RIS 系列 Semantics-Aware Dynamic Localization and Refinement for Referring Image Segmentation 论文阅读笔记
RIS 系列 Semantics-Aware Dynamic Localization and Refinement for Referring Image Segmentation 论文阅读笔记
- 一、Abstract
- 二、引言
- 三、相关工作
-
- Referring image segmentation
- Dynamic convolution
- Multi-modal reasoning
- 四、方法
-
- 4.1 总览
-
- 基础知识
- 语义感知动态卷积
- 每次迭代的路线
- Query 初始化和迭代更新
- 4.2 多模态特征编码
- 4.3 语义感知动态卷积
- 4.4 预测 Masks 和损失函数
- 五、实验
-
- 5.1 数据集和评估指标
-
- 数据集
- 评估指标
- 5.2 实施细节
- 5.3 与其他方法的比较
- 5.4 消融实验
-
- 与 CGAN 和 baseline 方法的比较
- 迭代的次数
- 语义感知动态卷积模块的结构
- Query 更新的方法
- 六、结论
- 附录
写在前面
又是一周周末,估计这周大家已经开学了。那就继续凎论文吧,早点毕业咯~
- 论文地址:Semantics-Aware Dynamic Localization and Refinement for Referring Image Segmentation
- 代码地址:原文暂未提供
- 收录于:AAAI 2023
- Ps:2023 年每周一篇博文阅读笔记,主页 更多干货,欢迎关注呀,期待 5 千粉丝有你的参与呦~
一、Abstract
指代图像分割 Referring image segmentation (RIS) 旨在产生高质量的 mask,现有的方法总是需要采用迭代学习的方法,依赖于 RNNs 或堆叠的注意力层来提炼视觉-语言特征。但基于 RNN 的方法依赖于特定的编码器,基于注意力的方法收益很低。于是本文引入渐进式地学习多模态特征的方法,核心 idea 是利用一个持续更新的 query 作为目标的表示,并在每个迭代步中加强与 qeury 相关的多模态特征而弱化不相关的特征,因此能够逐渐从定位中心转移到分割中心。提出的方法还可以直接插入一些 SOTA 的框架中,实验表明达到了 SOTA 的效果。

二、引言
首先介绍下指代图像分割 Referring image segmentation (RIS) 定义、应用,与传统语义/实例分割的区别。
目前有一些基于全卷积结构的方法,设计跨模态特征融合模块,在公共空间内对齐语言和视觉线索。然而语言和视觉输入可能会存在大量的冗余噪声,于是迭代学习方法出现了:在一些迭代次数内,逐渐地建立跨模态特征对齐和精炼,从而达到更准确的分割精度。
现有的 SOTA 方法通常通过循环神经网络 (RNNs) 或堆叠的注意力层来执行迭代学习,而基于 Transformer 的语言模型能够反复整合多尺度视觉语言特征,然而并未直接解决跨模态对齐。有一些方法引入级联分组注意力的方法,提炼整个图像的跨模态特征,但是缺乏先验信息来关注那些需要关注的区域,特别是目标间经常遮挡时的局部区域。
于是本文提出语言感知的动态定位和细化方法 semantics-aware dynamic localization and refinement (SADLR),其中一个语言感知动态卷积模块,在更新的目标表示 (query) 上执行条件卷积,通过逐渐地加强目标信息从而抑制背景噪声。为辅助定位,首先用输入表达式的语言特征向量来初始化 query,然后在多模态特征图上预测一个卷积核。在接下来的每一步中,采用上一步池化的目标上下文来更新 query,并再一次执行动态卷积。
实验表明将本文的方法应用在三个 SOTA 方法 (LTS、VLT、LAVT) 时,效果很好。
三、相关工作
Referring image segmentation
之前基于 CNN 的方法关注于跨模态特征融合,最近一些方法利用 Transformer 结构来聚合视觉-语言表示。为了缓解跨模态上下文建模的一些困难,一些方法采用迭代式学习和跨模态特征精炼的设计,这些方法主要从视觉特征中捕捉多模态语言信息。本文的工作与 CGAN 最相关,利用级联的多头注意力层迭代优化整个图像的跨模态映射图。不同的是,CGAN 不寻求利用预测作为先验来帮助提炼更重要的区域。实验表明级联注意力模型对那些基于传统模型 (非 Transformer) 的结构更有效。下图是几种方法的对比图:

本文提出的方法相较于上面这些方法有两点优势:不依赖于特定语言编码器或多模态特征编码计划的选择;能够泛化到到大量的 SOTA 模型上。
Dynamic convolution
动态卷积的应用非常广泛,一开始在短范围天气预测中被提出,最近则是在一些基于 query 的目标检测方法中流行。在这些模型中,设置一组可学习的 embedding 作为潜在的目标特征,于是根据这些 queries,利用动态的权重进行定位和分类目标。相比之下,本文利用动态卷积来解决自然语言的分割问题。
在那些解决指代视频目标分割的方法中,动态卷积/过滤指的是预测出相同通道数量的分类权重,从而作用于特征图。相比之下,本文旨在生成一组信息丰富的特征图,突出与动态 query 有关的语义。
Multi-modal reasoning
多模态推理包含大尺度预训练、通用的 Transformer 模型、MDETR。
四、方法
4.1 总览

基础知识
如图 3 所示,由一幅图像和一句表达式组成输入。首先利用一个语言编码器,例如 BERT 或 RNN 从输入的表达式中提取一组语言特征 L ∈ R C l × N L\in \mathbb{R}^{C_l\times N} L∈RCl×N,其中 C l C_l Cl 表示通道数量, N N N 为单词的个数。接着将输入的图像和语言特征 L L L 送入一个多模态特征编码器网络中,确保语言特征和视觉特征共同在单个特征空间中,以至捕捉到对齐的信息。将此多模态特征图记为 Y ∈ R C × H × W Y\in \mathbb{R}^{C\times H\times W} Y∈RC×H×W,其中 C C C 为通道的数量, H H H、 W W W 分别是图像的高和宽。
语义感知动态卷积
在后续处理中,通过语义感知动态卷积模块来迭代地提炼多模态特征。此模块每一层都从输入特征向量中预测一个卷积核,然后对多模态特征图卷积。本文称这种生成核的特征向量为 “query”。
每次迭代的路线
假设在提炼过程中有 n n n 次迭代,将动态 query 在每次迭代过程 i ∈ { 1 , 2 , … , n } i\in \{1,2,\ldots,n\} i∈{1,2,…,n} 中表示为 Q i ∈ R C Q_i\in \mathbb{R}^{C} Qi∈RC。在每次迭代过程中,将 query Q i Q_i Qi 和多模态特征图 Y Y Y (来源于编码阶段) 送入语义感知动态卷积模块中,其中每个卷积核来源于 Q i Q_i Qi 和 Y Y Y 的卷积。语义感知动态卷积模块的输出为一组与 Q i Q_i Qi 相关的特征图,表示为 Z i ∈ R C × H × W Z_i\in \mathbb{R}^{C\times H\times W} Zi∈RC×H×W,接下来使用 1 × 1 1\times1 1×1 卷积将 Z i Z_i Zi 投影到粗糙的得分图上,表示为 R i ∈ R 2 × H × W R_i\in \mathbb{R}^{2\times H\times W} Ri∈R2×H×W,其中 0 0 0 表示背景, 1 1 1 表示目标类别。在 R i R_i Ri 上应用 argmax 得到二值化后的目标 mask M i ∈ R H × W M_i\in \mathbb{R}^{H\times W} Mi∈RH×W。
Query 初始化和迭代更新
在不同的迭代次数内,使用不同类型的 queries 来强调不同类型的特征。首先,在第一次迭代时,用句子特征向量 S ∈ R S\in \mathbb{R} S∈R 来初始化 Q 1 Q_1 Q1。其中通过对语言编码器的输出 L L L 加个平均池化和通道维度的线性投影得到 S S S 。由于 Q 1 Q_1 Q1 包含纯粹的语言信息,语义感知动态卷积模块的输出 Z 1 Z_1 Z1 就能突出指代定位的信息。在第 i i i 次迭代时,利用 M i − 1 M_{i-1} Mi−1 得到新的 Q i Q_i Qi,而 Q i − 1 Q_{i-1} Qi−1 的更新则源自 Y Y Y 中池化后的目标特征向量 O i − 1 O_{i-1} Oi−1。这一过程如下:
O i − 1 = A v g P o o l ( M i − 1 , Y ) Q i = Q i − 1 + O i − 1 \begin{aligned} O_{i-1}& =\mathrm{AvgPool}(M_{i-1},Y) \\ Q_{i}& =Q_{i-1}+O_{i-1} \end{aligned} Oi−1Qi=AvgPool(Mi−1,Y)=Qi−1+Oi−1其中 A v g P o o l \mathrm{AvgPool} AvgPool 表示在 Y Y Y 的空间维度上计算特征向量的加权平均,而二值 mask M i − 1 M_{i-1} Mi−1 为权重图。这一 query 更新计划旨在逐渐地整合目标上下文信息到 query 中,从而在每次的迭代中使得 M i − 1 M_{i-1} Mi−1 更加准确。
4.2 多模态特征编码
默认采用 LAVT 作为多模态特征编码网络,利用级联的视觉 Transformer 来嵌入视觉和语言信息。在视觉 Backbone 的每个阶段中,一个像素-单词注意力用于对齐每个空间位置上的语言特征和视觉特征,一个语言路径直接整合多模态线索到视觉 Backbone 的下个阶段。尽管如此,本文的方法不受限于特定的多模态特征编码网络。
4.3 语义感知动态卷积

如上图 4 所示,语义感知动态卷积模块由两层动态卷积组成。在每次 SADLR 迭代时,给定 query Q i Q_i Qi,首先应用线性投影层产生动态核 K i ∈ R C × C ′ K_i\in\mathbb{R}^{C\times C^{\prime}} Ki∈RC×C′,其中 C C C 和 C ′ C^{\prime} C′ 分别为输入和输出的通道数。之后输入的特征图 Y Y Y 和动态核 K i K_i Ki 相乘,后面跟着一个层归一化和 ReLU 非线性激活。另外一个卷积核 K i ′ ∈ R C ′ × C K_i^{\prime}\in\mathbb{R}^{C^{\prime}\times C} Ki′∈RC′×C通过第二个线性投影在 Q i Q_i Qi 上产生。类似的,在前一层的输出和 K i ′ K^{\prime}_i Ki′ 间进行矩阵乘法,后接一个层正则化及 ReLU 非线性激活层。
4.4 预测 Masks 和损失函数
通过上采样将粗糙的得分图 R i R_i Ri 调整到输入图像的分辨率上,再使用 argmax 沿着通道维度即可得到预测的 masks。损失函数如下:
L = λ 1 L 1 + λ 2 L 2 + . . . + λ n L n L=\lambda_{1}L_{1}+\lambda_{2}L_{2}+...+\lambda_{n}L_{n} L=λ1L1+λ2L2+...+λnLn其中 L i L_i Li 表示第 i i i 次迭代的单个损失, λ i \lambda_i λi 为损失的平衡权重。每个损失采用平均 Dice 损失计算目标类别和背景类别。在推理过程中,最后一次的迭代 mask 用于预测。
五、实验
5.1 数据集和评估指标
数据集
RefCOCO、RefCOCO+、G-Ref。
评估指标
准确度 precision@K (P@K),其中 K 表示 IoU阈值;mean IoU (mIoU);overall IoU (oIoU)。
5.2 实施细节
大多数训练和推理设置与 LAVT 相同。BERT-base 为语言编码器,Swin-B 为 Backbone 网络。BERT 权重来源于 HuggingFace,Swin 初始化的权重来源于预训练在 ImageNet-22K 上的权重,剩余的参数随机初始化。端到端训练,AdamW 优化器,初始学习率 5 e − 5 5e-5 5e−5,权重衰减 2 2 2,“poly” 学习率计划。通道数 C l = 3 C_l=3 Cl=3, C = 512 C=512 C=512。默认的迭代次数 n = 3 n=3 n=3,于是权重超参数 λ 1 \lambda_1 λ1、 λ 2 \lambda_2 λ2、 λ 3 \lambda_3 λ3 分别设为 0.15,0.15,0.7(在确保整体权重为 1 时,给最后的迭代施以最大的权重值 (≥0.5),剩下的平分)。训练 40 epochs,batch_size 32。输入图像尺寸 480 × 480 480\times480 480×480,句子长度 20。
5.3 与其他方法的比较


5.4 消融实验
与 CGAN 和 baseline 方法的比较

迭代的次数
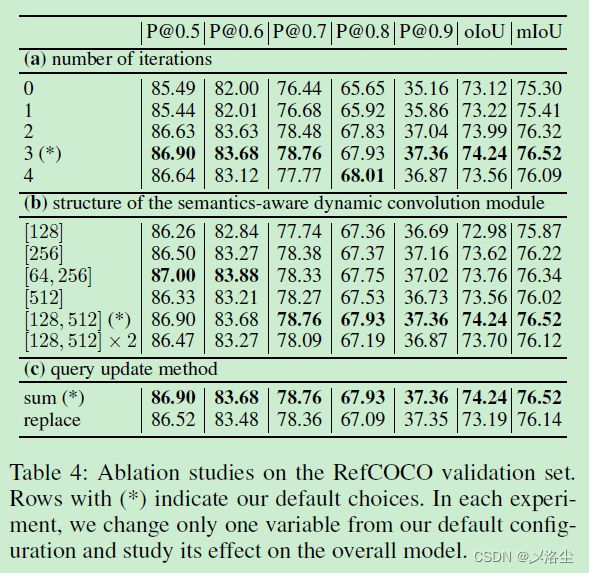
语义感知动态卷积模块的结构
上表 4 ( b )。
Query 更新的方法
上表 4 ( c )。
六、结论
本文提出语义感知动态定位和提炼方法用于 RIS,基于聚合的目标上下文迭代地提炼多模态特征图。实验表明方法的泛化性和效果很好。
附录

写在后面
这篇文章就提出了一个动态卷积结构和迭代方法,看着消化下就好。论文中反复出现对参数的描述,看样子这不是人能犯的错误呀。结合致谢一部分,有的是 AI 写的,这就不奇怪了。 另外,图 1,2 均未在论文中引用,需要注意。