【数据结构篇】线性表1 --- 顺序表、链表 (万字详解!!)
前言:这篇博客我们重点讲 线性表中的顺序表、链表
线性表(linear list)是n个具有相同特性的数据元素的有限序列。
线性表是一种在实际中广泛使用的数据结构,常见的线性表:顺序表、链表、栈、队列...
线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的,线性表在物理上存储时,通常以数组和链式结构的形式存储。
顺序表(ArrayList)
什么是顺序表?
顺序表是用一段物理地址连续的存储单元,依次存储数据元素的线性结构,一般情况下采用数组存储。在数组上完成数据的增删查改。
也就是说,顺序表 底层结构就是 一个数组。是使用数组 来完成的一种结构。
那现在有一个数组,如果有一组数据 1,2,3,4,5,6,7 , 我们现在想把这组数据放到数组里去。
我们先放进1,2,3 , 问当前数组里有多少个有效数据? 很明显是 3 个。
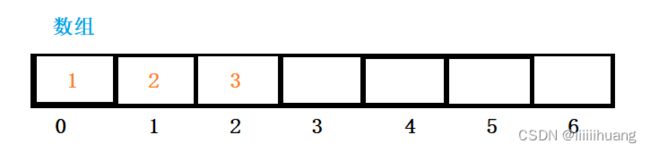
那怎么利用程序判断他有 3 个有效数据呢?
我们需要先定义一个变量 usedSize , 放进一个数据 usedSize++,放一个就加一下。这不就能确定有几个有效数据了吗。
代码实现 (MyArrayList)
接下来我们利用代码来实现顺序表的增删查改等方法:
--- 打印顺序表
就是遍历数组

--- 新增元素
1.新增元素,默认在数组最后新增
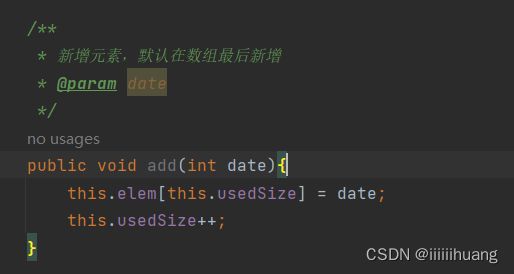
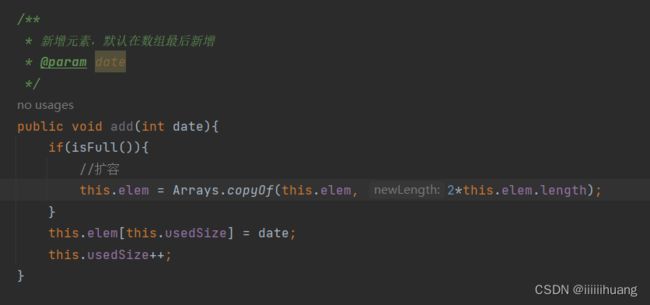
这么写没问题吗?如果满了怎么办?
所有我们要写一个方法来判断是否满了 :

新增元素前我们要判断是否满了,满了的话要扩容
新增看看效果:


2.在指定位置新增元素
我们的逻辑应该是把指定位置之后的数据 都向后挪,把指定位置空出来,再在指定位置插入数据 。
那具体该如何挪数据?
我们要从最后的位置开始挪 ,不能从第一个开始挪,不然会把之后的数据盖掉。

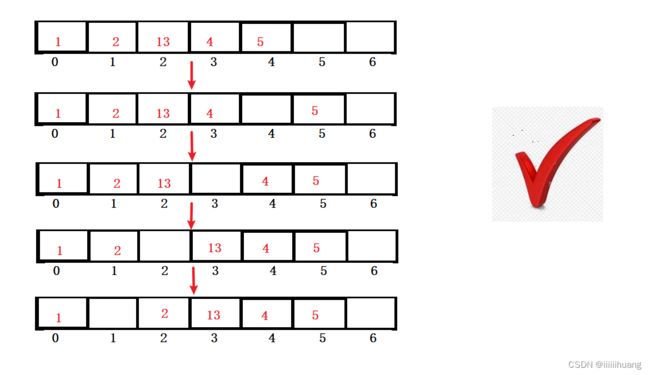
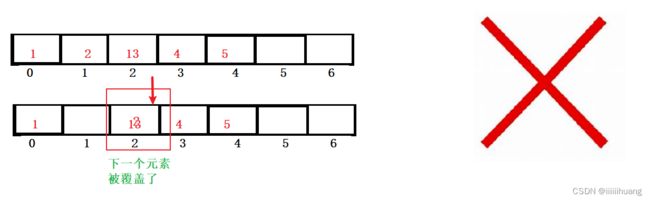
那我们现在确定了挪的方法,接下来我们看看代码如何实现:
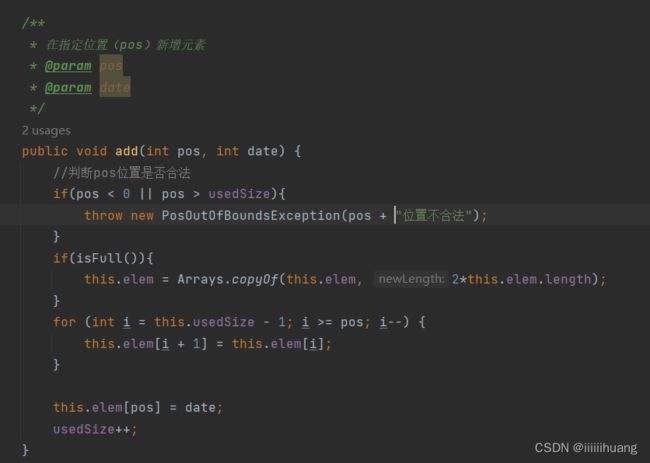
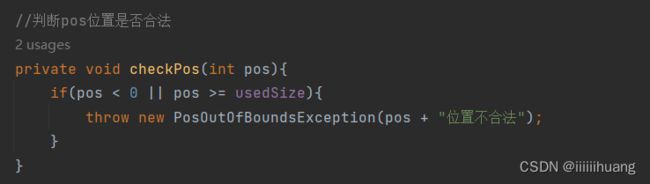
注意:我们这里是要判断pos的位置是否合法的 ,
pos不能小于0,也不能跳着放(大于usedSize).

为此我们还搞了个异常

(ps:异常之前讲过 链接 https://blog.csdn.net/iiiiiihuang/article/details/130671801?spm=1001.2014.3001.5501 )
我们看看运行效果 :

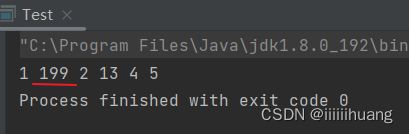
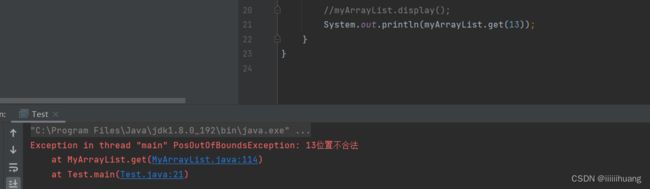
看看位置不合法时的运行结果:

--- 判断是否包含某个元素
运行结果

--- 查找某个元素具体位置(下标)

运行结果


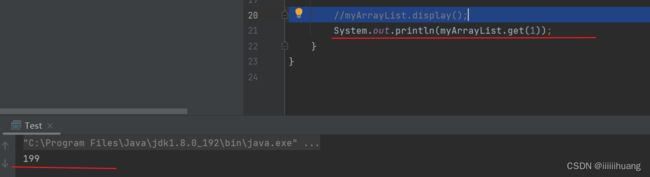
--- 获取 pos 位置的元素
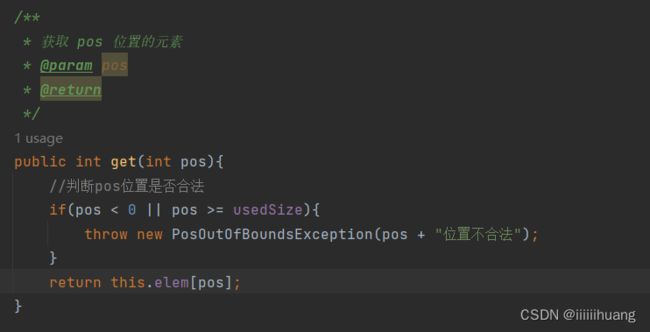
还要判断位置是否合法。
运行结果
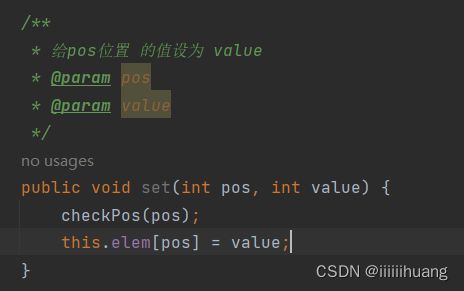
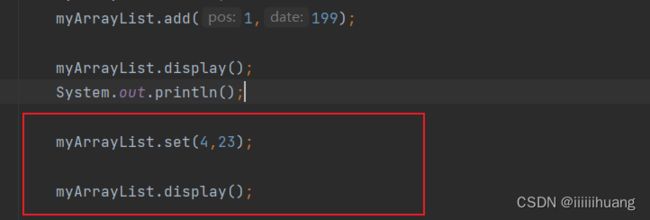
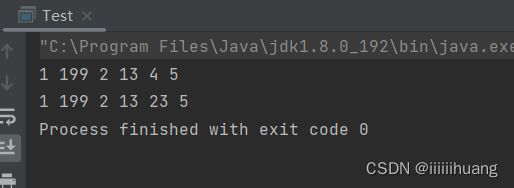
--- 给pos位置 的值设为 value
这里同样要先判断 pos 位置是否合法,那我们可以单独写一个方法,来判断。(方法的封装)
运行结果
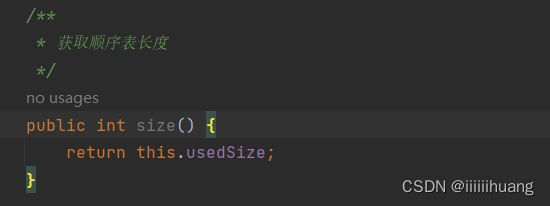
--- 获取顺序表长度
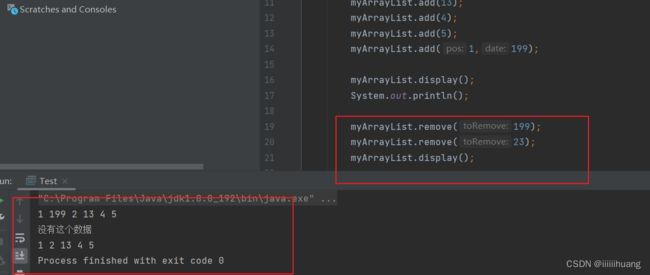
--- 删除第一次出现的关键字
代码实现

注意:usedSize - 1 防止越界,这里是 this.elem[i] = this.elem[i + 1], 那 i 走到倒数第二位就行了
运行结果
--- 清除顺序表

ps (小提一嘴): 现在的都是整型这么写可以,但是的是 引用类型 的时候要一个一个 置为 null ,删除也要有类似操作。
完整代码
import java.util.ArrayList;
import java.util.Arrays;
/**
* @Author: iiiiiihuang
*/
public class MyArrayList {
private int[] elem;//存放数据元素。
private int usedSize;//代表当前顺序表中有效数据个数。
private static final int DEFAULT_SIZE = 10;
/**
* 默认构造方法
*/
public MyArrayList() {
this.elem = new int[DEFAULT_SIZE];
}
/**
* 指定容量
* @param initCapacity
*/
public MyArrayList(int initCapacity) {
this.elem = new int[initCapacity];
}
/**
* 打印顺序表中的所有元素
*/
public void display() {
for (int i = 0; i < this.usedSize; i++) {
System.out.print(this.elem[i] + " ");
}
}
public boolean isFull() {
if(this.usedSize == this.elem.length){
return true;
}
return false;
}
/**
* 新增元素,默认在数组最后新增
* @param date
*/
public void add(int date){
if(isFull()){
//扩容
this.elem = Arrays.copyOf(this.elem, 2*this.elem.length);
}
this.elem[this.usedSize] = date;
this.usedSize++;
}
//判断pos位置是否合法
private void checkPos(int pos){
if(pos < 0 || pos >= usedSize){
throw new PosOutOfBoundsException(pos + "位置不合法");
}
}
/**
* 在指定位置(pos)新增元素
* @param pos
* @param date
*/
public void add(int pos, int date) {
//判断pos位置是否合法
if(pos < 0 || pos > usedSize){
throw new PosOutOfBoundsException(pos + "位置不合法");
}
if(isFull()){
this.elem = Arrays.copyOf(this.elem, 2*this.elem.length);
}
for (int i = this.usedSize - 1; i >= pos; i--) {
this.elem[i + 1] = this.elem[i];
}
this.elem[pos] = date;
usedSize++;
}
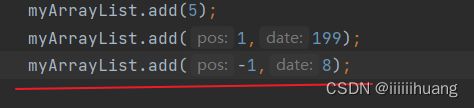
/**
* 判断是否包含某个元素
* @param toFind
* @return
*/
public boolean contains(int toFind){
for (int i = 0; i < this.usedSize; i++) {
if(this.elem[i] == toFind){
return true;
}
}
return false;
}
/**
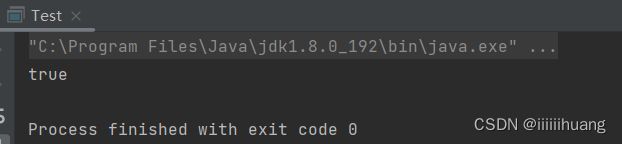
* 查找某个元素具体位置(下标)
* @param toFind
* @return
*/
public int indexOf(int toFind){
for (int i = 0; i < this.usedSize; i++) {
if(this.elem[i] == toFind){
return i;
}
}
return -1;
}
/**
* 获取 pos 位置的元素
* @param pos
* @return
*/
public int get(int pos) {
//判断pos位置是否合法
checkPos(pos);
return this.elem[pos];
}
/**
* 给pos位置 的值设为 value
* @param pos
* @param value
*/
public void set(int pos, int value) {
checkPos(pos);
this.elem[pos] = value;
}
/**
* 获取顺序表长度
*/
public int size() {
return this.usedSize;
}
/**
* 删除第一次出现的关键字
* @param toRemove
*/
public void remove(int toRemove) {
//获取要删除元素下标
int index = indexOf(toRemove);
if(index == -1){
System.out.println("没有这个数据");
return;
}
//usedSize - 1 防止越界
for (int i = index; i < this.usedSize - 1; i++) {
this.elem[i] = this.elem[i + 1];
}
usedSize--;
}
/**
* 清除顺序表
*/
public void clear() {
this.usedSize = 0;
}
}上述是自己实现一个顺序表结构,那以后用到顺序表都要我们自己重新实现吗? 当然不用啦!
Java里面已经帮你处理好了,有现成的 ,就是 ArrayList
ArrayList
在集合框架中,ArrayList是一个普通的类,实现了List接口 。

1. ArrayList是以泛型方式实现的,使用时必须要先实例化
2. ArrayList实现了RandomAccess接口,表明ArrayList支持随机访问
3. ArrayList实现了Cloneable接口,表明ArrayList是可以clone的
4. ArrayList实现了Serializable接口,表明ArrayList是支持序列化
5. 和Vector不同,ArrayList不是线程安全的,在单线程下可以使用,在多线程中可以选择 Vector或者CopyOnWriteArrayList
6. ArrayList底层是一段连续的空间,并且可以动态扩容,是一个动态类型的顺序表
我们可以在 IDEA 里看到 ArrayList 的源码
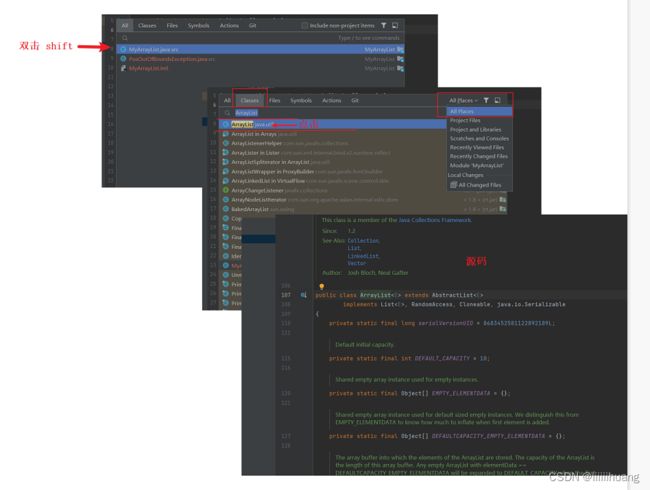
接下来我们 来介绍一下 ArrayList 的几种用法。
ArrayList 的实例化

这两种方法都行,区别就在于,方法一 可以调用的方法更多一些。 但是方法二 发生了向上转型,
一般情况下,我们用方法二多一点。
(ps: 向上转型 前面介绍过了 链接 https://blog.csdn.net/iiiiiihuang/article/details/130484383?spm=1001.2014.3001.5501 )
ArrayList的构造
| 方法 | 解释 |
| ArrayList() | 无参构造 |
| ArrayList(Collection c) | 利用其他 Collection 构建 ArrayList |
| ArrayList(int initialCapacity) | 指定顺序表初始容量 |
当我们调用不带参数的构造方法时,默认在第一次 add 时才会分配大小为10的内存
扩容按1.5倍进行扩容
ArrayList常见操作
| 方法 | 解释 |
| boolean add(E e) | 尾插 e |
| void add(int index, E element) | 将 e 插入到 index 位置 |
| boolean addAll(Collection c) | 尾插 c 中的元素 |
| E remove(int index) | 删除 index 位置元素 |
| boolean remove(Object o) | 删除遇到的第一个 o |
| E get(int index) | 获取下标 index 位置元素 |
| E set(int index, E element) | 将下标 index 位置元素设置为 element |
| void clear() | 清空 |
| boolean contains(Object o) | 判断 o 是否在线性表中 |
| int indexOf(Object o) | 返回第一个 o 所在下标 |
| int lastIndexOf(Object o) | 返回最后一个 o 的下标 |
| List |
截取部分 list |
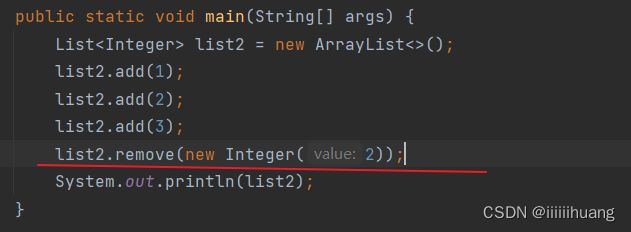
注意:这个remove怎么用?
![]()
要这么写才能删掉 等于2 的元素

演示一下 subList
![]()
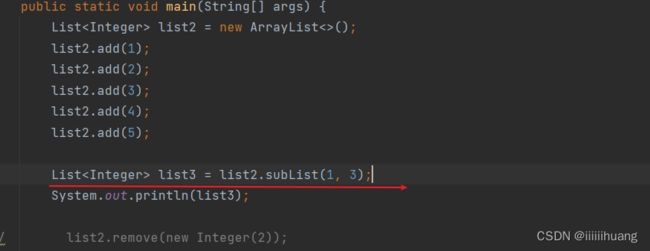
截取到2,3 (Java里一般都是左闭右开的 [ , , ) )
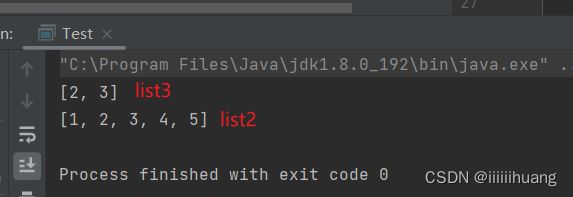
如果我们把 list3 的 0 下标该成 188 会方生什么?
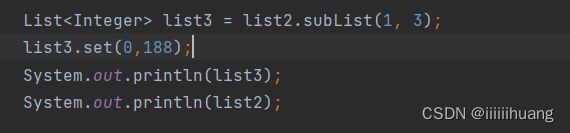
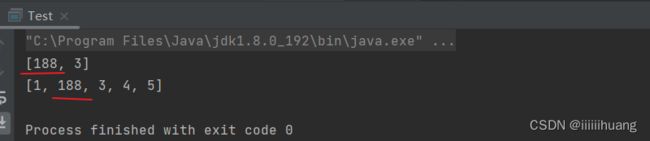
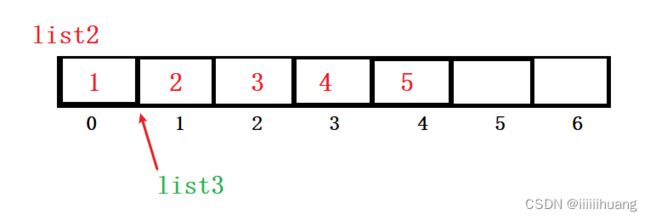
我们发现,list2 的 1 下标的位置(list3 的 0下标)也变成了188 . 为什么?
这是因为list3, 截取的时候并没有真正的把这个数据拿出来,只是指向了1 下标那儿的地址 ,所有更新值肯定会影响 list2.
ArrayList的遍历
ArrayList 可以使用三方方式遍历:使用迭代器 ,for循环+下标、foreach
上面是直接 用sout 遍历 的,是因为重写了 toString 方法。

---- 迭代器
一般情况下,能够直接通过 sout 输出 引用指向对象当中的内容的时候,此时一定重写了 toString 方法。
那我们看看ArrayList 里有没有 toString (ctrl + F) 搜索一下。发现没有。
但是 ArrayList 还继承了 AbstractList,我们去 AbstractList 里找找。发现还没有。

但是 AbstractList 还继承了 AbstractCollection ,
我们在 AbstractCollection 这里找到了 toString。
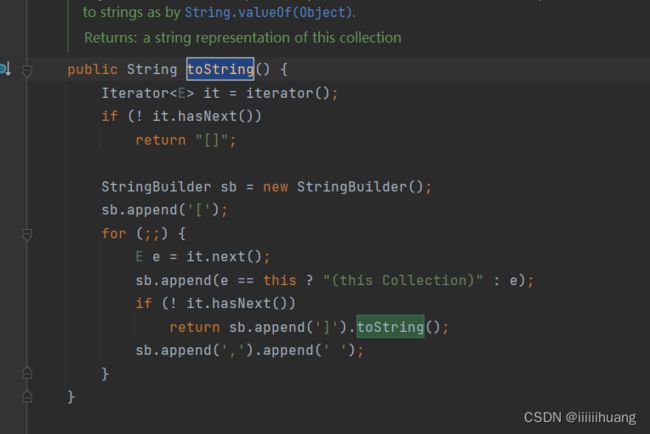
下面画线那个部分就是 迭代器 (遍历当前集合)

--- 用法一
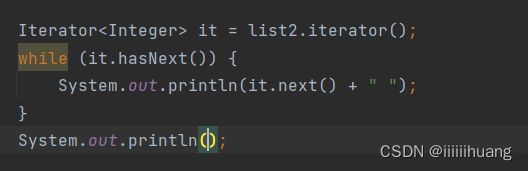
--- 用法二

上面两个用那个都行
--- 从后往前打印
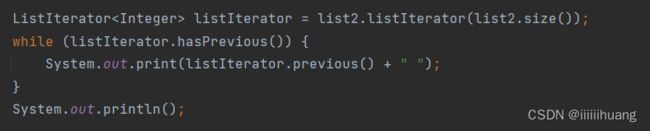
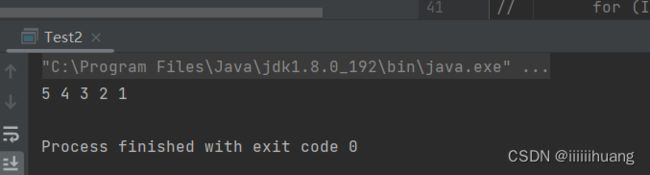

ps : 这个方法不行,因为这个不能传参
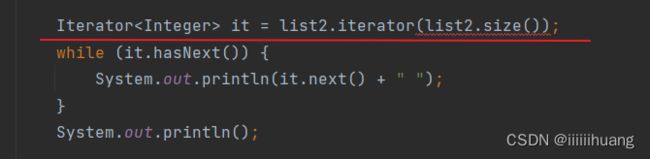

---- for循环+下标
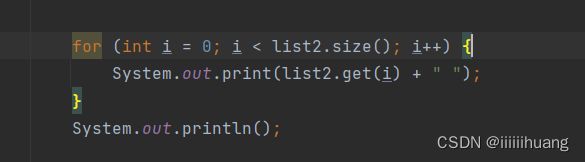

---- foreach

ArrayList 的优缺点
优点
1.可以通过下标 进行随机访问,顺序表适合对静态的数据进行 查找 和 更新
缺点
1.添加元素的效率比较低 (假如在 0 位置添加元素,就需要把后面所有的元素都往后移)
2.删除的效率也低(假如删除 0 位置元素,也需要移动后面所有的元素)
3.扩容 按1.5 倍扩容,有浪费 空间的情况。
(顺序表不适合用来 插入和删除 数据)
顺序表适合对静态的数据进行 查找 和 更新,不适合用来 插入和删除 数据,这时候就需要用 链表来做。接下来我们来介绍链表。
链表 (LinkedList)
什么是链表?
链表 是一种 物理存储结构上非连续 的存储结构,数据元素的 逻辑顺序 是通过链表中的 引用链接次序实现的 。
链表是由一个一个 节点 连成的 :(这个是单向 不带头 非循环 链表的节点)
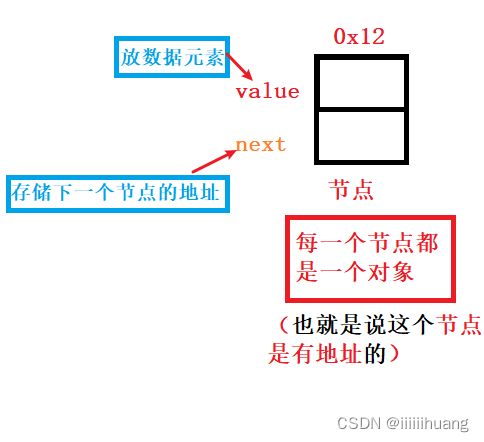
单向 不带头 非循环 链表
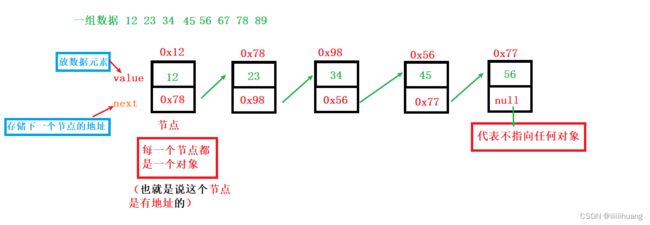
除此之外还有很多 类型的 链表,一般从三个方向去分
- 单向 双向
- 不带头 带头
- 非循环 循环
经过排列组合就会有下面这几种类型的链表:
- 单向 不带头 非循环 链表
- 单向 不带头 循环 链表
- 单向 带头 非循环 链表
- 单向 带头 循环 链表
- 双向 不带头 非循环 链表
- 双向 不带头 循环 链表
- 双向 带头 非循环 链表
- 双向 带头 循环 链表
上面我们画了不带头的 链表,接下来我们了解一下 带头的是啥样的?
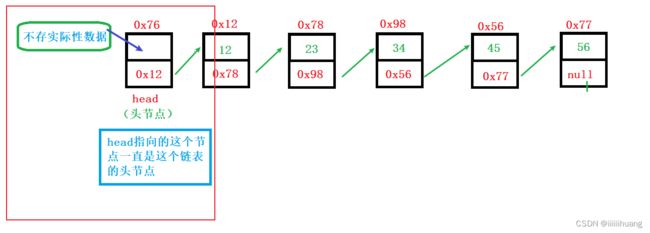
再来看看 循环的 :

等我们把单向的介绍完,在介绍双向的 。
我们重点讲 单向 不带头 非循环 链表 和 双向 不带头 非循环 链表 (这两种是工作,笔试面试考试重点)
单向 不带头 非循环 链表
代码实现
节点
上述可知 链表是由一个一个 节点 组成的,所以我们可以把这个节点定义成个内部类 。
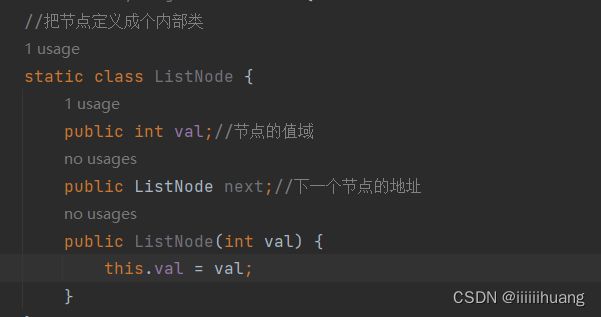
还得有一个 指向 第一个节点 的属性:
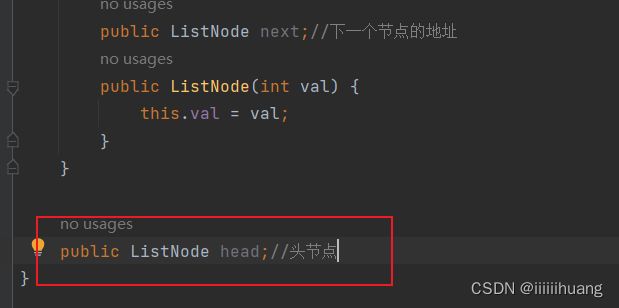
插入数据
--- 头插法

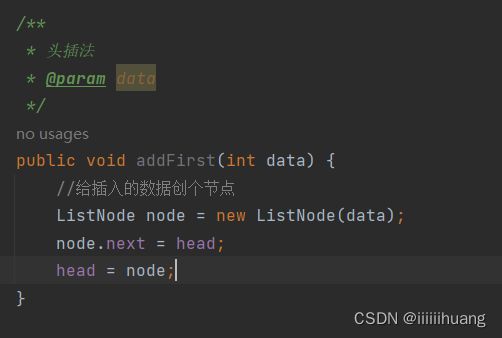
注意:如果我们把下面的语句反过来写可以吗? 变成 head = node; node.next = head;

不可以,先把node 置为 head, node 的下一个指向 head, 那不就是 自己指向自己了吗,后面的节点就都丢失了。
我们插入看看效果

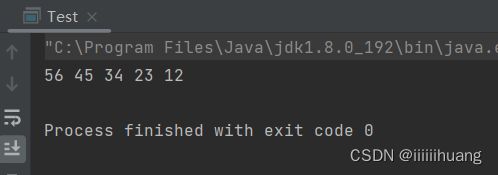
--- 尾插法
先找到最后一个节点,

所以循环里要写成 cur.next != null, 在到最后一个节点这就不进入循环了,那此时cur 就是最后一个节点,而不能写成cur != null, 这样会遍历完整个链表,停不住。

运行看看效果:


似乎是可以的,但是如果现在链表了一个节点也没有,再插入呢?

报错了!!—— 空指针异常 ,为啥呀? 我们返回代码哪里看一看,调试一下:
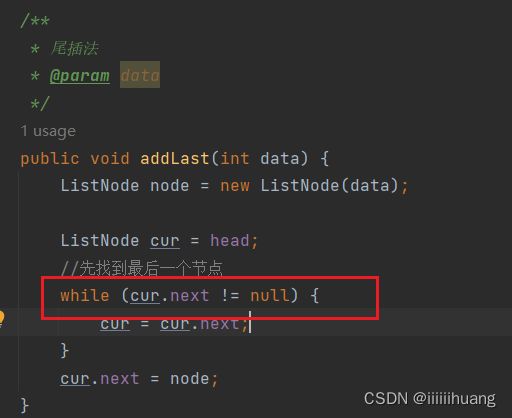
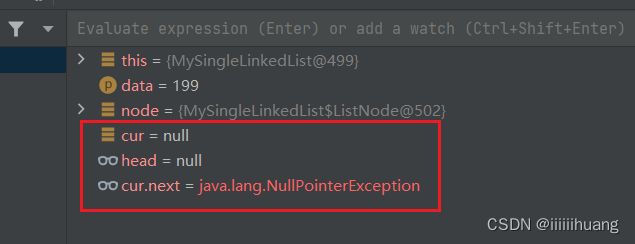
我们发现当 链表里一个节点都没有的时候,head = null,那cur = head, cur 也是 null,
那cur都为空了,哪来的 next ,那当然就报出来空指针异常了。
所以接下来我们改进一下代码:
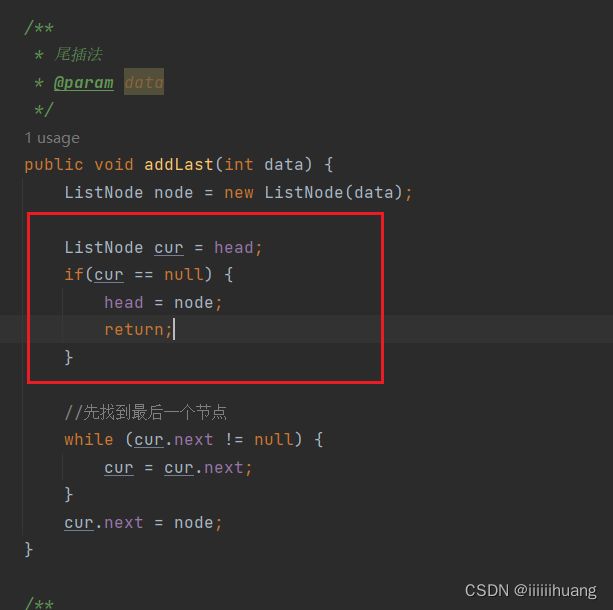
那我们再运行一下代码,就没有任何问题了
--- 任意位置插入(第一个数据节点为0号下标)
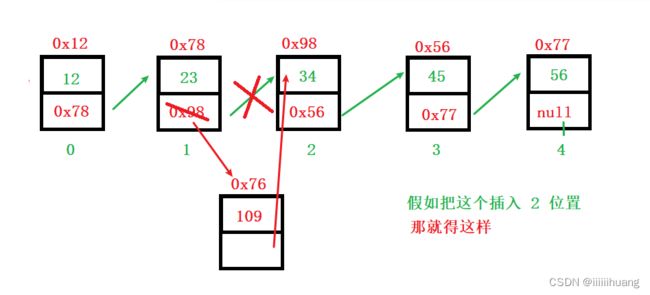
很明显,我们要确定 插入位置的前一个节点, 那如果你要插入 2 位置,那你就要找到 1 位置节点,那从 0 位置到 1 位置要走一步,也就是 index - 1 步。
找到要插入位置的前一个节点。这个是写方法 里面,还是单独封装看你喜好。
(我用的 while 循环,如果用for 循环的话,i < index - 1, 我觉得while 循环好理解点。)

找到位置了,我们就可以插入了。
先判断插入位置合不合法(类比上面的顺序表的部分)
都要先和后边的节点建立联系哦
看看效果

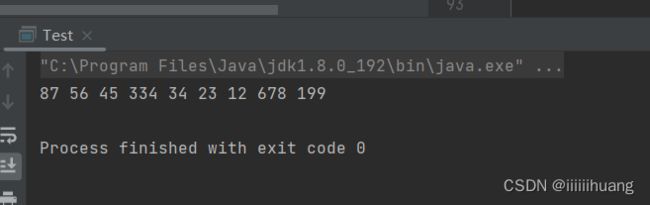
打印链表

但是用上面的方式走完之后,我自己都不知道头节点在哪里了 ,很可怕耶,
所以我们定义一个 cur节点 来代替 头节点 往下走。


单链表的长度

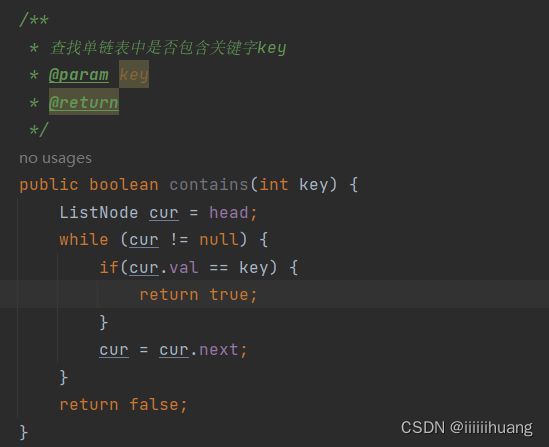
查找单链表中是否包含关键字key
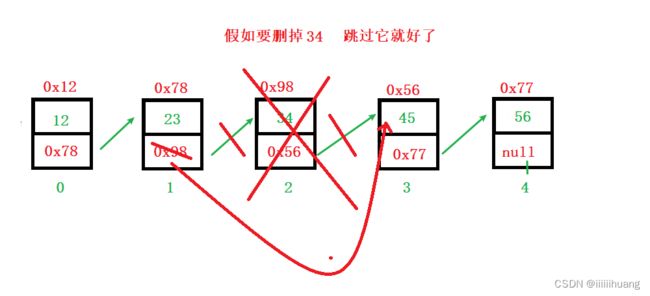
删除第一次出现关键字为key的节点
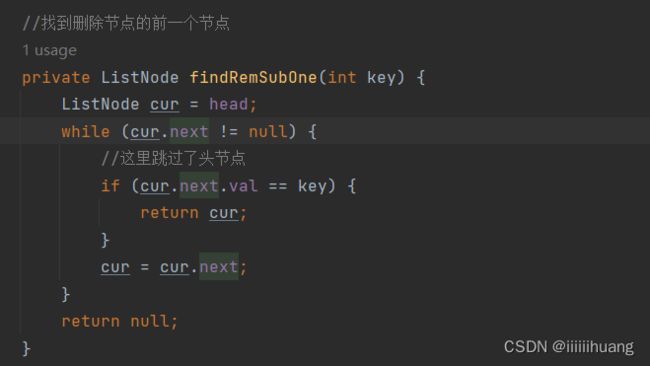
还是要找到删除节点的前一个,
为什么,循环那里要 cur.next != null, 因为,cur.next 不能是null,因为如果它是 null 的话,
那cur.next.val 就找不到值,那就会引起空指针异常,所以只要走到倒数第一个停住就好了(cur走到最后一个节点时不进入循环)

看看效果:
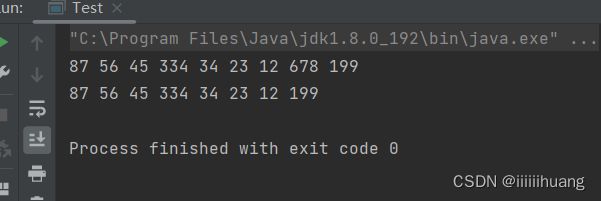
删除所有值为key的节点
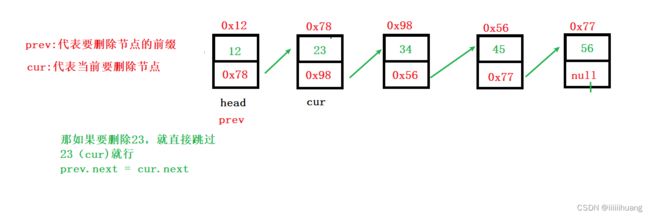
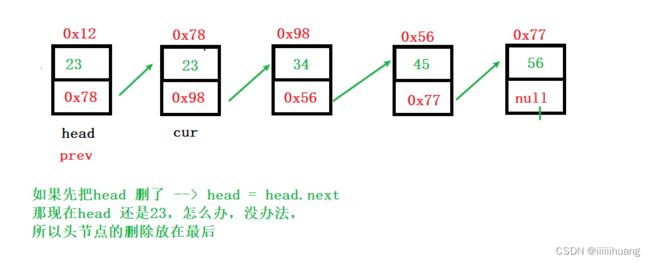
注意 :我们删除的是 cur 对应的值,cur 从第二个节点开始走,那如果第一个也是23(要删除的值)呢 ,所以我们要单独删除头节点,且在最后,不能放在前面。
运行结果
清除链表
完整代码
/**
* @Author: iiiiiihuang
*/
public class MySingleLinkedList {
//把节点定义成个内部类
static class ListNode {
public int val;//节点的值域
public ListNode next;//下一个节点的地址
public ListNode(int val) {
this.val = val;
}
}
public ListNode head;//头节点
/**
* 头插法
* @param data
*/
public void addFirst(int data) {
//给插入的数据创个节点
ListNode node = new ListNode(data);
node.next = head;
head = node;
}
/**
* 尾插法
* @param data
*/
public void addLast(int data) {
ListNode node = new ListNode(data);
ListNode cur = head;
if(cur == null) {
head = node;
return;
}
//先找到最后一个节点
while (cur.next != null) {
cur = cur.next;
}
cur.next = node;
}
/**
* 打印链表
*/
public void display() {
ListNode cur = head;
while(cur != null) {
System.out.print(cur.val + " ");
cur = cur.next;
}
System.out.println();
}
/**
* 任意位置插入
* @param index
* @param data
*/
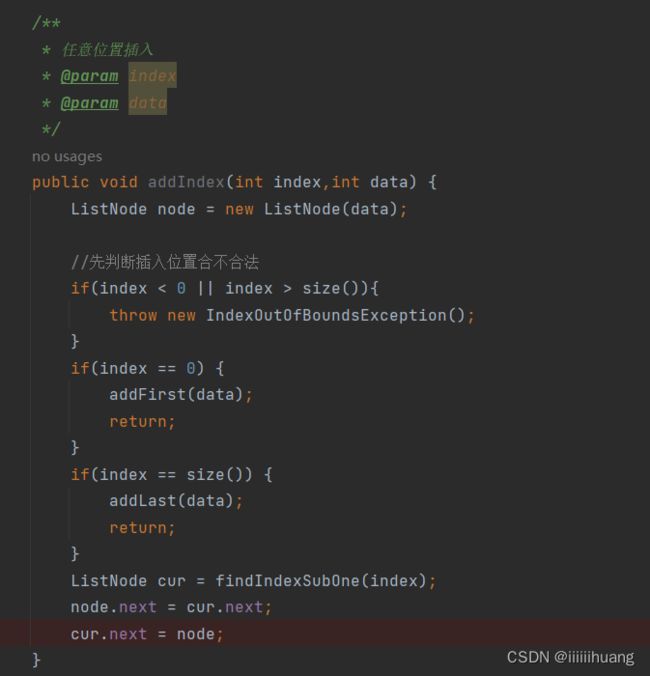
public void addIndex(int index,int data) {
ListNode node = new ListNode(data);
//先判断插入位置合不合法
if(index < 0 || index > size()){
throw new IndexOutOfBoundsException();
}
if(index == 0) {
addFirst(data);
return;
}
if(index == size()) {
addLast(data);
return;
}
ListNode cur = findIndexSubOne(index);
node.next = cur.next;
cur.next = node;
}
//找到要插入位置的前一个节点
private ListNode findIndexSubOne(int index) {
ListNode cur = head;
while (index - 1 != 0) {
cur = cur.next;
index--;
}
return cur;
}
/**
* 单链表的长度
* @return
*/
public int size() {
ListNode cur = head;
int count = 0;
while (cur != null) {
count++;
cur = cur.next;
}
return count;
}
/**
* 查找单链表中是否包含关键字key
* @param key
* @return
*/
public boolean contains(int key) {
ListNode cur = head;
while (cur != null) {
if(cur.val == key) {
return true;
}
cur = cur.next;
}
return false;
}
/**
* 删除第一次出现关键字为key的节点
* @param key
*/
public void remove(int key) {
if(head == null) {
return;
}
//单独删除头节点
if(head.val == key) {
head = head.next;
return;
}
//找到删除节点的前一个
ListNode cur = findRemSubOne(key);
if(cur == null) {
System.out.println("没有你要删除的数字");
return;
}
ListNode rem = cur.next;
cur.next = rem.next;
}
//找到删除节点的前一个节点
private ListNode findRemSubOne(int key) {
ListNode cur = head;
//这里跳过了头节点
while (cur.next != null) {
if (cur.next.val == key) {
return cur;
}
cur = cur.next;
}
return null;
}
/**
* 删除所有值为key的节点
* @param key
*/
public void removeAllKey(int key) {
ListNode cur = head.next;
ListNode prev = head;
while (cur != null) {
if(cur.val == key) {
prev.next = cur.next;
} else {
prev = cur;
}
cur = cur.next;
}
//删除头节点
if(head.val == key) {
head = head.next;
}
}
/**
* 清除链表
*/
public void clear() {
this.head = null;
}
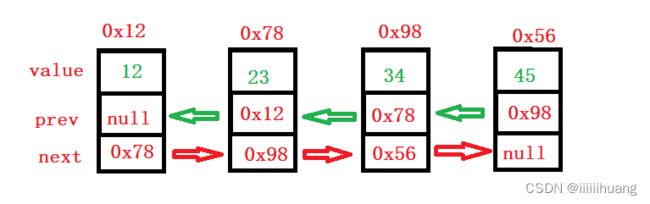
}双向 不带头 非循环 链表
画图看看结构
代码实现
创建节点内部类
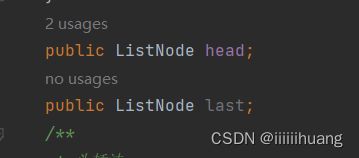
上面有的方法这也有
插入数据
--- 头插法
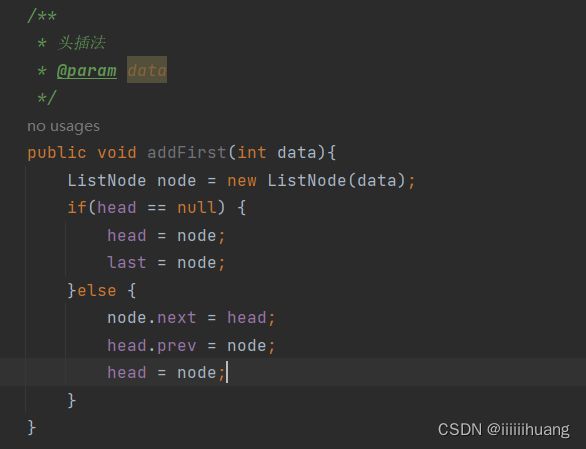
链表为空时,必须单独分情况,因为如果不分会:

运行结果


--- 尾插法
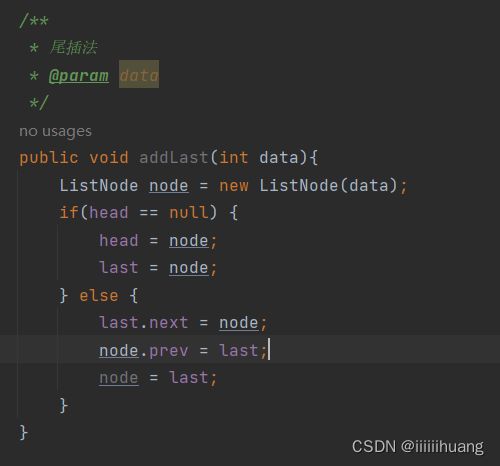
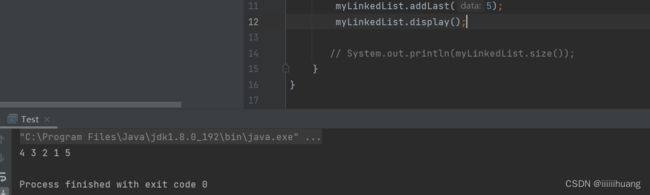
打印链表
和上面一样

查找链表中是否包含关键字key
和上面一样
链表的长度
和上面一样
运行结果


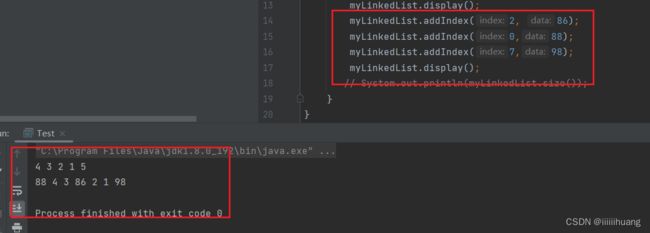
任意位置插入,第一个数据节点为0号下标


运行结果
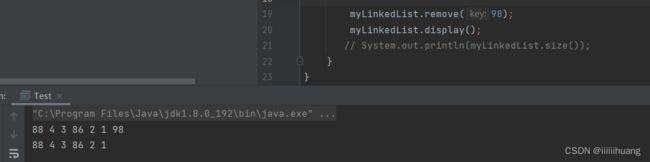
删除第一次出现关键字为key的节点

代码

头尾分开来,不然会空指针异常 。
运行结果

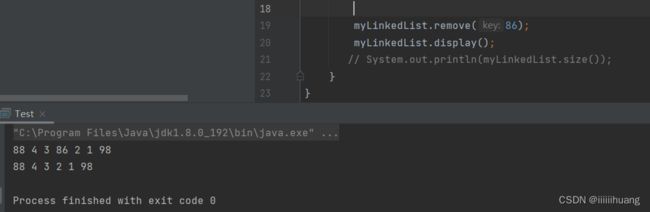
但是上面的代码还有问题

如果只有一个节点时,head = head.next; 那此时head 就是 null,那此时再head.prev 就会引起空指针异常
所以要改成这样:

删除所有值为key的节点
和上面几乎一致,只有一点不一样。
运行结果

清除链表
最简单粗暴的
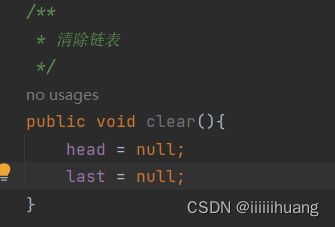

或者把每一个都置为空

完整代码
import java.util.List;
/**
* @Author: iiiiiihuang
*/
public class MyLinkedList {
static class ListNode {
private int val;
private ListNode prev;
private ListNode next;
public ListNode(int val) {
this.val = val;
}
}
public ListNode head;
public ListNode last;
/**
* 头插法
* @param data
*/
public void addFirst(int data){
ListNode node = new ListNode(data);
if(head == null) {
head = node;
last = node;
}else {
node.next = head;
head.prev = node;
head = node;
}
}
/**
* 尾插法
* @param data
*/
public void addLast(int data){
ListNode node = new ListNode(data);
if(head == null) {
head = node;
last = node;
} else {
last.next = node;
node.prev = last;
node = last;
}
}
/**
* 任意位置插入,第一个数据节点为0号下标
* @param index
* @param data
*/
public void addIndex(int index,int data){
ListNode node = new ListNode(data);
checkIndex(index);
if(index == 0) {
addFirst(data);
return;
}
if(index == size()) {
addLast(data);
return;
}
ListNode cur = searchIndex(index);
node.prev = cur.prev;
node.next = cur;
cur.prev.next = node;
cur.prev = node;
}
//找到插入位置
private ListNode searchIndex(int index) {
ListNode cur = head;
while (index != 0) {
cur = cur.next;
index--;
}
return cur;
}
//检查index的位置是否合法
private void checkIndex(int index) {
if(index < 0 || index > size()) {
throw new IndexOutOfBoundsException("位置不合法");
}
}
/**
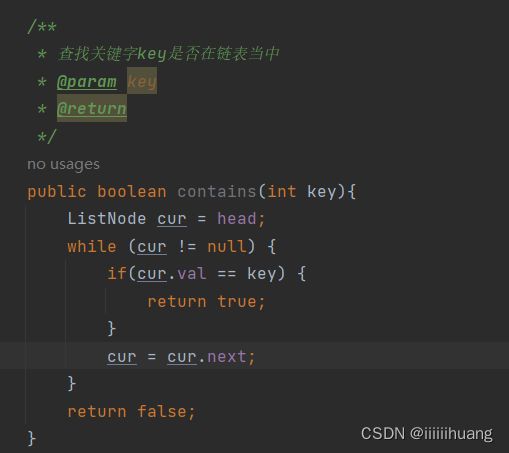
* 查找关键字key是否在链表当中
* @param key
* @return
*/
public boolean contains(int key){
ListNode cur = head;
while (cur != null) {
if(cur.val == key) {
return true;
}
cur = cur.next;
}
return false;
}
/**
* 删除第一次出现关键字为key的节点
* @param key
*/
public void remove(int key){
ListNode cur = head;
while (cur != null) {
if(cur.val == key) {
//删除头节点
if(cur == head) {
head = head.next;
if(head != null) {
//只有一个节点时
head.prev = null;
} else {
last = null;
}
} else {
//删除中间节点 和 尾巴节点
if(cur.next != null) {
//删除中间节点
cur.prev.next = cur.next;
cur.next.prev = cur.prev;
} else {
cur.prev.next = cur.next;
last = last.prev;
}
}
return;
} else {
cur = cur.next;
}
}
}
/**
* 删除所有值为key的节点
* @param key
*/
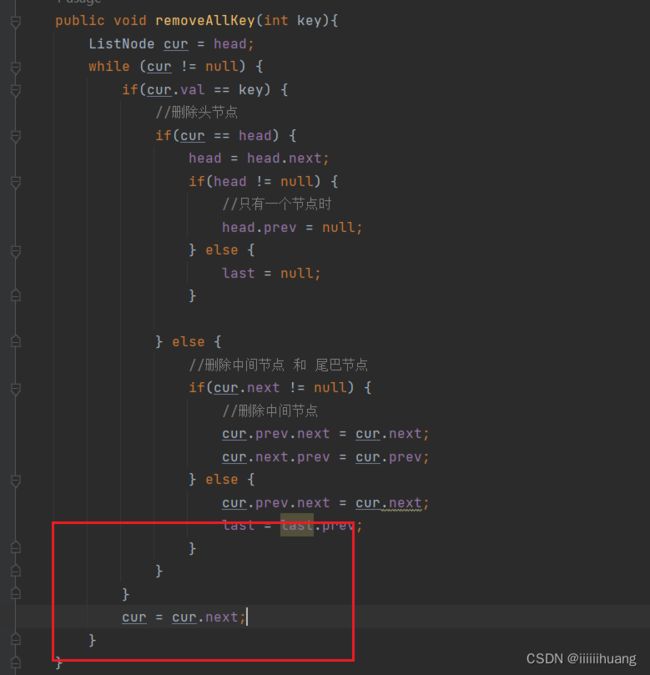
public void removeAllKey(int key){
ListNode cur = head;
while (cur != null) {
if(cur.val == key) {
//删除头节点
if(cur == head) {
head = head.next;
if(head != null) {
//只有一个节点时
head.prev = null;
} else {
last = null;
}
} else {
//删除中间节点 和 尾巴节点
if(cur.next != null) {
//删除中间节点
cur.prev.next = cur.next;
cur.next.prev = cur.prev;
} else {
cur.prev.next = cur.next;
last = last.prev;
}
}
}
cur = cur.next;
}
}
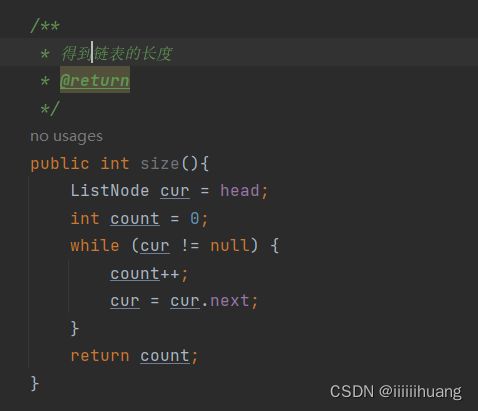
/**
* 得到链表的长度
* @return
*/
public int size(){
ListNode cur = head;
int count = 0;
while (cur != null) {
count++;
cur = cur.next;
}
return count;
}
/**
* 打印链表
*/
public void display(){
ListNode cur = head;
while (cur != null) {
System.out.print(cur.val + " ");
cur = cur.next;
}
System.out.println();
}
/**
* 清除链表
*/
public void clear(){
ListNode cur = head;
while (cur != null) {
//先记录下数据
ListNode curNext = cur.next;
cur.prev = null;
cur.next = null;
cur = curNext;
}
head = null;
last = null;
}
}
LinkedList的使用
先实例化一下

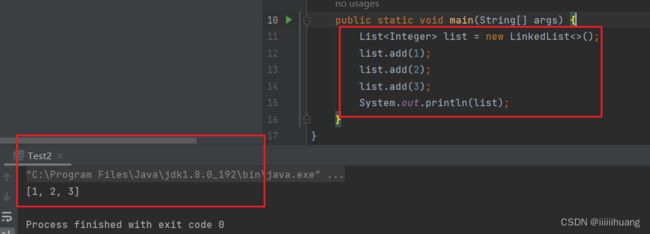
我们之前写的方法他都有,你只要调用就好了。

LinkedList 的 常见方法
| 方法 | 解释 |
| boolean add(E e) | 尾插 e |
| void add(int index, E element) | 将 e 插入到 index 位置 |
| boolean addAll(Collection c) | 尾插 c 中的元素 |
| E remove(int index) | 删除 index 位置元素 |
| boolean remove(Object o) | 删除遇到的第一个 o |
| E get(int index) | 获取下标 index 位置元素 |
| E set(int index, E element) | 将下标 index 位置元素设置为 element |
| void clear() | 清空 |
| boolean contains(Object o) | 判断 o 是否在线性表中 |
| int indexOf(Object o) | 返回第一个 o 所在下标 |
| int lastIndexOf(Object o) | 返回最后一个 o 的下标 |
| List |
截取部分 list |
LinkedList 的总结
1. LinkedList实现了List接口
2. LinkedList的底层使用了双向链表
3. LinkedList没有实现RandomAccess接口,因此LinkedList不支持随机访问
4. LinkedList的任意位置插入和删除元素时效率比较高,时间复杂度为O(1)
5. LinkedList比较适合任意位置插入或删除的场景
ArrayList和LinkedList的区别(顺序表和链表的区别)(面试题)
| 不同点 | ArrayList | LinkedList |
| 存储空间上 | 物理上一定连续 | 逻辑上连续,但物理上不一定连续 |
| 随机访问 | 支持O(1) (有下标) | 不支持:O(N) |
| 头插 | 需要搬移元素,效率低O(N) | 只需修改引用的指向,时间复杂度为O(1) |
| 插入 | 空间不够时需要扩容 | 没有容量的概念 |
| 应用场景 | 元素高效存储+频繁访问时 | 任意位置插入和删除频繁时 |
╰(*°▽°*)╯╰(*°▽°*)╯╰(*°▽°*)╯╰(*°▽°*)╯╰(*°▽°*)╯完 ╰(*°▽°*)╯╰(*°▽°*)╯╰(*°▽°*)╯╰(*°▽°*)╯╰(*°▽°*)╯