler.logging.LoggingHandler;
import io.netty.handler.ssl.SslContext;
import io.netty.handler.ssl.SslContextBuilder;
import io.netty.handler.ssl.util.SelfSignedCertificate;
/**
* Echoes back any received data from a client.
*/
public final class EchoServer {
static final boolean SSL = System.getProperty("ssl") != null;
static final int PORT = Integer.parseInt(System.getProperty("port", "8007"));
public static void main(String[] args) throws Exception {
// Configure SSL.
final SslContext sslCtx;
if (SSL) {
SelfSignedCertificate ssc = new SelfSignedCertificate();
sslCtx = SslContextBuilder.forServer(ssc.certificate(), ssc.privateKey()).build();
} else {
sslCtx = null;
}
// Configure the server.
// 1. 声明线程池
EventLoopGroup bossGroup = new NioEventLoopGroup(1);
EventLoopGroup workerGroup = new NioEventLoopGroup();
final EchoServerHandler serverHandler = new EchoServerHandler();
try {
// 2. 服务端引导器
ServerBootstrap b = new ServerBootstrap();
// 3. 设置线程池
b.group(bossGroup, workerGroup)
// 4. 设置ServerSocketChannel的类型
.channel(NioServerSocketChannel.class)
// 5. 设置参数
.option(ChannelOption.SO_BACKLOG, 100)
// 6. 设置ServerSocketChannel对应的Handler,只能设置一个
.handler(new LoggingHandler(LogLevel.INFO))
// 7. 设置SocketChannel对应的Handler
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline p = ch.pipeline();
if (sslCtx != null) {
p.addLast(sslCtx.newHandler(ch.alloc()));
}
// 可以添加多个子Handler
//p.addLast(new LoggingHandler(LogLevel.INFO));
p.addLast(serverHandler);
}
});
// 8. 绑定端口
// Start the server.
ChannelFuture f = b.bind(PORT).sync();
// Netty 的 Channel 跟 Java 原生的 Channel 是否有某种关系?
// bind () 是否调用了 Java 底层的 Socket 相关的操作?
// Netty 服务启动之后 ChannelPipeline 里面长什么样?
// 9. 等待服务端监听端口关闭,这里会阻塞主线程
// Wait until the server socket is closed.
f.channel().closeFuture().sync();
} finally {
// 10. 优雅地关闭两个线程池
// Shut down all event loops to terminate all threads.
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
}
基本过程十分简单:
1 初始化创建2个NioEventLoopGroup,其中BossGroup用于Accetpt连接建立事件并分发请求, WorkerGroup用于处理I/O读写事件和业务逻辑
(通俗来说,就是创建两个线程池。两批人。 一个负责 处理连接事件和分发请求 ,一个负责处理io读写 和 业务处理 )
2 基于ServerBootstrap(服务端启动引导类),配置EventLoopGroup、Channel类型,连接参数、配置入站、出站事件handler
3 绑定端口,开始工作。
图文并茂,理解不累。服务端 Netty 的工作流程 如下 :
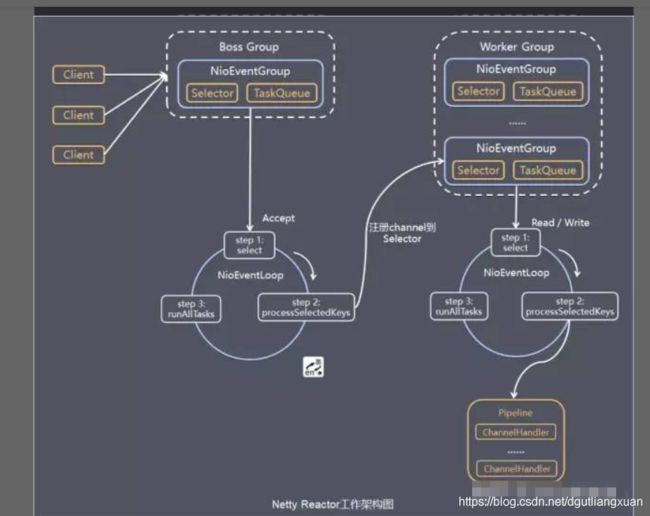
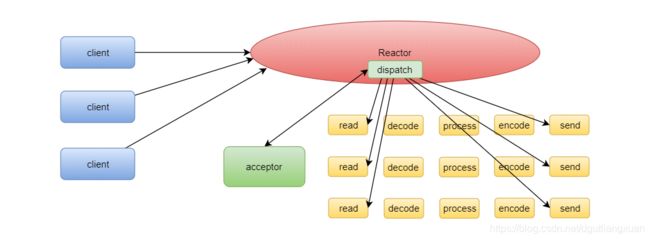
该图解读:
Netty主要基于主从Reactors多线程模型(如下图)做了一定的修改,
其中主从Reactor多线程模型有多个Reactor:MainReactor和SubReactor:
1 MainReactor负责客户端的连接请求,并将请求转交给SubReactor;
2 SubReactor负责相应通道的IO读写请求;
非IO请求(具体逻辑处理)的任务则会直接写入队列,等待worker threads进行处理。
虽然Netty的线程模型基于主从Reactor多线程**,
借用了MainReactor和SubReactor的结构,但是实际实现上,SubReactor和Worker线程在同一个线程池中:
也就是下面4行代码。
EventLoopGroupbossGroup=newNioEventLoopGroup();
EventLoopGroupworkerGroup=newNioEventLoopGroup();
ServerBootstrapserver=newServerBootstrap();
server.group(bossGroup,workerGroup).channel(NioServerSocketChannel.class)
上面代码中的bossGroup 和workerGroup是Bootstrap构造方法中传入的两个对象,
这两个group均是线程池。
其中, bossGroup线程池则只是在bind某个端口后,获得其中一个线程作为MainReactor,专门处理端口的accept事件,每个端口对应一个boss线程,
一般我们只绑定一个端口,所以boss线程往往只有一个。
workerGroup线程池会被各个SubReactor和worker线程充分利用.
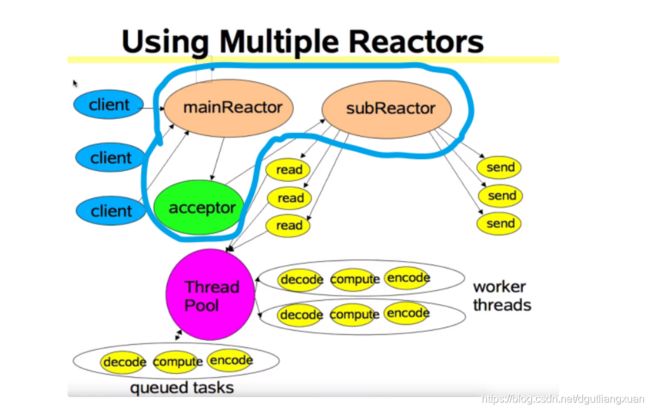
疑问: 如何理解主从Reactor模式里面的 acceptor 呢?
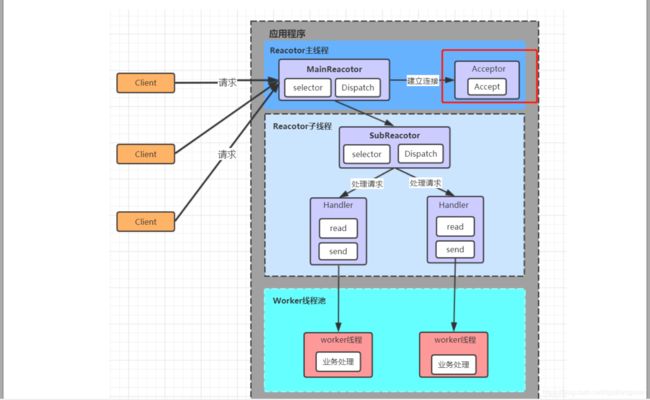
还是不大理解。。。。TODO 待续
该图主从Reactor多线程通俗的理解如下:
一批线程去处理accept 事件
其中 补充一下不好理解的地方。 SocketChannel对应的Handler :
// 7. 设置SocketChannel对应的Handler
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline p = ch.pipeline();
if (sslCtx != null) {
p.addLast(sslCtx.newHandler(ch.alloc()));
}
// 可以添加多个子Handler
//p.addLast(new LoggingHandler(LogLevel.INFO));
p.addLast(serverHandler);
}
});
下图就是很好的答案。上个好图,好东西。
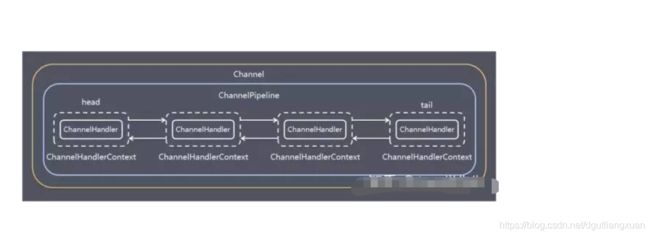
一个 Channel 包含了一个 ChannelPipeline, 而 ChannelPipeline 中又维护了一个由ChannelHandlerContext 组成的双向链表,
并且每个 ChannelHandlerContext 中又关联着一个 ChannelHandler。
入站事件和出站事件在一个双向链表中。
入站事件会从链表head往后传递到最后一个入站的handler。
出站事件会从链表tail往前传递到最前一个出站的handler,两种类型的handler互不干扰。
线程模型定义了应用或者框架如何执行你的代码,所以选择线程模型极其重要。Netty 提供了一个简单强大的线程模型来帮助我们简化代码。所有 ChannelHandler,包括业务逻辑,都保证由一个 Thread 同时执行特定的 Channel。这并不意味着Netty不能使用多线程,**只是 Netty 限制每个Channel 都由一个 Thread 处理,**这种设计适用于非阻塞 IO 操作。
另一个不同的demo 代码细节
初始化并启动Netty服务端过程如下:
public static void main(String[]args){
//创建mainReactor
NioEventLoopGroupboosGroup=newNioEventLoopGroup();
//创建工作线程组
NioEventLoopGroupworkerGroup=newNioEventLoopGroup();
finalServerBootstrapserverBootstrap=newServerBootstrap();
serverBootstrap
//组装NioEventLoopGroup
.group(boosGroup,workerGroup)
//设置channel类型为NIO类型
.channel(NioServerSocketChannel.class)
//设置连接配置参数
.option(ChannelOption.SO_BACKLOG,1024)
.childOption(ChannelOption.SO_KEEPALIVE,true)
.childOption(ChannelOption.TCP_NODELAY,true)
//配置入站、出站事件handler
.childHandler(newChannelInitializer<NioSocketChannel>(){
@Override
protectedvoidinitChannel(NioSocketChannelch){
//配置入站、出站事件channel
ch.pipeline().addLast(...);
ch.pipeline().addLast(...);
}
}
);
//绑定端口
intport=8080;
serverBootstrap.bind(port).addListener(future->{
if(future.isSuccess()){
System.out.println(newDate()+":端口["+port+"]绑定成功!");
} else{
System.err.println("端口["+port+"]绑定失败!");
}
}
);
}
Server端包含 1个Boss NioEventLoopGroup 和 1个Worker NioEventLoopGroup,NioEventLoopGroup相当于1个事件循环组,这个组里包含多个事件循环NioEventLoop(每个NioEventLoop包含1个selector和1个事件循环线程。)
每个Boss NioEventLoop循环执行的任务包含3步:
1 轮询accept事件
2 处理accept I/O事件,与Client建立连接,生成NioSocketChannel,并将NioSocketChannel注册到某个Worker NioEventLoop的Selector上
3 处理任务队列中的任务,runAllTasks。
任务队列中的任务包括用户调用eventloop.execute或schedule执行的任务,或者其它线程提交到该eventloop的任务。
每个Worker NioEventLoop循环执行的任务包含3步:
1 轮询read、write事件;
2 处I/O事件,即read、write事件,在NioSocketChannel可读、可写事件发生时进行处理
3 处理任务队列中的任务,runAllTasks。
其中任务队列中的task有3种典型使用场景:
1 用户程序自定义的普通任务
ctx.channel().eventLoop().execute(newRunnable(){
@Override
publicvoidrun(){
//...
}
}
);
在学习之前,建议先理解透整个框架原理结构,运行过程,可以少走很多弯路。
对于 Netty ,什么是新连接接入?以及新连接接入前,Netty处于什么状态
netty的服务端
1 NioServerSocketChannel初始化,
2 注册在BossGroup中的一条NioEventLoop中,
3 并且给NioServerSocketChannel中维护的jdk原生的ServerSocketChannel绑定好了端口后, 4 EventLoop启动,开始轮询工作…
这时候 EventLoop 它在轮询什么?
其实它在轮询监听当初NioServerSocketChannel经过二次注册感兴趣的事件时,
告诉 Selector,让Selector关注自己身上可能会出现 OP_ACCEPT 事件, 这合情合理,
因为对于Netty的主从Reactor线程模型中。BossGroup中的channel只关心OP_ACCEPT 也就是用户的请求建立连接事件。
补充一下 Netty 的核心组件有哪些 ?
推荐小弟的下一篇文章
Netty keepalive 和 idle 的三角关系
解除文件句柄数量的限制,修改
/etc/security/limits.conf 文件
soft nofile 1000000
hard nofile 1000000
2021年8月面试过程中记忆最深的10道题,供你参考。
=== 1. 如何理解微服务?什么是12 factor?解释一下?
国内的微服务实施主要依赖一线工程师执行,二线的技术经理、架构师应该对此有更深些理解。
否则会向领导经常反映“资源”紧张、要求一线执行者“责任心”、出问题会归咎于测试“不充分”,会以各种方式规避构建部署中的工程流程。
=== 2. 你怎么理解业务架构师和基础架构师的区别?
其实二者殊途同归,至少有80%所有相似:必须有架构能力。前者和行业业务相关,后者100%纯技术。
我个人理解:短期内基础架构更风光,也建议是年轻人必经之路。但后续(比如35岁以后)拼的就是综合实力。
简单来讲,业务架构师 -> CTO;基础架构师 -> 首席架构师
=== 3. 有看过哪些开源项目的源码?贡献过吗?聊一聊
代码能力一定是衡量一个程序员最基础的标准。如果自己有还不错的开源项目,就非常赞(开源项目 ≠ github代码仓库)
=== 4. 你是如何做技术选型的?
这是个能力活,需要有一定的广度和深度,是架构师常干的活。一般需要经过背景、技术调研、优缺点分析、规划、方案、落地、效果监控等
=== 5. 怎么评价PPT架构师?
这个比较尖锐,估计面试官是个技术范,但没竞争过PPT,。
架构师不写代码、技术总监不写代码甚至不会写代码在职场里其实还是比较常见的,但看现状是,现在越来越难“混”了
=== 6. 给你一个redisClient/zookeeperClient,写一把分布式锁(动手写代码题)
现在的面试,大部分都要求现场写代码。一方面考这个知识点,另一方面考敲代码手熟练不,代码格式、命名规范否
=== 7. 什么是幻读?如何解决
我认为他的考点是隔离级别、MVCC等
=== 8. javax、Jakarta、JSR、JCP…介绍一下
因为我简历里说了对这些有较深了解,所以…,我就侃侃而谈
=== 9. 精通Spring技术栈?聊一聊
嗯,也是因为我简历里写了精通二字,然后被“抓”。还好,我个人对Spring技术栈了解还算比较深的,绝大部分都能应对吧(问得还是比较深的,甚至到源码级别而非原理级别,所以精通二字慎用)
=== 10. 算法题
什么手写一个快速排序,什么如何判断镜像树,什么… 差不多一半吧,我的回答是两个字:不会
总而言之,我个人的一个体会:面试准备的时间花在刀刃上,这个刀刃指做过的代表性项目(最重要,可带着面试官的思路向你熟悉的领域走)、熟悉的组件/中间件、基础技术等等。建议可少花点时间在算法上,因为几乎没有面试官会因为1-2道算法题做不出来而pass掉人吧,那并不重要,真的。
但一定要有较好的【写代码能力】,这个几乎成为现在的必考了。如果写代码很熟练、很规范,那比做出一道算法题优秀多了。所以平时要多敲,少用ctrl c/v,熟能生巧嘛
深入了解NIO的优化实现原理
epoll() 函数
:select/poll 是顺序扫描 fd 是否就绪,而且支持的 fd 数量不宜过大,因此它
的使用受到了一些制约。
Linux 在 2.6 内核版本中提供了一个 epoll 调用,epoll 使用事件驱动的方式代替轮询扫描
fd。epoll 事先通过 epoll_ctl() 来注册一个文件描述符,将文件描述符存放到内核的一个事
件表中,这个事件表是基于红黑树实现的,所以在大量 I/O 请求的场景下,插入和删除的
性能比 select/poll 的数组 fd_set 要好,因此 epoll 的性能更胜一筹,而且不会受到 fd 数
量的限制
零拷贝
在 I/O 复用模型中,执行读写 I/O 操作依然是阻塞的,在执行读写 I/O 操作时,存在着多
次内存拷贝和上下文切换,给系统增加了性能开销。
零拷贝是一种避免多次内存复制的技术,用来优化读写 I/O 操作。
在网络编程中,通常由 read、write 来完成一次 I/O 读写操作。每一次 I/O 读写操作都需
要完成四次内存拷贝,路径是 I/O 设备 -> 内核空间 -> 用户空间 -> 内核空间 -> 其它
I/O 设备。
Linux 内核中的 mmap 函数可以代替 read、write 的 I/O 读写操作,实现用户空间和内核
空间共享一个缓存数据。mmap 将用户空间的一块地址和内核空间的一块地址同时映射到
相同的一块物理内存地址,不管是用户空间还是内核空间都是虚拟地址,最终要通过地址映
射映射到物理内存地址。这种方式避免了内核空间与用户空间的数据交换。I/O 复用中的
epoll 函数中就是使用了 mmap 减少了内存拷贝
在 Java 的 NIO 编程中,则是使用到了 Direct Buffer 来实现内存的零拷贝。Java 直接在
JVM 内存空间之外开辟了一个物理内存空间,这样内核和用户进程都能共享一份缓存数
据。