Leetcode刷题记录
这里写目录标题
- 1.线性表
-
- 1.1 链表
-
- 1.1.1 反转链表
- 1.1.2 相交链表
- 1.1.3 合并两个有序链表
- 1.1.4 分隔链表
- 1.1.5 环形链表
- 1.1.6 环形链表2
- 1.1.7 反转链表2
- 1.1.8 复制带随机指针的链表
- 1.1.9 奇偶链表
- 2.回溯
-
- 2.1 组合总和
-
- 2.1 组合总和2
- 2.3 全排列
- 2.4 全排列2
- 3. 树
-
- 3.1 树的三种遍历
- 3.2 二叉树的层次遍历
- 3.3 二叉树的锯齿形层序遍历
- 3.4 路径总和2
- 3.5 二叉树的最近公共祖先
- 3.6 二叉树的右视图
- 3.7 将有序数组转换为二叉搜索树
- 3.8 删除二叉搜索树中的节点
- 3.9 路径总和 III
- 3.10 平衡二叉树
- 3.11 二叉树的最小深度
- 3.12 左叶子之和
- 3.13 二叉搜索树的最小绝对差
- 4 动态规划
-
- 4.1 最长公共子序列LCS
- 4.2 最长回文子序列
- 4.3 最长回文子串
- 4.4 最长递增序列
- 4.5 最长连续递增序列
- 4.6 最长重复子数组
1.线性表
1.1 链表
做链表的题我认为一定要画图,清晰一下思路最重要。
1.1.1 反转链表
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。

在链表中,一个节点可以表示为数据域和指针域,画图的时候先不要画指针域的指向,先把每个节点都画出来就行了。
思路:
- 因为这道题是需要反转链表,在遍历链表的时候,我们可以把每一个节点的next域指向它的前一个节点。
- 因为链表是单向的,后面的节点肯定不会有前一个节点的位置,所以需要一个节点表示前一个节点。并且第一个节点其实没有前面的节点的,我们就新建一个null节点。
- 前面两步其实以及规定了每个节点的next的指向(反方向)那遍历的时候就需要原本每一个节点的下一个节点所以用一个指针指向每个节点的下一个节点。
代码:
class Solution {
public ListNode reverseList(ListNode head) {
//pre节点就是保存每一个节点的前面节点,用以把每一个节点的next域指向它的前一个节点
ListNode pre = null;
//curr节点表示当前节点的位置
ListNode curr = head;
//next节点表示原本每一个节点的下一个节点
ListNode next = null;
while(curr != null){
next = curr.next;
curr.next = pre;
pre = curr;
curr = next;
}
return pre;
}
}
1.1.2 相交链表
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
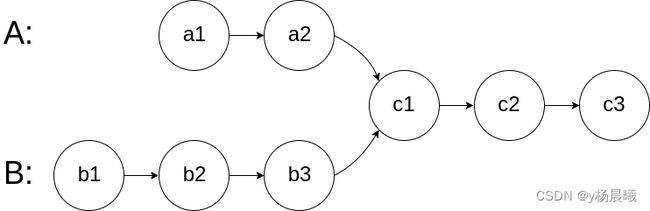
思路:就是找到共有的那一个点么,比较简单,使用set进行存储就行。
先存储a里面的所有节点,然后遍历b,如果找到了就说明有相交的部分。
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
Set<ListNode> set = new HashSet<>();
ListNode node = headA;
while(node!= null){
set.add(node);
node = node.next;
}
node = headB;
while(node != null){
if(set.contains(node)){
return node;
}
node = node.next;
}
return null;
}
}
1.1.3 合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。

思路:
- 这两个链表都是有序的,那我们就相当于新建一个大的链表。使用两个指针指向两个链表的表头,然后当两个指针都不为null的时候进行值的比较,哪个小就放在新链表里,然后那个指针向后移动一位就行。
- 当有一个链表遍历完了,那另一个链表剩下的节点都依次加到新链表就行了。
class Solution {
public ListNode mergeTwoLists(ListNode list1, ListNode list2) {
ListNode list = new ListNode();
ListNode cur = list;
while(list1 != null && list2 != null){
if(list1.val <= list2.val){
list.next = new ListNode(list1.val);
list1 = list1.next;
}else{
list.next = new ListNode(list2.val);
list2 = list2.next;
}
list = list.next;
}
while(list1 != null){
list.next = list1;
break;
}
while(list2 != null){
list.next = list2;
break;
}
return cur.next;
}
}
1.1.4 分隔链表
给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。
你应当 保留 两个分区中每个节点的初始相对位置。
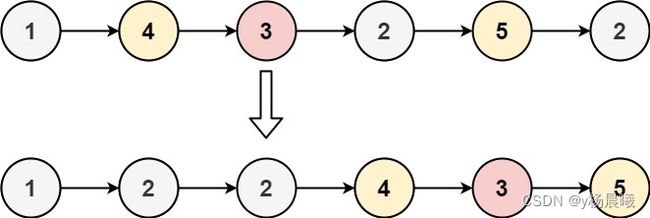
思路:
- 将这个链表分为大表和小表,分别存放大于和小于标志值的数。
- 这里我使用small表示小表的头结点,big表示大表的头结点。并且用两个指针指向头节点(头节点不移动)small 和 big 移动
- 注意:大表的最后一个节点要设置成为null,因为p复用的是原表的节点,可能指向其他的节点了,导致整个表是一个循环的表。
class Solution {
public ListNode partition(ListNode head, int x) {
ListNode big = new ListNode();
ListNode small = new ListNode();
ListNode ans = small;
ListNode cur = big;
while(head != null){
if(head.val < x){
small.next = head;
small = small.next;
}else{
big.next = head;
big = big.next;
}
head = head.next;
}
big.next = null;
small.next = cur.next;
return ans.next;
}
}
1.1.5 环形链表
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos
来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。如果链表中存在环 ,则返回 true 。 否则,返回 false 。

思路:
- 使用hashset来判断是否有重复出现的数字,有的话那一定就出现了环。
- 使用快慢指针:一个指针一次走一步,一个指针一次走两步,如果出现环的话,那么这两个指针是一定能相遇的。
代码:
hashset:
public class Solution {
public boolean hasCycle(ListNode head) {
ListNode node = head;
Set<ListNode> set = new HashSet<>();
while(node != null){
if(set.contains(node) == false){
set.add(node);
}else{
return true;
}
node = node.next;
}
return false;
}
}
快慢指针:
public class Solution {
public boolean hasCycle(ListNode head) {
if(head == null || head.next == null){
return false;
}
ListNode fast = head;
ListNode slow = head;
//快慢指针要注意跳出循环的条件
while(fast != null && fast.next != null){
fast = fast.next.next;
slow = slow.next;
if(fast == slow){
return true;
}
}
return false;
}
}
1.1.6 环形链表2
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos
来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos
不作为参数进行传递,仅仅是为了标识链表的实际情况。不允许修改 链表。

和上一道题的区别就是这次返回的是节点
思路:
- 使用HashSet
- 快慢指针
HashSet代码
public class Solution {
public ListNode detectCycle(ListNode head) {
ListNode node = head;
Set<ListNode> set = new HashSet<>();
while(node != null){
if(set.contains(node)){
return node;
}else{
set.add(node);
}
node = node.next;
}
return null;
}
}
快慢指针代码
思路:
- 我们设链表长度为a + b :a是进入环形之前的长度,b是环的长度
- 当fast与slow相遇的时候,可以发现fast走的距离是slow的两倍,即f = 2s 而可以观察到f比s多的距离其实就是多走了n个环 f = s + nb 这样就得出了 s = nb。
- 但是这道题求的是环形的第一个节点,而fast和slow可以在环内任意一点相遇,咋怎么办呢。我们考虑到从链表头到这环形的第一个节点的路程是 : a + nb(可以经过n个环),而slow的路程是nb,也就是说,当slow和fast第一次相遇后,s再走a步,就到了环形口了。
- 这个方法比较巧妙,贴个链接环形链表快慢指针
public class Solution {
public ListNode detectCycle(ListNode head) {
ListNode fast = head;
ListNode slow = head;
while(true){
if(fast == null || fast.next == null){
return null;
}
fast = fast.next.next;
slow = slow.next;
if(fast == slow){
break;
}
}
fast = head;
while(slow != fast){
fast = fast.next;
slow = slow.next;
}
return fast;
}
}
1.1.7 反转链表2
给你单链表的头指针 head 和两个整数 left 和 right ,其中 left <= right 。请你反转从位置 left 到位置 right 的链表节点,返回 反转后的链表 。

思路:
- 因为这道题不是反转整个链表,所以要把 需要反转的那个部分截取出来。所以先用两个循环截取出需要的部分。之后对截取出来的部分进行反转
注意的点:
- 截取时的两个节点的next需要为null,因为原链表的节点是有顺序的,会造成循环
- 最后的拼接注意顺序。
代码:
class Solution {
public ListNode reverseBetween(ListNode head, int left, int right) {
ListNode fakehead = new ListNode();
fakehead.next = head;
ListNode pre = fakehead;
//先找到左边的节点
for(int i = 0;i<left-1;i++){
pre = pre.next;
}
ListNode rightNode = pre;
for(int i = 0;i<right-left+1;i++){
rightNode = rightNode.next;
}
//找出出要反转的子链表
ListNode leftNode = pre.next;
//记录位置
ListNode currNode = rightNode.next;
//防止循环,进行切割
pre.next = null;
rightNode.next = null;
ListNode pre1 = null;
ListNode curr1 = leftNode;
//for(int i = 0;i
while(curr1 != null){
ListNode next = new ListNode();
next = curr1.next;
curr1.next = pre1;
pre1 = curr1;
curr1 = next;
}
pre.next = rightNode;
leftNode.next = currNode;
return fakehead.next;
}
}
1.1.8 复制带随机指针的链表
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和
random
指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有
x.random --> y 。返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示 Node.val 的整数。 random_index:随机指针指向的节点索引(范围从 0 到
n-1);如果不指向任何节点,则为 null 。 你的代码 只 接受原链表的头节点 head 作为传入参数。
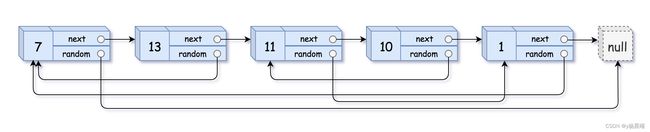
思路:
- 注意题意,每个节点有一个next域和random域。而本题中因为随机指针的存在,当我们拷贝节点时,「当前节点的随机指针指向的节点」可能还没创建。
- 所以使用map进行存储。首先遍历原链表,每遍历到一个节点,都新建一个相同val的节点。后来进行第二次遍历,这时候给对应的节点的next 和 random 进行赋值(复制链表中的指针都不应指向原链表中的节点 。)
- 这个思路确实巧妙
代码:
class Solution {
Map<Node,Node> map = new HashMap<>();
public Node copyRandomList(Node head) {
Node node = head;
//先把每遍历到一个节点,都新建一个相同val的节点
while(node != null){
map.put(node,new Node(node.val));
node = node.next;
}
node = head;
//给对应的节点的next 和 random 进行赋值
while(node != null){
map.get(node).next = map.get(node.next);
map.get(node).random = map.get(node.random);
node = node.next;
}
return map.get(head);
}
}
1.1.9 奇偶链表
给定单链表的头节点 head ,将所有索引为奇数的节点和索引为偶数的节点分别组合在一起,然后返回重新排序的列表。
第一个节点的索引被认为是 奇数 , 第二个节点的索引为 偶数 ,以此类推。
请注意,偶数组和奇数组内部的相对顺序应该与输入时保持一致。
你必须在 O(1) 的额外空间复杂度和 O(n) 的时间复杂度下解决这个问题。

思路:
- 之前第一遍写的太复杂了有好多判断。改用了新的方法:因为链表是奇数偶数交替的,所以将整个链表分开,分成一个奇一个偶,然后再进行合并就行了。
- 难点就在于怎么把这些奇或者偶找出来。
代码:
class Solution {
public ListNode oddEvenList(ListNode head) {
//先进行特殊值判断
if(head == null || head.next == null){
return head;
}
//head表示奇数的头节点 evenhead表示偶数节点的头节点
ListNode evenHead = head.next;
//使用两个指针,odd表示奇数指针,even表示偶数指针
ListNode odd = head;
ListNode even = evenHead;
while(even != null && even.next!= null){
odd.next = even.next;
odd = odd.next;
even.next = odd.next;
even = even.next;
}
//把两个链表链接起来
odd.next = evenHead;
return head;
}
}
2.回溯
回溯法思路的简单描述是:把问题的解空间转化成了图或者树的结构表示,然后使用深度优先搜索策略进行遍历,遍历的过程中记录和寻找所有可行解或者最优解。
- 回溯法按深度优先策略搜索问题的解空间树。首先从根节点出发搜索解空间树,当算法搜索至解空间树的某一节点时,先利用剪枝函数判断该节点是否可行(即能得到问题的解)。如果不可行,则跳过对该节点为根的子树的搜索,逐层向其祖先节点回溯;否则,进入该子树,继续按深度优先策略搜索。
- 回溯法的基本行为是搜索,搜索过程使用剪枝函数来为了避免无效的搜索。剪枝函数包括两类:1. 使用约束函数,剪去不满足约束条件的路径;2.使用限界函数,剪去不能得到最优解的路径。
- 问题的关键在于如何定义问题的解空间,转化成树(即解空间树)。解空间树分为两种:子集树和排列树。两种在算法结构和思路上大体相同
与深度优先遍历的思想很接近
有时候回溯比较难以想到,所以做题比较费劲,我挑几个比较典型的例题。
2.1 组合总和
给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数
target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。
对于给定的输入,保证和为 target 的不同组合数少于 150 个。
思路:这就是一个非常经典的组合问题,我们可以使用搜索回溯的方式来进行解答:
即对每一个数字进行 选/不选的判断

代码:
class Solution {
List<List<Integer>> ans = new ArrayList<List<Integer>>();
List<Integer> t = new ArrayList<>();
public List<List<Integer>> combinationSum(int[] candidates, int target) {
dfs(candidates,target,0);
return ans;
}
// 选或者不选index的值,这一步是需要脑子的剪枝操作
public void dfs(int[] nums,int target,int index){
if(index == nums.length){
return;
}
if(target == 0){
ans.add(new ArrayList<>(t));
return;
}
//跳过当前数字
dfs(nums, target, index+1);
//选择当前数字
if(target - nums[index] >= 0){
t.add(nums[index]);
dfs(nums, target-nums[index], index);
t.remove(t.size()-1);
}
}
}
2.1 组合总和2
给定一个候选人编号的集合 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target
的组合。candidates 中的每个数字在每个组合中只能使用 一次 。
注意:解集不能包含重复的组合。
变化是每个数字只能使用一次,使用递归 + 回溯的方法
思路:
- 因为题目描述中规定了解集不能包含重复的组合,我们可以考虑将相同的数放在一起进行处理。即我们先将数组进行排序,这样相同大小的数字就在一起了。
代码:
class Solution {
List<List<Integer>> ans = new ArrayList<List<Integer>>();
List<Integer> t = new ArrayList<>();
public List<List<Integer>> combinationSum2(int[] candidates, int target) {
Arrays.sort(candidates);
backtrack(candidates,target,0,0);
return ans;
}
private void backtrack(int[] candidates,int target,int sum,int begin) {
if(sum == target) {
ans.add(new ArrayList<>(t));
return;
}
for(int i = begin;i < candidates.length;i++) {
if(i > begin && candidates[i] == candidates[i-1]) continue;
int rs = candidates[i] + sum;
if(rs <= target) {
t.add(candidates[i]);
backtrack(candidates,target,rs,i+1);
t.remove(t.size()-1);
} else {
break;
}
}
}
}
2.3 全排列
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
思路:
- 题目中说了不包含重复数字的数组,所以可以不考虑数字重复的事情。
- 同样的,每一个数字只能用一遍,使用map或者set进行数字存储,确保不会多次使用。
- 和组合总和2一样的,这样的题目还是得用for循环,也就是每个数字按顺序进循环,循环里面再继续调用回溯。
代码:
class Solution {
List<List<Integer>> ans = new ArrayList<List<Integer>>();
List<Integer> t = new ArrayList<>();
HashMap<Integer,Integer> map = new HashMap();
Set<Integer> set = new HashSet();
public List<List<Integer>> permute(int[] nums) {
dfs(nums);
return ans;
}
public void dfs(int[] nums){
if(t.size() == nums.length){
ans.add(new ArrayList<>(t));
return;
}
for(int i = 0;i<nums.length;i++){
if(!set.contains(nums[i])){
set.add(nums[i]);
t.add(nums[i]);
System.out.println("当前t的状态: " + t.toString() + "当前i的值: " + i);
dfs(nums);
System.out.println("删除了 :" + nums[t.size()-1]);
t.remove(t.size()-1);
set.remove(nums[i]);
}
}
}
}
2.4 全排列2
给定一个可包含重复数字的序列 nums ,按任意顺序 返回所有不重复的全排列。
输入:
nums = [1,1,2]
输出:
[[1,1,2],
[1,2,1],
[2,1,1]]
思路:
- 我们选择对原数组排序,保证相同的数字都相邻,然后每次填入的数一定是这个数所在重复数集合中「从左往右第一个未被填过的数字」
- for循环保证了从数组中从前往后一个一个取值,再用if判断条件。
所以nums[i - 1]一定比nums[i]先被取值和判断。
如果nums[i - 1]被取值了,那vis[i - 1]会被置1,只有当递归再回退到这一层时再将它置0。
每递归一层都是在寻找数组对应于递归深度位置的值,每一层里用for循环来寻找。
所以当vis[i - 1] = 1时,说明nums[i - 1]和nums[i]分别属于两层递归中,
也就是我们要用这两个数分别放在数组的两个位置,这时不需要去重。
但是当vis[i - 1] = 0时,说明nums[i - 1]和nums[i]属于同一层递归中(只是for循环进入下一层循环),
也就是我们要用这两个数放在数组中的同一个位置上,这就是我们要去重的情况。
class Solution {
List<List<Integer>> ans = new ArrayList<List<Integer>>();
List<Integer> t = new ArrayList<>();
boolean[] flag;
public List<List<Integer>> permuteUnique(int[] nums) {
flag = new boolean[nums.length];
Arrays.sort(nums);
backtrack(nums,0);
return ans;
}
public void backtrack(int[] nums,int cur){
if(cur== nums.length){
ans.add(new ArrayList<>(t));
return;
}
for(int i = 0;i<nums.length;i++){
//continue:跳过当前循环继续下一个循环。
if(flag[i] || i > 0 && nums[i] == nums[i-1] && !flag[i-1]){
continue;
}
t.add(nums[i]);
flag[i] = true;
backtrack(nums,cur+1);
flag[i] = false;
t.remove(cur);
}
}
}
3. 树
树还是比较简单的(相比于回溯来说)
3.1 树的三种遍历
前序遍历:根 — 左 — 右
class Solution {
List<Integer> ans = new ArrayList<>();
public List<Integer> preorderTraversal(TreeNode root) {
PreOrder(root);
return ans;
}
public void PreOrder(TreeNode root){
if(root == null){
return;
}
ans.add(root.val);
PreOrder(root.left);
PreOrder(root.right);
}
}
中序遍历:左 — 中 — 右
class Solution {
List<Integer> ans = new ArrayList<>();
public List<Integer> inorderTraversal(TreeNode root) {
InOrder(root);
return ans;
}
public void InOrder(TreeNode node){
if(node == null){
return;
}
InOrder(node.left);
ans.add(node.val);
InOrder(node.right);
}
}
后序遍历 左— 右— 中
class Solution {
List<Integer> ans = new ArrayList<>();
public List<Integer> postorderTraversal(TreeNode root) {
PreOrder(root);
return ans;
}
public void PreOrder(TreeNode root){
if(root == null){
return;
}
PreOrder(root.left);
PreOrder(root.right);
ans.add(root.val);
}
}
3.2 二叉树的层次遍历
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
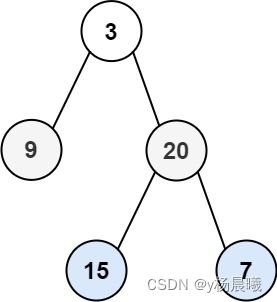
思路:
- 层次遍历的思路比较巧妙,从根节点开始,每一层的节点我们放在容器中,然后遍历容器,取一个扔一个,把这个取出来的节点的子节点再加到容器中,知道最后一层。
- 所以我们用队列可以存储节点。
- 这其实也就是广度优先的一种实现方法
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> ans = new ArrayList<>();
if(root == null){
return ans;
}
//使用队列Queue进行存储
Queue<TreeNode> queue = new LinkedList<TreeNode>();
queue.add(root);
//判出条件是队列不为空
while(!queue.isEmpty()){
//这里的list是存储每一层的节点的。
List<Integer> list = new ArrayList<>();
//这里为什么要有len呢,因为queue的size是动态变化的,for循环里面还在不断添加节点,所以不准确。
int len = queue.size();
//这里就是取出来queue中的节点放到list中,然后把这个节点的子节点再加到队列中去
//当循环完了的时候就进入了下一层的遍历了。
for(int i = 0;i<len;i++){
TreeNode node = queue.poll();
list.add(node.val);
if(node.left != null){
queue.add(node.left);
}
if(node.right != null){
queue.add(node.right);
}
}
ans.add(new ArrayList(list));
}
return ans;
}
}
3.3 二叉树的锯齿形层序遍历
给你二叉树的根节点 root ,返回其节点值的 锯齿形层序遍历 。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。
输入:root = [3,9,20,null,null,15,7]
输出:[[3],[20,9],[15,7]]

难点:
这道题是上一道题的变形,难点在于:
- 题目理解,是每一层遍历的顺序不一样,不是每一次。
- 怎么表示从左到右的顺序不一样。
思路:
- 延续上一题的写法,用队列进行存储与循环。
- 因为每一层的顺序不一样,考虑在list.add()中做手脚(使用头插法来进行逆序的模拟)。每一层在队列中的add保持不变,先左后右,但是在t.add中每隔一层变换一次。
- 如何变换:设置一个标志值count,当count余数是一的时候,这时,插入t的时候使用头插法,这样就形成了逆序。当余数为零的时候就正常插入。在每一次循环做完的时候进行count++就行了。
代码:
class Solution {
public List<List<Integer>> zigzagLevelOrder(TreeNode root) {
List<List<Integer>> ans = new ArrayList<>();
if(root == null){
return ans;
}
Queue<TreeNode> queue = new LinkedList<TreeNode>();
int count = 0;
queue.add(root);
while(!queue.isEmpty()){
List<Integer> t = new ArrayList<>();
int length = queue.size();
/*也就是说,因为偶数排的位置是从右到左,其实不是在偶数排的时候才反方向的加入的,
而是在奇数排的时候加入list的时候就反着加入,在list.add()中做手脚就行。
然后使用count来判断奇偶行
*/
if(count % 2 == 0){
for(int i = 0;i<length;i++){
TreeNode node = queue.poll();
if(node.left != null){
queue.add(node.left);
}
if(node.right != null){
queue.add(node.right);
}
t.add(node.val);
}
}else{
for(int i = 0;i<length;i++){
TreeNode node = queue.poll();
if(node.left != null){
queue.add(node.left);
}
if(node.right != null){
queue.add(node.right);
}
t.add(0,node.val);
}
}
count++;
ans.add(t);
}
return ans;
}
}
3.4 路径总和2
给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点 路径总和等于给定目标和的路径。
输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22
输出:[[5,4,11,2],[5,8,4,5]]

思路:
- 其实这道题不管是深度还是广度优先都能做,我习惯深度。
- 难点其实在于怎么向上回溯的时候实时的保持数据的正确性。
代码:
class Solution {
List<List<Integer>> ans = new ArrayList<>();
List<Integer> t = new ArrayList<>();
int sum = 0;
public List<List<Integer>> pathSum(TreeNode root, int targetSum) {
if(root == null){
return ans;
}
preOrder(root,targetSum);
return ans;
}
public void preOrder(TreeNode root, int target){
if(root == null){
return;
}
sum += root.val;
t.add(root.val);
System.out.println(t);
if(sum == target && root.left == null && root.right == null){
ans.add(new ArrayList<>(t));
//这里注意不能用return
/*
1.为什么在ans.add的时候不能要return呢,因为一旦使用了return,当数组里面是5 4 11 2
的时候满足条件,这时候你直接return了,就没办法继续往下走了,只能返回上一层,
那么就无法执行这一层的sum -= root.val;了,实际上执行的是上一层的sum -= root.val,
从数组删除的t.get(t.size()-1) 是2,但是sum里面删除的值是上一层的11,会造成错误,
更通俗的说就是:每一次t.remove的值要保持和当前root的val相同。所以不能使用return
*/
}
preOrder(root.left,target);
preOrder(root.right,target);
sum -= root.val;
System.out.println("remove : " + t.get(t.size()-1) + "-------" + root.val);
t.remove(t.size()-1);
}
}
3.5 二叉树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
思路:
这道题不能直接遍历找答案的原因是,叶子节点要根据自身的状态去给父亲节点返回信息。即每个父节点都会接收子节点的状态(是否含有p、q)并把这个状态往上传递,直到该结点满足祖先节点的条件。
所以思路如下:
- 存储节点的父子关系(用map),遍历一遍整个树,将每一个子节点设置为key,将其对应的父节点设置为value,这样就成了父子节点的一一对应。
- 创建一个set集合,从p开始向上遍历,包括他自己,每向上一次就把对应的节点存入set,来表示存储的父节点。
- 开始向上遍历q,并且在每向上一次就在set中寻找对应的q节点有没有存储在set里面,如果有,说明这个节点就是深度最大的节点,返回即可,如果没有,则继续向上。
class Solution {
HashMap<TreeNode,TreeNode> parentMap = new HashMap<>();
Set<TreeNode> set = new HashSet<>();
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if (root == null) {
return null;
}
dfs(root);
while (p != null) {
set.add(p);
p = parentMap.get(p);
}
while (q != null) {
if (set.contains(q)) {
return q;
}
q = parentMap.get(q);
}
return null;
}
public void dfs(TreeNode root){
if(root.left != null){
parentMap.put(root.left,root);
dfs(root.left);
}
if(root.right != null){
parentMap.put(root.right,root);
dfs(root.right);
}
}
}
3.6 二叉树的右视图
给定一个二叉树的 根节点 root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。

思路:
- 这道题还是比较有意思的,但是我用了比较笨的方法:就是进行层次遍历,然后每一次都把每一层的最后一个节点取出来就行了。
class Solution {
List<Integer> ans = new ArrayList<>();
Queue<TreeNode> queue = new LinkedList<>();
public List<Integer> rightSideView(TreeNode root) {
if(root == null){
return ans;
}
bfs(root);
return ans;
}
public void bfs(TreeNode root){
queue.add(root);
while (!queue.isEmpty()){
int len = queue.size();
for(int i = 0;i<len;i++){
TreeNode node = queue.poll();
if(node.left != null){
queue.add(node.left);
}
if(node.right != null){
queue.add(node.right);
}
if(i == len-1){
ans.add(node.val);
}
}
}
}
}
3.7 将有序数组转换为二叉搜索树
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 高度平衡 二叉搜索树。
高度平衡 二叉树是一棵满足「每个节点的左右两个子树的高度差的绝对值不超过 1 」的二叉树。
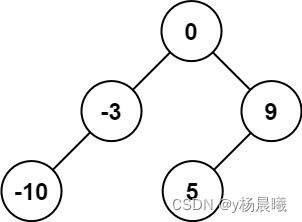
思路:
- 二叉搜索树的中序遍历就是升序序列。而这个数组就是升序的
所以,每一次都选择中间位置左边的那个数字作为根节点,即mid = (start+end)/2
这个节点的右节点的取值就是(mid+1+end)/2
这个节点的左节点的取值就是(start+mid-1)/2
进行递归就好了。
代码:
class Solution {
public TreeNode sortedArrayToBST(int[] nums) {
return bulidTree(0,nums.length-1,nums);
}
public TreeNode bulidTree(int start, int end,int[] nums){
if(start > end){
return null;
}
int mid = start + (end - start >> 1);
TreeNode node = new TreeNode();
node.val = nums[mid];
node.right = bulidTree(mid+1,end,nums);
node.left = bulidTree(start,mid-1,nums);
return node;
}
}
3.8 删除二叉搜索树中的节点
给定一个二叉搜索树的根节点 root 和一个值 key,删除二叉搜索树中的 key 对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用。
一般来说,删除节点可分为两个步骤:
首先找到需要删除的节点;
如果找到了,删除它。

思路:
- 因为要求返回的是二叉搜索树,并不是平衡二叉树,所以要求没那么高,没有要求平衡因子
- 同时注意二叉搜索树(bst)的性值:左子树的节点一定比根节点小,右子树的节点一定比根节点大。
难点:
- 怎么在删除后重新构建?还是根据性质。
- 删除的节点如果没有左/右子树,则返回有的那个子树.
- 如果都有的话,左子树的节点肯定比右子树的所有节点小,放在右子树的最左边的节点(最小的节点)的左子树上就行了。
class Solution {
public TreeNode deleteNode(TreeNode root, int key) {
if(root == null){
return null;
}
if(root.val > key){
root.left = deleteNode(root.left,key);
}else if(root.val <key){
root.right = deleteNode(root.right,key);
}else{
if(root.left == null){
return root.right;
}
if (root.right == null){
return root.left;
}
TreeNode node = root.right;
while (node.left != null){
node = node.left;
}
node.left = root.left;
root = root.right;
}
return root;
}
}
3.9 路径总和 III
给定一个二叉树的根节点 root ,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。
路径 不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
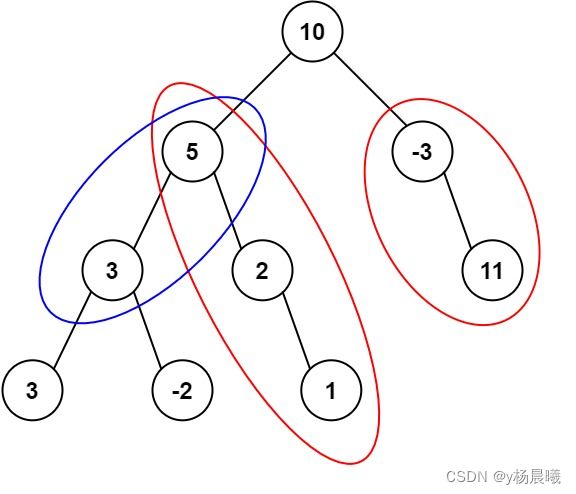
思路:
- 路径方向必须是向下的(只能从父节点到子节点)。
- 我用了偷懒的方法,先记录每一个节点,然后从每个节点开始遍历。
- 为什么用了大数?因为突然出现了大数的用例,也没办法。
代码:
class Solution {
int count = 0;
List<TreeNode> list = new ArrayList<>();
public int pathSum(TreeNode root, int targetSum) {
if(targetSum == 1000){
return 0;
}
preOrder(root,targetSum,new BigInteger(String.valueOf(0)));
count = 0;
int size = list.size();
for(int i = 0;i<size;i++){
System.out.println("-------------------------------");
preOrder(list.get(i),targetSum,new BigInteger(String.valueOf(0)));
}
return count;
}
public void preOrder (TreeNode root ,int target, BigInteger sum){
if (root == null) {
return;
}
list.add(root);
sum = sum.add(BigInteger.valueOf(root.val));
System.out.println("sum : " + sum);
if (sum.equals(BigInteger.valueOf(target))) {
count++;
}
preOrder(root.left, target, sum);
preOrder(root.right, target, sum);
sum = sum.subtract(BigInteger.valueOf(root.val));
}
}
3.10 平衡二叉树
给定一个二叉树,判断它是否是高度平衡的二叉树。
代码
class Solution {
public boolean isBalanced(TreeNode root) {
if (root == null) {
return true;
} else {
return Math.abs(height(root.left) - height(root.right)) <= 1 && isBalanced(root.left) && isBalanced(root.right);
}
}
public int height(TreeNode root) {
if (root == null) {
return 0;
} else {
return Math.max(height(root.left), height(root.right)) + 1;
}
}
}
3.11 二叉树的最小深度
给定一个二叉树,找出其最小深度。
最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
说明:叶子节点是指没有子节点的节点。

思路:
- 递归
- 当一个节点只有左子树或者只有右子树的时候,这时候没得选,最小深度就是子树的深度+1(算上他自己)
- 当左右子树都存在的时候这个节点的深度就是这两个子树的深度最小值加一(算上他自己)
代码:
class Solution {
public int minDepth(TreeNode root) {
if(root == null){
return 0;
}
int left = minDepth(root.left);
int right = minDepth(root.right);
if(root.left == null || root.right == null){
return Math.max(left,right)+1;
}
return Math.min(left,right)+1;
}
}
3.12 左叶子之和
给定二叉树的根节点 root ,返回所有左叶子之和。

思路:
- 首先注意,题目要求的是左叶子,不是左视图。
- 什么是叶子节点,就是除了根节点之外的,没有左孩子和有孩子的节点就是叶子节点。那么左叶子就是上一个节点的左孩子并且是叶子的节点。
- 怎么判断出是左子树不是右子树呢,其实在传参的时候加入一个参数,左子树的true右子树的false就行了。
代码:
class Solution {
int ans = 0;
public int sumOfLeftLeaves(TreeNode root) {
if(root.left == null && root.right == null){
return 0;
}
return root != null ? order(root,true):0;
}
public int order(TreeNode root,boolean flag){
if(root == null){
return 0;
}
order(root.left,true);
if(root.left == null && root.right == null ){
if(flag == true)
ans += root.val;
System.out.println(ans);
}
order(root.right,false);
return ans;
}
}
3.13 二叉搜索树的最小绝对差
给你一个二叉搜索树的根节点 root ,返回 树中任意两不同节点值之间的最小差值 。
差值是一个正数,其数值等于两值之差的绝对值。
输入:root = [4,2,6,1,3]
输出:1

思路:
- 不能暴力解决,得想办法捏:首先,这是一个二叉搜索树,所以想到性质:二叉搜索树的中序遍历得到的序列是递增的,所以最小的差值肯定是递增序列相邻的两个数字之间的
- 所以使用一个值ans记录最小值,刚开始是int ans = Integer.MAX_VALUE;,使用一个值flag,用flag来当参数,传递每一个节点的val值,作用就是与下一个节点计算差值。
代码:
class Solution {
int ans = Integer.MAX_VALUE;
int flag = -1;
public int getMinimumDifference(TreeNode root) {
if(root == null){
return 0;
}
dfs(root);
return ans;
}
public void dfs(TreeNode root){
if(root == null){
return;
}
dfs(root.left);
if(flag == -1){
flag = root.val;
}else{
ans = Math.min(ans,root.val-flag);
flag = root.val;
}
dfs(root.right);
}
}
4 动态规划
亚雷吗没保存还得再写一遍
先不写了,考完再写。
4.1 最长公共子序列LCS
给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
例如,“ace” 是 “abcde” 的子序列,但 “aec” 不是 “abcde” 的子序列。
两个字符串的 公共子序列 是这两个字符串所共同拥有的子序列。
输入:text1 = “abcde”, text2 = “ace”
输出:3
解释:最长公共子序列是 “ace” ,它的长度为 3 。
思路:
典型的动态规划问题:两个text的最长公共子序列
- 边界值分析:首先确定,当第一个text的长度为0,或者第二个子序列的长度为0时,这时候公共子序列的长度是为0的。
- 建立二维数组dp[][] 将dp[0][j] 与 dp [i][0]设置为0
- 分析,因为dp[0][0]的值为0 ,所以两次循环从0开始。当text1[i-1] == text2[j-1]的时候 dp[i][j]就加一。分析一个,这时候,因为是从text1开始循环的,有可能text2后面也有字符与text1[i]是相同的并且公共子序列更长,所以是往后继续找的。
- 当不一样的时候,就找dp[i-1][j],dp[i][j-1]中最大的(只要有一个text往后面退一个就行了。
代码:
class Solution {
public int longestCommonSubsequence(String text1, String text2) {
int n = text1.length();
int m = text2.length();
int [][] dp = new int[n+1][m+1];
for(int i = 1;i<=n;i++){
for(int j = 1;j<=m;j++){
if(text1.charAt(i-1) == text2.charAt(j-1)){
dp[i][j] = dp[i-1][j-1] + 1;
}
else{
dp[i][j] =Math.max(dp[i-1][j],dp[i][j-1]);
}
}
}
return dp[n][m];
}
}
4.2 最长回文子序列
给你一个字符串 s ,找出其中最长的回文子序列,并返回该序列的长度。
子序列定义为:不改变剩余字符顺序的情况下,删除某些字符或者不删除任何字符形成的一个序列。
妙招:字符串反转后进行最长公共子序列的判断。
代码:
class Solution {
public int longestPalindromeSubseq(String s) {
int n = s.length();
int[][] dp = new int[n+1][n+1];
String s1 = new String();
for(int i = n-1;i>=0;i--){
s1 +=s.charAt(i);
}
for(int i = 1;i<=n;i++){
for(int j = 1;j<=n;j++){
if(s.charAt(i-1) == s1.charAt(j-1)){
dp[i][j] = dp[i-1][j-1] + 1;
}else{
dp[i][j] = Math.max(dp[i-1][j],dp[i][j-1]);
}
}
}
return dp[n][n];
}
}
4.3 最长回文子串
给你一个字符串 s,找到 s 中最长的回文子串。
这个问题转换为最长公共子序列(LCS) 问题来求解:把字符串S倒过来变成字符串T,然后对S和T进行LCS模型求解,得到的结果就是需要的答案。而事实上这种做法是错误的,因为一旦S中同时存在一个子串和它的倒序,那么答案就会出错。例如字符串S= “ABCDZJUDCBA”,将其倒过来之后会变成T = “ABCDUJZDCBA”,这样得到最长公共子串为"ABCD",长度为4,而事实上S的最长回文子串长度为1。因此这样的做法是不行的。
思路:
- 因为是回文,所以用中心扩散法。
- 把字符串的每一个位置都当作中心试一遍,然后找出最长的长度的子串就行了。
- 注意长度的选取和子串的截取就行了
代码:
class Solution {
public String longestPalindrome(String s) {
int n = s.length();
if(n<2){
return s;
}
if(n == 2 && s.charAt(0) != s.charAt(1)){
return s.substring(0,1);
}
int start = 0;
int end = 0;
for(int i = 0;i<n;i++){
int len1 = fun(s,i,i);
int len2 = fun(s,i,i+1);
int len = Math.max(len1,len2);
if(len > end-start){
//计算子串的起始位置,结束位置
start = i - (len - 1) / 2;
end = i + len / 2;
}
}
//从beginIndex开始取,到endIndex结束,从0开始数,其中不包括endIndex位置的字符
return s.substring(start,end+1);
}
private int fun(String s,int left,int right){
while(right < s.length() && left >= 0 && s.charAt(left) == s.charAt(right)){
left--;
right++;
}
//在这里 left和right表示的是两个位置,在这两个指针之间的串是回文子串,不包括他俩指向的位置
//所以长度应该为right-left+1-2
return right-left-1;
}
}
4.4 最长递增序列
给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。
子序列 是由数组派生而来的序列,删除(或不删除)数组中的元素而不改变其余元素的顺序。例如,[3,6,2,7] 是数组 [0,3,1,6,2,2,7] 的子序列。
思路:
- 先将dp数组都设置为1
- 使用两个循环,第一个循环i代表当前的位置
第二个循环j代表在i之前的所有元素。 - 当i指向的数组值大于j时,就为dp[i]进行赋值,Math.max(dp[i],dp[j]+1);
- 因为是从0开始的,每一个位置都存储的是最大的值,当后面的值更大的时候就会加一,所以保证了正确性。
代码:
class Solution {
public int lengthOfLIS(int[] nums) {
int[] dp = new int[nums.length];
Arrays.fill(dp,1);
for(int i = 0;i<nums.length;i++){
for(int j = 0;j<i;j++){
if(nums[i] > nums[j]){
dp[i] = Math.max(dp[i],dp[j]+1);
}
}
}
Arrays.sort(dp);
return dp[nums.length-1];
}
}
4.5 最长连续递增序列
给定一个未经排序的整数数组,找到最长且 连续递增的子序列,并返回该序列的长度。
连续递增的子序列 可以由两个下标 l 和 r(l < r)确定,如果对于每个 l <= i < r,都有 nums[i] < nums[i + 1] ,那么子序列 [nums[l], nums[l + 1], …, nums[r - 1], nums[r]] 就是连续递增子序列。
i
思路:
- 和上一题差不多,只是这道题要求的是连续递增
- 当i指向的数组值大于j时,就为dp[i]进行赋值 = dp[j] +1,注意当i小于j 的时候就说明不连续了,这时候dp[i]就要重新赋值为1
代码:
class Solution {
public int findLengthOfLCIS(int[] nums) {
int[] dp = new int[nums.length];
Arrays.fill(dp,1);
for(int i = 0;i<nums.length;i++){
for(int j = 0;j<i;j++){
if(nums[i] > nums[j]){
dp[i] = dp[j]+1;
}else{
dp[i] = 1;
}
}
}
Arrays.sort(dp);
return dp[nums.length-1];
}
}
4.6 最长重复子数组
给两个整数数组 nums1 和 nums2 ,返回 两个数组中 公共的 、长度最长的子数组的长度 。
思路:
- 当nums[i-1] = nums[j-1]的时候说明有一个相同的字串,这时候
dp[i][j] = dp[i-1][j-1] + 1; - 再因为这里是nums1[i-1] == nums2[j-1],所以循环的范围是i<=n;j<=m。
- 当不相等的时候,设置dp为0;
- 循环dp数组,找出最大的值,即为最长重复子数组的长度。
代码:
class Solution {
public int findLength(int[] nums1, int[] nums2) {
int n = nums1.length;
int m = nums2.length;
int[][] dp = new int[n+1][m+1];
int max = 0;
for(int i = 1;i<=n;i++){
for(int j = 1;j<=m;j++){
//因为这里是nums1[i-1] == nums2[j-1],所以判断的范围是i<=n;j<=m
if(nums1[i-1] == nums2[j-1]){
dp[i][j] = dp[i-1][j-1] + 1;
}
else{
dp[i][j] = 0;
}
max = Math.max(max,dp[i][j]);
}
}
return max;
}
}