Mysql--索引,事务隔离级别、锁 、主从复制,读写分离
目录
一 Mysql主从复制
二 读写分离 ()
mycat中间件的配置文件
/usr/mycat/conf/schema.conf
/usr/mycat/conf/server.conf
日志文件

binlog
binlog指二进制日志,它记录了数据库上的所有改变,并以二进制的形式保存在磁盘中,它可以用来查看数据库的变更历史、数据库增量备份和恢复、MySQL的复制(主从数据库的复制)。
binlog有三种格式:
statement:基于SQL语句的复制(statement-based replication,SBR)
row:基于行的复制(row-based replication,RBR)
mixed:混合模式复制(mixed-based replication,MBR)
redolog
1. 用途
保证数据的更新操作不丢失,同时保证了性能
2. 如何使用redo log来保证更新操作的不丢失?
数据修改成功之后,就需要将该数据页刷到磁盘中去,以防丢失,但是现在已经引入了redo log,此时只需要这个修改信息写入到redo log当中,也就是将哪个数据页哪里发生了修改写入到redo log当中,而不需要将修改过的整个数据页刷到磁盘当中去
3. 写redo log同样也是一次磁盘的写操作,凭什么说它的性能就更高一点呢?
写redo log还有刷数据页到磁盘中去,都是磁盘的的写操作,但是呢,将修改信息写入到redo log当中,只需要数据顺序写入redo log当中,这里其实就是一次顺序写磁盘的操作.而将数据页刷到磁盘中,因为一个修改操作可能会同时修改多个数据页,这些数据页又不是连续的,此时就意味着随机写磁盘并且,对于MySQL来说,一个数据页是16kb,可能一次性更新多个数据页,此时可能需要随机写入几百k的数据而对于redo log,一次修改可能只需要写入几k的数据,数据量相对于刷数据页的方式是大大减少的比较一下写redo log和刷数据页,写redo log是磁盘的顺序写,小数据量,而刷数据页到磁盘可能就意味着随机写,而且还是大数据量的,两者一比较,写redo log的性能可能比刷数据页的性能高100倍
综上所述,redo log能够在保证数据不丢失的时候,同时保证了性能
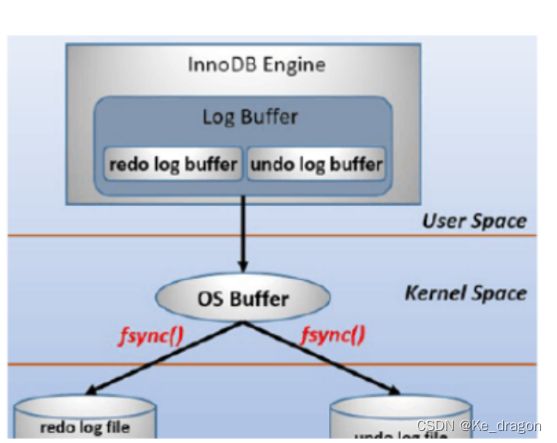
redo log包括两部分:⼀是内存中的⽇志缓冲(redo log buffer),该部分⽇志是易失性的;⼆是磁盘上的重做⽇志⽂件(redo log file),该部分⽇志是持久的。
在概念上,innodb通过force log at commit机制实现事务的持久性,即在事务提交的时候,必须先将该事务的所有事务⽇志写⼊到磁盘上的redo log file和undo log file中进⾏持久化。
为了确保每次⽇志都能写⼊到事务⽇志⽂件中,在每次将log buffer中的⽇志写⼊⽇志⽂件的过程中都会调⽤⼀次操作系统的fsync操作(即fsync()系统调⽤)。因为MariaDB/MySQL是⼯作在⽤户空间的,MariaDB/MySQL的log buffer处于⽤户空间的内存中。要写⼊到磁盘上的log file中(redo:ib_logfileN⽂件,undo:share tablespace或.ibd⽂件),中间还要经过操作系统内核空间的os buffer,调⽤fsync()的作⽤就是将OS buffer中的⽇志刷到磁盘上的log file中。
也就是说,从redo log buffer写⽇志到磁盘的redo log file中,
MySQL中数据是以页为单位,你查询一条记录,会从硬盘把一页的数据加载出来,加载出来的数据叫数据页,会放入到Buffer Pool中。后续的查询都是先从Buffer Pool中找,没有命中再去硬盘加载,减少硬盘IO开销,提升性能。更新表数据的时候,也是如此,发现Buffer Pool里存在要更新的数据,就直接在Buffer Pool里更新。然后会把“在某个数据页上做了什么修改”记录到重做日志缓存(redo log文件)里,接着刷盘到redo log文件里。
binlog redolog区别:
假设一个事务,对表做10万行的记录插入,在这个过程中,一直不断的往redolog顺序记录,而binlog不会记录,直到事务提交,才会一次性写入binlog文件中。
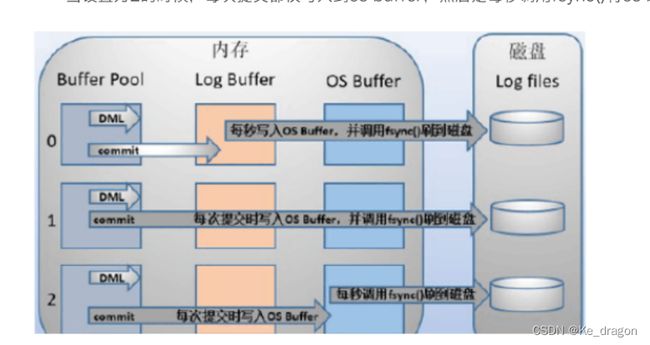
刷盘时机
InnoDB存储引擎为redo log的刷盘策略提供了innodb_flush_log_at_trx_commit参数,它支持三种策略
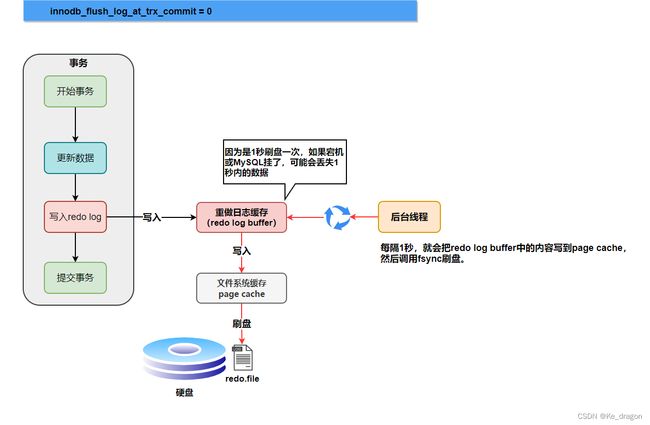
设置为0的时候,表示每次事务提交时不进行刷盘操作(另外InnoDB存储引擎有一个后台线程,每隔1秒,就会把redo log buffer中的内容写到文件系统缓存(page cache),然后调用fsync盘。)
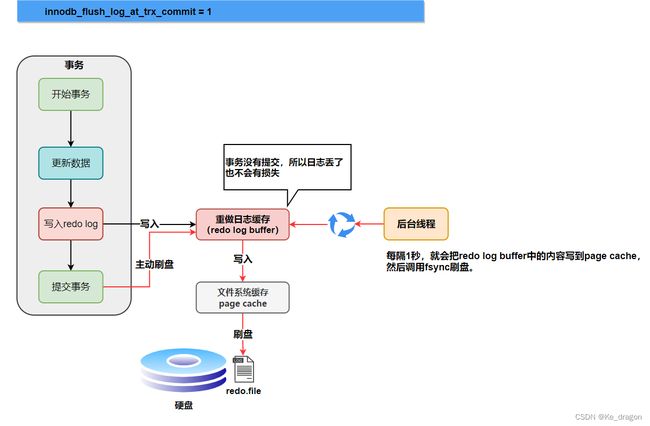
设置为1的时候,表示每次事务提交时都将进行刷盘操作(默认值)
设置为2的时候,表示每次事务提交时都只把redo log buffer内容写入page cache

也就是说,一个没有提交事务的redo log记录,也可能会刷盘。(参数为0的情况)
为什么呢?因为在事务执行过程redo log记录是会写入redo log buffer中,这些redo log记录会被后台线程刷盘。

除了后台线程每秒1次的轮询操作,还有一种情况,当redo log buffer占用的空间即将达到innodb_log_buffer_size一半的时候,后台线程会主动刷盘。
下面是不同刷盘策略的流程图
innodb_flush_log_at_trx_commit=0

为什么binlog没有崩溃恢复功能,而redo有?
- bin log 是可以追加写入的。“追加写” 是指 bin log 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志
- redo log 是循环写的,空间固定会被用完
可以看到,redo log 和 bin log 的一个很大的区别就是,一个是循环写,一个是追加写。也就是说 redo log 只会记录未刷入磁盘的日志,已经刷入磁盘的数据都会从 redo log 这个有限大小的日志文件里删除。
而 bin log 是追加日志,保存的是全量的日志。这就会导致一个问题,那就是没有标志能让 InnoDB 从 bin log 中判断哪些数据已经刷入磁盘了,哪些数据还没有。
举个例子,bin log 记录了两条日志:
记录 1:给 id = 1 这一行的 age 字段加 1
记录 2:给 id = 1 这一行的 age 字段加 1
假设在记录 1 刷盘后,记录 2 未刷盘时,数据库崩溃。重启后,只通过 bin log 数据库是无法判断这两条记录哪条已经写入磁盘,哪条没有写入磁盘,不管是两条都恢复至内存,还是都不恢复,对 id = 1 这行数据来说,都是不对的。
但 redo log 不一样,只要刷入磁盘的数据,都会从 redo log 中被抹掉,数据库重启后,直接把 redo log 中的数据都恢复至内存就可以了。
这就是为什么说 redo log 具有崩溃恢复的能力,而 bin log 不具备
一 Mysql主从复制
-
主数据库有个bin-log二进制文件,纪录了所有增删改Sql语句。(binlog线程)
-
从数据库把主数据库的bin-log文件的sql语句复制过来。(io线程)
-
从数据库的relay-log重做日志文件中再执行一次这些sql语句。(Sql执行线程)
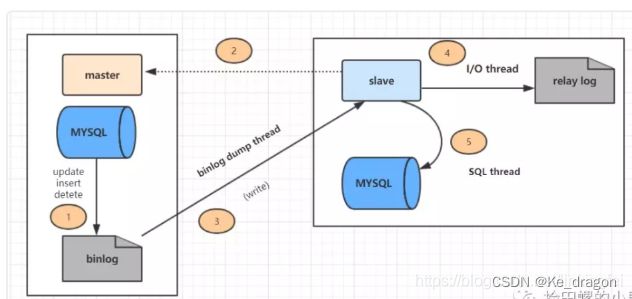
上图主从复制分了五个步骤进行:
步骤一:主库的更新事件(update、insert、delete)被写到binlog
步骤二:从库发起连接,连接到主库。
步骤三:此时主库创建一个binlog dump thread,把binlog的内容发送到从库。
步骤四:从库启动之后,创建一个I/O线程,读取主库传过来的binlog内容并写入到relay log
步骤五:还会创建一个SQL线程,从relay log里面读取内容,从ExecMasterLog_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db。
二 读写分离 ()


mycat中间件的配置文件
/usr/mycat/conf/schema.conf
select user()
/usr/mycat/conf/server.conf
druidparser
utf8
123456
aa
mysql事务隔离级别(默认rr,即可重复读)
什么是事务?
事务是一个程序的执行单元。事务本身并不具备4个特性(原子性,一致性,隔离性,持久性),我们通过某种手段,尽可能让这些执行单元满足这4个特性,我们就称这是个正确的事务。
隔离级别:
并发情况下,事务引发的问题。多个执行单元并发执行,会引发以下问题:
脏读(破坏了隔离性)
在数据库技术中,脏数据在临时更新( 脏读)中产生。事务A更新了某个数据项X,但是由于某种原因,事务A出现了问题,于是要把A回滚。但是在回滚之前,另一个事务B读取了数据项X的值(A更新后),A回滚了事务,数据项恢复了原值。事务B读取的就是数据项X的就是一个“临时”的值,就是脏数据。
通俗的讲,当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是脏数据,依据脏数据所做的操作可能是不正确的。
不可重复读(破坏了一致性 update delete)
A事务在本事务,对自己未操作的数据进行多次读取,结果不一致。或者不存在的情况。
幻读 (破坏了一致性,insert)
A事务在本事务,对自己未操作的数据进行多次读取,第一次数据不存在。第二次出现了。
解决:
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 读未提交 | 会 | 会 | 会 |
| 读已提交 | 会 | 会 | |
| 可重复读 | 会 | ||
| 串行化(事务与事务之间串行执行,毫无并发可言,性能极低) |
可重复读其实也可以解决幻读,但是要在业务上做保证,即加for update等字段,原理就是加gap锁和行锁变成next -key锁。(next-key locks由record locks(索引加锁) 和 gap locks(间隙锁,每次锁住的不光是需要使用的数据,还会锁住这些数据附近的数据))(*)