使用 Amazon SageMaker 微调和部署 ChatGLM 模型

本篇文章主要介绍如何使用 Amazon SageMaker 进行 ChatGLM 模型部署和微调的示例。
这个示例主要包括:
ChatGLM 总体介绍
ChatGLM 微调介绍
ChatGLM 环境设置
ChatGLM 微调训练
ChatGLM 部署测试
前言
大语言模型是一种基于深度学习技术的人工智能模型,可以追溯到早期的语言模型和机器翻译系统。直到最近,随着深度学习技术的崛起,大型预训练语言模型才开始引起广泛的关注。
大语言模型使用大规模的文本数据集进行预训练,从而学习到丰富的语言知识和语境理解能力。通过预训练和微调的方式,大语言模型可以用于各种自然语言处理任务,例如文本生成、机器翻译、问答系统、对话系统等。它们在许多领域都展示出了令人印象深刻的性能,并成为推动人工智能技术发展的重要驱动力。
ChatGLM 总体介绍
ChatGLM 模型是由清华大学开源的、支持中英双语问答的对话语言模型,并针对中文进行了优化。该模型基于 General Language Model(GLM)架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署。
ChatGLM 具备以下特点:
充分的中英双语预训练:ChatGLM 在 1:1 比例的中英语料上训练了 1T 的 token 量,兼具双语能力。
优化的模型架构和大小:修正了二维 RoPE 位置编码实现。6B(62 亿)的参数大小,也使得研究者和个人开发者自己微调和部署 ChatGLM 成为可能。
较低的部署门槛:FP16 半精度下,ChatGLM 需要至少 13 GB 的显存进行推理,结合模型量化技术,这一需求可以进一步降低到 10GB(INT8) 和 6GB(INT4),使得 ChatGLM 可以部署在消费级显卡上。
更长的序列长度:ChatGLM 序列长度达 2048,支持更长对话和应用。
ChatGLM 微调介绍
模型微调主要分为 Full Fine-Tune 和 PEFT (Performance-Efficient Fine-Tune),前者模型全部参数都会进行更新,训练时间较长,训练资源较大;而后者会冻结大部分参数、微调训练网络结构,常见的方式是 LoRA 和 P-Tuning v2。对于 ChatGLM 来说,选择 P-Tuning v2 进行模型微调,其网络结构如下:在Transformers 的所有层均增加 Prompt/Prefix。

ChatGLM 环境设置
备注:项目中的示例代码均保存于代码仓库,地址如下:
https://github.com/GlockGao/aws-sagemaker-llm
1. 升级 Python SDK
pip install --upgrade boto3
pip install --upgrade sagemaker
pip install huggingface_hub2. 获取运行时资源,包括区域、角色、账号、S3 桶等
import boto3
import sagemaker
from sagemaker import get_execution_role
sess = sagemaker.Session()
role = get_execution_role()
sagemaker_default_bucket = sess.default_bucket()
account = sess.boto_session.client("sts").get_caller_identity()["Account"]
region = sess.boto_session.region_name左滑查看更多
ChatGLM 微调训练
准备微调
克隆代码
rm -rf ChatGLM-6B
git clone https://github.com/THUDM/ChatGLM-6B.git
cd ChatGLM-6B
git checkout 163f94e160f08751545e3722730f1832d73b92d1左滑查看更多
下载数据集
此处采用示例的广告数据集。根据输入实现广告语的输出,格式如下:
{
"content": "类型#上衣版型#宽松版型#显瘦图案#线条衣样式#衬衫衣袖型#泡泡袖衣款式#抽绳",
"summary": "这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。"
}
# 下载 ADGEN 数据集
wget -O AdvertiseGen.tar.gz https://cloud.tsinghua.edu.cn/f/b3f119a008264b1cabd1/?dl=1
# 解压数据集
tar -xzvf AdvertiseGen.tar.gz左滑查看更多
下载 ChatGLM 原始模型
from huggingface_hub import snapshot_download
from pathlib import Path
local_cache_path = Path("./model")
local_cache_path.mkdir(exist_ok=True)
model_name = "THUDM/chatglm-6b"
# Only download pytorch checkpoint files
allow_patterns = ["*.json", "*.pt", "*.bin", "*.model", "*.py"]
model_download_path = snapshot_download(
repo_id=model_name,
cache_dir=local_cache_path,
allow_patterns=allow_patterns,
)
# Get the model files path
import os
from glob import glob
local_model_path = None
paths = os.walk(r'./model')
for root, dirs, files in paths:
for file in files:
if file == 'config.json':
# print(os.path.join(root, file))
local_model_path = str(os.path.join(root, file))[0:-11]
print(local_model_path)
if local_model_path == None:
print("Model download may failed, please check prior step!")左滑查看更多
拷贝模型和数据到 S3
chmod +x ./s5cmd
./s5cmd sync ${local_model_path} s3://${sagemaker_default_bucket}/llm/models/chatglm/original-6B/
./s5cmd sync ./AdvertiseGen/ s3://${sagemaker_default_bucket}/llm/datasets/chatglm/AdvertiseGen/
rm -rf model
rm -rf AdvertiseGen
rm -rf AdvertiseGen.tar.gz左滑查看更多
模型微调
模型的微调使用 P-Tuning v2,以实现成本和效果的平衡。
模型微调更改的源代码较多,具体可以参考上述 git 仓库。
模型微调参数
模型微调设置的关键参数如下:
前缀词长度:128
学习率:2e-2,确保 loss 在训练过程中下降
batch size:1
gradient accumulation step:16
训练步长:50,步长仅设置为 50 步,已经可以看出比较明显的微调结果
import time
from sagemaker.huggingface import HuggingFace
PRE_SEQ_LEN=128
LR=2e-2
BATCH_SIZE=1
GRADIENT_ACCUMULATION_STEPS=16
TRAIN_STEPS=50
job_name = f'huggingface-chatglm-finetune-ptuning-{time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime())}'
instance_type = "ml.g4dn.2xlarge"
instance_count = 1
# 基础模型存放地址
model_name_or_path = 's3://{}/llm/models/chatglm/original-6B/'.format(sagemaker_default_bucket)
# 微调模型输出地址
output_dir = '/opt/ml/model/adgen-chatglm-6b-ft'
model_s3_path = 's3://{}/llm/models/chatglm/finetune-ptuning-adgen/'.format(sagemaker_default_bucket)
# 模型环境变量设置
environment = {
'PYTORCH_CUDA_ALLOC_CONF': 'max_split_size_mb:32',
'TRAIN_DATASET' : '/opt/ml/input/data/AdvertiseGen/train.json',
'TEST_DATASET' : '/opt/ml/input/data/AdvertiseGen/dev.json',
'PROMPT_COLUMN' : 'content',
'RESPONSE_COLUMN' : 'summary',
'MODEL_NAME_OR_PATH' : model_name_or_path,
'OUTPUT_DIR' : output_dir,
'MODEL_OUTPUT_S3_PATH' : model_s3_path,
'TRAIN_STEPS' : '50'
}
inputs = {
'AdvertiseGen': f"s3://{sagemaker_default_bucket}/llm/datasets/chatglm/AdvertiseGen/"
}左滑查看更多
开启模型微调
huggingface_estimator = HuggingFace(
entry_point = 'sm_ptune_train.py',
source_dir = './ChatGLM-6B/ptuning',
instance_type = instance_type,
instance_count = instance_count,
base_job_name = job_name,
role = role,
script_mode = True,
transformers_version = '4.26',
pytorch_version = '1.13',
py_version = 'py39',
environment = environment
)
huggingface_estimator.fit(inputs=inputs)左滑查看更多
ChatGLM 部署测试
模型部署
1. 准备 Dummy 模型
!touch dummy
!tar czvf model.tar.gz dummy
assets_dir = 's3://{0}/{1}/assets/'.format(sagemaker_default_bucket, 'chatglm')
model_data = 's3://{0}/{1}/assets/model.tar.gz'.format(sagemaker_default_bucket, 'chatglm')
!aws s3 cp model.tar.gz $assets_dir
!rm -f dummy model.tar.gz左滑查看更多
2. 配置模型参数
from sagemaker.pytorch.model import PyTorchModel
model_name = None
entry_point = 'chatglm-inference-finetune.py'
framework_version = '1.13.1'
py_version = 'py39'
base_model_name_or_path = 's3://{}/llm/models/chatglm/original-6B/'.format(sagemaker_default_bucket)
finetune_model_name_or_path = 's3://{}/llm/models/chatglm/finetune-ptuning-adgen/adgen-chatglm-6b-ft/checkpoint-50/pytorch_model.bin'.format(sagemaker_default_bucket)
# 模型环境变量设置
model_environment = {
'SAGEMAKER_MODEL_SERVER_TIMEOUT': '600',
'SAGEMAKER_MODEL_SERVER_WORKERS': '1',
'MODEL_NAME_OR_PATH' : base_model_name_or_path,
'PRE_SEQ_LEN' : '128',
'FINETUNE_MODEL_NAME_OR_PATH' : finetune_model_name_or_path,
}
model = PyTorchModel(
name = model_name,
model_data = model_data,
entry_point = entry_point,
source_dir = './code',
role = role,
framework_version = framework_version,
py_version = py_version,
env = model_environment
)左滑查看更多
3. 部署微调模型
from sagemaker.serializers import JSONSerializer
from sagemaker.deserializers import JSONDeserializer
endpoint_name = None
instance_type = 'ml.g4dn.2xlarge'
instance_count = 1
predictor = model.deploy(
endpoint_name = endpoint_name,
instance_type = instance_type,
initial_instance_count = instance_count,
serializer = JSONSerializer(),
deserializer = JSONDeserializer()
)左滑查看更多
4. 其中关键的模型加载代码如下:加载原始的 ChatGLM 模型、同时加载 FineTune 的 PrefixEncoder 参数共同进行推理
import torch
import os
from transformers import AutoConfig, AutoModel, AutoTokenizer
# 载入Tokenizer
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
# 如果需要加载的是新 Checkpoint(只包含 PrefixEncoder 参数):
config = AutoConfig.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True, pre_seq_len=128)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", config=config, trust_remote_code=True)
prefix_state_dict = torch.load(os.path.join(CHECKPOINT_PATH, "pytorch_model.bin"))
new_prefix_state_dict = {}
for k, v in prefix_state_dict.items():
if k.startswith("transformer.prefix_encoder."):
new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
model = model.quantize(4)
model.half().cuda()左滑查看更多
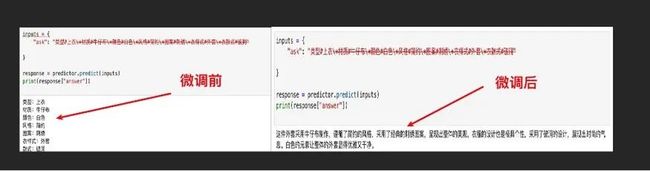
模型微调前后对比
1. 模型测试
inputs = {
"ask": "类型#上衣\*材质#牛仔布\*颜色#白色\*风格#简约\*图案#刺绣\*衣样式#外套\*衣款式#破洞"
}
response = predictor.predict(inputs)
print(response["answer"])左滑查看更多
2. 对比原始 ChatGLM 模型,对于相同的输入,输出更偏广告词,而不是单纯的语义提取
3. 清除资源
predictor.delete_endpoint()总结
大语言模型方兴未艾,正在以各种方式改变和影响着整个世界。客户拥抱大语言模型,亚马逊云科技团队同样在深耕客户需求和大语言模型技术,可以在未来更好地协助客户实现需求、提升业务价值。
本篇作者

高郁
亚马逊云科技解决方案架构师,主要负责企业客户上云,帮助客户进行云架构设计和技术咨询,专注于智能湖仓、AI/ML 等技术方向。

听说,点完下面4个按钮
就不会碰到bug了!
