TextRNN实现文本分类
TextRNN实现文本分类
任务介绍
给定一个如下的外卖评论的数据(1w条),训练模型分类好评和差评。

思路
给出的baseline为0.82(F1),方法是将语料中所有字拆开训练成300D的word2vec后,每一句的处理采用将所有字的向量相加取平均的方法得到句向量(300D),然后使用一个全连接层进行训练。
优化的思路自然就是从这个方法的缺点入手,主要的提升点有:
- 把所有的字拆开进行训练可以改进为先清洗语料(清除一些特殊符号、表情包等),并用分词后的词(word)进行word2vec
- 原来句向量的方法对句子中的信息可能会丢失,可以改用把所有词向量都输入网络中进行训练
- 改用更加复杂的模型如TextRNN、TextCNN等(最后使用了双层的LSTM)。另外的方法可以参考(https://www.cnblogs.com/sandwichnlp/p/11698996.html)
TextRNN
TextRNN的结构如图所示
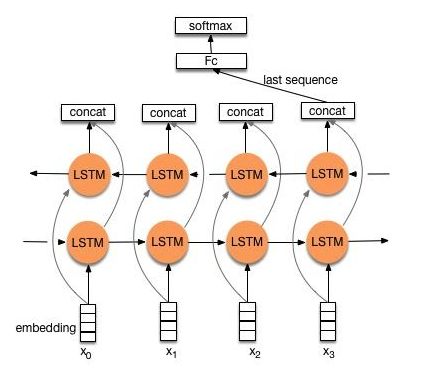
可以看到主要就是把词向量输入一个BiLSTM(双向LSTM),将两个方向最后得到的向量concat,然后经过一个全连接层(FC),最后softmax。
LSTM结构解决了RNN中梯度消失(Vanishing gradients)和梯度爆炸(exploding gradients)的问题,原始的RNN对短期输入比较敏感,而LSTM增加了一个单元状态(cell state)来记忆长期的信息,通过输入门(input gate)、输出门(output gate)和遗忘门(forget gate)来决定LSTM最终的输出。另外还有一种变体叫GRU,其仅有更新门(update gate)和重置门(reset gate)且将单元状态和输出合并。(详见https://www.jianshu.com/p/19fd7206f070 )
但最终使用的网络却并非这一个结构,在测试中,这一网络最好的表现只有0.87(F1),最后取得0.90好成绩的网络是一个堆叠的uniLSTM网络,其结构如下

可以看到其中添加了Dropout来防止过拟合(详见 https://blog.csdn.net/program_developer/article/details/80737724),个人觉得因为训练数据偏少(1w条,划分训练集测试集后更少),因此优势较为明显。其主要为两个单向的LSTM加上Dropout和Softmax。
新手上路
看了这么多理论,就可以开始动手实践了。实际上动手实践才是比较难的内容(因为模型实现主要使用keras,对模型内部细节不必理解得十分透彻)。
除此之外环境也是一个十分让人头疼的事情,tensorflow1.x与cuda、cudnn等有十分令人头大的依赖关系,其配置过程也十分麻烦,这里一劳永逸使用了据说比较稳定的tf2.1。
环境
- Win10 1903 @ R7-3700x 16G RTX-2060
- Anaconda
- Python 3.7.6
- tensorflow-gpu==2.1
- CUDA 10.1
- CuDNN 7.6
ps. 建议保持CUDA和CuDNN的版本一直不变,直到tf指定更新的版本。另外建议你使用与我一样的环境配置。
过程一共有如下几步:数据预处理、模型构建、训练预测。
数据预处理
首先要清洗掉一些特殊符号、表情等,这一步比较简单,用正则表达式很方便就能完成。贴下代码
import re
pat = re.compile("[^u4e00-u9fa5\w,.,。!!?! ]")
res = []
with open("../data/input/train_input.txt", "r", encoding='utf-8') as f:
for line in f:
line = re.sub(pat, "", line)
res.append(line)
with open("../data/input/train_input_.txt", 'w', encoding='utf-8') as fw:
for line in res:
fw.write(line + "\n")
然后是词向量(word2vec),这里使用gensim的工具,处理完后保存。贴下代码
import pandas as pd
import jieba
import logging
from gensim.models.word2vec import Word2Vec
file = "data/train.csv"
data = pd.read_csv(file, sep='\t', encoding='UTF-8', header=None)
sentence = list(data[1])
def segment_sen(sen):
sen_list = jieba.lcut(sen)
return sen_list
sens_list = [segment_sen(i) for i in sentence]
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
model = Word2Vec(sens_list, min_count=1, iter=20, size=300)
model.save("models/word2vec.model")
注意这里的 Word2Vec(sens_list, min_count=1, iter=20, size=300) 一共有四个参数,分别是词列表,最小出现次数(设置为1可以抛弃只出现过1次的词,当然同时也会造成后面有一些词没有词向量的情况),迭代次数和词向量的维度(这里选择了比较常见的300D)。最后把模型保存下来,后面还会用来把句子转换成向量表示(embedding)。
如此一来就已经得到了词的向量表示,接下来需要把句子用句向量表示。贴下代码
from gensim.models.word2vec import Word2Vec
import numpy as np
import pickle
import jieba
corpus = []
with open("../data/input/train_input_.txt", 'r', encoding='utf-8') as f:
for line in f:
corpus.append(line.strip())
with open("../models/word2vec.model", 'rb') as f:
w2v = Word2Vec.load(f)
all_sens = []
for sen in corpus:
sen_vec = []
word_list = jieba.lcut(sen)
for word in word_list:
try:
word_vec = w2v.wv[word]
sen_vec.append(word_vec)
except KeyError:
continue
print(len(sen_vec))
if len(sen_vec) <= 50:
for i in range(len(sen_vec),50):
sen_vec.append(np.zeros(300))
else:
sen_vec = sen_vec[:50]
sen_vec = np.asarray(sen_vec)
all_sens.append(sen_vec)
print(all_sens)
with open("../data/w2v-vec.pickle", "wb") as fw:
pickle.dump(all_sens, fw)
print("DONE!")
这里对句子的长度进行了padding,统一长度为50(观察语料后决定, 绝大多数语料小于这个长度),若语料不足50以0补足,超过则截断。最后把所有句向量用pickle保存。
ps. pickle是一个能将python数据结构(包括numpy数据结构)序列化保存的包,主要就两个方法(load和dump),文件打开时需要用二进制方式(指定b)进行读写。
到这里数据处理部分结束。
模型构建
先贴代码
def TextRNN(self):
model = Sequential()
# model.add(layers.Dropout(0.2))
# model.add(layers.Bidirectional(layers.LSTM(128, return_sequences=True), merge_mode='concat', input_shape=(50, 300)))
model.add(layers.LSTM(256, return_sequences=True, input_shape=(50, 300)))
model.add(layers.Dropout(0.1))
model.add(layers.LSTM(256, return_sequences=True, input_shape=(50, 300)))
model.add(layers.Dropout(0.1))
# model.add(layers.Bidirectional(layers.LSTM(128, return_sequences=True), merge_mode='concat', input_shape=(50, 300)))
# model.add(layers.Dropout(0.1))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1))
# model.add(layers.Softmax())
model.compile(optimizer=Adam(1e-4), loss='binary_crossentropy', metrics=['accuracy'])
model.build((50,))
model.summary()
return model
实际上在实验中我一共尝试了多种RNN的组合,例如一个BiLSTM(0.87左右)、两个BiLSTM(0.84)、单个LSTM不加Dropout、单个LSTM加Dropout、双层LSTM不加Dropout、双层LSTM加Dropout(最佳)。同时Dropout的比例尝试过0.5(最差)、0.3、0.2、0.1(最佳)、0.05,表现在loss下降得比较快且最后的loss比较小。另外也有尝试LSTM的单元数128和256,最终256取得最佳结果,而BiLSTM则128取得最佳结果。最后的softmax层经过实验发现改为一层64relu的全连接层更好。
模型训练
训练的过程就比较简单,把测试集给模型训练就好了。这里还使用到了一个工具类(utils)。贴下代码
import pandas as pd
import numpy as np
import pickle
def load_pickle_data(pickle_path):
with open(pickle_path, 'rb')as f:
pickle_data = pickle.load(f)
return np.array(pickle_data)
def load_label_data():
label_data = pd.read_csv('../data/train.csv', '\t')['label'].values
return label_data
def train_test_split(x, y, seg=0.8):
split_num = int(len(x) * seg)
x_train, x_test = x[:split_num], x[split_num:]
y_train, y_test = y[:split_num], y[split_num:]
return x_train, x_test, y_train, y_test
def load_train_data():
x_data = load_pickle_data('../data/w2v-vec.pickle')
y_data = load_label_data()
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data)
return x_train, x_test, y_train, y_test
from src.model import CommentFoodSafetyModel
from src.data_process import load_train_data
from src.evaluate import get_f1_score, get_accuracy
x_train, x_test, y_train, y_test = load_train_data()
model = CommentFoodSafetyModel().TextRNN()
# model = CommentFoodSafetyModel().TextCNN()
model.fit(x_train, y_train, validation_split=0.1, epochs=20, verbose=1)
y_pred = model.predict(x_test)
f1 = get_f1_score(y_test, y_pred)
acc = get_accuracy(y_test, y_pred)
print(f1)
print(acc)
模型评价
主要使用f1-macro和准确率进行评价,用到了sklearn这个包。贴下代码
from sklearn.metrics import f1_score
import numpy as np
def translate_data(y_pred):
y_prediction = []
for y in y_pred:
if y[0] >= 0.4:
y_prediction.append(1)
else:
y_prediction.append(0)
return y_prediction
def get_f1_score(y_true, y_pred):
y_pred = translate_data(y_pred)
f1 = f1_score(y_true, y_pred, average='macro')
return f1
def get_accuracy(y_true, y_pred):
y_pred = translate_data(y_pred)
acc = 0
pred = [0, 0]
true = [0, 0]
for y1, y2 in zip(y_true, y_pred):
if y1 == y2:
acc += 1
if y1 == 0:
true[0] += 1
elif y1 == 1:
true[1] += 1
if y2 == 0:
pred[0] += 1
elif y2 == 1:
pred[1] += 1
acc = acc / len(y_true)
result = 'true label: ' + str({'0': true[0], '1': true[1]}) + '\n'
result += 'prediction label: ' + str({'0': pred[0], '1': pred[1]})
return acc, result
最终结果
最后取得了0.90的F1-macro和94.9%的正确率,可以说666了(据闻比赛最高0.93F1?)
![]()
总结
虽然这个模型是跑起来了,也取得了比较可以的结果,但是其实做的过程中基本只是抱着能用的想法,中途也遇到很多坑。另外在最后面模型跑起来了进行一些参数调整优化的时候也没有详细实验、记录下数据,也没有深入探究原因。
过程中遇到的一些坑汇总
各种奇怪的环境问题(DLL not found、Unknown Error: DNN not implemented等)
一定要确定环境的tf版本与CUDA、CuDNN相对应,相关的对应可以百度,建议使用我这一套,很省心。
model.fit报维数错误
如果没有在model中加一个Input层或者说在LSTM中设置input_shape=(50,300)在使用model.fit()时会因为无法识别你给的是一个列表而导致给进去一个三维的数组(有点笨)。另外据说如果没有对句子进行padding,也会出现识别的问题。
其他林林总总的参数、维度问题
查阅tensorflow的文档(https://www.tensorflow.org/api/stable?hl=en),另外tensorflow的另一篇教程也比较有参考意义(https://www.tensorflow.org/tutorials/text/text_classification_rnn?hl=en)。
再另外在构建模型的时候不妨手算一下维度之类的信息。
MemeoryError
内存不够了,加钱吧