【Datawhale 科大讯飞-基于论文摘要的文本分类与关键词抽取挑战赛】机器学习方法baseline
内容
科大讯飞AI开发者大赛NLP赛道题目:
基于论文摘要的文本分类与关键词抽取挑战赛
任务:
1.机器通过对论文摘要等信息的理解,判断该论文是否属于医学领域的文献。
2.提取出该论文关键词。
数据集的获取
训练集:
这里读取title、abstract、author、keywords拼接在一起作为text,也就是输入数据。

# 导入pandas用于读取表格数据
import pandas as pd
# 导入BOW(词袋模型),可以选择将CountVectorizer替换为TfidfVectorizer(TF-IDF(词频-逆文档频率)),注意上下文要同时修改,亲测后者效果更佳
from sklearn.feature_extraction.text import CountVectorizer
# 导入LogisticRegression回归模型
from sklearn.linear_model import LogisticRegression
# 过滤警告消息
from warnings import simplefilter
from sklearn.exceptions import ConvergenceWarning
simplefilter("ignore", category=ConvergenceWarning)
# 读取数据集
train = pd.read_csv('/home/aistudio/data/data231041/train.csv')
train['title'] = train['title'].fillna('')
train['abstract'] = train['abstract'].fillna('')
test = pd.read_csv('/home/aistudio/data/data231041/testB.csv')
test['title'] = test['title'].fillna('')
test['abstract'] = test['abstract'].fillna('')
# 提取文本特征,生成训练集与测试集
train['text'] = train['title'].fillna('') + ' ' + train['author'].fillna('') + ' ' + train['abstract'].fillna('')+ ' ' + train['Keywords'].fillna('')
test['text'] = test['title'].fillna('') + ' ' + test['author'].fillna('') + ' ' + test['abstract'].fillna('')
特征工程
这里将对应的文本token转化为vector,方便后面进行计算,这里的CountVectorizer()使用的是BOW模型,所以编码后的维度应该是词表的大小。
vector = CountVectorizer().fit(train['text'])
train_vector = vector.transform(train['text'])
test_vector = vector.transform(test['text'])
其中,train[‘text’]的shape是[6000,]
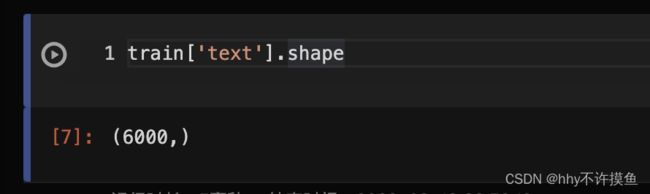
所以对应的train_vector的shape就是(6000, 67855)

test_vector是(2000, 67855)
训练
这里使用的是逻辑回归的方法。本质上是在线性层上堆叠了一个非线性layer,sigmoid将最终结果scale到0-1之间,方便我们进行二分类任务。
# 引入模型
model = LogisticRegression()
# 开始训练,这里可以考虑修改默认的batch_size与epoch来取得更好的效果
model.fit(train_vector, train['label'])
验证
用测试集进行验证。
# 利用模型对测试集label标签进行预测
test['label'] = model.predict(test_vector)
test['Keywords'] = test['title'].fillna('')
test[['uuid','Keywords','label']].to_csv('submit_task1.csv', index=None)
提交结果,分数如下。

改进
当然这还没完,之前的CountVectorizer()是基于BOW模型的。我们也可以基于 TF-IDF 进行提取。
TF 指 term frequence,即词频,指某个词在文章中出现次数与文章总次数的比值;
IDF 指 inverse document frequence,即逆文档频率,指包含某个词的文档数占语料库总文档数的比例
每个词最终的 IF-IDF 即为 TF 值乘以 IDF 值。计算出每个词的 TF-IDF 值后,使用 TF-IDF 计算得到的数值向量替代原文本即可实现基于 TF-IDF 的文本特征提取。
from sklearn.feature_extraction.text import TfidfVectorizer
vector = TfidfVectorizer().fit(train["text"])
# vector = CountVectorizer().fit(train['text'])
train_vector = vector.transform(train['text'])
test_vector = vector.transform(test['text'])
结果也会有显而易见的提高。
