JavaScript专题
防抖
你是否在⽇常开发中遇到⼀个问题,在滚动事件中需要做个复杂计算或者实现⼀个按钮的防⼆次点击操作。
这些需求都可以通过函数防抖动来实现。尤其是第⼀个需求,如果在频繁的事件回调中做复杂计算,很有可能导致⻚⾯卡顿,不如将多次计算合并为⼀次计算,只在⼀个精确点做操作。
PS:防抖和节流的作⽤都是防⽌函数多次调⽤。区别在于,假设⼀个⽤户⼀直触发这个函数,且每次触发函数的间隔⼩于wait,防抖的情况下只会调⽤⼀次,⽽节流的 情况会每隔⼀定时间(参数wait)调⽤函数。
我们先来看⼀个袖珍版的防抖理解⼀下防抖的实现:
// func是⽤户传⼊需要防抖的函数
// wait是等待时间
const debounce = (func, wait = 50) => {
// 缓存⼀个定时器id
let timer = 0
// 这⾥返回的函数是每次⽤户实际调⽤的防抖函数
// 如果已经设定过定时器了就清空上⼀次的定时器
// 开始⼀个新的定时器,延迟执⾏⽤户传⼊的⽅法
return function (...args) {
if (timer) clearTimeout(timer)
timer = setTimeout(() => {
func.apply(this, args)
}, wait)
}
}
// 不难看出如果⽤户调⽤该函数的间隔⼩于wait的情况下,上⼀次的时间还未到就被清除了,并不会执⾏函数这是⼀个简单版的防抖,但是有缺陷,这个防抖只能在最后调⽤。⼀般的防抖会有immediate选项,表示是否⽴即调⽤。这两者的区别,举个栗⼦来说:
- 例如在搜索引擎搜索问题的时候,我们当然是希望⽤户输⼊完最后⼀个字才调⽤查询接⼝,这个时候适⽤ 延迟执⾏ 的防抖函数,它总是在⼀连串(间隔⼩于wait的)函数触发之后调⽤。
- 例如⽤户给interviewMap点star的时候,我们希望⽤户点第⼀下的时候就去调⽤接⼝,并且成功之后改变star按钮的样⼦,⽤户就可以⽴⻢得到反馈是否star成功了,这个情况适⽤ ⽴即执⾏ 的防抖函数,它总是在第⼀次调⽤,并且下⼀次调⽤必须与前⼀次调⽤的时间间隔⼤于wait才会触发。
下⾯我们来实现⼀个带有⽴即执⾏选项的防抖函数
// 这个是⽤来获取当前时间戳的
function now() {
return new Date()
}
/**
* 防抖函数,返回函数连续调⽤时,空闲时间必须⼤于或等于 wait,func 才会执⾏
*
* @param {function} func 回调函数
* @param {number} wait 表示时间窗⼝的间隔
* @param {boolean} immediate 设置为ture时,是否⽴即调⽤函数
* @return {function} 返回客户调⽤函数
*/
function debounce(func, wait = 50, immediate = true) {
let timer, context, args
// 延迟执⾏函数
const later = () => setTimeout(() => {
// 延迟函数执⾏完毕,清空缓存的定时器序号
timer = null
// 延迟执⾏的情况下,函数会在延迟函数中执⾏
// 使⽤到之前缓存的参数和上下⽂
if (!immediate) {
func.apply(context, args)
context = args = null
}
}, wait)
// 这⾥返回的函数是每次实际调⽤的函数
return function (...params) {
// 如果没有创建延迟执⾏函数(later),就创建⼀个
if (!timer) {
timer = later()
// 如果是⽴即执⾏,调⽤函数
// 否则缓存参数和调⽤上下⽂
if (immediate) {
func.apply(this, params)
} else {
context = this
args = params
}
// 如果已有延迟执⾏函数(later),调⽤的时候清除原来的并重新设定⼀
// 这样做延迟函数会重新计时
} else {
clearTimeout(timer)
timer = later()
}
}
}整体函数实现的不难,总结⼀下。
- 对于按钮防点击来说的实现:如果函数是⽴即执⾏的,就⽴即调⽤,如果函数是延迟执⾏的,就缓存上下⽂和参数,放到延迟函数中去执⾏。⼀旦我开始⼀个定时器,只要我定时器还在,你每次点击我都重新计时。⼀旦你点累了,定时器时间到,定时器重置为null ,就可以再次点击了。
- 对于延时执⾏函数来说的实现:清除定时器ID,如果是延迟调⽤就调⽤函数
节流
防抖动和节流本质是不⼀样的。防抖动是将多次执⾏变为最后⼀次执⾏,节流是将多次执⾏ 变成每隔⼀段时间执⾏。
/*
* 节流 思路:
* 先开启一个定时任务执行,定时任务完成后则清空,当再调用时,如果定时任务仍存在则不执行任何操作
* */
function throttle(fn, space) {
let task = null;
return function () {
if (!task) {
task = setTimeout(function (...arg) {
task = null;
fn.apply(this, arg);
}, space);
}
}
}
let throttleShowLog = throttle(()=>{}, 3000);模拟实现 call 和 apply
可以从以下⼏点来考虑如何实现
- 不传⼊第⼀个参数,那么默认为 window
- 改变了 this 指向,让新的对象可以执⾏该函数。那么思路是否可以变成给新的对象添加
⼀个函数,然后在执⾏完以后删除?
Function.prototype.myCall = function (context) {
context = context || window
// 给 context 添加⼀个属性
// getValue.call(a, 'yck', '24') => a.fn = getValue
context.fn = this // 核心
// 将 context 后⾯的参数取出来
const args = [...arguments].slice(1)
// getValue.call(a, 'yck', '24') => a.fn('yck', '24')
const result = context.fn(...args)
// 删除 fn
delete context.fn
return result
}以上就是 call 的思路, apply 的实现也类似
Function.prototype.myApply = function (context) {
context = context || window
context.fn = this
let result
// 需要判断是否存储第⼆个参数
// 如果存在,就将第⼆个参数展开
if (arguments[1]) {
result = context.fn(...arguments[1])
} else {
result = context.fn()
}
delete context.fn
return result
}bind 和其他两个⽅法作⽤也是⼀致的,只是该⽅法会返回⼀个函数。并且我们可以通过bind 实现柯⾥化。
同样的,也来模拟实现下 bind
Function.prototype.myBind = function (context) {
if (typeof this !== 'function') {
throw new TypeError('Error')
}
const _this = this
const args = [...arguments].slice(1)
// 返回⼀个函数
return function F() {
// 因为返回了⼀个函数,我们可以 new F(),所以需要判断
if (this instanceof F) {
return new _this(...args, ...arguments)
}
return _this.apply(context, args.concat(...arguments))
}
}Promise 实现
Promise 是 ES6 新增的语法,解决了回调地狱的问题。
可以把 Promise 看成⼀个状态机。初始是 pending 状态,可以通过函数 resolve 和 reject ,将状态转变为 resolved 或者 rejected 状态,状态⼀旦改变就不能再次变化。
Generator 实现
Generator 是 ES6 中新增的语法,和 Promise ⼀样,都可以⽤来异步编程
从以上代码可以发现,加上 * 的函数执⾏后拥有了 next 函数,也就是说函数执⾏后返回 了⼀个对象。每次调⽤ next 函数可以继续执⾏被暂停的代码。以下是 Generator 函数的简单实现。
Map、FlatMap 和 Reduce
Map 作⽤是⽣成⼀个新数组,遍历原数组,将每个元素拿出来做⼀些变换然后 append 到新 的数组中。
[1, 2, 3].map((v) => v + 1)
// -> [2, 3, 4]Map 有三个参数,分别是当前索引元素,索引,原数组
['1','2','3'].map(parseInt)
// parseInt('1', 0) -> 1
// parseInt('2', 1) -> NaN
// parseInt('3', 2) -> NaNFlatMap 和 map 的作⽤⼏乎是相同的,但是对于多维数组来说,会将原数组降维。可以将 FlatMap 看成是 map + flatten ,⽬前该函数在浏览器中还不⽀持。
而且仅支持一维
const res = [1, [2], 3].flatMap((v) => v + 1)
// -> [ 2, '21', 4 ]如果想将⼀个多维数组彻底的降维,可以这样实现
const flattenDeep = (arr) => Array.isArray(arr)
? arr.reduce( (a, b) => [...a, ...flattenDeep(b)] , [])
: [arr]
flattenDeep([1, [[2], [3, [4]], 5]])Reduce 作⽤是数组中的值组合起来,最终得到⼀个值
function a() {
console.log(1);
}
function b() {
console.log(2);
}
[a, b].reduce((a, b) => a(b()))
// -> 2 1async 和 await ⼀个函数如果加上 async ,那么该函数就会返回⼀个 Promise
async function test() {
return "1";
}
console.log(test()); // -> Promise {: "1"} 可以把 async 看成将函数返回值使⽤ Promise.resolve() 包裹了下。
await 只能在 async 函数中使⽤。
function sleep() {
return new Promise(resolve => {
setTimeout(() => {
console.log('finish')
resolve("sleep");
}, 2000);
});
}
async function test() {
let value = await sleep();
console.log("object");
}
test()上⾯代码会先打印 finish 然后再打印 object 。因为 await 会等待 sleep 函数resolve ,所以即使后⾯是同步代码,也不会先去执⾏同步代码再来执⾏异步代码。
async 和 await 相⽐直接使⽤ Promise 来说,优势在于处理 then 的调⽤链,能够更清晰准确的写出代码。缺点在于滥⽤ await 可能会导致性能问题,因为 await 会阻塞代码,也许之后的异步代码并不依赖于前者,但仍然需要等待前者完成,导致代码失去了并发性。
下⾯来看⼀个使⽤ await 的代码。
var a = 0
var b = async () => {
a = a + await 10
console.log('2', a) // -> '2' 10
a = (await 10) + a
console.log('3', a) // -> '3' 20
}
b()
a++
console.log('1', a) // -> '1' 1对于以上代码你可能会有疑惑,这⾥说明下原理
- ⾸先函数 b 先执⾏,在执⾏到 await 10 之前变量 a 还是 0,因为在 await 内部实现了 generators , generators 会保留堆栈中东⻄,所以这时候 a = 0 被保存了下来
- 因为 await 是异步操作,遇到 await 就会⽴即返回⼀个 pending 状态的 Promise 对象,暂时返回执⾏代码的控制权,使得函数外的代码得以继续执⾏,所以会先执⾏console.log('1', a)
- 这时候同步代码执⾏完毕,开始执⾏异步代码,将保存下来的值拿出来使⽤,这时候 a = 10
- 然后后⾯就是常规执⾏代码了
Proxy
Proxy 是 ES6 中新增的功能,可以⽤来⾃定义对象中的操作
图层
⼀般来说,可以把普通⽂档流看成⼀个图层。特定的属性可以⽣成⼀个新的图层。不同的图 层渲染互不影响,所以对于某些频繁需要渲染的建议单独⽣成⼀个新图层,提⾼性能。但也 不能⽣成过多的图层,会引起反作⽤。
通过以下⼏个常⽤属性可以⽣成新图层
- 3D 变换: translate3d 、 translateZ
- will-change
- video 、 iframe 标签
- 通过动画实现的 opacity 动画转换
- position: fixed
重绘(Repaint)和回流(Reflow) 重绘和回流是渲染步骤中的⼀⼩节,但是这两个步骤对于性能影响很⼤。
- 重绘是当节点需要更改外观⽽不会影响布局的,⽐如改变 color 就叫称为重绘
- 回流是布局或者⼏何属性需要改变就称为回流
回流必定会发⽣重绘,重绘不⼀定会引发回流。回流所需的成本⽐重绘⾼的多,改变深层次 的节点很可能导致⽗节点的⼀系列回流。
所以以下⼏个动作可能会导致性能问题:
- 改变 window ⼤⼩
- 改变字体
- 添加或删除样式
- ⽂字改变
- 定位或者浮动
- 盒模型
很多⼈不知道的是,重绘和回流其实和 Event loop 有关。
- 当 Event loop 执⾏完 Microtasks 后,会判断 document 是否需要更新。因为浏览器是60Hz 的刷新率,每 16ms 才会更新⼀次。
- ...
- 执⾏ requestAnimationFrame 回调
减少重绘和回流
- 使⽤ translate 替代 top
- 使⽤ visibility 替换 display: none ,因为前者只会引起重绘,后者会引发回流 (改变了布局)
- 把 DOM 离线后修改,⽐如:先把 DOM 给 display:none (有⼀次 Reflow),然后你修 改100次,然后再把它显示出来
不要把 DOM 结点的属性值放在⼀个循环⾥当成循环⾥的变量
for(let i = 0; i < 1000; i++) { // 获取 offsetTop 会导致回流,因为需要去获取正确的值 console.log(document.querySelector('.test').style.offsetTop) }- 不要使⽤ table 布局,可能很⼩的⼀个⼩改动会造成整个 table 的重新布局
- 动画实现的速度的选择,动画速度越快,回流次数越多,也可以选择使⽤
requestAnimationFrame - CSS 选择符从右往左匹配查找,避免 DOM 深度过深
- 将频繁运⾏的动画变为图层,图层能够阻⽌该节点回流影响别的元素。⽐如对于 video 标签,浏览器会⾃动将该节点变为图层。
性能章节
DNS 预解析
DNS 解析也是需要时间的,可以通过预解析的⽅式来预先获得域名所对应的 IP
缓存
缓存对于前端性能优化来说是个很重要的点,良好的缓存策略可以降低资源的重复加载提⾼ ⽹⻚的整体加载速度。
通常浏览器缓存策略分为两种:强缓存和协商缓存。
强缓存
实现强缓存可以通过两种响应头实现: Expires 和 Cache-Control 。强缓存表示在缓存期 间不需要请求, state code 为 200
Expires: Wed, 22 Oct 2018 08:41:00 GMTExpires 是 HTTP / 1.0 的产物,表示资源会在 Wed, 22 Oct 2018 08:41:00 GMT 后过 期,需要再次请求。并且 Expires 受限于本地时间,如果修改了本地时间,可能会造成缓存 失效。
Cache-control: max-age=30Cache-Control 出现于 HTTP / 1.1,优先级⾼于 Expires 。该属性表示资源会在 30 秒后 过期,需要再次请求。
协商缓存
如果缓存过期了,我们就可以使⽤协商缓存来解决问题。协商缓存需要请求,如果缓存有效 会返回 304。
协商缓存需要客户端和服务端共同实现,和强缓存⼀样,也有两种实现⽅式。
Last-Modified 和 If-Modified-Since
Last-Modified 表示本地⽂件最后修改⽇期, If-Modified-Since 会将 Last-Modified 的值发送给服务器,询问服务器在该⽇期后资源是否有更新,有更新的话就会将新的资源发 送回来。
但是如果在本地打开缓存⽂件,就会造成 Last-Modified 被修改,所以在 HTTP / 1.1 出现 了 ETag 。
ETag 和 If-None-Match
ETag 类似于⽂件指纹, If-None-Match 会将当前 ETag 发送给服务器,询问该资源 ETag 是否变动,有变动的话就将新的资源发送回来。并且 ETag 优先级⽐ Last-Modified ⾼。
选择合适的缓存策略
对于⼤部分的场景都可以使⽤强缓存配合协商缓存解决,但是在⼀些特殊的地⽅可能需要选 择特殊的缓存策略
- 对于某些不需要缓存的资源,可以使⽤ Cache-control: no-store ,表示该资源不需 要缓存
- 对于频繁变动的资源,可以使⽤ Cache-Control: no-cache 并配合 ETag 使⽤,表示 该资源已被缓存,但是每次都会发送请求询问资源是否更新。
- 对于代码⽂件来说,通常使⽤ Cache-Control: max-age=31536000(超长时间) 并配合策略缓存使⽤,然后对⽂件进⾏指纹处理,⼀旦⽂件名变动就会⽴刻下载新的⽂件。
使⽤ HTTP / 2.0
因为浏览器会有并发请求限制,在 HTTP / 1.1 时代,每个请求都需要建⽴和断开,消耗了好⼏个 RTT 时间,并且由于 TCP 慢启动的原因,加载体积⼤的⽂件会需要更多的时间。
在 HTTP / 2.0 中引⼊了多路复⽤,能够让多个请求使⽤同⼀个 TCP 链接,极⼤的加快了⽹
⻚的加载速度。并且还⽀持 Header 压缩,进⼀步的减少了请求的数据⼤⼩。
预加载
在开发中,可能会遇到这样的情况。有些资源不需要⻢上⽤到,但是希望尽早获取,这时候 就可以使⽤预加载。
预加载其实是声明式的 fetch ,强制浏览器请求资源,并且不会阻塞 onload 事件,可以 使⽤以下代码开启预加载
预加载可以⼀定程度上降低⾸屏的加载时间,因为可以将⼀些不影响⾸屏但重要的⽂件延后 加载,唯⼀缺点就是兼容性不好。
预渲染
可以通过预渲染将下载的⽂件预先在后台渲染,可以使⽤以下代码开启预渲染
预渲染虽然可以提⾼⻚⾯的加载速度,但是要确保该⻚⾯百分百会被⽤户在之后打开,否则 就⽩⽩浪费资源去渲染
优化渲染过程
懒执⾏
懒执⾏就是将某些逻辑延迟到使⽤时再计算。该技术可以⽤于⾸屏优化,对于某些耗时逻辑 并不需要在⾸屏就使⽤的,就可以使⽤懒执⾏。懒执⾏需要唤醒,⼀般可以通过定时器或者 事件的调⽤来唤醒。
懒加载
懒加载就是将不关键的资源延后加载。
懒加载的原理就是只加载⾃定义区域(通常是可视区域,但也可以是即将进⼊可视区域)内 需要加载的东⻄。对于图⽚来说,先设置图⽚标签的 src 属性为⼀张占位图,将真实的图⽚ 资源放⼊⼀个⾃定义属性中,当进⼊⾃定义区域时,就将⾃定义属性替换为 src 属性,这样 图⽚就会去下载资源,实现了图⽚懒加载。
懒加载不仅可以⽤于图⽚,也可以使⽤在别的资源上。⽐如进⼊可视区域才开始播放视频等 等。
⽂件优化
图⽚优化
图⽚加载优化
- 不⽤图⽚。很多时候会使⽤到很多修饰类图⽚,其实这类修饰图⽚完全可以⽤ CSS 去代
替。 - 对于移动端来说,屏幕宽度就那么点,完全没有必要去加载原图浪费带宽。⼀般图⽚都⽤
CDN 加载,可以计算出适配屏幕的宽度,然后去请求相应裁剪好的图⽚。 - ⼩图使⽤ base64 格式
- 将多个图标⽂件整合到⼀张图⽚中(雪碧图)
- 选择正确的图⽚格式:
- 对于能够显示 WebP 格式的浏览器尽量使⽤ WebP 格式。因为 WebP 格式具有更好的图像数据压缩算法,能带来更⼩的图⽚体积,⽽且拥有⾁眼识别⽆差异的图像质量,缺点就是兼容性并不好
- ⼩图使⽤ PNG,其实对于⼤部分图标这类图⽚,完全可以使⽤ SVG 代替
- 照⽚使⽤ JPEG
其他⽂件优化
- CSS ⽂件放在 head 中
- 服务端开启⽂件压缩功能
- 将 script 标签放在 body 底部,因为 JS ⽂件执⾏会阻塞渲染。当然也可以把script 标签放在任意位置然后加上 defer ,表示该⽂件会并⾏下载,但是会放到HTML 解析完成后顺序执⾏。对于没有任何依赖的 JS ⽂件可以加上 async ,表示加载和渲染后续⽂档元素的过程将和 JS ⽂件的加载与执⾏并⾏⽆序进⾏。
- 执⾏ JS 代码过⻓会卡住渲染,对于需要很多时间计算的代码可以考虑使⽤
Webworker 。 Webworker 可以让我们另开⼀个线程执⾏脚本⽽不影响渲染。
CDN
静态资源尽量使⽤ CDN 加载,由于浏览器对于单个域名有并发请求上限,可以考虑使⽤多个 CDN 域名。对于 CDN 加载静态资源需要注意 CDN 域名要与主站不同,否则每次请求都会带 上主站的 Cookie。
其他
使⽤ Webpack 优化项⽬
- 对于 Webpack4,打包项⽬使⽤ production 模式,这样会⾃动开启代码压缩
- 使⽤ ES6 模块来开启 tree shaking(树摇),这个技术可以移除没有使⽤的代码
- 优化图⽚,对于⼩图可以使⽤ base64 的⽅式写⼊⽂件中
- 按照路由拆分代码,实现按需加载
- 给打包出来的⽂件名添加哈希,实现浏览器缓存⽂
如何渲染⼏万条数据并不卡住界⾯
这道题考察了如何在不卡住⻚⾯的情况下渲染数据,也就是说不能⼀次性将⼏万条都渲染出来,⽽应该⼀次渲染部分 DOM,那么就可以通过 requestAnimationFrame 来每 16 ms刷 新⼀次。
框架基本原理篇
MVVM 由以下三个内容组成
View:界⾯
Model:数据模型
ViewModel:作为桥梁负责沟通 View 和 Model
在 JQuery 时期,如果需要刷新 UI 时,需要先取到对应的 DOM 再更新 UI,这样数据和业务 的逻辑就和⻚⾯有强耦合。
在 MVVM 中,UI 是通过数据驱动的,数据⼀旦改变就会相应的刷新对应的 UI,UI 如果改 变,也会改变对应的数据。这种⽅式就可以在业务处理中只关⼼数据的流转,⽽⽆需直接和 ⻚⾯打交道。ViewModel 只关⼼数据和业务的处理,不关⼼ View 如何处理数据,在这种情况 下,View 和 Model 都可以独⽴出来,任何⼀⽅改变了也不⼀定需要改变另⼀⽅,并且可以将 ⼀些可复⽤的逻辑放在⼀个 ViewModel 中,让多个 View 复⽤这个 ViewModel。
在 MVVM 中,最核⼼的也就是数据双向绑定,例如 Angluar 的脏数据检测,Vue 中的数据劫持。
数据劫持
Vue2 内部使⽤了 Object.defineProperty() 来实现双向绑定,通过这个函数可以监听到 set 和 get 的事件。
以上代码简单的实现了如何监听数据的 set 和 get 的事件,但是仅仅如此是不够的,还需 要在适当的时候给属性添加发布订阅
{{name}}
在解析如上模板代码时,遇到 {{name}} 就会给属性 name 添加发布订阅。
Proxy 与 Object.defineProperty 对⽐
Object.defineProperty 虽然已经能够实现双向绑定了,但是他还是有缺陷的。
- 只能对属性进⾏数据劫持,所以需要深度遍历整个对象
- 对于数组不能监听到数据的变化(Vue2重写数组方法)
路由原理
前端路由实现起来其实很简单,本质就是监听 URL 的变化,然后匹配路由规则,显示相应的 ⻚⾯,并且⽆须刷新。⽬前单⻚⾯使⽤的路由就只有两种实现⽅式
- hash 模式
- history 模式
www.test.com/#/ 就是 Hash URL,当 # 后⾯的哈希值发⽣变化时,不会向服务器请求数 据,可以通过 hashchange 事件来监听到 URL 的变化,从⽽进⾏跳转⻚⾯。

History 模式是 HTML5 新推出的功能,⽐之 Hash URL 更加美观

Virtual Dom
为什么需要 Virtual Dom
众所周知,操作 DOM 是很耗费性能的⼀件事情,既然如此,我们可以考虑通过 JS 对象来模 拟 DOM 对象,毕竟操作 JS 对象⽐操作 DOM 省时的多。
当然在实际操作中,我们还需要给每个节点⼀个标识,作为判断是同⼀个节点的依据。所以 这也是 Vue 和 React 中官⽅推荐列表⾥的节点使⽤唯⼀的 key 来保证性能。
那么既然 DOM 对象可以通过 JS 对象来模拟,反之也可以通过 JS 对象来渲染出对应的 DOM
Virtual Dom 算法简述
DOM 是多叉树的结构,如果需要完整的对⽐两颗树的差异,那么需要的时间复杂度会是 O(n^ 3),这个复杂度肯定是不能接受的。于是 React 团队优化了算法,实现了 O(n) 的复杂度来对⽐差异。
实现 O(n) 复杂度的关键就是只对⽐同层的节点,⽽不是跨层对⽐,这也是考虑到在实际业务中很少会去跨层的移动 DOM 元素。
所以判断差异的算法就分为了两步
- ⾸先从上⾄下,从左往右遍历对象,也就是树的深度遍历,这⼀步中会给每个节点添加索引,便于最后渲染差异
- ⼀旦节点有⼦元素,就去判断⼦元素是否有不同
Vue 章节
NextTick 原理分析
nextTick 可以让我们在下次 DOM 更新循环结束之后执⾏延迟回调,⽤于获得更新后的 DOM。
⽣命周期分析
⽣命周期函数就是组件在初始化或者数据更新时会触发的钩⼦函数。
- created
- mounted
- upadted
- destoryed
安全章节
XSS
跨⽹站指令码(英语:Cross-site scripting,通常简称为:XSS)是⼀种⽹站应⽤程 式的安全漏洞攻击,是代码注⼊的⼀种。它允许恶意使⽤者将程式码注⼊到⽹⻚上, 其他使⽤者在观看⽹⻚时就会受到影响。这类攻击通常包含了 HTML 以及使⽤者端 脚本语⾔。
XSS 分为三种:反射型,存储型和 DOM-based
- 例如通过 URL 获取某些参数
- ⽐如写了⼀篇包含攻击代码 的⽂章
如何防御
最普遍的做法是转义输⼊输出的内容,对于引号,尖括号,斜杠进⾏转义
对于显示富⽂本来说,不能通过上⾯的办法来转义所有字符,因为这样会把需要的格式也过滤掉。这种情况通常采⽤⽩名单过滤的办法,当然也可以通过⿊名单过滤,但是考虑到需要 过滤的标签和标签属性实在太多,更加推荐使⽤⽩名单的⽅式。
CSP
内容安全策略 (CSP) 是⼀个额外的安全层,⽤于检测并削弱某些特定类型的攻击, 包括跨站脚本 (XSS) 和数据注⼊攻击等。⽆论是数据盗取、⽹站内容污染还是散发恶 意软件,这些攻击都是主要的⼿段。
CSRF
跨站请求伪造(英语:Cross-site request forgery),也被称为 one-click attack 或 者 session riding,通常缩写为 CSRF 或者 XSRF, 是⼀种挟制⽤户在当前已登录 的Web应⽤程序上执⾏⾮本意的操作的攻击⽅法。跟跨網站指令碼(XSS)相 ⽐,XSS 利⽤的是⽤户对指定⽹站的信任,CSRF 利⽤的是⽹站对⽤户⽹⻚浏览器 的信任。
假设⽹站中有⼀个通过 Get 请求提交⽤户评论的接⼝,那么攻击者就可以在钓⻥⽹站中加⼊ ⼀个图⽚,图⽚的地址就是评论接⼝

如果接⼝是 Post 提交的,就相对麻烦点,需要⽤表单来提交接⼝
如何防御
防范 CSRF 可以遵循以下⼏种规则:
- Get 请求不对数据进⾏修改
- 不让第三⽅⽹站访问到⽤户 Cookie
- 阻⽌第三⽅⽹站请求接⼝
- 请求时附带验证信息,⽐如验证码或者 token
SameSite
可以对 Cookie 设置 SameSite 属性。该属性设置 Cookie 不随着跨域请求发送,该属性可以很⼤程度减少 CSRF 的攻击,但是该属性⽬前并不是所有浏览器都兼容。
验证 Referer
对于需要防范 CSRF 的请求,我们可以通过验证 Referer 来判断该请求是否为第三⽅⽹站发起的。(用referer来判断上一页面是不是自己网站)
Token
服务器下发⼀个随机 Token(算法不能复杂),每次发起请求时将 Token 携带上,服务器验证 Token 是否有效。
密码安全
密码安全虽然⼤多是后端的事情,但是作为⼀名优秀的前端程序员也需要熟悉这⽅⾯的知识。
加盐
对于密码存储来说,必然是不能明⽂存储在数据库中的,否则⼀旦数据库泄露,会对⽤户造 成很⼤的损失。并且不建议只对密码单纯通过加密算法加密,因为存在彩虹表的关系。
⽹络章节
UDP
⾯向报⽂
UDP 是⼀个⾯向报⽂(报⽂可以理解为⼀段段的数据)的协议。意思就是 UDP 只是报⽂的搬运⼯,不会对报⽂进⾏任何拆分和拼接操作。
具体来说
- 在发送端,应⽤层将数据传递给传输层的 UDP 协议,UDP 只会给数据增加⼀个 UDP 头标识下是 UDP 协议,然后就传递给⽹络层了
- 在接收端,⽹络层将数据传递给传输层,UDP 只去除 IP 报⽂头就传递给应⽤层,不会任何拼接操作
不可靠性
- UDP 是⽆连接的,也就是说通信不需要建⽴和断开连接。
- UDP 也是不可靠的。协议收到什么数据就传递什么数据,并且也不会备份数据,对⽅能不能收到是不关⼼的
- UDP 没有拥塞控制,⼀直会以恒定的速度发送数据。即使⽹络条件不好,也不会对发送速率进⾏调整。这样实现的弊端就是在⽹络条件不好的情况下可能会导致丢包,但是优点也很明显,在某些实时性要求⾼的场景(⽐如电话会议)就需要使⽤ UDP ⽽不是 TCP。
⾼效
因为 UDP 没有 TCP 那么复杂,需要保证数据不丢失且有序到达。所以 UDP 的头部开销⼩, 只有⼋字节,相⽐ TCP 的⾄少⼆⼗字节要少得多,在传输数据报⽂时是很⾼效的。

头部包含了以下⼏个数据
- 两个⼗六位的端⼝号,分别为源端⼝(可选字段)和⽬标端⼝
- 整个数据报⽂的⻓度
- 整个数据报⽂的检验和(IPv4 可选 字段),该字段⽤于发现头部信息和数据中的错误
传输⽅式
UDP 不⽌⽀持⼀对⼀的传输⽅式,同样⽀持⼀对多,多对多,多对⼀的⽅式,也就是说 UDP
提供了单播,多播,⼴播的功能
TCP
头部
TCP 头部⽐ UDP 头部复杂的多

对于 TCP 头部来说,以下⼏个字段是很重要的
- Sequence number,这个序号保证了 TCP 传输的报⽂都是有序的,对端可以通过序号顺 序的拼接报⽂
- Acknowledgement Number,这个序号表示数据接收端期望接收的下⼀个字节的编号是 多少,同时也表示上⼀个序号的数据已经收到
- Window Size,窗⼝⼤⼩,表示还能接收多少字节的数据,⽤于流量控制
- 标识符
建⽴连接三次握⼿

你是否有疑惑明明两次握⼿就可以建⽴起连接,为什么还需要第三次应答?
因为这是为了防⽌失效的连接请求报⽂段被服务端接收(避免丢包的情况),从⽽产⽣错误。
可以想象如下场景。客户端发送了⼀个连接请求 A,但是因为⽹络原因造成了超时,这时TCP 会启动超时重传的机制再次发送⼀个连接请求 B。此时请求顺利到达服务端,服务端应答完就建⽴了请求。如果连接请求 A 在两端关闭后终于抵达了服务端,那么这时服务端会认为客户端⼜需要建⽴ TCP 连接,从⽽应答了该请求并进⼊ ESTABLISHED 状态。此时客户端其实是 CLOSED 状态,那么就会导致服务端⼀直等待,造成资源的浪费。
PS:在建⽴连接中,任意⼀端掉线,TCP 都会重发 SYN 包,⼀般会重试五次,在建⽴连接 中可能会遇到 SYN FLOOD 攻击。遇到这种情况你可以选择调低重试次数或者⼲脆在不能处 理的情况下拒绝请求。
断开链接四次握⼿
为什么 A 要进⼊ TIME-WAIT 状态,等待 2MSL 时间后才进⼊ CLOSED 状态?
为了保证 B 能收到 A 的确认应答。若 A 发完确认应答后直接进⼊ CLOSED 状态,如果确认 应答因为⽹络问题⼀直没有到达,那么会造成 B 不能正常关闭。
ARQ 协议
ARQ 协议也就是超时重传机制。通过确认和超时机制保证了数据的正确送达,ARQ 协议包含
停⽌等待 ARQ 和连续 ARQ。
滑动窗⼝
在上⾯⼩节中讲到了发送窗⼝。在 TCP 中,两端都维护着窗⼝:分别为发送端窗⼝和接收端窗⼝。
发送端窗⼝包含已发送但未收到应答的数据和可以发送但是未发送的数据

发送端窗⼝是由接收窗⼝剩余⼤⼩决定的。接收⽅会把当前接收窗⼝的剩余⼤⼩写⼊应答报 ⽂,发送端收到应答后根据该值和当前⽹络拥塞情况设置发送窗⼝的⼤⼩,所以发送窗⼝的 ⼤⼩是不断变化的。
当发送端接收到应答报⽂后,会随之将窗⼝进⾏滑动

滑动窗⼝实现了流量控制。接收⽅通过报⽂告知发送⽅还可以发送多少数据,从⽽保证接收 ⽅能够来得及接收数据。
Zero 窗⼝
在发送报⽂的过程中,可能会遇到对端出现零窗⼝的情况。在该情况下,发送端会停⽌发送 数据,并启动 persistent timer 。该定时器会定时发送请求给对端,让对端告知窗⼝⼤⼩。在 重试次数超过⼀定次数后,可能会中断 TCP 链接。
拥塞处理
拥塞处理和流量控制不同,后者是作⽤于接收⽅,保证接收⽅来得及接受数据。⽽前者是作 ⽤于⽹络,防⽌过多的数据拥塞⽹络,避免出现⽹络负载过⼤的情况。
拥塞处理包括了四个算法,分别为:慢开始,拥塞避免,快速重传,快速恢复。
慢开始算法
慢开始算法,顾名思义,就是在传输开始时将发送窗⼝慢慢指数级扩⼤,从⽽避免⼀开始就 传输⼤量数据导致⽹络拥塞。
慢开始算法步骤具体如下
- 连接初始设置拥塞窗⼝(Congestion Window) 为 1 MSS(⼀个分段的最⼤数据量)
- 每过⼀个 RTT 就将窗⼝⼤⼩乘⼆
- 指数级增⻓肯定不能没有限制的,所以有⼀个阈值限制,当窗⼝⼤⼩⼤于阈值时就会启动
拥塞避免算法。
拥塞避免算法
拥塞避免算法相⽐简单点,每过⼀个 RTT (来回通讯延迟 Round-trip delay)窗⼝⼤⼩只加⼀,这样能够避免指数级增⻓导致⽹ 络拥塞,慢慢将⼤⼩调整到最佳值。
在传输过程中可能定时器超时的情况,这时候 TCP 会认为⽹络拥塞了,会⻢上进⾏以下步骤:
- 将阈值设为当前拥塞窗⼝的⼀半
- 将拥塞窗⼝设为 1 MSS
- 启动拥塞避免算法
快速重传
快速重传⼀般和快恢复⼀起出现。⼀旦接收端收到的报⽂出现失序的情况,接收端只会回复 最后⼀个顺序正确的报⽂序号(没有 Sack 的情况下)。如果收到三个重复的 ACK,⽆需等 待定时器超时再重发⽽是启动快速重传。具体算法分为两种:
HTTP
HTTP 协议是个⽆状态协议,不会保存状态。
Post 和 Get 的区别
先引⼊副作⽤和幂等的概念。
副作⽤指对服务器上的资源做改变,搜索是⽆副作⽤的,注册是副作⽤的。
幂等指发送 M 和 N 次请求(两者不相同且都⼤于 1),服务器上资源的状态⼀致,⽐如注册 10 个和 11 个帐号是不幂等的,对⽂章进⾏更改 10 次和 11 次是幂等的。
在规范的应⽤场景上说,Get 多⽤于⽆副作⽤,幂等的场景,例如搜索关键字。Post 多⽤于 副作⽤,不幂等的场景,例如注册。
在技术上说:
- Get 请求能缓存,Post 不能
- Post 相对 Get 安全⼀点点,因为Get 请求都包含在 URL ⾥,且会被浏览器保存历史纪录,Post 不会,但是在抓包的情况下都是⼀样的。
- Post 可以通过 request body来传输⽐ Get 更多的数据,Get 没有这个技术
- URL有⻓度限制,会影响 Get 请求,但是这个⻓度限制是浏览器规定的,不是 RFC (Request for Comments,请求意见稿的相关标准)规定的
- Post ⽀持更多的编码类型且不对数据类型限制
常⻅状态码
2XX 成功
- 200 OK,表示从客户端发来的请求在服务器端被正确处理
- 204 No content,表示请求成功,但响应报⽂不含实体的主体部分
- 205 Reset Content,表示请求成功,但响应报⽂不含实体的主体部分,但是与 204 响应
不同在于要求请求⽅重置内容 - 206 Partial Content,进⾏范围请求
3XX 重定向
- 301 moved permanently,永久性重定向,表示资源已被分配了新的 URL
- 302 found,临时性重定向,表示资源临时被分配了新的 URL
- 303 see other,表示资源存在着另⼀个 URL,应使⽤ GET ⽅法获取资源
- 304 not modified,表示服务器允许访问资源,但因发⽣请求未满⾜条件的情况
- 307 temporary redirect,临时重定向,和302含义类似,但是期望客户端保持请求⽅法不
变向新的地址发出请求
4XX 客户端错误
- 400 bad request,请求报⽂存在语法错误
- 401 unauthorized,表示发送的请求需要有通过 HTTP 认证的认证信息
- 403 forbidden,表示对请求资源的访问被服务器拒绝
- 404 not found,表示在服务器上没有找到请求的资源
5XX 服务器错误
- 500 internal sever error,表示服务器端在执⾏请求时发⽣了错误
- 501 Not Implemented,表示服务器不⽀持当前请求所需要的某个功能
- 502 Bad Gateway ,一般来自上游服务器无效响应,多来自nginx配置错误
- 503 service unavailable,表明服务器暂时处于超负载或正在停机维护,⽆法处理请求
HTTP ⾸部



HTTPS
HTTPS 还是通过了 HTTP 来传输信息,但是信息通过 TLS 协议进⾏了加密。
TLS
TLS 协议位于传输层之上,应⽤层之下。⾸次进⾏ TLS 协议传输需要两个 RTT ,接下来可以 通过 Session Resumption 减少到⼀个 RTT。
在 TLS 中使⽤了两种加密技术,分别为:对称加密和⾮对称加密。
对称加密
对称加密就是两边拥有相同的秘钥,两边都知道如何将密⽂加密解密。
⾮对称加密:
有公钥私钥之分,公钥所有⼈都可以知道,可以将数据⽤公钥加密,但是将数据解密必须使 ⽤私钥解密,私钥只有分发公钥的⼀⽅才知道。
TLS 握⼿过程如下图:
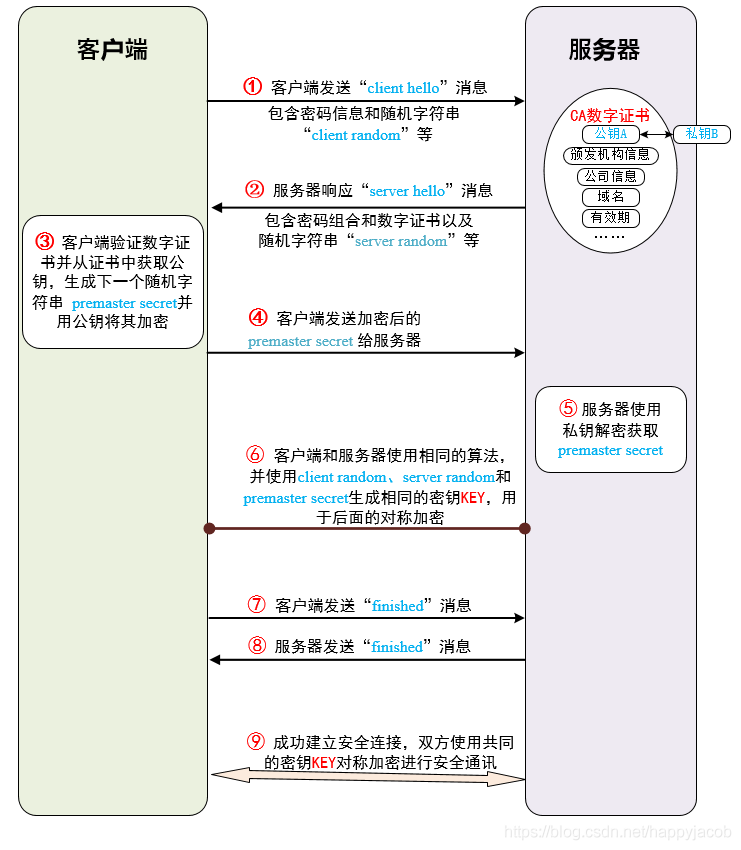
- 客户端发送⼀个随机值,需要的协议和加密⽅式
- 服务端收到客户端的随机值,⾃⼰也产⽣⼀个随机值,并根据客户端需求的协议和加密⽅式来使⽤对应的⽅式,发送⾃⼰的证书(如果需要验证客户端证书需要说明)
- 客户端收到服务端的证书并验证是否有效,验证通过会再⽣成⼀个随机值,通过服务端证书的公钥去加密这个随机值并发送给服务端,如果服务端需要验证客户端证书的话会附带证书
- 服务端收到加密过的随机值并使⽤私钥解密获得第三个随机值,这时候两端都拥有了三个随机值,可以通过这三个随机值按照之前约定的加密⽅式⽣成密钥,接下来的通信就可以通过该密钥来加密解密
通过以上步骤可知,在 TLS 握⼿阶段,两端使⽤⾮对称加密的⽅式来通信,但是因为⾮对称 加密损耗的性能⽐对称加密⼤,所以在正式传输数据时,两端使⽤对称加密的⽅式通信。
PS:以上说明的都是 TLS 1.2 协议的握⼿情况,在 1.3 协议中,⾸次建⽴连接只需要⼀个 RTT,后⾯恢复连接不需要 RTT 了。
### HTTP 2.0
HTTP 2.0 相⽐于 HTTP 1.X,可以说是⼤幅度提⾼了 web 的性能。
在 HTTP 1.X 中,为了性能考虑,我们会引⼊雪碧图、将⼩图内联、使⽤多个域名等等的⽅式。这⼀切都是因为浏览器限制了同⼀个域名下的请求数量,当⻚⾯中需要请求很多资源的时候,队头阻塞(Head of line blocking)会导致在达到最⼤请求数量时,剩余的资源需要等待其他资源请求完成后才能发起请求。
在 HTTP 1.X 中,因为队头阻塞的原因,你会发现请求是这样的
队头阻塞(head-of-line blocking)发生在一个TCP分节丢失,导致其后续分节不按序到达接收的时候。 该后续分节将被接收端一直保持,直到丢失的第一个分节被发送端重传并到达接收为止。 该后续分节的延迟递送确保接收应用进程能够按照发送端的发送顺序接收数据。
⼆进制传输
HTTP 2.0 中所有加强性能的核⼼点在于此。在之前的 HTTP 版本中,我们是通过⽂本的⽅式 传数据。在 HTTP 2.0 中引⼊了新的编码机制,所有传输的数据都会被分割,并采⽤⼆进制 格式码。
多路复⽤
在 HTTP 2.0 中,有两个⾮常重要的概念,分别是帧(frame)和流(stream)。
帧代表着最⼩的数据单位,每个帧会标识出该帧属于哪个流,流也就是多个帧组成的数据流。
多路复⽤,就是在⼀个 TCP 连接中可以存在多条流。换句话说,也就是可以发送多个请求,对端可以通过帧中的标识知道属于哪个请求。通过这个技术,可以避免 HTTP 旧版本中的队头阻塞问题,极⼤的提⾼传输性能。
Header 压缩
在 HTTP 1.X 中,我们使⽤⽂本的形式传输 header,在 header 携带 cookie 的情况下,可能 每次都需要重复传输⼏百到⼏千的字节。
在 HTTP 2.0 中,使⽤了 HPACK 压缩格式对传输的 header 进⾏编码,减少了 header 的⼤ ⼩。并在两端维护了索引表,⽤于记录出现过的 header ,后⾯在传输过程中就可以传输已经 记录过的 header 的键名,对端收到数据后就可以通过键名找到对应的值。
服务端 Push
在 HTTP 2.0 中,服务端可以在客户端某个请求后,主动推送其他资源。
可以想象以下情况,某些资源客户端是⼀定会请求的,这时就可以采取服务端 push 的技术,提前给客户端推送必要的资源,这样就可以相对减少⼀点延迟时间。当然在浏览器兼容的情 况下你也可以使⽤ prefetch 。
QUIC
这是⼀个⾕歌出品的基于 UDP 实现的同为传输层的协议,⽬标很远⼤,希望替代 TCP 协议。
- 该协议⽀持多路复⽤,虽然 HTTP 2.0 也⽀持多路复⽤,但是下层仍是 TCP,因为 TCP的重传机制,只要⼀个包丢失就得判断丢失包并且重传,导致发⽣队头阻塞的问题,但是UDP 没有这个机制
- 实现了⾃⼰的加密协议,通过类似 TCP 的 TFO 机制可以实现 0-RTT,当然 TLS 1.3 已经实现了 0-RTT 了
⽀持重传和纠错机制(向前恢复),在只丢失⼀个包的情况下不需要重传,使⽤纠错机制恢复丢失的包
- 纠错机制:通过异或的⽅式,算出发出去的数据的异或值并单独发出⼀个包,服务端在发现有⼀个包丢失的情况下,通过其他数据包和异或值包算出丢失包
- 在丢失两个包或以上的情况就使⽤重传机制,因为算不出来了
DNS
DNS 的作⽤就是通过域名查询到具体的 IP。
因为 IP 存在数字和英⽂的组合(IPv6),很不利于⼈类记忆,所以就出现了域名。你可以把 域名看成是某个 IP 的别名,DNS 就是去查询这个别名的真正名称是什么。
在 TCP 握⼿之前就已经进⾏了 DNS 查询,这个查询是操作系统⾃⼰做的。当你在浏览器中 想访问 www.google.com 时,会进⾏⼀下操作:
- 操作系统会⾸先在本地缓存中查询
- 没有的话会去系统配置的 DNS 服务器中查询
- 如果这时候还没得话,会直接去 DNS 根服务器查询,这⼀步查询会找出负责 com 这个⼀级域名的服务器
- 然后去该服务器查询 google 这个⼆级域名
- 接下来三级域名的查询其实是我们配置的,你可以给 www 这个域名配置⼀个 IP,然后还可以给别的三级域名配置⼀个 IP
以上介绍的是 DNS 迭代查询,还有种是递归查询,区别就是前者是由客户端去做请求,后者是系统配置的 DNS 服务器做请求,得到结果后将数据返回给客户端。
PS:DNS 是基于 UDP 做的查询。
从输⼊ URL 到⻚⾯加载完成的过程
这是⼀个很经典的⾯试题,在这题中可以将本⽂讲得内容都串联起来。
- ⾸先做 DNS 查询,如果这⼀步做了智能 DNS 解析的话,会提供访问速度最快的 IP 地址回来。
- 接下来是 TCP 握⼿,应⽤层会下发数据给传输层,这⾥ TCP 协议会指明两端的端⼝号,然后下发给⽹络层。⽹络层中的 IP 协议会确定 IP 地址,并且指示了数据传输中如何跳转路由器。然后包会再被封装到数据链路层的数据帧结构中,最后就是物理层⾯的传输了。
- TCP 握⼿结束后会进⾏ TLS 握⼿,然后就开始正式的传输数据。
- 数据在进⼊服务端之前,可能还会先经过负责负载均衡的服务器,它的作⽤就是将请求合理的分发到多台服务器上,这时假设服务端会响应⼀个 HTML ⽂件
- ⾸先浏览器会判断状态码是什么,如果是 200 那就继续解析,如果 400 或 500 的话就会报错,如果 300 的话会进⾏重定向,这⾥会有个重定向计数器,避免过多次的重定向,超过次数也会报错。
- 浏览器开始解析⽂件,如果是 gzip 格式的话会先解压⼀下,然后通过⽂件的编码格式知道该如何去解码⽂件。
- ⽂件解码成功后会正式开始渲染流程,先会根据 HTML 构建 DOM 树,有 CSS 的话会去构建 CSSOM 树。如果遇到 script 标签的话,会判断是否存在 async 或者 defer,前者会并⾏进⾏下载并执⾏ JS,后者会先下载⽂件,然后等待 HTML 解析完成后顺序执⾏,如果以上都没有,就会阻塞住渲染流程直到 JS 执⾏完毕。遇到⽂件下载的会去下 载⽂件,这⾥如果使⽤ HTTP 2.0 协议的话会极⼤的提⾼多图的下载效率。
- 初始的 HTML 被完全加载和解析后会触发 DOMContentLoaded 事件
- CSSOM 树和 DOM 树构建完成后会开始⽣成 Render 树,这⼀步就是确定⻚⾯元素的布局、样式等等诸多⽅⾯的东⻄
- 在⽣成 Render 树的过程中,浏览器就开始调⽤ GPU 绘制,合成图层,将内容显示在屏幕上了
数据结构章节
科班就略了哈....