HTTP协议
文章目录
- 一.概念
-
- 1. 服务器&客户端
- 2.URL
-
- 1) URL路径
- 2) URL中的参数(query String)
- 3) URL片段标识符
- 4) URL格式小结
-
- URL encode
- URL encode 注意
- 二、HTTP
-
- 1.HTTP格式
-
- 1) 请求格式
- 2) HTTP响应格式
- 3) HTTP请求响应格式小结
- 2.HTTP请求中的方法
-
- 1) 哪些方式会触发HTTP请求?
- 2) GET请求格式的注意事项
- 3) POST请求
- 4) GET和POST的区别
- 5) 传输数据
- 3. 请求报头
-
- Host
- Content-Length
- Content-Type
- User-Agent
- Referer
- Cookie
- 正文body
- 4.状态码
-
- 200 OK
- 404 Not Found
- 405
- 403 Forbidden
- 500 Internal Server Error
- 302 Move temporarily
一.概念
HTTP全称叫做超文本传输协议,超文本,其实就是指"HTML"(超文本里面包含一些特殊的东西,图片,链接,音频),HTTP最早就是为了下载HTML
HTTP这个协议在传输层主要是基于TCP来实现了
TCP传输字节流的协议,只是把数据按照字节来传输而已,TCP并没有传输一个"结构化"的数据
应用层协议,就是在干这件事情,就是把传输层的字节流赋予一定的含义。HTTP协议是应用层协议中的典型代表。
HTTP协议主要有三个大版本(不算小版本)
- HTTP1:也是现在主流使用的版本,基于TCP
- HTTP2:支持的不多,也是基于TCP,主要引入的是安全性(相当于HTTPS的加强版)
- HTTP3:还在建设中,基于UDP,主要是为了提高效率
1. 服务器&客户端
在网络通信中,主要涉及到几个核心概念
- 服务器 vs 客户端
- 请求 vs 响应
服务器和客户端之间的沟通,存在多种模型
-
一发一收 ,请求和响应是一一对应
HTTP协议就是一发一收这种传输模型
-
多发一收
多个请求对应到一个响应,典型的场景,大文件上传,把文件分成多份发送
-
一发多收,一个请求,对应到很多的响应,典型场景就是看直播
-
多发多收,多个请求,对应到多个响应
正向代理
站在服务器的角度,把客户端隐藏起来
反向代理
站在客户端的角度,把真实的服务器给藏起来,咱们访问到的很多的服务器,其实可能都是反向代理
2.URL
URL (Uniform Resource Locator 统一资源定位符) ,也就是我们俗称的 网址
网络的很多协议,都是相关的标准文档来描述它们的,RFC系列文档,各种协议,具体的细节规范,都是RFC系列文档来描述的
RFC文档

现在几乎看不到user:pass这个种格式了现在登录都是直接搞一个登录页面,在登录页面里,去写用户名和密码(input),以表单或者是ajax的形式进行提交
URL不仅仅是给HTTP服务的,还能够给很多协议提供服务
https://cn.bing.com/search?q=java&qs=n&form=QBRE&sp=-1&lq=0&pq=java&sc=10-4&sk=&cvid=ABF82973A61640E28A767B238D2E6BBD&ghsh=0&ghacc=0&ghpl=
协议名后面的 :// 这个是固定内容
cn.bing.com这是必应的域名,域名本质上就是一个ip地址,就是为了方便记忆, 地址部分不包含 /
地址后面还可以带一个冒号:,冒号后面可以写一个具体的端口号,就表示要访问的服务器端口号
如果不写端口号,浏览器给一个默认的端口号,对于HTTP协议来说,默认的端口号就是 80.
对于HTTPS来说,默认的端口号就是443
一个服务器,具体绑定的是哪个端口,这个就不一定。如果对方服务器绑定的端口不是默认端口,就需要进行修改了
1) URL路径
URL中的路径,表示访问服务器上的不同资源,一个服务器程序上有很多资源(有很多的HTML,有很多的图片,CSS,JS)
/dir/index.html
2) URL中的参数(query String)
URL中的参数,也叫做"查询字符串",query String
q=java&qs=n&form=QBRE&sp=-1&lq=0&pq=java&
sc=10-4&sk=&cvid=ABF82973A61640E28A767B238D2E6BBD&ghsh=0&ghacc=0&ghpl=
这些参数,都是浏览器给服务器传递的一些信息
这里的参数,有很多,也可以没有
这些参数都是以键值对的方式来组织的
键值对之间 使用&来分割
键和值之间 使用 = 来分割
query string 整体,使用?来作为起始标志
每个键值对都表示啥意思呢?这是程序员自己约定的,不同的网站,这里的查询字符串中的键值对,就截然不同
预定 query string 中传递哪些参数,也是咱们在进行 web 开发时重要工作
3) URL片段标识符
URL中的片段标识符,不是特别常见通常用于定位一个HTML页面的具体位置,这个就是在"文档类"网站中,非常常见。


4) URL格式小结

- 协议名称:URL支持很多种协议
- 用户名密码:现在已经废弃了,不再使用
- 服务器地址:可以是域名,也可以是IP地址
- 端口号:如果不写端口号,就会有一个默认值(浏览器自动加的),HTTP默认值80,HTTPS默认值443
- 路径:表示服务器上面具体的哪个资源
- 查询字符串:浏览器给服务器传递的一些参数(这是程序员自己定义的)
URL的初心就是用来区分一个网络上的唯一资源
- 先通过服务器地址,定位到一个具体的服务器
- 再通过端口号定位到一个具体的应用程序
- 再通过路径定位到这个应用程序管理的一个具体资源
- 再通过查询字符串,对这个具体资源的要求做出进一步解释
- 最后通过 片段标识 来确定定位到这个资源的哪个部分
URL encode
URL 中有些东西是用户自定义的,典型的就是 query string,用户自定义的 query string 中,是可能存在一些 特殊符号
比如 :/ ? & . 等一些特殊符号
如果query string中也包含了上面这些特殊符号,就可能导致浏览器/服务器解析URL的时候出错
本来人家程序是判定 URL中 ? 后面的就是 query string ,如果自己写的 query string 里有写了个 **?**那么此时浏览器就懵逼了,到底哪里是query string 。
稳妥的做法,应该就是让后面的query string里,不要包含特殊字符,针对特殊字符,直接进行转义(浏览器就能自动进行)
除了特殊符号之外,像汉字之类的,也是需要 urlEncode
把特殊字符,转成转义字符 :urlEncode
把转义字符,还原成原来的字符:urlDecode
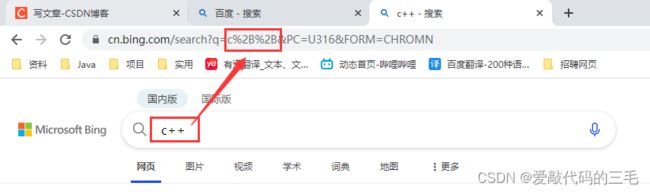
query=c%2B%2B这个就是标识用户输入的查询词,%2B%2B就是url encode 的结果,所谓的转移,其实就是把这个特殊字符里面的值,按照十六进制来表示,每个字节在前面放一个 %
+的转义就是 %2B

https://cn.bing.com/search?q=%E5%AD%A6%E4%B9%A0&qs=n&form=QBRE&sp=-1&lq=0&pq=%E5%AD%A6%E4%B9%A0&sc=13-2&sk=&cvid=6EA9B877DAD84A90A17BE689951BB9C8&ghsh=0&ghacc=0&ghpl=
%E5%AD%A6%E4%B9%A0就是学习两个字 urlEncode的结果

URL encode 注意
一定要重点注意,为啥要 url encode
虽然浏览器会自动的对这里的特殊符号进行 encode,但是有的时候,咱们手动构造的URL,不一定能自动 encode。
稳妥起见,如果咱们需要自己构造URL,URL里面带有特殊符号的时候,一定要手动的encode,否则就可能请求发送失败。
比如,html有个a标签
<a href="https://11.22.33.44/path?query="学习">a>
<a href="https://11.22.33.44/path?query="%E5%AD%A6%E4%B9%A0"">
这里千万不能就在代码中写"学习",而是要手动的encode,如果你自己测试用chrome,很可能是没问题。
有的浏览器能访问,有的浏览器就不能访问,所以一定要手动encode
二、HTTP
1.HTTP格式
1) 请求格式

HTTP的请求格式可以分为4个部分,分别为首行、请求头、空行、正文
1.首行
HTTP请求的行有3部分,使用空格来分割
请求使用的方法 请求的URL HTTP的版本号
GET https://www.baidu.com/ HTTP/1.1
2.请求头(header)
请求头header中都是一些键值对,键值对之间使用换行符来进行分割,键和值之间使用:+空格来分割
请求头有多少行是不固定的,但是请求头是使用一个空行来作为结束标记

3.空行
通过这个空行来表示请求头header部分已经结束

4.正文
当前这个访问百度的正文也是一个空行,有的请求有正文,有的请求没有正文。正文可以有很多种,比如常见的json
2) HTTP响应格式

HTTP响应也是分为4个部分,其中也是包括首行、请求头、空行、正文
1.首行
HTTP响应的首行由三个部分组成,版本号、状态码、状态码描述
HTTP/1.1 200 OK
2.响应头
响应头有多个键值对,每一个键值对占一行,键和值之间职业:+空格来分割
3.空行
作为响应头的结束标记
4.正文
响应的正文可以有也可以没有
3) HTTP请求响应格式小结
请求
请求方法 请求的URL 版本号
请求报头key: 请求报头value
请求报头key: 请求报头value
......
[空行】
正文
响应
版本号 状态码 状态码描述
响应报头key: 响应报头value
响应报头key: 响应报头value
......
[空行]
正文
2.HTTP请求中的方法
关于请求中的"方法",属于HTTP协议之初,一个"初心",把请求根据功能,划分成不同的种类
有的时候,需要从服务器获取一些数据,GET
有的时候,需要给服务器上传一些数据,POST
有的时候,需要删除一下服务器的数据,DELETE
有的时候,需要了解一下服务器的一些选项,OPTIONS
不同种类的请求,就用"方法"来进行区分,方法诞生之初,是有"语义"的
这些方法都是HTTP1版本的方法,暂时不考虑2和3

随着时间的推移,HTTP协议方法的初心,并没有实现。
现在咱们在进行web开发的时候,方法已经不表示最初的语义了。
GET:初心是从服务器获取数据
POST:初心是往服务器提交数据
但是实际上,现在GET和POST都既可以用来获取,也可以用来提交,一切的一切都取决于程序员的代码如何实现。
因此,在现在看来,这些方法已经失去了实质的意义,不同的方法之间都是可以相互替换的
再进一步的讲,这些方法和方法之间,没有本质区别(理论上是可以相互替换的)
1) 哪些方式会触发HTTP请求?
- 直接在浏览器中输入URL,就会触发一个HTTP请求
- HTML页面中的一些特殊标签,link(引入CSS) ,img(图片),script(引入),a(超链接,用户点击时触发)也会触发HTTP的GET请求
- form表单
- ajax
- 使用java代码/其它的库
- 通过linux下的wget/curl
- 通过第三方工具,postman这类工具
2) GET请求格式的注意事项
body部分为空
通常情况下,GET的body为空,但是如果自己构造一个body不为空的GET请求,是完全可以的。
GET请求的body是完全可以不为空的,为空只是一种习惯上的做法
关于GET请求的URL长度问题
URL长度的上限要以RFC标准文档为准!
在RFC标准文档中,HTTP协议,RFC2616标准,对于URL的长度,是没有做出限制的,只不过有些浏览器可能会对URL长度做出限制。
3) POST请求
HTTP协议中,最常用的就是GET,其次就是POST。
啥时候会使用到POST请求?最常见的情况,就是登录。
使用GET完成登录,行不行?完全OK,只不过咱们习惯上是使用POST实现登录
构造POST请求的方式也很多
- form
- ajax
- 第三方工具

POST请求的特点:
- 首行第一部分为POST
- URL的query string 一般为空,但是也完全可以加上 query string,为空只是一种习惯
- header部分有若干个键值对
- body部分一般不为空,但是body为空,也是完全可行的
POST请求的body里面的数据格式,也是支持很多种格式。
格式的类型,由请求头中的Content-Type字段来表示
body的长度,由请求头中的Content-Length字段来表示(单位是字节)
body里面具体要填啥数据?和GET的query string 类似,都是程序员自己约定的
4) GET和POST的区别
GET和POST没有本质区别
使用GET给服务器提交一个数据,是否可以?完全可以
使用GET删除服务器的一个数据,是否可以?完全可以
HTTP协议中的各种方法之间(尤其是GET和POST之间)没有本质区别
然后细节上还是有点区别的
-
数据位置:GET把自定义数据放到 query string,POST把自定义数据放到body
-
语义区别:GET一般用于"获取数据",POST一般用于提交数据
-
幂等性:GET请求一般会设计成"幂等"的,POST请求一般不要求设计成"幂等"
-
可缓存:GET请求一般会被缓存,POST请求一般不能被缓存(同样也是取决于程序员的设计)
这些东西都不是绝对的,这些规则都是可以被打破的,最终结论还是那句话:POST和GET没有本质区别
幂等?
某个请求,执行一次和执行多次,没啥区别(幂等与否都是取决于程序员的设计)
5) 传输数据
-
传输数据量
RFC标准中并没有描述,URL的长度,也没有描述body的长度
更何况,GET也可以没有body,POST也可以有URL
-
传输数据类型
URL里面一般是放文本
body里面可以放文本,也可以放二进制
GET也可以有body,也可以针对二进制数据进行URL encode,就可以把数据通过URL来传递了
3. 请求报头
请求报头中的键值对也是非常重要的。
Host
Host: gitee.com
描述了主机的地址:端口号
地址可以是域名,也可以是IP
Host这个东西,其实是和URL中表示的信息是重叠的
一般来说Host中的内容和URL中的地址是一致的,但是也不绝对
Content-Length
表示body的长度,单位是字节
如果没有body(GET请求),此时就可以没有这个 Content-Length
Content-Type
表示body中的数据格式
常见选项
-
application/x-www-form-urlencoded: form 表单提交的数据格式. 此时 body 的格式形如:
title=test&content=hello -
multipart/form-data: form 表单提交的数据格式(在 form 标签中加上enctyped=“multipart/form-data” . 通常用于提交图片/文件. body
上传文件的时候,会涉及到这种格式
-
application/json: 数据为 json 格式.
{"username":"123456789","password":"xxxx","code":"jw7l","uuid":"d110a05ccde64b16 a861fa2bddfdcd15"} -
text/html:body的数据格式是html
User-Agent
User-Agent简称UA,这是一个非常重要的字段
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/114.0.0.0 Safari/537.36
UA就描述了系统的版本+浏览器信息
古老时期,那个时候的浏览器只能显示文字,随着时间的推移,就出现了一些浏览器,能显示图片,后面又出现了一些浏览器,能显示多媒体,再往后浏览器能够支持JS…
通过UA服务器就能知道,用户电脑的这个浏览器支持哪些功能,根据浏览器的不同,来决定返回一个啥样的页面
到现在UA已经失去了最初的意义,但是UA又有了一个新的使命
可以用来区分,PC端还是移动端,同一个网站,用PC和手机分别访问,看到的网页排版,可能不一样
接下来这里如何进行区分?
就是统计请求的UA,PC上的UA和手机的UA是不一样的
通过UA区分出是手机还是电脑,来返回不同板式的页面,这是一种实现方式(实际开发中,这种做法挺少见,UA更多的是用来统计用户)
更主流的实现方式叫做"响应式布局",基于CSS3中的"媒体查询"功能,大概就是能够获取到当前页面的宽度,根据宽度来决定样式,从而达到一份代码,适应多种不同宽度的屏幕。
手机的浏览器,很多都支持"模拟UA",可以切换UA为其它的值,就能够在手机上看到和PC端类似的网页代码了
Referer
表示当前这个页面是从哪来的(从哪个页面跳转过来的)
注意:直接在浏览器中输入RUL/点击收藏夹 打开的页面是没有Referer
通过搜索主页,跳转到搜索结果页,就是带有Referer
类似于这种搜索广告,搜狗、百度等公司主要就是靠这个赚钱
怎么计费?按照点击计费,点击一次就得让广告主给搜狗钱。
具体被 点击了多少次,这个咋算?
搜狗肯定得算一份,每次点击都会先跳到搜狗的服务器,然后搜狗再跳转到对应的网站落地页。
广告主自己也得算一份,广告主只能拿到自己的服务器的数据,就可以看看自己服务器上面有多少请求的Referer是从搜狗过来的
流量劫持
某个广告主,他同时在多个平台上投放了广告,广告主就按照Referer来统计,并进行结算
是否有可能,有人 把这个Referer给改了,从而导致广告主,统计 错误呢?
完全是有可能的,那就是运行商(电信、移动、联通)
HTTP完全是明文,运营商 有掌握了网络传输的基础设备,这个时候就完全可以把本来是搜狗的流量,把Referer一改,改成自己的流量(运营商自己也是有类似的广告平台的)
流量劫持,这种事情在2014年左右的时候非常多。
为了防止流量劫持,因此各种广告平台都做了一件事情,把网站从http升级成https
Cookie
Cookie的值是一个字符串(程序员自己定义的字符串),Cookie相当于浏览器这边进行本地存储的一种机制,比如程序员想让浏览器这边存一些信息,就可以使用Cookie
Cookie还有一个特点,Cookie能够在 后续请求服务器的时候,自动把之前保存的值给带上

由于Cookie存储空间有限(取决于浏览器具体的实现的,一般都不很大),因此Cookie一般能保存一些简单的信息,最典型的就是用户身份信息。
为了考虑到安全性,浏览器是禁止网页直接访问计算机的磁盘的,但是在网页开发的时候,有需要能够在网页端保存一些数据
早期的时候,主要就是依赖Cookie以键值对的形式储存的数据,存储量相对来说比较小,只能存一些简单的数据。
使用Cookie最常见的用法,就是存储用户的身份信息(回话ID)
保存在浏览器这边的Cookie就会在后续请求中,自动的代入到请求的报头中
现在的浏览器,有更多的本地存储的机制了
现在的网站也不完全依赖Cookie,有了一些新的存储机制
-
LocalStorage
HTML5开始引入的机制
浏览器支持一种"键值对"方式来进行存储
通过JS提供了一组API,来操作数据
这里保存的数据就会持久的存储下去
-
IndexDB
比较性的浏览器才支持的机制
浏览器内部集成了一个"数据库",支持类似于SQL的方式来进行操作数据
正文body
为啥大家这么喜欢用HTTP?
主要是因为HTTP拓展性太好了,非常方便程序员基于这个协议来传输自定义数据
- URL中的路径
- URL中的 query string
- header 中可以自定义键值对
- body中也可以自定义数据
body中放啥格式的数据都行,但是有几种格式是比较常见的
-
application/x-www-form-urlencoded
表单提交的数据格式.
-
multipart/form-data
主要是用来上传文件
-
application/json
json是一种非常常用的数据组织的格式,类似于下面这种
{ "operationName":"managementFieldPermissions", "variables":{}, "query":"query managementFieldPermissions {\n fieldPermissionInfos(namespaces: [NOJ]) {\n fieldName\n permissionCodes\n __typename\n }\n}\n" }
4.状态码
状态码,表示了这次请求的"结果"
200 OK
抓包一般抓到的状态码都是 200,表示从客户端发来的请求在服务器端被正常处理了
404 Not Found
404表示没有找到资源
每个请求,都带有一个URL,URL里面都有一个路径/index.html这种,这就表示这次请求想要的资源是啥。
如果你要请求的资源人家服务器没有,就会发出404
404表明服务器上无法找到请求的资源,除此之外,也可以在服务器端拒绝请求且不想说明理由时使用
405
一般是请求方法和服务器接收请求方法对应不上
403 Forbidden
403表示访问被拒绝(因为没有权限)
很多地方涉及到用户名和密码的校验过程
一般这种密码错误之类的情况,错误提示一般是 forbidden,或者叫做 access denied
当在没有登录的情况下,直接访问码云私有的代码片段,就会出现403,没有登录所有没有权限访问

此时Fiddler抓到的部分HTTPS响应就是403

500 Internal Server Error
表示服务器挂了,在网络上,这种情况会非常常见。一般是服务器代码执行过程中遇到了一些特殊情况(服务器异常崩溃)
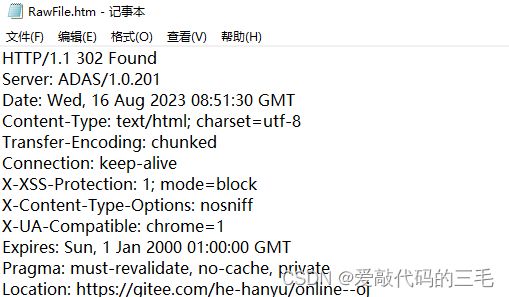
302 Move temporarily
重定向
类似于"呼叫转移",别人呼叫旧号码,自动转移到新号码上
别人访问旧的页面,自动跳转到新的页面。
列如在未登录的情况下,访问了私有的代码片段就会出现403
现在进行登录,登录成功之后,就会自动跳转到之前的这个项目页面
Location就表示接下来要跳转到哪个地址,浏览器就会根据Location中记录的URL,立即访问这个URL
Location: https://gitee.com/he-hanyu/codes/fntpg0kdz8xmcrjwuqb3454
对于302这样的重定向来说,body不是必须的,这里的body就是一个简单的HTML,里面就只有一个a标签
万一浏览器没有自动跳转,那么用户手动点击这个a标签也可以跳转(用户的浏览器千差万别,有的比较旧的浏览器不一定能跳转)