Google Cloud Architech flowchart (help you better choose cloud product)
Which compute option ?
GCP has a continuum of compute options which can be graphically depicted as:

It may be obvious at either end of the continuum which option you choose but the decision becomes less straight forward in the middle so flowchart to the rescue :
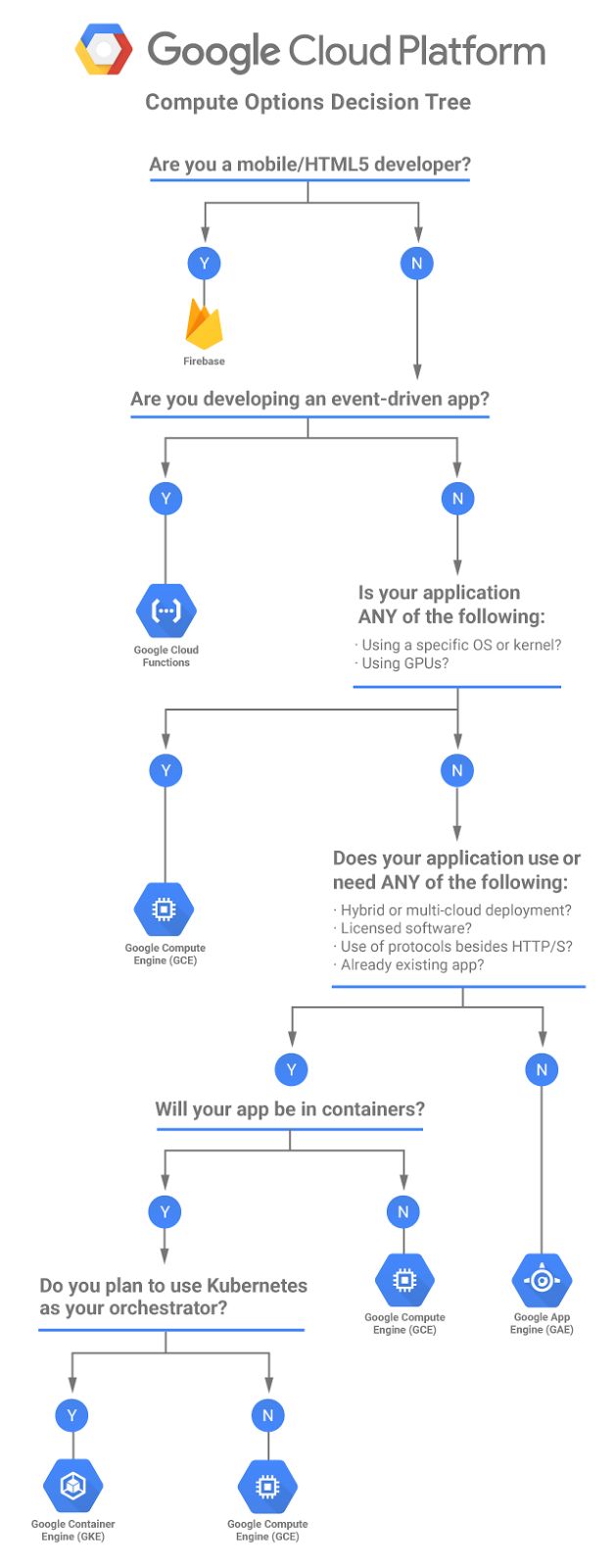
The compute flowchart with accompanying words can be found here and a nice table comparing the compute options is here.
What Storage type?
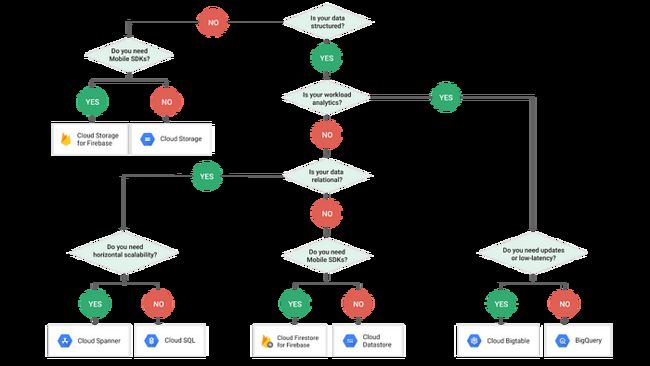
Data data data data data! ( Sung to the 60’s Batman theme music) . I struggle to think of any application where data isn’t a thing . The myriad ways you can store your data is probably after considering the security controls needed the most important decision you need to make. GCP has your back with a great flowchart and tables ( I love tables too) which can be found here
Which Network Tier?
GCP’s network even if I say so myself is fantastic but it’s recognised that not every use case needs to optimize for performance and cost may be the driver. So welcome to Network tiers.
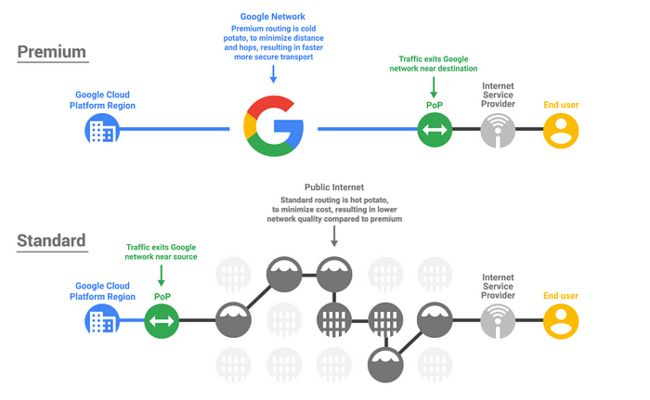
You can see the funky animated gif for the above image here
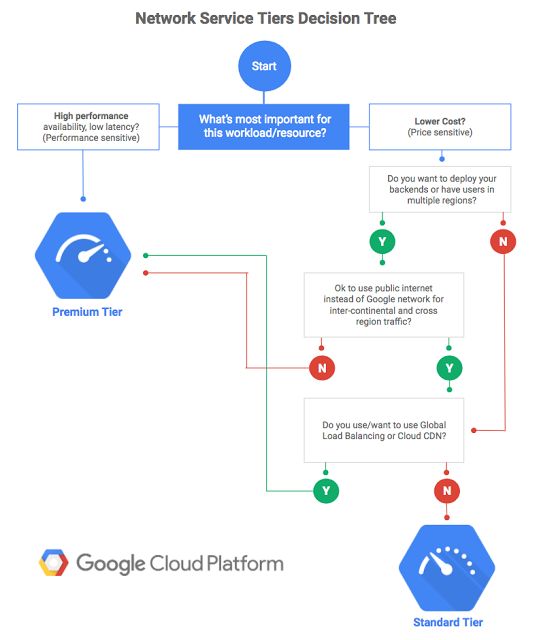
The words that go with the above can be found here . There are some useful tables there too.
How to manage encryption keys
GCP has a continuum of ways for you to manage your encryption keys graphically depicted as
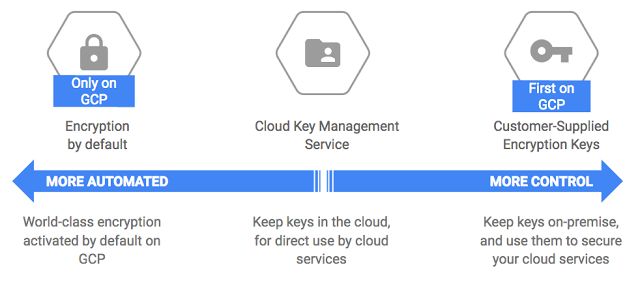
Yes I know that the continuum graphic alone is probably all you need but when the announcement for the KMS service was made they produced a flow chart and I Just had to include it here
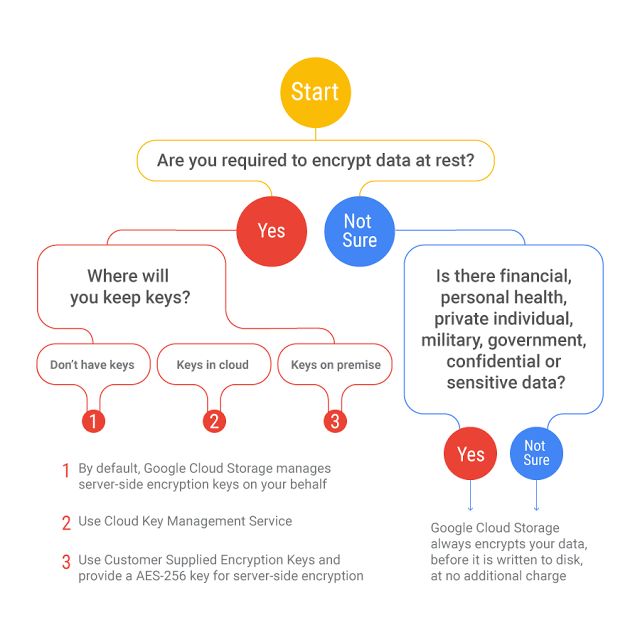
The words that go with the above can be found here and a nice table that compliments the flow chart can be found here at the Encryption at rest landing page . ( Everything you ever wanted to know about Encryption at rest on GCP and more !)
Which Authentication option ?
I’m going to sneak in here a flowchart of my own as GCP doesn’t have one for this yet!! ( hint hint!)
Update Dec 2nd 2017:
Neal Mueller responded to my hint about wanting a GCP flowchart for Authentication and it’s so much prettier than my version see updated flowchart below! Thanks Neal.
So just to make sure we are on the same page authentication identifies who you are ! This flowchart is focused on wether its identity — > application ( deployed on GCP) or identity — > direct access to GCP
Need an identity mgt product?
How you manage your identities depends on the use case. Need to manage users who will have direct access to GCP resources versus users who need access to an application that you’re hosting on GCP? Different requirements and thus different solutions required. Here’s a flowchart to help you figure out out the right solution for your use case

The words that go with the flowchart can be found here.
Choosing a Load balancer
Load balancing is great it allows you to treat a group of compute resources as a single entity providing an entry point that has in the case of GCP load balancing services a single anycast IP address. Combining GCP Load balancers with autoscaling you can scale the resources up and down according to metrics you configure. There are loads more cool features but you get the idea. So what type of load balancing service do you need? Layer 7, layer 4, global , regional? Maybe you need an internal load balancer well there’s a flowchart for helping you decide ( Okay you knew that was coming didn’t you? )
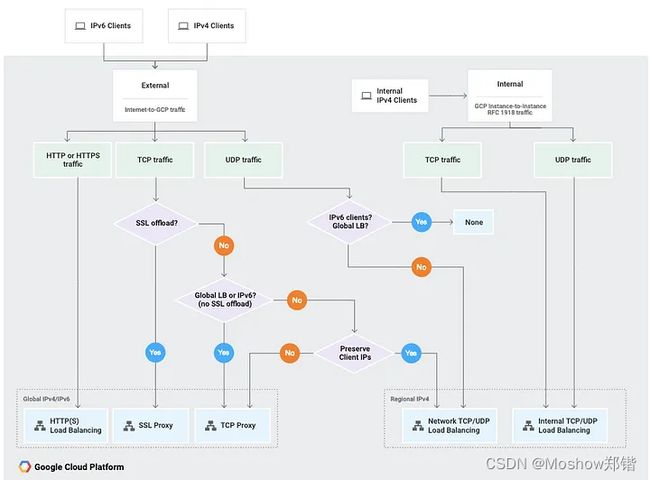
Here are the words to go with the flowchart. Once you have figured out what load balancing option is likely to address your needs have a look at the load balancing overview page as a first stop before diving in.
Choosing a Cloud Storage class for your use case
Cloud Storage (GCS) is a fantastic service which is suitable for a variety of use cases. The thing is it has different classes and each class is optimised to address different use cases. All the storage classes offer low latency (time to first byte typically tens of milliseconds) and high durability. You can use the same APiIs , lifecycle rules etc . Basically the classes differ by their availability, minimum storage durations, and charges for storage and access.
There are 4 classes that you need to care about .
Multi regional — geo redundant storage optimised for storing data that is frequently accessed (“hot” objects) for example web site serving and multi media streaming.
Regional — Data can be stored at lower cost, with the trade-off of data being stored in a specific regional location, instead of having redundancy distributed over a large geographic area. This is ideal for when you need the data to be close to the computing resources that process the data say for when using Dataproc.
Nearline — Nearline Storage is ideal for data you plan to read or modify on average once a month or less. Nearline Storage data stored in multi-regional locations is redundant across multiple regions, providing higher availability than Nearline Storage data stored in regional locations. This is great for backups . You should be carrying out regular DR fire drills at least once a month which includes recovering your data from your backups !
Coldline- a very low cost, highly durable storage service. It is the best choice for data that you plan to access at most once a year, due to its slightly lower availability, 90-day minimum storage duration, costs for data access, and higher per-operation costs. This is ideal for long term archiving use cases
Here’s a flow chart that helps you decide which storage class is appropriate for your use case when you don’t feel like reading too many words to figure out your choices ( which after all is what flowcharts are for ) .
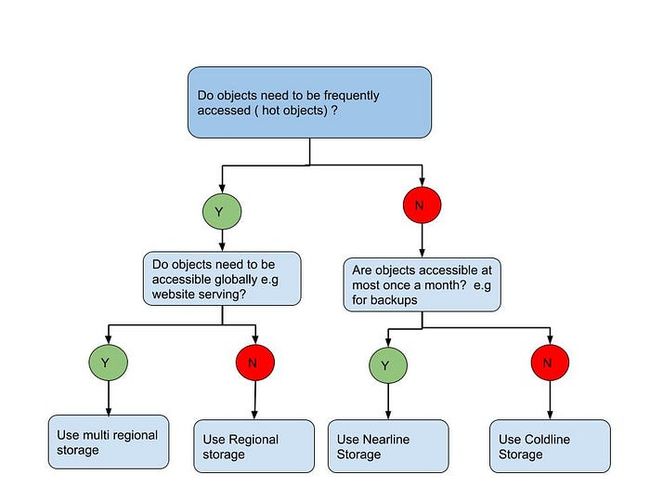
For an overview of the GCS storage classes see here
ML or SQL ?
Always wanted to know whether you really need to use ML or whether a SQL query will suffice well
Sara Robinson
tweeted this flow chart

From https://twitter.com/SRobTweets/status/1053273512079699968
