论文浅尝 - IJCAI | Knowledge is NOT always you need: 外部知识注入预训练模型的利与弊...
转载公众号 | 浙大KG
论文题目:Drop Redundant, Shrink Irrelevant: Selective Knowledge Injection for Language Model Pretraining
本文作者:张宁豫(浙江大学)、邓淑敏(浙江大学)、张亦弛(阿里巴巴)、张伟(阿里巴巴)、陈华钧(浙江大学)等
发表会议:IJCAI 2021 (欢迎转载,转载请注明出处)

引言
近年来,有很多工作尝试将知识图谱等外部知识融入到BERT为代表的预训练语言模型中。但是,不少外部知识存在一定程度的噪音,且不少实体存在歧义。事实上,先前工作已发现预训练语言模型中捕获了相当数量的实体、常识知识,那么不加选择地将所有的外部知识融入语言模型真的最优么?本文探讨了语言模型中融入知识噪音的问题,并提出了一种基于频率采样和谱正则化的选择性知识融入方法。在基准数据集上的实验结果表明,我们的方法可以增强最新的知识注入的预训练语言模型。
一、前言
2018年以来,预训练语言模型的研究风起云涌。由于预训练过程缺乏对知识的捕捉,学者们提出不少将知识融合预训练语言模型的方法如ERNIE[1]、KnowBERT[2]、CoLake[3]等。知识的融入的确提升了不少知识密集型任务如关系抽取、实体分类等的效果。然而,外部知识中存在相当程度的噪音。一方面,由于实体的歧义性,文本可能会被融入完全错误、不相关的实体知识。比如,对于“qq飞车小橘子”这句话,如果将水果“小橘子”的实体知识融入语言模型,对语义理解反而可能会其负面作用。另一方面,并不是所有的三元组知识都能促进语义理解。比如对于“斯蒂芬·库里和克莱·汤普森带领勇士队勇夺2015年nbva冠军”这句话,三元组知识(斯蒂芬·库里,女儿,赖利)在可能对理解语义起不到多少帮助。事实上,CokeBERT[4]和K-BERT[5]都曾在实验中发现,不加选择的融入知识并非最优。
从另一个角度,2019年Allan 发表在EMNLP2019的论文[6]及一些后续工作[7,8,9]指出,预训练语言模型在参数空间其实学习到了大量的实体、常识知识,甚至可以作为一个连续型知识库,这启发了我们思考:语言模型注入的知识真的越多越好么?外部的噪音知识对模型有什么影响呢?我们有没有办法对知识加以选择更好地进行知识注入呢?其实,[10]中有学者发现,不加选择的注入实体知识并不一定会带来知识密集型任务性能的提升。受到这些工作启发,我们首先分析了知识中噪音对预训练语言模型的影响。
二、分析
我们首先采样了部分实体和实例,并根据实体频率分析不同知识注入的差异,其次分析了知识噪音对模型的影响。由于很难判断知识图谱中究竟有多少噪音,因此我们采取人工控制噪音的方式来分析,这里的噪音主要是指实体的歧义性。我们通过实体替换的方式来人工制造知识噪音。
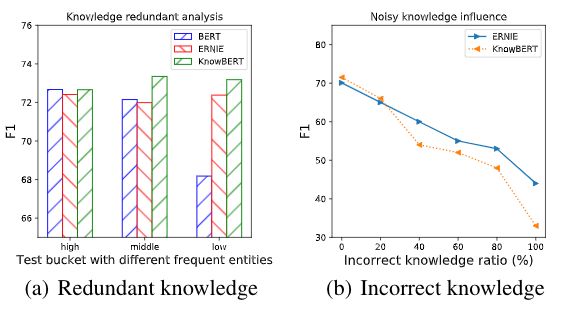
如上图a所示,我们发现对于低频实体而言,注入实体的增益相对较大,这一发现也同[10]中的结论类似。在图b中,我们发现,随着噪音的注入,模型性能显著下降。这一发现也同[11]中的随机扰动知识图谱导致的结论一致。由此我们发现,一般来说,知识噪音会损害模型性能(极少数情况噪音会修复知识图谱中错误的关联关系进而提升鲁棒性,见[11])。基于此发现,我们可以通过频率对知识进行选择,以注入对模型更加有用的知识,减少噪音注入的可能性。
受到迁移学习中负迁移理论的启发[12,13],我们进行进一步分析。我们对知识注入模型的权重和特征及其奇异值进行分析,以验证语言模型是否可以适用于负迁移理论。
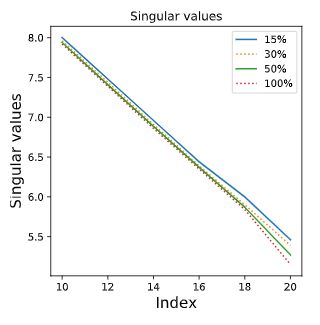
具体的说,我们对预训练语言模型的最后一层输出特征进行SVD分解,并比较模型在给定15%、30%、50%和100%训练样本时奇异值的情况,如下公式所示:

如下图所示,我们发现在下游任务微调过程中,模型特征的尾部奇异值往往会自动下降,这一发现也和论文[13]中结论一致,也就说注入的噪音知识可以类比成迁移学习中造成负迁移的原因之一。基于此发现,我们可以直接对尾部奇异值进行约束,以减轻源领域(注入了噪音的语言模型)对下有任务的影响。
三、方法
方法包含两部分,首先我们提出一种基于频率的实体采样算法来选择知识(这一方法不需要额外参数,也可以基于注意力机制来选择知识如[14])。先前的工作表明,语言模型其实已经掌握了大部分高频实体知识,因此我们对预训练语料(维基百科)中的高频实体设置一个较低的权重,鼓励模型注入低频实体。
然而,由于知识图谱中存在大量一对多、多对一的事实知识,这部分知识高频实体也较难习得,且这些实体包含的信息相对较为丰富,因此,我们提高同一个文档内的实体间跳数较少的实体的采样权重(超参数控制),具体采样公式如下:

其次,我们采用了一种谱正则技术来减轻噪音对微调的影响。一般来说传统的机器学习模型可以通过对参数或特征进行正则来减轻迁移学习的负迁移现象,然而对于语言模型,其参数维度远大于特征维度,因此我们仅对特征进行正则。我们对语言模型的输出特征进行SVD分解,并对尾部k个特征值进行约束:
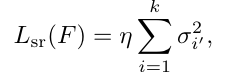
整体的模型图如下:

四、实验
我们基于维基百科重新进行了知识注入预训练(ERNIR,KnowBERT),并在多个知识密集型数据集上进行了实验,如下表所示,我们的方法在大多数数据集上都取得了较好的效果。此外,我们还发现,通过知识选择和正则化,我们的方法在GLUE上的性能下降小于原始的知识注入模型。

五、总结与展望
在本文中,我们分析了知识噪音对语言模型性能的影响,并提出一种基于知识选择的知识融入方法。随着人工神经网络技术的不断发展,数据驱动渐入天花板。尽管超大规模的预训练语言模型如GPT-3取得了令人惊艳的效果,它仍然经常闹笑话。数据+知识是驱动未来认知AI的重要路线之一。对于通用的、高频的实体、常识等知识,也许可以通过大规模预训练习得,然而更多的低频长尾知识、多元关联知识、复杂逻辑知识,数据驱动的方法较难使模型具备相应的能力,可能知识注入和融合符号化推理的方式更加有效。我们的工作探讨了如何更好的利用知识,但仍然有模型训练慢、知识选择相对Ad hoc等不足。在未来很多可以改进的方向如:
1)深入探索哪些知识对神经网络更有用?
神经网络通过海量的数据预训练可能已经在参数空间习得部分知识,这些连续空间的参数更加有利于机器去适应下有任务,[15]探索了模型究竟掌握了哪些常识知识,仍需要更多的工作去探索神经网络的能与不能。
2)如何高效注入知识?
符号化知识和向量化表征存在显著的异构性,[16]提出了一种基于Graph-to-text的方式减轻了数据差异,然而对于大多数人类可读的知识,如何高效的将其转换为机器可理解的方式,并注入模型中,仍面临较大挑战。
3)如何更新模型中的知识?
互联网每天会产生海量的新文本,人类知识也在不断更新,比如在不同时间阶段三元组知识(美国,现任总统,特朗普)会更新为(美国,现任总统,拜登)。因此,如何更新预训练语言模型参数空间的知识面临研究挑战。[17]对这一问题进行了初步探索。事实上,降低预训练语言模型的迭代成本,使得模型低碳、经济、环保具有非常重要的现实意义。
4)如何解耦模式识别和符号推理?
神经网络由于其强大的非线性拟合能力,使其在一定程度上具备超越人类的模式识别能力。然而,对于一些基本的常识、数值、逻辑推理问题,预训练语言模型经常闹笑话。融合数据和知识,进行神经符号化学习可能是使机器具备推理能力的重要技术路线之一。然而神经网络的向量空间高度抽象,符号空间相对离散,如何针对具体任务将符号表示Grounding到向量空间,解耦模式识别和符号推理仍面临严峻挑战。
[1] ERNIE: Enhanced Language Representation with Informative Entities. ACL2019
[2] Knowledge Enhanced Contextual Word Representations. EMNLP2019
[3] CoLAKE: Contextualized Language and Knowledge Embedding.COLING2020
[4] CokeBERT: Contextual Knowledge Selection and Embedding towards Enhanced Pre-Trained Language Models
[5] K-BERT: Enabling Language Representation with Knowledge Graph.AAAI2020
[6] Language Models as Knowledge Bases? EMNLP2019
[7] Language Models as Knowledge Bases: On Entity Representations, Storage Capacity, and Paraphrased Queries.
[8] How can we know what language models know
[9] Language Models are Open Knowledge Graphs.
[10] KEPLER: A Unified Model for Knowledge Embedding and Pre-trained Language Representation. TACL2020
[11] Learning to Deceive Knowledge Graph Augmented Models via Targeted Perturbation ICLR2020
[12] Transferability vs. Discriminability: Batch Spectral Penalization for Adversarial Domain Adaptation. ICML2019
[13] Catastrophic Forgetting Meets Negative Transfer: Batch Spectral Shrinkage for Safe Transfer Learning. NeurIPS 2020
[14] Commonsense Knowledge Aware Conversation Generation with Graph Attention. IJCAI2018
[15] Dimensions of Commonsense Knowledge
[16] Benchmarking Knowledge-enhanced Commonsense Question Answering via Knowledge-to-Text Transformation. AAAI2021
[17] Knowledge Neurons in Pretrained Transformers
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 网站。