用户输入问题,将问题代表的语句存到mysql或qdrant向量数据库,然后对所有语句进行分词生成词云+pip安装切换镜像源
如果提示安装 pip install paddlehub==2.0.0的有些包不可写入,用本机用户权限安装:
pip install paddlehub==2.0.0 --user
这样就不会报错了,提供足够的权限。
切换镜像源:pip install -i url site-package,url和package是要修改的
pip install -i http://pypi.douban.com/simple/ opencv-python可替换成:
https://pypi.tuna.tsinghua.edu.cn/simple设置清华镜像源
清华:https://pypi.tuna.tsinghua.edu.cn/simple
阿里云:https://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
华中理工大学:http://pypi.hustunique.com/
山东理工大学:http://pypi.sdutlinux.org/
豆瓣:http://pypi.douban.com/simple/一、首先,需要准备的操作是:
1、安装好python3系列版本
2、安装python第三方库wordcloud;
3、安装numpy、pillow库。
4、安装jieba库
5、安装matplotlib库
pip install wordcloud
pip install numpy
pip install pillow
pip install jieba
pip install matplotlib生成词云时,wordcloud 默认会以空格或标点为分隔符对目标文本进行分词处理。
对于中文文本,分词处理需要由用户来完成。
一般步骤是先将文本分词处理,然后以空格拼接,再调用wordcloud库函数。
处理中文时还需要指定中文字体。
例如,选择了微软雅黑字体(msyh.ttf)作为显示效果,需要将该字体文件与代码存放在同一目录下或在字体文件名前增加完整路径。
二、打开命令行:windows+R
输入Fonts,找到微软雅黑简体文件:

点击简体文件,按 ctrl+c 复制该字体文件,将该文件放在下面你要写的代码所在位置,比如我写的代码py文件放在 "C:\Users\59980\Desktop\peixun位置,你就将改字体文件放在该文件夹,最终字体文件路径:"C:\Users\59980\Desktop\peixun\msyh.ttc"。
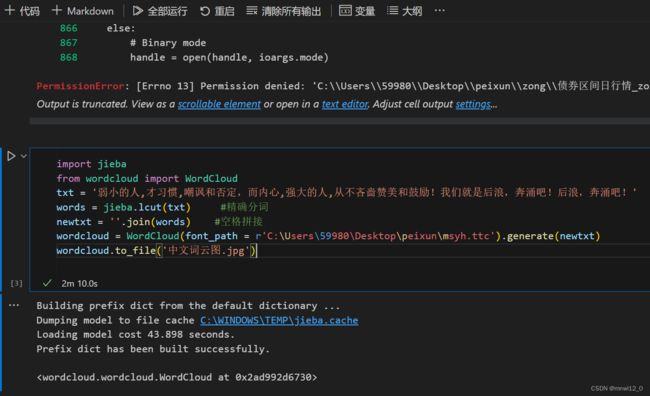
三、完整代码:
import jieba
from wordcloud import WordCloud
txt = '弱小的人,才习惯,嘲讽和否定,而内心,强大的人,从不吝啬赞美和鼓励!我们就是后浪,奔涌吧!后浪,奔涌吧!'
words = jieba.lcut(txt) #精确分词
newtxt = ''.join(words) #空格拼接
wordcloud = WordCloud(font_path =r'C:\Users\59980\Desktop\peixun\msyh.ttc').generate(newtxt)
wordcloud.to_file('中文词云图.jpg')
点击运行:
看到最后 built successfully 即运行成功,已经生成了图片在对应的文件夹。注意:每生成一次结果都不一样。
结果:
四、上面简单的演示了如何快速生成词云,下面将演示如何利用用户输入存储到数据库进行生成词云:
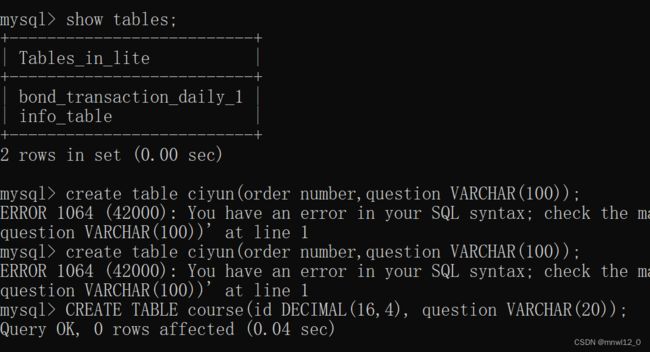
首先连接数据库,可以是向量数据库Qdrant,也可以是本地数据库mysql,方便起见用MySQL演示:首先在数据库里面创建对应表格:
import pymysql
#连接数据库
conn=pymysql.connect(host = '127.0.0.1' # 连接名称,默认127.0.0.1
,user = 'root' # 用户名
,passwd='152617' # 密码
,port= 3306 # 端口,默认为3306
,db='lite' # 数据库名称
,charset='utf8' # 字符编码
)
cur = conn.cursor() # 生成游标对象
#=============插入语句===============================
sql1= "INSERT INTO t_user VALUES ('4','魏六')"
#===================================================
try:
cur.execute(sql1) # 执行插入的sql语句
conn.commit() # 提交到数据库执行
except:
conn.rollback()# 如果发生错误则回滚
conn.close() # 关闭数据库连接##明天再补充细节
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import pymysql
#连接数据库
conn=pymysql.connect(host = '127.0.0.1' # 连接名称,默认127.0.0.1
,user = 'root' # 用户名
,passwd='152617' # 密码
,port= 3306 # 端口,默认为3306
,db='lite' # 数据库名称
,charset='utf8' # 字符编码
)
txt=[]
cur = conn.cursor() # 生成游标对象
while True:
#这里要前端控制用户输入提取用户的问题语句
user_input = input("请输入你的问题(输入'0'退出): ")
if user_input == '0':
break
#将用户问题插入到数据库 [可以是向量数据库Qdrant,我这里用本地MySQL]
sql = "INSERT INTO ciyun (question) VALUES (%s)"
values = (user_input,)
try:
cur.execute(sql, values)
conn.commit()
except Exception as e:
print("发生错误:", e)
conn.rollback()
#将数据库里面数据导出到文本
sql="select * from ciyun "
cur.execute(sql)
data = cur.fetchall()
for j in data[:]:
txt += j
cur.close()
conn.close()
#分词处理 [可以用停用词、转化词优化]
print(txt)
seg_list = []
for string in txt:
seg_list += jieba.cut(string, cut_all=False)
keywords = " ".join(seg_list)
#生成、显示词云图
wordcloud = WordCloud(font_path=r'C:\Users\59980\Desktop\peixun\msyh.ttc').generate(keywords)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
# wordcloud.to_file('中文词云图.jpg')
运行结果:
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import pymysql
def Generate_WordCloud(user_input):
conn=pymysql.connect(host = '127.0.0.1',user = 'root',passwd='152617',port= 3306,db='lite',charset='utf8')#连接数据库
txt=[]
cur = conn.cursor() # 生成游标对象
if user_input == ' ':
return
#将用户问题插入到数据库 [可以是向量数据库Qdrant,我这里用本地MySQL]
sql = "INSERT INTO ciyun (question) VALUES (%s)"
values = (user_input,)
try:
cur.execute(sql, values)
conn.commit()
except Exception as e:
print("发生错误:", e)
conn.rollback()
#将数据库里面数据导出到文本
sql="select * from ciyun "
cur.execute(sql)
data = cur.fetchall()
for j in data[:]:
txt += j
cur.close()
conn.close()
#分词处理 [可以用停用词、转化词优化]
# print(txt)
seg_list = []
for string in txt:
seg_list += jieba.cut(string, cut_all=False)
keywords = " ".join(seg_list)
return keywords
#生成、显示词云图
user_input=input('请输入你的问题:')
keyword=Generate_WordCloud(user_input)
wordcloud = WordCloud(font_path=r'C:\Users\taiping.wang\Desktop\MSYH.TTC').generate(keyword)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis("off")
plt.show()
# wordcloud.to_file('中文词云图.jpg')
方案2:用 飞浆LAC模型进行训练:
数据库数据文件 :

后续再补充