Python 之Excel openpyxl 参数详解
@[TOC]Python 之Excel openpyxl 参数详解
openpyxl 是
Excel表结构
1 安装
pip install openpyxl
2 倒包
import openpyxl
from openpyxl import Workbook
- Workbook 小写w 会报错 : TypeError: ‘module’ object is not callable
3 工作簿层面
| 代码 | 说明 | 运行结果 |
|---|---|---|
| wb.sheetnames | # 获取 簿中的表的名字 | [‘明细’, ‘汇总’] |
| wb.active | # 获取 活跃表 | |
| wb._sheets[1] | # 读入 指定 表 | |
| wb.copy_worksheet(wb._sheets[1] | # 复制 表 | |
| wb.copy_worksheet(wb[“汇总”]) | # 复制 指定表 | |
| wb[“汇总”].title = “新sheet名字” | # 改名字 | |
| wb.create_sheet(“新建sheet”,0) | # 新建表,0表示位置 | |
| wb_new=Workbook() | # 新建 簿 | |
| wb.save(“新人口统计.xlsx”) | # 保存 工作簿 |

4 工作表层面
4.1 基础代码
| 代码 | 说明 | 运行结果 |
|---|---|---|
| sheet=wb.active | # 【激活】 活动表 | |
| sheet.title | # 名字 | 【读】sheet名字 |
| sheet.dimensions | # 【读】表的大小尺寸 | A1:E73 |
| sheet.max_row,sheet.min_column | # 最大行 最小列 | 73 1 |
| del wb[“汇总 Copy1”] | #复制工作表 | |
| wb.remove(“汇总 Copy1”) | #删除工作表 |
4.2 读
4.2.1 读 — 表\行\列\切片\单元格
| 大类 | 代码 | 运行结果 |
|---|---|---|
| 1.1 读全部 | for cell in ws.values:print(cell) | |
| 1.2.1 读行 | for cell in ws[1]:print(cell.coordinate,":",cell.value,end="*") | |
| 1.3.1 读列 | for cell in ws[“c”]:print(cell.value,end="*") | |
| 1.4 读切片 | for range in ws[“A1:C2”]: “\n for cell in range: print(cell.value,end=”,") | |
| 1.5.1 读单元格 | print(ws[“a1”].value) | |
| 1.5.2 读单元格 | print(ws.cell(row=1,column=ws.max_column).value) |
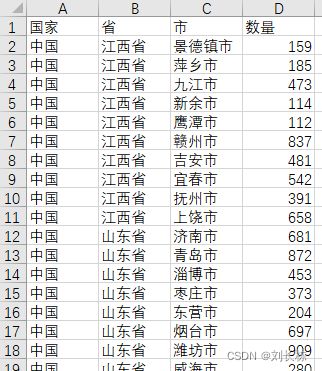
4.2.2 表格内容读取 成 行的形式
输出

[说明]
- [列表形式 ]使输出结果为列表形式 , 失败 不能分行 , 不能统计 无意义
- [集合的形式 ] 适合统计 因为他有 key和value
代码
for row in range(2, ws.max_row) :
print(row, end=",") # 取行号
# 每一行 取 国家\省份
国家=ws.cell(row=row,column=1).value
省=ws.cell(row=row,column=2).value
市=ws.cell(row=row,column=3).value
人口=ws.cell(row=row,column=4).value
print(国家,省,市,人口)
4.3 写
4.3.1 写单元格
ws["a5"]="ab5"
ws.cell(row=5,column=2,value="b5")
4.3.2 最后一行
ws.append([5,88,99,25])
4.3.3 写入多行
4.3.3.1 多行 – 集合

data={
"中国":"北京",
"日本":"东京"
}
for i in data:
sheet.append([i,data[i]]) | # 以列表的形式 写入表格
4.3.3.2 多行 – 列表
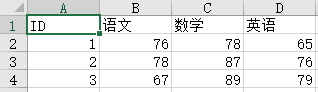
list=[
[6,66,66,66],
[7,77,77,77]
]
for row in list:ws.append(row)
4.3.4 插入一/多行,并写入数据
ws.insert_rows(5,3) # 5是位置, 3是一次3行
n=1
for i in [4,44,44,44]:
ws.cell(row=5,column=n,value=i)
n+=1
4.3.5 插入一列,并写入数据
ws.insert_cols(3)
n=1
for i in ["化学",89,99,99,85]:
ws.cell(row=n,column=3,value=i)
n+=1
4.4 删
ws.delete_rows(2,2) # 第几行开始删除, 删除几行
ws.delete_cols(2)
4.5 移
-
移动单元格 数字为正 向下(右)
ws.move_range("a2:c3",rows=3,cols=4)
4.6 将公式写入单元格
ws['b6'] = "=AVERAGE(b1:b5)"
代码奉上 读写删
# --*coding:utf-8*--
import openpyxl
from openpyxl import Workbook
# 读入
wb=openpyxl.load_workbook("002 例子 写入求和平均.xlsx")
print(wb.sheetnames)
ws=wb["求和|平均"]
# 1 读
## 1.1 读全部
for cell in ws.values:print(cell)
## 1.2.1 读行
for cell in ws[1]:print(cell.coordinate,":",cell.value,end="*")
## 1.3.1 读列
for cell in ws["c"]:print(cell.value,end="*")
## 1.4 读切片
for range in ws["A1:C2"]:
for cell in range:print(cell.value,end=",")
print()
## 1.5 读单元格
print(ws["a1"].value)
print(ws.cell(row=1,column=ws.max_column).value)
# 2 写
## 2.1 写单元格
ws["a5"]="ab5"
ws.cell(row=5,column=2,value="b5")
## 2.2 写行/列
##### 2.2.1 最后一行
ws.append([5,88,99,25])
##### 2.2.2 写入多行
list=[
[6,66,66,66],
[7,77,77,77]
]
for row in list:ws.append(row)
##### 2.2.3 插入一行,并写入数据
ws.insert_rows(5)
n=1
for i in [4,44,44,44]:
ws.cell(row=5,column=n,value=i)
n+=1
##### 2.2.3 插入一列,并写入数据
ws.insert_cols(3)
n=1
for i in ["化学",89,99,99,85]:
ws.cell(row=n,column=3,value=i)
n+=1
# 3 删除行
ws.delete_rows(2)
ws.delete_cols(2)
for cell in ws.values:print(cell)
5 单元格层面
5.1 合并 拆分
| 代码 | 说明 | 运行结果 |
|---|---|---|
| sheet[“c2”].row,sheet[“c2”].column | # 【读】 坐标 | 2 3 |
| sheet.merge_cells(“a1:a3”) | # 合并单元格 | |
| sheet.merge_cells(f"a{sheet.max_row-2}:a{sheet.max_row}") | #合并单元格 | |
| sheet.unmerge_cells(f"a{sheet.max_row-2}") | #拆分单元格 |
6 单元格 样式
6.1 倒包
from openpyxl.styles import Font, colors, Alignment
6.2 字体
字体样式 = Font(name='等线', size=24, italic=True, color=colors.RED, bold=True)
sheet['A1'].font = 字体样式
6.3 对齐
#设置B1中的数据垂直居中和水平居中
sheet['B1'].alignment = Alignment(horizontal='center', vertical='center')
6.4 行高列宽
# 第2行行高
sheet.row_dimensions[2].height = 40
# C列列宽
sheet.column_dimensions['C'].width = 30
7 获取所有单元格内容
-
模式一
-
### 访问 表中的所有内容 for row in sheet.rows: for cell in row: print(cell.value,end=",") # 输出: 国家,首都,越南,河内,中国,北京,日本,东京, -
模式 二
for i in sheet.values: print(i) # 输出 ('国家', '首都') ('越南', '河内') ('中国', '北京') ('日本', '东京')
#--*coding:utf-8*--
##### 1 倒包
import openpyxl
from openpyxl import Workbook # 小写w 会TypeError: 'module' object is not callable
##### 2 打开已有
wb=openpyxl.load_workbook("人口统计.xlsx")
##### 3 工作簿层面
print(wb.sheetnames) # 获取 簿中的表的名字 :['明细', '汇总']
print(wb.active) # 获取 活跃表
print(wb._sheets[1]) # 读入 指定 表 :8 例子
8.1 求和和平均
-
要求

-
知识点
1, 列表 写入表格 for in , ws.append 2, 获取 行内容 3, 写入 指定坐标 内容
# --*coding:utf-8*--
"""生成一个Excel表,计算求和和平均数"""
# 1,倒包
from openpyxl import Workbook
# 2,新建
wb = Workbook()
ws = wb.active
# 3,写入
list = [
["学号", "姓名", "语文", "数学", "英语"],
["sd000562", "姜大苯", 88, 66, 99],
["sd000555", "小妮子", 99, 55, 88],
["sd000666", "刘大东", 88, 99, 77]
]
for row in list : ws.append(row)
# 4,计算
max_column = ws.max_column
## 4.1 读取一行数据
for row in ws.rows :
row_list = [cell.value for cell in row[2 :5]]
## 4.2 第二行开始 求和和平均
if type(row_list[1]) == int :
row_sum = sum(row_list)
row_avg = format(row_sum / len(row_list), ".2f")
print(row_list, row_sum, row_avg)
# 写入 求和和平均
ws.cell(row=row[0].row, column=max_column + 1).value = row_sum
ws.cell(row=row[0].row, column=max_column + 2).value = float(row_avg)
# 写入 总分和平均分 列标题
ws.cell(row=1, column=max_column + 1).value = "总分"
ws.cell(row=1, column=max_column + 2).value = "平均分"
# 显示结果
for cell in ws.values : print(cell)
wb.save("002 例子 写入求和平均.xlsx")