如何使用 Flink SQL 探索 GitHub 数据集|Flink-Learning 实战营
作者|王洪顺(弘舜)
为进一步帮助开发者学习使用 Flink,Apache Flink 中文社区近期发起 Flink-Learning 实战营项目。本次实战营通过真实有趣的实战场景帮助开发者实操体验 Flink,课程包括实时数据接入、实时数据分析、实时数据应用的场景实。并结合小松鼠助教模式,全方位帮助入营开发者轻松玩转 Flink,点击下方图片扫码即刻入营。

本期将继续详细介绍 Flink- Learning 实战营。
想要了解如何使用 Flink 在 GitHub 中发现最热门的项目吗?本实验使用阿里云实时计算 Flink 版内置的 GitHub 公开事件数据集,通过 Flink SQL 实时探索分析 Github 公开数据集中隐藏的彩蛋!
完成本实验后,您将掌握的知识有:
- 了解 Flink 和流式计算的优势
- 对 Flink SQL 基础能力和 Flink 实时处理特性有初步体验
实验简介
通过 Flink 对 GitHub 的实时事件流进行分析,并通过报表直观展示,了解 GitHub 的最新热门趋势、特定仓库或者组织的活跃度。
体验此场景后,可以对 Flink SQL 基础能力和 Flink 实时处理特性有直观的初步体验。
■ 为回馈广大开源开发者对社区的支持,阿里云实时计算 Flink 版提供云原生免费试用资源
实验资源
本场景使用到的实验资源和配置如下:
阿里云实时计算 Flink 版
| 配置项 | 规格 |
|---|---|
| Task Manger 个数 | 4 个 |
| Task Manager CPU | 2 核心 |
| Task Manager Memory | 8 GiB |
| Job Manager CPU | 1 核 |
| Job Manager Memory | 2 GiB |
体验目标
对 Flink SQL 基础能力和 Flink 实时处理特性有直观的初步体验。
背景知识
GitHub 公开数据集(GitHub Archive)是 GitHub 提供的一个开放数据集合,它包含了每个公共仓库的事件数据,例如提交、拉取请求、问题和评论等。GitHub 公开数据集的数据可以用于进行各种类型的研究和分析,例如开源社区的协作情况、开发者的行为特征、编程语言的发展趋势等。使开发者们更好地了解 GitHub 上的活动和趋势,并从中获得有价值的信息和洞察。
本实验将 GitHub 公开数据集实时同步到 SLS 作为数据源,根据 Flink 对数据进行多种维度的分析并且通过报表直观展示。
前置知识
- 了解 Flink 相关的基础知识。
- 了解 Flink SQL 相关的基础知识。
环境搭建
创建 Session 集群。进入阿里云控制台,选择实时计算 Flink 版。然后选择已经购买的工作空间。
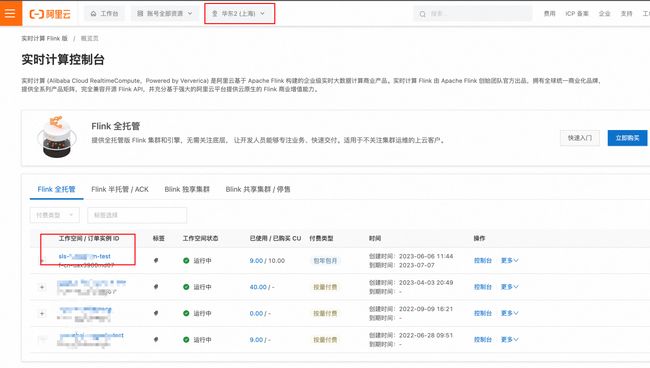
在开始阿里云实时计算 Flink 版作业编写前,需要先创建 Session 集群,只有创建了 Flink 集群,才能执行任务。
1.点击系统管理 -> Session 集群 ->创建 Session
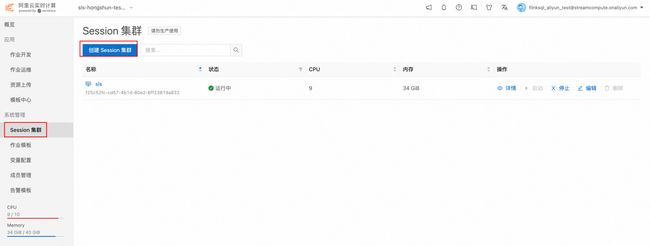
2.创建 Session 集群时设置为 SQL Preview 集群,这样无需设置 Sink, 即可将 Select 语句的结果输出成图表的格式。
实验 1:Github 关注数排行榜
本实验统计从一周前起的 Github 关注度排行榜。
操作
1.作业 SQL 代码。其中 startTime 尽量设置为当前此刻的一周前附近,如果设置的时间太早,前面无效计算时间比较长,不仅耗费资源,而且很久才能加载出计算结果。根据不同的地域设置相应的 project 和endPoint,如实例为上海的服务平台,因此设置'project' = 'github-events-shanghai'和'endPoint' = 'https://cn-shanghai-intranet.log.aliyuncs.com',其他地域如北京、杭州、深圳更改为对应值即可。
-- 通过DDL语句创建SLS源表,SLS中存放了Github的实时数据。
CREATE TEMPORARY TABLE gh_event(
id STRING, -- 每个事件的唯一ID。
created_at BIGINT, -- 事件时间,单位秒。
created_at_ts as TO_TIMESTAMP(created_at*1000), -- 事件时间戳(当前会话时区下的时间戳,如:Asia/Shanghai)。
type STRING, -- Github事件类型,如:。ForkEvent, WatchEvent, IssuesEvent, CommitCommentEvent等。
actor_id STRING, -- Github用户ID。
actor_login STRING, -- Github用户名。
repo_id STRING, -- Github仓库ID。
repo_name STRING, -- Github仓库名,如:apache/flink, apache/spark, alibaba/fastjson等。
org STRING, -- Github组织ID。
org_login STRING -- Github组织名,如: apache,google,alibaba等。
) WITH (
'connector' = 'sls', -- 实时采集的Github事件存放在阿里云SLS中。
'project' = 'github-events-shanghai', -- 存放公开数据的SLS项目。例如'github-events-hangzhou'。
'endPoint' = 'https://cn-shanghai-intranet.log.aliyuncs.com', -- 公开数据仅限阿里云实时计算 Flink 版通过私网地址访问。例如'https://cn-hangzhou-intranet.log.aliyuncs.com'。
'logStore' = 'realtime-github-events', -- 存放公开数据的SLS logStore。
'accessId' = ' ', -- 只读账号的AK。
'accessKey' = ' ', -- 只读账号的SK。
'batchGetSize' = '500', -- 批量读取数据,每批最多拉取500条。
'startTime' = '2023-06-01 14:00:00' -- 开始时间,尽量设置到需要计算的时间附近,否则无效计算的时间较长。默认值为当前值
);
-- 配置开启mini-batch, 每2s处理一次。
SET 'table.exec.mini-batch.enabled'='true';
SET 'table.exec.mini-batch.allow-latency'='2s';
SET 'table.exec.mini-batch.size'='4096';
-- 作业设置4个并发,聚合更快。
SET 'parallelism.default' = '4';
-- 查看Github新增star数Top 5仓库。
SELECT DATE_FORMAT(created_at_ts, 'yyyy-MM-dd') as `date`, repo_name, COUNT(*) as num
FROM gh_event WHERE type = 'WatchEvent'
GROUP BY DATE_FORMAT(created_at_ts, 'yyyy-MM-dd'), repo_name
ORDER BY num DESC
LIMIT 5;
2.验证 SQL 是否正确并且执行
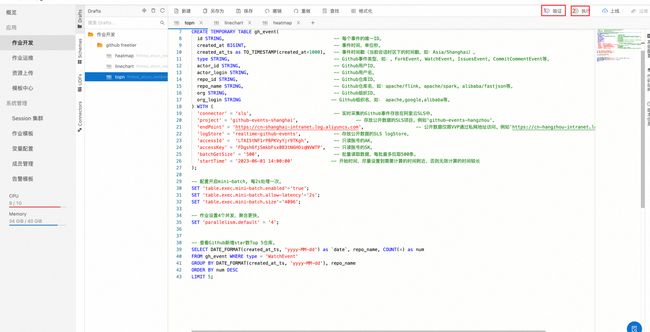
3.配置图表
a. 选择 Y Bar 并且编辑标题栏为 Top 5
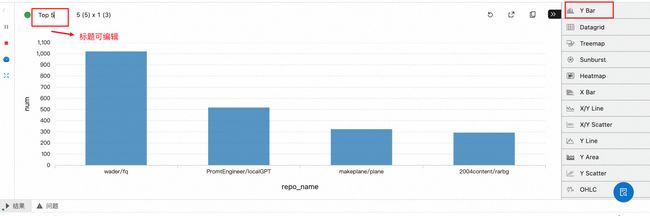
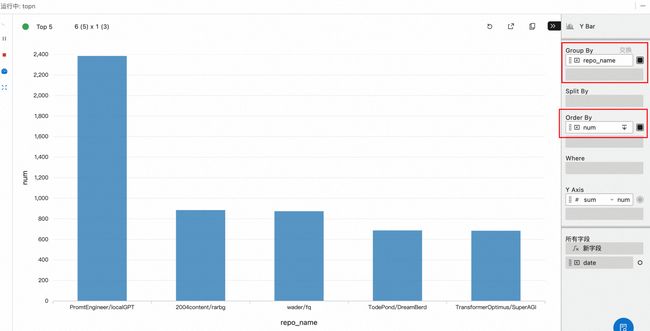
b. 配置 group by repo_name, order by num,即根据 repo_name 分组比较数量
c. 实验可以一直运行,不断消费最新的数据。但是如果当前集群的 CPU 数配置的较少,不足以执行两个任务,又想执行下一个实验是,可以将本实验停止。点击结果左侧的红色方框即可。
结果
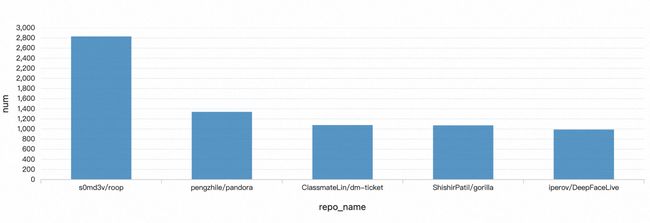
第一名:s0md3v/roop 视频换脸(最近我在b站也经常翻到)
第二名:pengzhile/pandora 潘多拉实现了网页版 ChatGPT 的主要操作
第三名:ClassmateLin/dm-ticket 大麦网抢票(疫情放开,估计上周演唱会很多)
第四名:ShishirPatil/gorilla 连接海量 API 的大型语言模型
第五名: iperov/DeepFaceLive 换脸
由此可见最近一周最流行的 repo 就是 ai 视频换脸和大模型,最流行的领域就是 ai
实验 2:统计组织活跃度变化
本实验统计 apache 和 alibaba 组织开源在从 24 小时前开始的活跃度趋势变化。
操作
1.SQL 代码如下。其中 startTime 尽量设置为当前此刻的 24 小时前附近,如果设置的时间太早,前面无效计算时间比较长,不仅耗费资源,而且很久才能加载出计算结果。如果想要统计 alibaba, 改成 org_login ='alibaba' 即可
CREATE TEMPORARY TABLE gh_event(
id STRING, -- 每个事件的唯一ID。
created_at BIGINT, -- 事件时间,单位秒。
created_at_ts as TO_TIMESTAMP(created_at*1000), -- 事件时间戳(当前会话时区下的时间戳,如:Asia/Shanghai)。
type STRING, -- Github事件类型,如:。ForkEvent, WatchEvent, IssuesEvent, CommitCommentEvent等。
actor_id STRING, -- Github用户ID。
actor_login STRING, -- Github用户名。
repo_id STRING, -- Github仓库ID。
repo_name STRING, -- Github仓库名,如:apache/flink, apache/spark, alibaba/fastjson等。
org STRING, -- Github组织ID。
org_login STRING -- Github组织名,如: apache,google,alibaba等。
) WITH (
'connector' = 'sls', -- 实时采集的Github事件存放在阿里云SLS中。
'project' = 'github-events-shanghai', -- 存放公开数据的SLS项目。例如'github-events-hangzhou'。
'endPoint' = 'https://cn-shanghai-intranet.log.aliyuncs.com', -- 公开数据仅限阿里云实时计算 Flink 版通过私网地址访问。例如'https://cn-hangzhou-intranet.log.aliyuncs.com'。
'logStore' = 'realtime-github-events', -- 存放公开数据的SLS logStore。
'accessId' = ' ', -- 只读账号的AK。
'accessKey' = ' ', -- 只读账号的SK。
'batchGetSize' = '500', -- 批量读取数据,每批最多拉取500条。
'startTime' = '2023-06-07 14:00:00' -- 开始时间,尽量设置到需要计算的时间附近,否则无效计算的时间较长
);
-- 配置开启mini-batch, 每2s处理一次。
SET 'table.exec.mini-batch.enabled'='true';
SET 'table.exec.mini-batch.allow-latency'='2s';
SET 'table.exec.mini-batch.size'='4096';
-- 作业设置4个并发,聚合更快。
SET 'parallelism.default' = '4';
-- 从一天前开始统计事件总量
SELECT NOW(), max(created_at_ts) as created_ts, COUNT(*) as event_count
FROM gh_event
WHERE org_login ='apache' and
created_at_ts >= NOW() - INTERVAL '1' DAY;
2.点击执行,并且配置图表
a. 点击图表配置

b. 编辑标题为"apache",并且选择 X/Y Line

c. 配置 X 轴为 create_ts, y 轴为 event_count
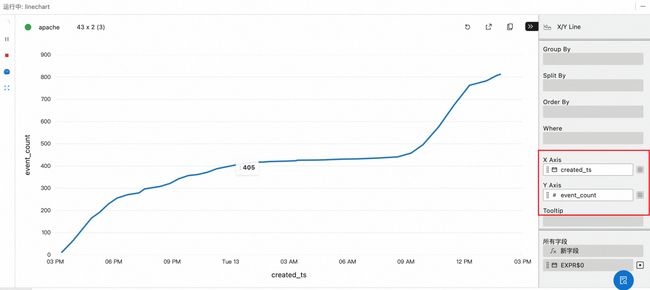
结果
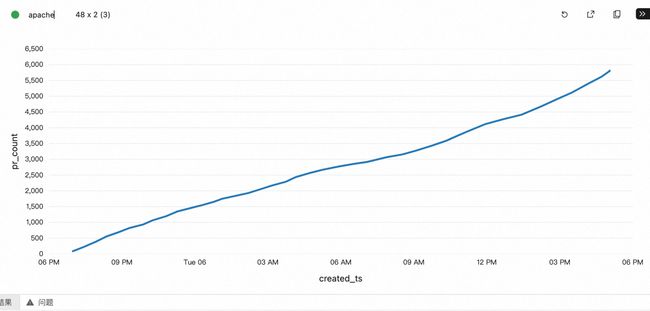
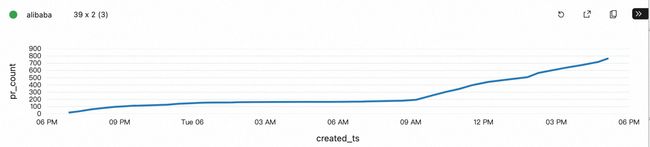
apache 作为全球性的开源组织,一天内的活跃度比较均匀,而阿里巴巴开源基本由国内开发者关注和贡献,夜间增加比较平缓,在 9 点之后明显提升。
实验 3: 统计仓库贡献时间分布情况
本实验统计 flink 和 spark 开源仓库在从一周前前开始的贡献分布情况。贡献包括代码提交、commit 评论、issue 评论、提交 PR 请求、PR 请求的审查评论等与开发者相关的事件。
1.作业 SQL 代码。其中 startTime 尽量设置为当前此刻的一周前附近,如果设置的时间太早,前面无效计算时间比较长,不仅耗费资源,而且很久才能加载出计算结果。如果想要统计 spark, 改成 repo_name = 'apache/flink'' 即可。
CREATE TEMPORARY TABLE gh_event(
id STRING, -- 每个事件的唯一ID。
created_at BIGINT, -- 事件时间,单位秒。
created_at_ts as TO_TIMESTAMP(created_at*1000), -- 事件时间戳(当前会话时区下的时间戳,如:Asia/Shanghai)。
type STRING, -- Github事件类型,如:。ForkEvent, WatchEvent, IssuesEvent, CommitCommentEvent等。
actor_id STRING, -- Github用户ID。
actor_login STRING, -- Github用户名。
repo_id STRING, -- Github仓库ID。
repo_name STRING, -- Github仓库名,如:apache/flink, apache/spark, alibaba/fastjson等。
org STRING, -- Github组织ID。
org_login STRING -- Github组织名,如: apache,google,alibaba等。
) WITH (
'connector' = 'sls', -- 实时采集的Github事件存放在阿里云SLS中。
'project' = 'github-events-shanghai', -- 存放公开数据的SLS项目。例如'github-events-hangzhou'。
'endPoint' = 'https://cn-shanghai-intranet.log.aliyuncs.com', -- 公开数据仅限阿里云实时计算 Flink 版通过私网地址访问。例如'https://cn-hangzhou-intranet.log.aliyuncs.com'。
'logStore' = 'realtime-github-events', -- 存放公开数据的SLS logStore。
'accessId' = ' ', -- 只读账号的AK。
'accessKey' = ' ', -- 只读账号的SK。
'batchGetSize' = '500', -- 批量读取数据,每批最多拉取500条。
'startTime' = '2023-06-01 14:00:00' -- 开始时间,尽量设置到需要计算的时间附近,否则无效计算的时间较长
);
-- 配置开启mini-batch, 每2s处理一次。
SET 'table.exec.mini-batch.enabled'='true';
SET 'table.exec.mini-batch.allow-latency'='2s';
SET 'table.exec.mini-batch.size'='4096';
-- 作业设置4个并发,聚合更快。
SET 'parallelism.default' = '4';
-- 配置开启mini-batch, 每2s处理一次。
SET 'table.exec.mini-batch.enabled'='true';
SET 'table.exec.mini-batch.allow-latency'='2s';
SET 'table.exec.mini-batch.size'='4096';
-- 作业设置4个并发,聚合更快。
SET 'parallelism.default' = '4';
-- 统计从上周起的贡献量
SELECT DATE_FORMAT(created_at_ts, 'yyyy-MM-dd') as comment_date, HOUR(created_at_ts) AS comment_hour ,COUNT(*) AS comment_count
FROM gh_event
WHERE created_at_ts >= NOW() - INTERVAL '7' DAY
AND repo_name = 'apache/flink'
AND (type ='CommitCommentEvent' OR
type='IssueCommentEvent' or
type = 'PullRequestReviewCommentEvent'or
type = 'PushEvent' or
type = 'PullRequestEvent' or
type = 'PullRequestReviewEvent')
GROUP BY DATE_FORMAT(created_at_ts, 'yyyy-MM-dd'), HOUR(created_at_ts) ;
2.点击执行,并且配置图表。选择 Heatmap, 设置 Group by comment_date, Spli By comment_hour,Color为 Sum(comment_count), 即 X 轴为天,Y 周为小时,根据总数量显示颜色深浅。
想要了解更多关于如何在 GitHub 中发现最热门的项目的知识吗?快来尝试一下吧!

点击即刻入营