二进制部署K8s群集+Openebs+KubeSphere+Ceph群集
二进制K8s集群部署——版本为v1.20.4
https://www.cnblogs.com/lizexiong/p/14882419.html
K8s群集配置表
| 主机名 | IP地址 | 组件 | 系统 | 配置 |
|---|---|---|---|---|
| k8smaster1 | 192.168.10.101 | docker、etcd、kube-apiserver、kube-controller-manager、kube-scheduler、kubelet、kube-proxy、nginx、keepalived | Centos7.9 | 2C/2G |
| k8smaster2 | 192.168.10.102 | docker、etcd、kube-apiserver、kube-controller-manager、kube-scheduler、kubelet、kube-proxy、nginx、keepalived | Centos7.9 | 2C/2G |
| k8smaster* | … | … | Centos7.9 | 2C/2G |
| k8snode1 | 192.168.10.103 | docker、etcd、kubelet.service、kube-proxy.service | Centos7.9 | 2C/2G |
| k8snode2 | 192.168.10.104 | docker、etcd、kubelet.service、kube-proxy.service | Centos7.9 | 2C/2G |
| k8snode3 | 192.168.10.104 | docker、kubelet.service、kube-proxy.service | Centos7.9 | 2C/2G |
| k8snode* | … | … | Centos7.9 | 2C/2G |
| k8snode* | … | … | Centos7.9 | 2C/2G |
k8s集群——k8smaster节组件点部署
一、基础环境配置初始化所有集群主机——(所有主机k8s主机操作)
1、所有节点修改主机名
192.168.10.101主机
hostnamectl set-hostname k8smaster1
su
192.168.10.102主机
hostnamectl set-hostname k8smaster2
su
192.168.10.103主机
hostnamectl set-hostname k8snode1
su
192.168.10.104主机
hostnamectl set-hostname k8snode2
su
2、关闭放火墙、内核安全机制、swap交换分区
systemctl stop firewalld
systemctl disable firewalld
sed -i "s/.*SELINUX=.*/SELINUX=disabled/g" /etc/selinux/config
swapoff -a
sed -i '/swap/s/^\(.*\)$/#\1/g' /etc/fstab
3、添加hosts文件
cat >> /etc/hosts << EOF
192.168.10.101 k8smaster1
192.168.10.102 k8smaster2
192.168.10.103 k8snode1
192.168.10.104 k8snode2
EOF
4、将桥接的IPv4流量传递到iptables的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
5、配置国内yum和epel源
cd /etc/yum.repos.d/
wget http://mirrors.aliyun.com/repo/Centos-7.repo
mv aliyun.repo aliyun.repo.bak
mv Centos-7.repo CentOS-Base.repo
yum clean all
yum makecache
yum update
wget /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
6、配置时间同步
#安装chrony服务
yum -y install chrony
#启动chronyd服务
systemctl start chronyd
#设置为开机自启动
systemctl enable chronyd
#查看确认时间同步
chronyc sources -v
#或使用阿里云的时间同步服务
yum -y install ntpdate
ntpdate time1.aliyun.com
6、升级系统内核
uname -r
3.10.0-514.el7.x86_64
#下载kernel-ml-4.18.9.tar.gz相关版本的包,可根据情况访问http://193.49.22.109/elrepo/kernel/el7/x86_64/RPMS/自行下载上传到服务器中
tar xf kernel-ml-4.18.9.tar.gz
cd kernel-ml-4.18.9
yum localinstall kernel-ml*
#查看当前的内核
cat /boot/grub2/grub.cfg |grep ^menuentry
menuentry 'CentOS Linux (4.18.9-1.el7.elrepo.x86_64) 7 (Core)' --class centos --class gnu-linux --class gnu --class os --unrestricted $menuentry_id_option 'gnulinux-3.10.0-1127.el7.x86_64-advanced-abb47b92-d268-4d8c-a9df-43bf44522cab' {
menuentry 'CentOS Linux (3.10.0-1127.el7.x86_64) 7 (Core)' --class centos --class gnu-linux --class gnu --class os --unrestricted $menuentry_id_option 'gnulinux-3.10.0-1127.el7.x86_64-advanced-abb47b92-d268-4d8c-a9df-43bf44522cab' {
menuentry 'CentOS Linux (0-rescue-63f20fbd07a048dc88574233e1ad966b) 7 (Core)' --class centos --class gnu-linux --class gnu --class os --unrestricted $menuentry_id_option 'gnulinux-0-rescue-63f20fbd07a048dc88574233e1ad966b-advanced-abb47b92-d268-4d8c-a9df-43bf44522cab' {
#设置默认启动新内核,并重新生成grub2
grub2-set-default 0 或者 grub2-set-default 'CentOS Linux (4.18.9-1.el7.elrepo.x86_64) 7 (Core)'
grub2-mkconfig -o /boot/grub2/grub.cfg
#重启所有节点
reboot
#再次查看内核
uname -r
4.18.9-1.el7.elrepo.x86_64
二、所有节点安装docker——(k8s所有节点操作)
1、下载docker的yum源并安装docker
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
yum -y install docker-ce-19.03.9-3.el7
systemctl enable docker && systemctl start docker
docker --version
2、设置docker镜像仓库地址加速地址
mkdir -p /etc/docker
vim /etc/docker/daemon.json
{
"registry-mirrors": ["https://w2hvqdzg.mirror.aliyuncs.com"]
}
systemctl daemon-reload
systemctl restart docker
#到此所有节点初始化完成
三、部署etcd群集
1、为etcd准备自签证书——(k8smaser1节点操作)
k8s 所有组件都是 采用https加密通信的,这些组件一般有两套根证书生成:k8s 组件(apiserver)和etcd。
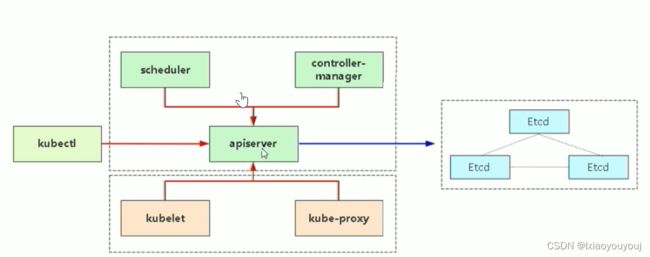 红色线:k8s 自建证书颁发机构(CA),需要携带有它生成的客户端证书访问apiserver。
红色线:k8s 自建证书颁发机构(CA),需要携带有它生成的客户端证书访问apiserver。
蓝色线:etcd 自建证书颁发机构(CA),需要携带它颁发的客户端证书访问etcd。
准备 cfssl 证书生成工具
cfssl 是一个开源的证书管理工具, 使用 json 文件生成证书, 相比 openssl 更方便使用。
找任意一台服务器操作, 这里用 Master 节点。
#下载相关工具
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
chmod +x cfssl_linux-amd64 cfssljson_linux-amd64 cfssl-certinfo_linux-amd64
mv cfssl_linux-amd64 /usr/local/bin/cfssl
mv cfssljson_linux-amd64 /usr/local/bin/cfssljson
mv cfssl-certinfo_linux-amd64 /usr/bin/cfssl-certinfo
生成 Etcd 证书
创建自签证书颁发机构(CA)
#创建证书相关工作目录
mkdir -p ~/TLS/{etcd,k8s}
cd ~/TLS/etcd
#创建ca自签机构的json配置文件
cat > ca-config.json<< EOF
{
"signing":{
"default":{
"expiry":"876000h"
},
"profiles":{
"www":{
"expiry":"87600h",
"usages":[
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
cat > ca-csr.json<< EOF
{
"CN":"etcd CA",
"key":{
"algo":"rsa",
"size":2048
},
"names":[
{
"C":"CN",
"L":"Beijing",
"ST":"Beijing"
}
]
}
EOF
#初始化生成ca证书
cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
ls *.pem
ca-key.pem ca.pem
#使用自签 CA证书 签发 Etcd HTTPS 证书,创建https证书申请文件
{
"CN":"etcd",
"hosts":[
"192.168.10.101",
"192.168.10.102",
"192.168.10.103",
"192.168.10.104"
],
"key":{
"algo":"rsa",
"size":2048
},
"names":[
{
"C":"CN",
"L":"BeiJing",
"ST":"BeiJing"
}
]
}
注意:上述文件 hosts 字段中 IP 为所有 etcd 节点的集群内部通信 IP, 一个都不能少! 为了方便后期扩容可以多写几个预留的 IP。
#生成https证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=www server-csr.json | cfssljson -bare server
#查看生成的https证书
ls server*pem
server-key.pem server.pem
2、安装部署etcd——(k8smaster1节点操做)
Etcd 是一个分布式键值存储系统, Kubernetes 使用 Etcd 进行数据存储; 为解决 Etcd 单点故障, 在生产中采用集群方式部署,避免 Etcd 单点故障, 这里使用 4 台组建集群, 可容忍 1 台机器故障, 如果使用 5 台组建集群, 可容忍 2 台机器故障。生产环境建议单独服务器部署这些etcd节点。
#下载etcd安装包
wget https://github.com/etcd-io/etcd/releases/download/v3.4.9/etcd-v3.4.9-linux-amd64.tar.gz
mkdir /opt/etcd/{bin,cfg,ssl} -p
tar zxvf etcd-v3.4.9-linux-amd64.tar.gz
mv etcd-v3.4.9-linux-amd64/{etcd,etcdctl} /opt/etcd/bin/
#把前面生成的证书拷贝到k8群集etcd证书文件存放路径
#是etcd的ca证书和https证书
cp ~/TLS/etcd/ca*pem ~/TLS/etcd/server*pem /opt/etcd/ssl/
#创建etcd配置文件
cat > /opt/etcd/cfg/etcd.conf << EOF
#[Member]
ETCD_NAME="etcd-1"
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.10.101:2380"
ETCD_LISTEN_CLIENT_URLS="https://192.168.10.101:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.10.101:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.10.101:2379"
ETCD_INITIAL_CLUSTER="etcd-1=https://192.168.10.101:2380,etcd-2=https://192.168.10.102:2380,etcd-3=https://192.168.10.103:2380,etcd-4=https://192.168.10.104:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
EOF
ETCD_NAME: etcd群集节点名称, 集群中唯一
ETCD_DATA_DIR: etcd数据存放目录
ETCD_LISTEN_PEER_URLS: 集群通信监听地址
ETCD_LISTEN_CLIENT_URLS: 客户端访问监听地址,也就是当前机器的ip地址,
ETCD_INITIAL_ADVERTISE_PEER_URLS: 集群通告地址
ETCD_ADVERTISE_CLIENT_URLS: 客户端通告地址
ETCD_INITIAL_CLUSTER: 集群节点地址,需要将每个etcd节点的ip和端口都写上。
ETCD_INITIAL_CLUSTER_TOKEN: 集群 Token
ETCD_INITIAL_CLUSTER_STATE: 加入集群的当前状态, new 是新集群, existing 表示加入已有集群
把当前节点的/opt/etcd目录上传到其他etcd集群节点的/opt/目录下
scp -r /opt/etcd/ root@192.168.10.102:/opt/
scp -r /opt/etcd/ root@192.168.10.103:/opt/
scp -r /opt/etcd/ root@192.168.10.104:/opt/
3、在其他etcd群集节点修改etcd相关配置文件——(Etcd群集节点操作)
vim /opt/etcd/cfg/etcd.conf
#[Member]
ETCD_NAME="etcd-1" #修改为当前节点名,节点 2 改为 etcd-2,节点 3 改为 etcd-3,节点4 改为 etcd-4,以此类推
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
ETCD_LISTEN_PEER_URLS="https://192.168.10.101:2380" #修改为当前节点的IP地址
ETCD_LISTEN_CLIENT_URLS="https://192.168.10.101:2379" #修改为当前节点的IP地址
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.10.101:2380" #修改为当前节点的IP地址
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.10.101:2379" #修改为当前节点的IP地址
ETCD_INITIAL_CLUSTER="etcd-1=https://192.168.10.101:2380,etcd-2=https://192.168.10.102:2380,etcd-3=https://192.168.10.103:2380,etcd-4=https://192.168.10.104:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
#在所有etcd节点配置systemd系统命令控制etcd启停自启动等
cat > /usr/lib/systemd/system/etcd.service << EOF
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
EnvironmentFile=/opt/etcd/cfg/etcd.conf
ExecStart=/opt/etcd/bin/etcd \
--cert-file=/opt/etcd/ssl/server.pem \
--key-file=/opt/etcd/ssl/server-key.pem \
--peer-cert-file=/opt/etcd/ssl/server.pem \
--peer-key-file=/opt/etcd/ssl/server-key.pem \
--trusted-ca-file=/opt/etcd/ssl/ca.pem \
--peer-trusted-ca-file=/opt/etcd/ssl/ca.pem \
--logger=zap
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
#在所有etcd群集节点启动并设置etcd开机启动
systemctl daemon-reload
systemctl start etcd
systemctl enable etcd
#查看集群状态
ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://192.168.10.101:2379,https://192.168.10.102:2379,https://192.168.10.103:2379,https://192.168.10.104:2379" endpoint health --write-out=table
+-----------------------------+--------+-------------+-------+
| ENDPOINT | HEALTH | TOOK | ERROR |
+-----------------------------+--------+-------------+-------+
| https://192.168.10.102:2379 | true | 18.673674ms | |
| https://192.168.10.103:2379 | true | 17.055034ms | |
| https://192.168.10.101:2379 | true | 20.266814ms | |
| https://192.168.10.104:2379 | true | 21.71931ms | |
+-----------------------------+--------+-------------+-------+
#当显示如上所示,则代表启动正常了。
#如果输出上面信息, 就说明集群部署成功。 如果有问题第一步先看日志:/var/log/message 或 journalctl -u etcd,或者journalctl -u etcd -f 实时查看日志。
#到此etcd集群部署成功
四、部署master节点组件(这里先部署一个主节点、剩余主节点我们后面加入)
部署kube-apiserver——(k8smaster1节点操作)
1、创建生成apiserver相关证书
安装apiserver,需要做一个自签证书,从而可以让apiserver通过https访问node节点。下面我们先生成apiserver的自签证书
#创建自签证书颁发机构(ca)
cd /root/TLS/k8s
cat > ca-config.json<< EOF
{
"signing":{
"default":{
"expiry":"876000h"
},
"profiles":{
"kubernetes":{
"expiry":"87600h",
"usages":[
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
cat > ca-csr.json<< EOF
{
"CN":"kubernetes",
"key":{
"algo":"rsa",
"size":2048
},
"names":[
{
"C":"CN",
"L":"Beijing",
"ST":"Beijing",
"O":"k8s",
"OU":"System"
}
]
}
EOF
#生成ca证书
cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
ls *pem
ca-key.pem ca.pem
**使用自签CA证书签发 kube-apiserver HTTPS 证书**
#创建https证书申请文件
为了方便我们后面将单master扩展为多master集群,我们在hosts 数组中添加几个IP作为备用如下所示多余的就是备用IP地址,其中包含以后扩展的k8smaster、k8snode节点和群集漂移VIP地址
注意:记得不要忘记里面的node节点IP地址,不然无法和node节点进行通讯
cat > server-csr.json<< EOF
{
"CN":"kubernetes",
"hosts":[
"10.0.0.1", #集群IP
"127.0.0.1", #自己本身地址
"192.168.10.101",
"192.168.10.102",
"192.168.10.103",
"192.168.10.104",
"192.168.10.105",
"192.168.10.106",
"192.168.10.107",
"192.168.10.244", #集群虚拟漂移VIP地址
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key":{
"algo":"rsa",
"size":2048
},
"names":[
{
"C":"CN",
"L":"BeiJing",
"ST":"BeiJing",
"O":"k8s",
"OU":"System"
}
]
}
EOF
注意:创建https证书文件中的hosts地址框中除了集群IP、127.0.0.1、集群中其他节点IP、还要包含集群虚拟漂移VIP地址
如果没有集群虚拟漂移VIP地址的话后面在添加其他k8smaster节点和k8snode节点时,因为会修改某些配置文件中向apiserver通讯的https
地址为集群虚拟漂移VIP地址,如果没集群虚拟漂移VIP地址会发生各个组件无法和apiserver进行通讯导致集群一直处在NotReady状态
#生成证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes server-csr.json | cfssljson -bare server
#查看生产的证书
ls server*pem
server-key.pem server.pem
2、下载k8s群集安装包
访问https://github.com/kubernetes/kubernetes/tree/master/CHANGELOG可以查询k8s 的各个版本
 我们今天主要以K8s-v1.20.4版本为例演示
我们今天主要以K8s-v1.20.4版本为例演示
#下面的类型根据自己系统类型选择
3、上传并解压安装包——k8smaser1节点操作
#然后将下载的kubernetes-server-linux-amd64.tar.gz 包上传到k8smaster1节点中
#解压安装包
tar -zxvf kubernetes-server-linux-amd64.tar.gz
#解压包的所有文件都在/server/bin 路径下
cd kubernetes/server/bin
 部署master主要需要这些文件,kube-apiserver,kube-controller-manager,kubectl,kube-scheduler。
部署master主要需要这些文件,kube-apiserver,kube-controller-manager,kubectl,kube-scheduler。
4、创建k8smaster1节点安装文件夹
#创建k8smaster节点安装的相关文件夹
mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}
#将k8smaster1节点的相关执行文件拷贝到对应目录
cp kube-apiserver kube-scheduler kube-controller-manager /opt/kubernetes/bin
cp kubectl /usr/bin/
**安装kube-apiserver**
#拷贝前面生成apiserver认证的证书
cp ~/TLS/k8s/ca*pem ~/TLS/k8s/server*pem /opt/kubernetes/ssl/
#创建apiserver配置文件
cat > /opt/kubernetes/cfg/kube-apiserver.conf << EOF
KUBE_APISERVER_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--etcd-servers=https://192.168.10.101:2379,https://192.168.10.102:2379,https://192.168.10.103:2379,https://192.168.10.104:2379 \\
--bind-address=192.168.10.101 \\
--secure-port=6443 \\
--advertise-address=192.168.10.101 \\
--allow-privileged=true \\
--service-cluster-ip-range=10.0.0.0/24 \\
--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction \\
--authorization-mode=RBAC,Node \\
--enable-bootstrap-token-auth=true \\
--token-auth-file=/opt/kubernetes/cfg/token.csv \\
--service-node-port-range=20000-32767 \\
--kubelet-client-certificate=/opt/kubernetes/ssl/server.pem \\
--kubelet-client-key=/opt/kubernetes/ssl/server-key.pem \\
--tls-cert-file=/opt/kubernetes/ssl/server.pem \\
--tls-private-key-file=/opt/kubernetes/ssl/server-key.pem \\
--client-ca-file=/opt/kubernetes/ssl/ca.pem \\
--service-account-key-file=/opt/kubernetes/ssl/ca-key.pem \\
--service-account-issuer=api \\
--service-account-signing-key-file=/opt/kubernetes/ssl/server-key.pem \\
--etcd-cafile=/opt/etcd/ssl/ca.pem \\
--etcd-certfile=/opt/etcd/ssl/server.pem \\
--etcd-keyfile=/opt/etcd/ssl/server-key.pem \\
--requestheader-client-ca-file=/opt/kubernetes/ssl/ca.pem \\
--proxy-client-cert-file=/opt/kubernetes/ssl/server.pem \\
--proxy-client-key-file=/opt/kubernetes/ssl/server-key.pem \\
--requestheader-allowed-names=kubernetes \\
--requestheader-extra-headers-prefix=X-Remote-Extra- \\
--requestheader-group-headers=X-Remote-Group \\
--requestheader-username-headers=X-Remote-User \\
--enable-aggregator-routing=true \\
--audit-log-maxage=30 \\
--audit-log-maxbackup=3 \\
--audit-log-maxsize=100 \\
--audit-log-path=/opt/kubernetes/logs/k8s-audit.log"
EOF
注: 上面两个\ 第一个是转义符, 第二个是换行符, 使用转义符是为了使用 EOF 保留换行符。
• --logtostderr:启用日志
• —v:日志等级
• --log-dir:日志目录
• --etcd-servers:etcd集群地址
• --bind-address:监听地址
• --secure-port:https安全端口
• --advertise-address:集群通告地址
• --allow-privileged:启用授权
• --service-cluster-ip-range:Service虚拟IP地址段
• --enable-admission-plugins:准入控制模块
• --authorization-mode:认证授权,启用RBAC授权和节点自管理
• --enable-bootstrap-token-auth: **启用TLS bootstrap机制下面会配置生成token验证文件**
• --token-auth-file:bootstrap token文件
• --service-node-port-range:Service nodeport类型默认分配端口范围
• --kubelet-client-xxx:apiserver访问kubelet客户端证书
• --tls-xxx-file:apiserver https证书
• 1.20版本必须加的参数:–service-account-issuer,–service-account-signing-key-file
• --etcd-xxxfile:连接Etcd集群证书
• --audit-log-xxx:审计日志
启动聚合层相关配置:
• –requestheader-client-ca-file
• –proxy-client-cert-file
• –proxy-client-key-file
• –requestheader-allowed-names
• –requestheader-extra-headers-prefix
• –requestheader-group-headers
• –requestheader-username-headers
• –enable-aggregator-routin
启用 TLS Bootstrapping 机制
TLS Bootstraping: Master apiserver 启用 TLS 认证后, Node 节点 kubelet 和 kubeproxy 要与 kube-apiserver 进行通信, 必须使用 CA 签发的有效证书才可以, 当 Node节点很多时, 这种客户端证书颁发需要大量工作, 同样也会增加集群扩展复杂度。 为了简化流程, Kubernetes 引入了 TLS bootstraping 机制来自动颁发客户端证书, kubelet会以一个低权限用户自动向 apiserver 申请证书, kubelet 的证书由 apiserver 动态签署。
所以强烈建议在 Node 上使用这种方式, 目前主要用于 kubelet, kube-proxy 还是由我们统一颁发一个证书。
TLS bootstraping 工作流程:

5、创建token文件
#创建上述配置文件中 token 文件
cat > /opt/kubernetes/cfg/token.csv << EOF
fb69c54a1cbcd419b668cf8418c3b8cd,kubelet-bootstrap,10001,"system:node-bootstrapper"
EOF
格式: token, 用户名, UID, 用户组
#token 也可自行生成替换
head -c 16 /dev/urandom | od -An -t x | tr -d ' '
6、配置systemd 管理 apiserver
cat > /usr/lib/systemd/system/kube-apiserver.service << EOF
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-apiserver.conf
ExecStart=/opt/kubernetes/bin/kube-apiserver \$KUBE_APISERVER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
#kube-apiserver启动并设置开机启动
systemctl daemon-reload
systemctl start kube-apiserver
systemctl enable kube-apiserver
到此apiserver安装完成。接下来我们来部署scheduler和controller-manager
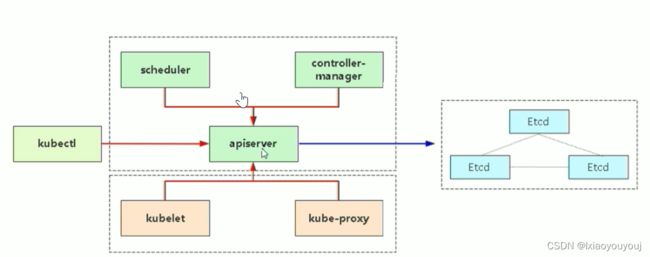
通过上图,我们可以了解到,scheduler和controller-manager 也是借助https链接apiserver的的6443 端口,scheduler和controller-manager 链接apiserver的时候,需要有一个身份:kubeconfig。也就是说scheduler和controller-manager 是通过kubeconfig 文件来链接apiserver的。同样的,kubelet和kube-proxy也是通过kubeconfig来链接apiserver的。
备注:kubeconfig是链接k8s 集群的一个配置文件,需要我们手动生成的。
我们先配置scheduler和controller-manager程序
然后在配置kubeconfig文件。
五、部署kube-controller-manager——(k8smaser1节点操作)
1、创建kube-controller-manager 的配置文件
cat > /opt/kubernetes/cfg/kube-controller-manager.conf << EOF
KUBE_CONTROLLER_MANAGER_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--leader-elect=true \\
--kubeconfig=/opt/kubernetes/cfg/kube-controller-manager.kubeconfig \\
--bind-address=127.0.0.1 \\
--allocate-node-cidrs=true \\
--cluster-cidr=10.244.0.0/16 \\
--service-cluster-ip-range=10.0.0.0/24 \\
--cluster-signing-cert-file=/opt/kubernetes/ssl/ca.pem \\
--cluster-signing-key-file=/opt/kubernetes/ssl/ca-key.pem \\
--root-ca-file=/opt/kubernetes/ssl/ca.pem \\
--service-account-private-key-file=/opt/kubernetes/ssl/ca-key.pem \\
--experimental-cluster-signing-duration=876000h0m0s"
EOF
– kubeconfi:链接apiserver的配置文件
– leader-elect: 当该组件启动多个时, 自动选举( HA)
– cluster-signing-cert-file
– cluster-signing-key-file: 自动为 kubelet 颁发证书的 CA, 与 apiserver 保持一致
2、生成kube-controller-manager.kubeconfig文件
cd /root/TLS/k8s/
#创建证书请求文件
cat > kube-controller-manager-csr.json << EOF
{
"CN": "system:kube-controller-manager",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "system:masters",
"OU": "System"
}
]
}
EOF
#生成证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-controller-manager-csr.json | cfssljson -bare kube-controller-manager
ls kube-controller-manager*
-rw-r--r-- 1 root root 1045 3月 27 13:12 kube-controller-manager.csr
-rw-r--r-- 1 root root 255 3月 27 13:11 kube-controller-manager-csr.json
-rw------- 1 root root 1679 3月 27 13:12 kube-controller-manager-key.pem
-rw-r--r-- 1 root root 1440 3月 27 13:12 kube-controller-manager.pem
生成kubeconfig 文件
#切换到刚才生成kube-controller-manager证书地方
cd /root/TLS/k8s/
#设置环境变量KUBE_CONFIG
KUBE_CONFIG="/opt/kubernetes/cfg/kube-controller-manager.kubeconfig"
#设置环境变量KUBE_APISERVER
KUBE_APISERVER="https://192.168.10.101:6443" # apiserver IP:PORT
kubectl config set-cluster kubernetes \
--certificate-authority=/opt/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-credentials kube-controller-manager \
--client-certificate=./kube-controller-manager.pem \
--client-key=./kube-controller-manager-key.pem \
--embed-certs=true \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-context default \
--cluster=kubernetes \
--user=kube-controller-manager \
--kubeconfig=${KUBE_CONFIG}
kubectl config use-context default --kubeconfig=${KUBE_CONFIG}
#通过命令查看kube-controller-manager.kubeconfig是否生成成功
ll /opt/kubernetes/cfg/kube-controller-manager.kubeconfig
-rw------- 1 root root 6348 3月 27 13:15 /opt/kubernetes/cfg/kube-controller-manager.kubeconfig
3、配置systemd 管理 controller-manager
cat > /usr/lib/systemd/system/kube-controller-manager.service << EOF
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-controller-manager.conf
ExecStart=/opt/kubernetes/bin/kube-controller-manager \$KUBE_CONTROLLER_MANAGER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
#启动controller-manager,并设置开机自启动
systemctl daemon-reload
systemctl start kube-controller-manager
systemctl enable kube-controller-manager
systemctl status kube-controller-manager
六、部署kube-scheduler——(k8smaser1节点操作)
1、创建kube-scheduler配置文件
cat > /opt/kubernetes/cfg/kube-scheduler.conf << EOF
KUBE_SCHEDULER_OPTS="--logtostderr=false \
--v=2 \
--log-dir=/opt/kubernetes/logs \
--leader-elect \
--kubeconfig=/opt/kubernetes/cfg/kube-scheduler.kubeconfig \\
--bind-address=127.0.0.1"
EOF
– leader-elect: 当该组件启动多个时, 自动选举( HA)
– kubeconfi:链接apiserver的配置文件
2、生成kube-scheduler.kubeconfig文件
#切换目录
cd /root/TLS/k8s/
#创建证书请求文件
cat > kube-scheduler-csr.json << EOF
{
"CN": "system:kube-scheduler",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "system:masters",
"OU": "System"
}
]
}
EOF
#生成证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-scheduler-csr.json | cfssljson -bare kube-scheduler
ll kube-scheduler*
-rw-r--r-- 1 root root 1029 3月 27 13:19 kube-scheduler.csr
-rw-r--r-- 1 root root 245 3月 27 13:17 kube-scheduler-csr.json
-rw------- 1 root root 1675 3月 27 13:19 kube-scheduler-key.pem
-rw-r--r-- 1 root root 1424 3月 27 13:19 kube-scheduler.pem
**创建生成kubeconfig 文件**
#切换到刚才生成kube-scheduler 证书地方
cd /root/TLS/k8s/
#设置环境变量KUBE_CONFIG
KUBE_CONFIG="/opt/kubernetes/cfg/kube-scheduler.kubeconfig"
#配置环境变量KUBE_APISERVER
KUBE_APISERVER="https://192.168.10.101:6443" # apiserver IP:PORT
#生成kubeconfig文件
kubectl config set-cluster kubernetes \
--certificate-authority=/opt/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-credentials kube-scheduler \
--client-certificate=./kube-scheduler.pem \
--client-key=./kube-scheduler-key.pem \
--embed-certs=true \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-context default \
--cluster=kubernetes \
--user=kube-scheduler \
--kubeconfig=${KUBE_CONFIG}
kubectl config use-context default --kubeconfig=${KUBE_CONFIG}
ll /opt/kubernetes/cfg/kube-scheduler.kubeconfig
-rw------- 1 root root 6306 3月 27 13:20 /opt/kubernetes/cfg/kube-scheduler.kubeconfig
3、配置systemd管理scheduler
cat > /usr/lib/systemd/system/kube-scheduler.service << EOF
[Unit]
Description=Kubernetes Scheduler
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-scheduler.conf
ExecStart=/opt/kubernetes/bin/kube-scheduler \$KUBE_SCHEDULER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
#kube-scheduler启动并设置开机启动
systemctl daemon-reload
systemctl start kube-scheduler
systemctl enable kube-scheduler
systemctl status kube-scheduler
#查看集群状态
**所有组件都已经启动成功, 通过 kubectl 工具查看当前集群组件状态:**
**如下输出说明 Master 节点组件运行正常。**
kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-1 Healthy {"health":"true"}
etcd-3 Healthy {"health":"true"}
etcd-0 Healthy {"health":"true"}
etcd-2 Healthy {"health":"true"}
如果执行kubectl get cs出现下面报错就说明我们没有配置kubectl的kubeconfig的证书
The connection to the server localhost:8080 was refused - did you specify the right host or port?
七、生成kubectl访问apiserver证书——(k8smaser1节点操作)
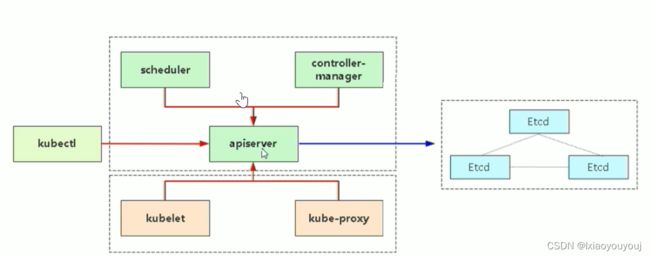 注意:通过kubectl 来访问apiserver时,也是通过https的。我们之前为etcd和apiserver自签证书的时候解释过,上图中红色线部分都是通过https的方式,需要有k8s CA机构生成的证书,各个节点的(scheduler,controller-manager、kubelet、kube-proxy)需要携带有它生成的客户端证书(kubeconfig)访问apiserver。
注意:通过kubectl 来访问apiserver时,也是通过https的。我们之前为etcd和apiserver自签证书的时候解释过,上图中红色线部分都是通过https的方式,需要有k8s CA机构生成的证书,各个节点的(scheduler,controller-manager、kubelet、kube-proxy)需要携带有它生成的客户端证书(kubeconfig)访问apiserver。
kubectl 访问apiserver也是同样的原理,需要也要带着客户端证书(kubeconfig)
为此我们需要为kubectl 单独分配一下kubeconfig。
为kubectl 分配kubeconfig的方式也是类似的。
1、生成kubectl访问apiserver证书
**注意cn字段是admin,并且将其绑定到system:master 组下面。这样就具备了链接k8s 集群管理员权限。**
#切换目录
cd /root/TLS/k8s/
#创建证书请求文件
cat > admin-csr.json<< EOF
{
"CN":"admin",
"hosts":[],
"key":{
"algo":"rsa",
"size":2048
},
"names":[
{
"C":"CN",
"L":"Beijing",
"ST":"Beijing",
"O":"system:masters",
"OU":"System"
}
]
}
EOF
#生成证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes admin-csr.json | cfssljson -bare admin
ll admin*
-rw-r--r-- 1 root root 1009 3月 27 14:25 admin.csr
-rw-r--r-- 1 root root 276 3月 27 14:25 admin-csr.json
-rw------- 1 root root 1675 3月 27 14:25 admin-key.pem
-rw-r--r-- 1 root root 1403 3月 27 14:25 admin.pem
2、生成kubeconfig 文件
#创建目录:因为kubectl的默认配置文件为/user/.kube/路径下的config文件
mkdir /root/.kube
#切换到刚才生成kube-scheduler 证书地方
cd /root/TLS/k8s/
#设置环境变量KUBE_CONFIG**
KUBE_CONFIG="/root/.kube/config"
#配置环境变量KUBE_APISERVER
KUBE_APISERVER="https://192.168.10.101:6443" # apiserver IP:PORT
kubectl config set-cluster kubernetes \
--certificate-authority=/opt/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-credentials cluster-admin \
--client-certificate=./admin.pem \
--client-key=./admin-key.pem \
--embed-certs=true \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-context default \
--cluster=kubernetes \
--user=cluster-admin \
--kubeconfig=${KUBE_CONFIG}
kubectl config use-context default --kubeconfig=${KUBE_CONFIG}
ll /root/.kube/config
-rw------- 1 root root 6276 3月 27 14:28 /root/.kube/config
#然后在执行kubectl get cs
kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-1 Healthy {"health":"true"}
etcd-3 Healthy {"health":"true"}
etcd-0 Healthy {"health":"true"}
etcd-2 Healthy {"health":"true"}
#出现这些就说明没问题了
k8s集群——k8snode节点部署相关组件(kubelet,kube-proxy)
一、部署kubelet
1、在所有k8snode节点上创建k8s文件夹
mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}
2、把kubelet、kube-proxy及相关软件包复制到所有k8snode节点——(k8smaster1节点操作)
cd kubernetes/server/bin/
#复制 kube-proxy
scp kube-proxy root@192.168.10.103:/opt/kubernetes/bin/
scp kube-proxy root@192.168.10.104:/opt/kubernetes/bin/
#复制kubelet
scp kubelet root@192.168.10.103:/opt/kubernetes/bin/
scp kubelet root@192.168.10.104:/opt/kubernetes/bin/
#复制kubectl
scp kubectl root@192.168.10.103:/usr/bin/
scp kubectl root@192.168.10.104:/usr/bin/
#把生成的kubectl.kubeconfig文件拷贝到k8snode节点
cd /root/
scp -r .kube/ root@192.168.10.103:/root/
scp -r .kube/ root@192.168.10.104:/root/
#这样k8snode节点也可以使用kubectl命令了
3、创建kubelet.conf 文件——(所有k8snode节点操作)
#其中–hostname-override 改成对用node节点的主机名称,我们这里是k8snode1和k8snode2
cat > /opt/kubernetes/cfg/kubelet.conf << EOF
KUBELET_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--hostname-override=k8snode1 \\
--network-plugin=cni \\
--kubeconfig=/opt/kubernetes/cfg/kubelet.kubeconfig \\
--bootstrap-kubeconfig=/opt/kubernetes/cfg/bootstrap.kubeconfig \\
--config=/opt/kubernetes/cfg/kubelet-config.yml \\
--cert-dir=/opt/kubernetes/ssl \\
--pod-infra-container-image=lizhenliang/pause-amd64:3.0"
EOF
– hostname-override: 显示名称, 集群中唯一
– network-plugin: 启用 CNI
– kubeconfig: 空路径, 会自动生成, 后面用于连接 apiserver
– bootstrap-kubeconfig: 首次启动向 apiserver 申请证书
– config: 配置参数文件
– cert-dir: kubelet 证书生成目录
– pod-infra-container-image: 管理 Pod 网络容器的镜像
4、创建 kubelet 参数配置文件——(所有k8snode节点操作)
cat > /opt/kubernetes/cfg/kubelet-config.yml << EOF
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
address: 0.0.0.0
port: 10250
readOnlyPort: 10255
cgroupDriver: cgroupfs
clusterDNS:
- 10.0.0.2
clusterDomain: cluster.local
failSwapOn: false
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 2m0s
enabled: true
x509:
clientCAFile: /opt/kubernetes/ssl/ca.pem
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 5m0s
cacheUnauthorizedTTL: 30s
evictionHard:
imagefs.available: 15%
memory.available: 100Mi
nodefs.available: 10%
nodefs.inodesFree: 5%
maxOpenFiles: 1000000
maxPods: 110
EOF
5、所有k8snode节点生成bootstrap.kubeconfig 客户端请求文件——(k8smaser1节点操作)
#将k8smaster1节点/opt/kubernetes/ssl/所有文件复制到所有k8snode节点
cd /opt/kubernetes/ssl
scp ca* server* root@192.168.10.103:/opt/kubernetes/ssl/
scp ca* server* root@192.168.10.104:/opt/kubernetes/ssl/
6、生成 kubelet的bootstrap.kubeconfig 配置文件,并复制到各个k8snode节点——(k8smaster1节点操作)
#配置环境变量KUBE_APISERVER
KUBE_APISERVER="https://192.168.10.101:6443" # apiserver IP:PORT
#配置环境变量token
TOKEN="fb69c54a1cbcd419b668cf8418c3b8cd" #与之前配置生成的 token.csv 里保持一致
#设置环境变量KUBE_CONFIG
KUBE_CONFIG="/opt/kubernetes/cfg/bootstrap.kubeconfig"
#生成bootstrap.kubeconfig文件
kubectl config set-cluster kubernetes \
--certificate-authority=/opt/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-credentials "kubelet-bootstrap" \
--token=${TOKEN} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-context default \
--cluster=kubernetes \
--user="kubelet-bootstrap" \
--kubeconfig=${KUBE_CONFIG}
kubectl config use-context default --kubeconfig=${KUBE_CONFIG}
cd /opt/kubernetes/cfg
ll bootstrap.kubeconfig
-rw------- 1 root root 2168 3月 27 15:25 bootstrap.kubeconfig
#复制bootstrap.kubeconfig到所有k8snode节点
scp bootstrap.kubeconfig root@192.168.10.103:/opt/kubernetes/cfg/
scp bootstrap.kubeconfig root@192.168.10.104:/opt/kubernetes/cfg/
所有k8snode节点操作*********
7、配置systemd管理kubelet,启动并设置开机自启动——(所有k8snode节点操作)
cat > /usr/lib/systemd/system/kubelet.service << EOF
[Unit]
Description=Kubernetes Kubelet
After=docker.service
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kubelet.conf
ExecStart=/opt/kubernetes/bin/kubelet \$KUBELET_OPTS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl start kubelet
systemctl enable kubelet
systemctl status kubelet
8、授权 kubelet-bootstrap 用户允许请求证书——(k8smaser1节点操作)
这一步主要是为后面添加k8snode节点做准备,让我们之前创建的token 文件中的用户,并绑定到角色node-bootstrapper,从而可以让k8snode 以token 文件中的用户带着node-bootstrapper角色最小权限的访问apiserver。
kubectl create clusterrolebinding kubelet-bootstrap \
--clusterrole=system:node-bootstrapper \
--user=kubelet-bootstrap
批准 kubelet 的证书申请并加入集群——(在k8smaster1节点上执行)

批准申请命令示例
kubectl certificate approve node-csr-uCEGPOIiDdlLODKts8J658HrFq9CZ–K6M4G7bjhk8A

查询集群状态——(k8smaser1节点操作)
由于网络插件还没有部署, 节点会没有准备就绪 NotReady
kubectl get node
NAME STATUS ROLES AGE VERSION
k8snode1 NotReady 8m27s v1.20.4
k8snode2 NotReady 8m13s v1.20.4
#而且这里也没有显示k8smaster节点的状态,想要探测到集群中master节点状态也需要在master节点部署kubelet、kube-proxy
##后面会有详细操作说明
二、部署kube-proxy——(所有k8snode节点操作)
1、创建kube-proxy配置文件
cat > /opt/kubernetes/cfg/kube-proxy.conf << EOF
KUBE_PROXY_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--config=/opt/kubernetes/cfg/kube-proxy-config.yml"
EOF
2、配置参数配置文件
cat > /opt/kubernetes/cfg/kube-proxy-config.yml << EOF
kind: KubeProxyConfiguration
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress: 0.0.0.0
metricsBindAddress: 0.0.0.0:10249
clientConnection:
kubeconfig: /opt/kubernetes/cfg/kube-proxy.kubeconfig
hostnameOverride: k8snode1
clusterCIDR: 10.0.0.0/24
EOF
#注意:kubeconfig前面有两个空格。
#hostnameOverride 为当前主机名称。node1 节点为k8snode1,node2节点为k8snode2
3、生成 kube-proxy.kubeconfig 文件——(k8smaser1节点操作)
在k8smaster1 节点上生成 kube-proxy 证书
#切换目录
cd /root/TLS/k8s
#创建证书请求文件
cat > kube-proxy-csr.json<< EOF
{
"CN":"system:kube-proxy",
"hosts":[
],
"key":{
"algo":"rsa",
"size":2048
},
"names":[
{
"C":"CN",
"L":"BeiJing",
"ST":"BeiJing",
"O":"k8s",
"OU":"System"
}
]
}
EOF
#生成证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy
ls kube-proxy*pem
kube-proxy-key.pem kube-proxy.pem
生成 kubeconfig 文件
KUBE_APISERVER="https://192.168.10.101:6443"
KUBE_CONFIG="/opt/kubernetes/cfg/kube-proxy.kubeconfig"
kubectl config set-cluster kubernetes \
--certificate-authority=/opt/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-credentials kube-proxy \
--client-certificate=./kube-proxy.pem \
--client-key=./kube-proxy-key.pem \
--embed-certs=true \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-context default \
--cluster=kubernetes \
--user=kube-proxy \
--kubeconfig=${KUBE_CONFIG}
kubectl config use-context default --kubeconfig=${KUBE_CONFIG}
ll /opt/kubernetes/cfg/kube-proxy.kubeconfig
-rw------- 1 root root 6274 3月 27 15:36 /opt/kubernetes/cfg/kube-proxy.kubeconfig
将kube-proxy.kubeconfig拷贝到所有k8snode节点指定路径——(k8smaster1节点操作)
scp /opt/kubernetes/cfg/kube-proxy.kubeconfig root@192.168.10.103:/opt/kubernetes/cfg/
scp /opt/kubernetes/cfg/kube-proxy.kubeconfig root@192.168.10.104:/opt/kubernetes/cfg/
4、配置systemd管理kube-proxy——(所有k8snode节点操作)
cat > /usr/lib/systemd/system/kube-proxy.service << EOF
[Unit]
Description=Kubernetes Proxy
After=network.target
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-proxy.conf
ExecStart=/opt/kubernetes/bin/kube-proxy \$KUBE_PROXY_OPTS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
#启动并设置开机启动
systemctl daemon-reload
systemctl start kube-proxy
systemctl status kube-proxy
systemctl enable kube-proxy
k8s群集——部署集群网络calico
一、部署calico网路组件——(k8smaser1节点操作)
访问calico官网https://docs.tigera.io/

 这里以calico3.15为例
这里以calico3.15为例

1、下载安装calico网络组件的安装文件
curl https://docs.projectcalico.org/archive/v3.15/manifests/calico.yaml -O
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 176k 100 176k 0 0 187k 0 --:--:-- --:--:-- --:--:-- 187k
ll calico.yaml
-rw-r--r-- 1 root root 181004 3月 28 16:17 calico.yaml
kubectl apply -f calico.yaml
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-97769f7c7-lmv6k 1/1 Running 1 23h
calico-node-dqh44 1/1 Running 2 23h
calico-node-gnfz7 1/1 Running 1 23h
kubectl get node
NAME STATUS ROLES AGE VERSION
k8snode1 Ready 23h v1.20.4
k8snode2 Ready 23h v1.20.4
#可以看到在安装完集群网络后工作节点状态就变为了ready状态了
k8s群集——部署coredns
1、k8smaster1节点操作创建coredns.yaml文件——(k8smaser1节点操作)
vim coredns.yaml
#Warning: This is a file generated from the base underscore template file: coredns.yaml.base
apiVersion: v1
kind: ServiceAccount
metadata:
name: coredns
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
kubernetes.io/bootstrapping: rbac-defaults
addonmanager.kubernetes.io/mode: Reconcile
name: system:coredns
rules:
- apiGroups:
- ""
resources:
- endpoints
- services
- pods
- namespaces
verbs:
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
addonmanager.kubernetes.io/mode: EnsureExists
name: system:coredns
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:coredns
subjects:
- kind: ServiceAccount
name: coredns
namespace: kube-system
---
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
labels:
addonmanager.kubernetes.io/mode: EnsureExists
data:
Corefile: |
.:53 {
errors
health
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
upstream
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
proxy . /etc/resolv.conf
cache 30
loop
reload
loadbalance
}
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: coredns
namespace: kube-system
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "CoreDNS"
spec:
# replicas: not specified here:
# 1. In order to make Addon Manager do not reconcile this replicas parameter.
# 2. Default is 1.
# 3. Will be tuned in real time if DNS horizontal auto-scaling is turned on.
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
selector:
matchLabels:
k8s-app: kube-dns
template:
metadata:
labels:
k8s-app: kube-dns
annotations:
seccomp.security.alpha.kubernetes.io/pod: 'docker/default'
spec:
serviceAccountName: coredns
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
- key: "CriticalAddonsOnly"
operator: "Exists"
containers:
- name: coredns
image: coredns/coredns:1.2.2
imagePullPolicy: IfNotPresent
resources:
limits:
memory: 170Mi
requests:
cpu: 100m
memory: 70Mi
args: [ "-conf", "/etc/coredns/Corefile" ]
volumeMounts:
- name: config-volume
mountPath: /etc/coredns
readOnly: true
ports:
- containerPort: 53
name: dns
protocol: UDP
- containerPort: 53
name: dns-tcp
protocol: TCP
- containerPort: 9153
name: metrics
protocol: TCP
livenessProbe:
httpGet:
path: /health
port: 8080
scheme: HTTP
initialDelaySeconds: 60
timeoutSeconds: 5
successThreshold: 1
failureThreshold: 5
securityContext:
allowPrivilegeEscalation: false
capabilities:
add:
- NET_BIND_SERVICE
drop:
- all
readOnlyRootFilesystem: true
dnsPolicy: Default
volumes:
- name: config-volume
configMap:
name: coredns
items:
- key: Corefile
path: Corefile
---
apiVersion: v1
kind: Service
metadata:
name: kube-dns
namespace: kube-system
annotations:
prometheus.io/port: "9153"
prometheus.io/scrape: "true"
labels:
k8s-app: kube-dns
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
kubernetes.io/name: "CoreDNS"
spec:
selector:
k8s-app: kube-dns
clusterIP: 10.0.0.2
ports:
- name: dns
port: 53
protocol: UDP
- name: dns-tcp
port: 53
protocol: TCP
kubectl apply -f coredns.yaml
serviceaccount/coredns configured
clusterrole.rbac.authorization.k8s.io/system:coredns configured
clusterrolebinding.rbac.authorization.k8s.io/system:coredns configured
configmap/coredns configured
deployment.apps/coredns created
service/kube-dns configured
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-97769f7c7-lmv6k 1/1 Running 1 46h
calico-node-dqh44 1/1 Running 2 46h
calico-node-gnfz7 1/1 Running 1 46h
coredns-6d8f96d957-mjkdf 1/1 Running 0 27s
2、如果执行以下命令出错——(k8smaser1节点操作)
kubectl logs coredns-6d8f96d957-mjkdf -n kube-system
#出现如下错误
Error from server (Forbidden): Forbidden (user=kubernetes, verb=get, resource=nodes, subresource=proxy) ( pods/log coredns-6b9bb479b9-79qt8)
说明apiserver没有权限访问kubelet 所以要创建apiserver访问权限
3、创建授权配置文件授权 apiserver 访问 kubelet所有k8smaster节点都需要操作——(这里先在k8smaster1节点操做)
#编辑授权apiserver访问kubelet的yaml文件
vim apiserver-to-kubelet-rbac.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:kube-apiserver-to-kubelet
rules:
- apiGroups:
- ""
resources:
- nodes/proxy
- nodes/stats
- nodes/log
- nodes/spec
- nodes/metrics
- pods/log
verbs:
- "*"
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:kube-apiserver
namespace: ""
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:kube-apiserver-to-kubelet
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: kubernetes
#执行授权apiserver访问kubelet的yaml文件
kubectl apply -f apiserver-to-kubelet-rbac.yaml
kubectl logs coredns-6d8f96d957-mjkdf -n kube-system
.:53
2023/04/11 06:11:18 [INFO] CoreDNS-1.2.2
2023/04/11 06:11:18 [INFO] linux/amd64, go1.11, eb51e8b
CoreDNS-1.2.2
linux/amd64, go1.11, eb51e8b
2023/04/11 06:11:18 [INFO] plugin/reload: Running configuration MD5 = 18863a4483c30117a60ae2332bab9448
W0411 06:24:20.801128 1 reflector.go:341] github.com/coredns/coredns/plugin/kubernetes/controller.go:350: watch of *v1.Endpoints ended with: too old resource version: 730901 (731192)
W0411 06:24:26.130903 1 reflector.go:341] github.com/coredns/coredns/plugin/kubernetes/controller.go:355: watch of *v1.Namespace ended with: too old resource version: 729252 (731192)
W0411 06:29:47.732366 1 reflector.go:341] github.com/coredns/coredns/plugin/kubernetes/controller.go:348: watch of *v1.Service ended with: too old resource version: 729252 (731192)
W0411 06:43:26.757851 1 reflector.go:341] github.com/coredns/coredns/plugin/kubernetes/controller.go:348: watch of *v1.Service ended with: too old resource version: 731192 (733682)
W0412 07:24:20.172632 1 reflector.go:341] github.com/coredns/coredns/plugin/kubernetes/controller.go:350: watch of *v1.Endpoints ended with: too old resource version: 1008607 (1008610)
W0412 07:26:17.959584 1 reflector.go:341] github.com/coredns/coredns/plugin/kubernetes/controller.go:355: watch of *v1.Namespace ended with: too old resource version: 731192 (1008713)
W0412 07:26:54.061601 1 reflector.go:341] github.com/coredns/coredns/plugin/kubernetes/controller.go:350: watch of *v1.Endpoints ended with: too old resource version: 1008728 (1008779)
W0412 07:26:54.835794 1 reflector.go:341] github.com/coredns/coredns/plugin/kubernetes/controller.go:355: watch of *v1.Namespace ended with: too old resource version: 1008713 (1008789)
W0412 07:27:57.357091 1 reflector.go:341] github.com/coredns/coredns/plugin/kubernetes/controller.go:355: watch of *v1.Namespace ended with: too old resource version: 1008789 (1008914)
W0412 07:28:05.938866 1 reflector.go:341] github.com/coredns/coredns/plugin/kubernetes/controller.go:350: watch of *v1.Endpoints ended with: too old resource version: 1008779 (1008918)
W0412 07:28:47.303274 1 reflector.go:341] github.com/coredns/coredns/plugin/kubernetes/controller.go:355: watch of *v1.Namespace ended with: too old resource version: 1008914 (1009091)
W0412 07:29:22.444485 1 reflector.go:341] github.com/coredns/coredns/plugin/kubernetes/controller.go:350: watch of *v1.Endpoints ended with: too old resource version: 1008918 (1009139)
W0412 07:30:08.527392 1 reflector.go:341] github.com/coredns/coredns/plugin/kubernetes/controller.go:350: watch of *v1.Endpoints ended with: too old resource version: 1009139 (1009148)
W0412 07:30:13.596922 1 reflector.go:341] github.com/coredns/coredns/plugin/kubernetes/controller.go:355: watch of *v1.Namespace ended with: too old resource version: 1009091 (1009157)
W0412 07:30:36.928386 1 reflector.go:341] github.com/coredns/coredns/plugin/kubernetes/controller.go:355: watch of *v1.Namespace ended with: too old resource version: 1009157 (1009172)
W0412 07:32:11.591105 1 reflector.go:341] github.com/coredns/coredns/plugin/kubernetes/controller.go:348: watch of *v1.Service ended with: too old resource version: 954709 (1009148)
#可以看到命令可以正常使用了
k8s群集——增加K8smaster节点升级为高可用架构
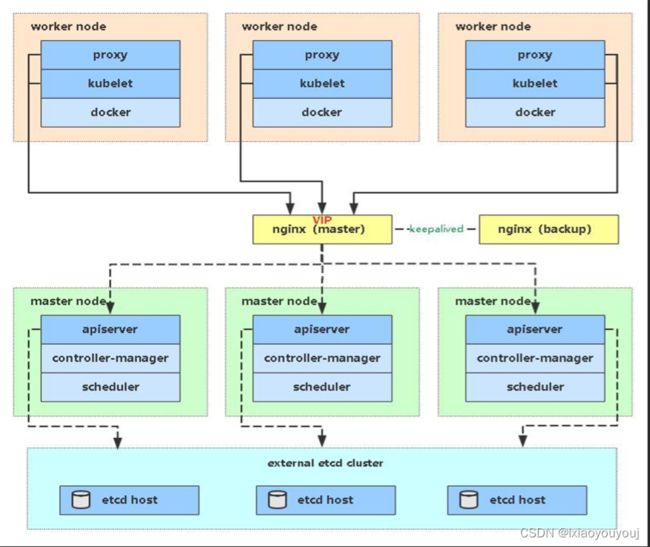
Kubernetes作为容器集群系统,通过健康检查+重启策略实现了Pod故障自我修复能力,通过调度算法实现将Pod分布式部署,并保持预期副本数,根据Node失效状态自动在其他Node拉起Pod,实现了应用层的高可用性。
针对Kubernetes集群,高可用性还应包含以下两个层面的考虑:
Etcd数据库的高可用性和Kubernetes Master组件的高可用性,而Etcd我们已经采用3个节点组建集群实现高可用,本节将对Master节点高可用进行说明和实施。
Master节点扮演着总控中心的角色,通过不断与工作节点上的Kubelet和kube-proxy进行通信来维护整个集群的健康工作状态。如果Master节点故障,将无法使用kubectl工具或者API做任何集群管理。
Master节点主要有三个服务kube-apiserver、kube-controller-manager和kube-scheduler,其中kube-controller-manager和kube-scheduler组件自身通过选择机制已经实现了高可用,所以Master高可用主要针对kube-apiserver组件,而该组件是以HTTP API提供服务,因此对他高可用与Web服务器类似,增加负载均衡器对其负载均衡即可,并且可水平扩容。
一、部署k8smaster2节点(如果添加多master操作和添加k8smaser2是一样的)
前面我们所有节点已经初始化和安装过docker了所以这里我们直接部署k8smaster2节点就好了
1、复制k8smaster1节点相关配置到k8smaster2节点——(k8smaser1节点操作)
scp -r /opt/kubernetes 192.168.10.102:/opt/
scp /usr/lib/systemd/system/kube* 192.168.10.102:/usr/lib/systemd/system/
scp /usr/bin/kubectl 192.168.10.102:/usr/bin/
scp -r ~/.kube 192.168.10.102:/root/
2、修改相关配置文件地址为本地地址——(k8smaser2节点操作)
vim /opt/kubernetes/cfg/kube-apiserver.conf
KUBE_APISERVER_OPTS="--logtostderr=false \
--v=2 \
--log-dir=/opt/kubernetes/logs \
--etcd-servers=https://192.168.10.101:2379,https://192.168.10.102:2379,https://192.168.10.103:2379,https://192.168.10.104:2379 \
--bind-address=192.168.10.102 \
--secure-port=6443 \
--advertise-address=192.168.10.102 \
--allow-privileged=true \
--service-cluster-ip-range=10.0.0.0/24 \
--enable-admission-plugins=NamespaceLifecycle,ServiceAccount,LimitRanger,ResourceQuota,NodeRestriction \
--authorization-mode=RBAC,Node \
--enable-bootstrap-token-auth=true \
--token-auth-file=/opt/kubernetes/cfg/token.csv \
--service-node-port-range=20000-32767 \
--kubelet-client-certificate=/opt/kubernetes/ssl/server.pem \
--kubelet-client-key=/opt/kubernetes/ssl/server-key.pem \
--tls-cert-file=/opt/kubernetes/ssl/server.pem \
--tls-private-key-file=/opt/kubernetes/ssl/server-key.pem \
--client-ca-file=/opt/kubernetes/ssl/ca.pem \
--service-account-key-file=/opt/kubernetes/ssl/ca-key.pem \
--service-account-issuer=api \
--service-account-signing-key-file=/opt/kubernetes/ssl/server-key.pem \
--etcd-cafile=/opt/etcd/ssl/ca.pem \
--etcd-certfile=/opt/etcd/ssl/server.pem \
--etcd-keyfile=/opt/etcd/ssl/server-key.pem \
--requestheader-client-ca-file=/opt/kubernetes/ssl/ca.pem \
--proxy-client-cert-file=/opt/kubernetes/ssl/server.pem \
--proxy-client-key-file=/opt/kubernetes/ssl/server-key.pem \
--requestheader-allowed-names=kubernetes \
--requestheader-extra-headers-prefix=X-Remote-Extra- \
--requestheader-group-headers=X-Remote-Group \
--requestheader-username-headers=X-Remote-User \
--enable-aggregator-routing=true \
--audit-log-maxage=30 \
--audit-log-maxbackup=3 \
--audit-log-maxsize=100 \
--audit-log-path=/opt/kubernetes/logs/k8s-audit.log"
#修改这两处
--bind-address= #修改为本机地址
--advertise-address= #修改为本机地址
vim /opt/kubernetes/cfg/kube-controller-manager.kubeconfig
server: https://192.168.10.102:6443 #修改server地址为本机地址
vim /opt/kubernetes/cfg/kube-scheduler.kubeconfig
server: https://192.168.10.102:6443 #修改server地址为本机地址
vim /opt/kubernetes/cfg/bootstrap.kubeconfig
server: https://192.168.10.102:6443 #修改server地址为本机地址
vim /opt/kubernetes/cfg/kube-proxy.kubeconfig
server: https://192.168.10.102:6443 #修改server地址为本机地址
vim /root/.kube/config
server: https://192.168.10.102:6443 #修改server地址为本机地址
3、启动设置开机自启主节点服务
systemctl daemon-reload
systemctl enable kube-apiserver kube-controller-manager kube-scheduler
systemctl start kube-apiserver kube-controller-manager kube-scheduler
4、如果执行kubectl get cs命令出错误——(k8smaser2节点操作)
kubectl get cs
tail -f /var/log/messges #查看日志发现是这个问题
k8s.io/client-go/informers/factory.go:134: Failed to watch *v1.ReplicationController: failed to list *v1.ReplicationController: Get "https://192.168.10.102:6443/api/v1/replicationcontrollers?limit=500&resourceVersion=0": dial tcp 192.168.10.102:6443: connect: connection refused
#可能是linux的内核安全机制没有彻底关闭
setenforce 0
sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
#然后重启主节点上面的kube-apiserver服务
systemctl restart kube-apiserver.service
#再次查看
kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-2 Healthy {"health":"true"}
etcd-1 Healthy {"health":"true"}
etcd-0 Healthy {"health":"true"}
etcd-3 Healthy {"health":"true"}
5、如果k8smaster2节点执行kubectl get cs出现以下错误
kubectl get cs
error:kubectl get cs No resources found.
原因是因为我们之前已经让k8smaster1节点批准 kubelet 的证书申请并加入集群了
在k8smaster2节点没有批准kubelet的证书申请并加入群集,所以我们要重新申请加入集群
#停止kubelet服务——(所有k8snode节操作)
systemctl stop kubelet.service
#删除kubelet认证自动生成的文件
cd /opt/kubernetes/ssl
ca-key.pem kubelet-client-2023-03-29-16-55-33.pem kubelet.crt server-key.pem
ca.pem kubelet-client-current.pem kubelet.key server.pem
rm -f kubelet-client-* kubelet*
#在启动kubelet服务
systemctl start kubelet.service
#创建授权过kubelet-bootstrap的k8smaster节点操作
kubectl delete clusterrolebinding kubelet-bootstrap #先删除之前的kubelet-bootstrap
kubectl create clusterrolebinding kubelet-bootstrap --clusterrole=system:node-bootstrapper --user=kubelet-bootstrap #在重新创建授权下
#在k8smaster节点查看node节点的请求——(所有k8smaster节点都可操作)
kubectl get csr
NAME AGE REQUESTOR CONDITION
node-csr-mJwuqA7DAf4UmB1InN_WEYhFWbQKOqUVXg9Bvc7Intk 4s kubelet-bootstrap Pending
node-csr-ydhzi9EG9M_Ozmbvep0ledwhTCanppStZoq7vuooTq8 11s kubelet-bootstrap Pending
#所有k8smaster授权kubelet的请求——(所有k8smaster节点操作)
kubectl certificate approve node-csr-mJwuqA7DAf4UmB1InN_WEYhFWbQKOqUVXg9Bvc7Intk
certificatesigningrequest.certificates.k8s.io/node-csr-mJwuqA7DAf4UmB1InN_WEYhFWbQKOqUVXg9Bvc7Intk approved
kubectl certificate approve node-csr-ydhzi9EG9M_Ozmbvep0ledwhTCanppStZoq7vuooTq8
certificatesigningrequest.certificates.k8s.io/node-csr-ydhzi9EG9M_Ozmbvep0ledwhTCanppStZoq7vuooTq8 approved
6、创建授权配置文件授权 apiserver 访问 kubelet(所有k8smaster节点都需操做)这里k8smaser2节点操作
k8smaster1节点已经执行过了,只需要在未执行的master节点执行
如果不进行授权可能导致kubectl logs 等命令执行出错
#编辑授权访问kubelet的yaml文件
vim apiserver-to-kubelet-rbac.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:kube-apiserver-to-kubelet
rules:
- apiGroups:
- ""
resources:
- nodes/proxy
- nodes/stats
- nodes/log
- nodes/spec
- nodes/metrics
- pods/log
verbs:
- "*"
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:kube-apiserver
namespace: ""
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:kube-apiserver-to-kubelet
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: kubernetes
#执行授权可以访问kubelet的yaml文件
kubectl apply -f apiserver-to-kubelet-rbac.yaml
#测试查看pod日志
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-97769f7c7-lmv6k 1/1 Running 2 3d17h
calico-node-dqh44 1/1 Running 3 3d17h
calico-node-gnfz7 1/1 Running 2 3d17h
calico-node-jqklg 1/1 Running 0 20h
calico-node-x48ld 1/1 Running 0 20h
coredns-6d8f96d957-mjkdf 1/1 Running 1 43h
kubectl logs coredns-6d8f96d957-mjkdf -n kube-system
.:53
2023/03/30 05:07:35 [INFO] CoreDNS-1.2.2
2023/03/30 05:07:35 [INFO] linux/amd64, go1.11, eb51e8b
CoreDNS-1.2.2
linux/amd64, go1.11, eb51e8b
2023/03/30 05:07:35 [INFO] plugin/reload: Running configuration MD5 = 18863a4483c30117a60ae2332bab9448
#这样就可以正常查看日志了
#到此所有master节点都部署完毕了,接下来我们要实现高可用的功能了
k8s群集——部署Nginx+Keepalived高可用负载均衡器
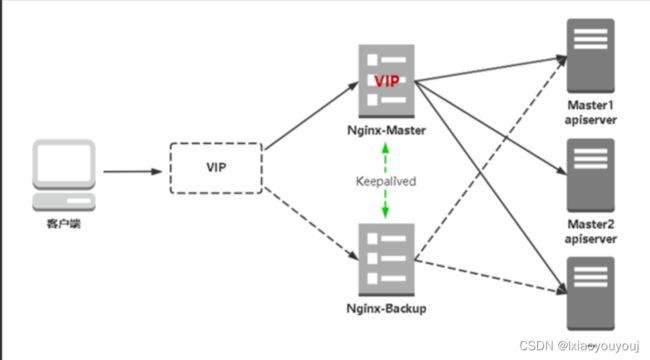 • Nginx是一个主流Web服务和反向代理服务器,这里用四层实现对apiserver实现负载均衡。
• Nginx是一个主流Web服务和反向代理服务器,这里用四层实现对apiserver实现负载均衡。
• Keepalived是一个主流高可用软件,基于VIP绑定实现服务器双机热备,在上述拓扑中,Keepalived主要根据Nginx运行状态判断是否需要故障转移(漂移VIP),例如当Nginx主节点挂掉,VIP会自动绑定在Nginx备节点,从而保证VIP一直可用,实现Nginx高可用。
注意1:为了节省机器,这里与K8s Master节点机器复用。也可以独立于k8s集群之外部署,只要nginx与apiserver能通信就行。
注意2:如果你是在公有云上,一般都不支持keepalived,那么你可以直接用它们的负载均衡器产品,直接负载均衡多台Master kube-apiserver,架构与上面一样
一、部署配置nginx+keepalived高可用负载均衡器——(所有k8smaser节点操作)
1、安装nginx+keepalived
yum -y install epel-release nginx keepalived
2、配置nginx
vim /etc/nginx/nginx.conf
# For more information on configuration, see:
# * Official English Documentation: http://nginx.org/en/docs/
# * Official Russian Documentation: http://nginx.org/ru/docs/
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
# Load dynamic modules. See /usr/share/doc/nginx/README.dynamic.
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
#(配置如下*********************************************************************************)
#四层负载均衡,为两台Master apiserver组件提供负载均衡
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
access_log /var/log/nginx/k8s-access.log main;
upstream k8s-apiserver {
server 192.168.10.101:6443; # Master1 APISERVER IP:PORT
server 192.168.10.102:6443; # Master2 APISERVER IP:PORT
}
server {
listen 16443; #由于nginx与master节点复用,这个监听端口不能是6443,否则会冲突
proxy_pass k8s-apiserver;
}
}
#(配置如上********************************************************************************)
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 4096;
include /etc/nginx/mime.types;
default_type application/octet-stream;
# Load modular configuration files from the /etc/nginx/conf.d directory.
# See http://nginx.org/en/docs/ngx_core_module.html#include
# for more information.
include /etc/nginx/conf.d/*.conf;
server {
listen 80;
listen [::]:80;
server_name _;
root /usr/share/nginx/html;
# Load configuration files for the default server block.
include /etc/nginx/default.d/*.conf;
error_page 404 /404.html;
location = /404.html {
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
}
}
}
3、配置keeplalived
cd /etc/keepalived/
mv keepalived.conf keepalived.conf.bak
vim keepalived.conf
global_defs {
notification_email {
acassen@firewall.loc
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_MASTER #注意:k8smaster1(nginx主)配置为NGINX_MASTER 其他k8smaster(nginx备)配置为NGINX_BACKUP
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh" #指定检查nginx工作状态脚本(根据nginx状态判断是否故障转移)
}
vrrp_instance VI_1 {
state MASTER
interface ens33 # 修改为实际网卡名
virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的
priority 100 # 优先级,备服务器设置 90
advert_int 1 # 指定VRRP 心跳包通告间隔时间,默认1秒
authentication {
auth_type PASS
auth_pass 1111
}
# 虚拟漂移VIP地址要和之前配置apiserver 生成server证书配置中的漂移VIP地址一致
virtual_ipaddress {
192.168.10.244/24
}
track_script {
check_nginx
}
}
4、创建keepalived配置文件中判断nginx工作状态的脚本文件
vim check_nginx.sh
#!/bin/bash
count=$(ss -antp |grep nginx |egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
exit 1
else
exit 0
fi
5、赋予脚本执行权限
chmod +x /etc/keepalived/check_nginx.sh
6、启动nginx、keepalived
systemctl daemon-reload
systemctl enable nginx keepalived
systemctl start nginx keepalived
二、如果启动nginx失败出现以下错误
nginx: [emerg] unknown directive "stream" in /etc/nginx/nginx.conf:18
nginx: configuration file /etc/nginx/nginx.conf test failed
#说明缺少modules模块,要安装modules模块
yum -y install nginx-all-modules.noarch
#检查nginx配置文件是否正确
nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
#然后在启动nginx就没问题了
三、验证nginx+keepalived高可用负载均衡器是否正常工作
1、查看keepalived工作状态——(k8smaser1节点操作)
ip add
1: lo: ,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: ,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:e1:88:76 brd ff:ff:ff:ff:ff:ff
inet 192.168.10.101/24 brd 192.168.10.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.10.244/24 scope global secondary ens33 #可以看到VIP地址已经生成了
valid_lft forever preferred_lft forever
inet6 fe80::726c:ab0c:3c5f:95de/64 scope link tentative noprefixroute dadfailed
valid_lft forever preferred_lft forever
inet6 fe80::92fb:ba59:2bcd:6051/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: docker0: ,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:9d:17:5a:70 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
6: tunl0@NONE: ,UP,LOWER_UP> mtu 1440 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
inet 10.244.93.64/32 brd 10.244.93.64 scope global tunl0
valid_lft forever preferred_lft forever
2、关闭k8smaster1节点Nginx,测试VIP是否漂移到备节点服务器——(k8smaser1节点操作)
systemctl stop nginx.service
pkill nginx
ip add
1: lo: ,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: ,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:e1:88:76 brd ff:ff:ff:ff:ff:ff
inet 192.168.10.101/24 brd 192.168.10.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::726c:ab0c:3c5f:95de/64 scope link tentative noprefixroute dadfailed
valid_lft forever preferred_lft forever
inet6 fe80::92fb:ba59:2bcd:6051/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: docker0: ,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:9d:17:5a:70 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
6: tunl0@NONE: ,UP,LOWER_UP> mtu 1440 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
inet 10.244.93.64/32 brd 10.244.93.64 scope global tunl0
valid_lft forever preferred_lft forever
#已经看不到VIP了
3、在k8smaser2节点查看VIP是否飘过来了——(k8smaser2节点操作)
ip add
1: lo: ,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: ,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:85:60:1b brd ff:ff:ff:ff:ff:ff
inet 192.168.10.102/24 brd 192.168.10.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.10.244/24 scope global secondary ens33 #可以看到VIP已经飘过来了
valid_lft forever preferred_lft forever
inet6 fe80::92fb:ba59:2bcd:6051/64 scope link tentative noprefixroute dadfailed
valid_lft forever preferred_lft forever
inet6 fe80::726c:ab0c:3c5f:95de/64 scope link tentative noprefixroute dadfailed
valid_lft forever preferred_lft forever
inet6 fe80::8c84:a019:e9ba:d8d0/64 scope link tentative noprefixroute dadfailed
valid_lft forever preferred_lft forever
3: docker0: ,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:75:c3:0d:9d brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
6: tunl0@NONE: ,UP,LOWER_UP> mtu 1440 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
inet 10.244.137.64/32 brd 10.244.137.64 scope global tunl0
valid_lft forever preferred_lft forever
4、k8smaster1节点重新启动nginx服务后,VIP又从新漂移绑定到ens33上,而Nginx Backup节点的ens33网卡上的VIP解绑了——(k8smaser1节点操作)
systemctl start nginx
ip add
1: lo: ,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: ,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:e1:88:76 brd ff:ff:ff:ff:ff:ff
inet 192.168.10.101/24 brd 192.168.10.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.10.244/24 scope global secondary ens33 #可以看到VIP地址又飘回来了
valid_lft forever preferred_lft forever
inet6 fe80::726c:ab0c:3c5f:95de/64 scope link tentative noprefixroute dadfailed
valid_lft forever preferred_lft forever
inet6 fe80::92fb:ba59:2bcd:6051/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: docker0: ,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:9d:17:5a:70 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
6: tunl0@NONE: ,UP,LOWER_UP> mtu 1440 qdisc noqueue state UNKNOWN group default qlen 1000
link/ipip 0.0.0.0 brd 0.0.0.0
inet 10.244.93.64/32 brd 10.244.93.64 scope global tunl0
valid_lft forever preferred_lft forever
#集群中任意一台机器访问负载均衡地址出现以下就说明没有问题
curl -k https://192.168.10.244:16443/version
{
"major": "1",
"minor": "20",
"gitVersion": "v1.20.4",
"gitCommit": "e87da0bd6e03ec3fea7933c4b5263d151aafd07c",
"gitTreeState": "clean",
"buildDate": "2021-02-18T16:03:00Z",
"goVersion": "go1.15.8",
"compiler": "gc",
"platform": "linux/amd64"
k8s群集——配置能查看节点显示所有master、node节点的状态
1、查看节点发现只显示node节点——(k8smaser1节点操作)
kubectl get node
NAME STATUS ROLES AGE VERSION
k8snode1 Ready 3d18h v1.20.4
k8snode2 Ready 3d18h v1.20.4
2、配置能查看所有master、node节点的状态——(k8snode1节点操作)
#复制kubelet、kube-proxy安装包到所有主节点
scp -r /opt/kubernetes/bin/* root@192.168.10.101:/opt/kubernetes/bin/
scp -r /opt/kubernetes/bin/* root@192.168.10.102:/opt/kubernetes/bin/
#复制kubelet、kube-proxy的所有配置文件到所有主节点
scp -r /opt/kubernetes/cfg/* root@192.168.10.101:/opt/kubernetes/cfg/
scp -r /opt/kubernetes/cfg/* root@192.168.10.102:/opt/kubernetes/cfg/
#复制kubelet、kube-proxy的service文件到所有主节点
scp -r /usr/lib/systemd/system/{kubelet,kube-proxy}.service root@192.168.10.101:/usr/lib/systemd/system/
scp -r /usr/lib/systemd/system/{kubelet,kube-proxy}.service root@192.168.10.101:/usr/lib/systemd/system/
3、修改kubelet、kube-proxy配置文件中的主机名为k8smaster的主机名——(所有k8smaser节点操作)
#k8smaster1操作
vim /opt/kubernetes/cfg/kubelet.conf
--hostname-override=k8smaster1
vim /opt/kubernetes/cfg/kube-proxy-config.yml
hostnameOverride: k8smaster1
#k8smaster2操作
vim /opt/kubernetes/cfg/kubelet.conf
--hostname-override=k8smaster2
vim /opt/kubernetes/cfg/kube-proxy-config.yml
hostnameOverride: k8smaster2
4、修改所有节点相关配置文件中和apiserver通讯的地址改为集群虚拟漂移VIP地址——(所有k8s节点操作)
#k8smaster1节点操作
#查看配置文件中和apiserver通讯的地址
grep 192.168.10.101 /opt/kubernetes/cfg/*
/opt/kubernetes/cfg/admin.conf: server: https://192.168.10.101:6443
/opt/kubernetes/cfg/bootstrap.kubeconfig: server: https://192.168.10.101:6443
/opt/kubernetes/cfg/kube-controller-manager.kubeconfig: server: https://192.168.10.101:6443
/opt/kubernetes/cfg/kubelet.kubeconfig: server: https://192.168.10.101:6443
/opt/kubernetes/cfg/kube-proxy.kubeconfig: server: https://192.168.10.101:6443
/opt/kubernetes/cfg/kube-scheduler.kubeconfig: server: https://192.168.10.101:6443
grep 192.168.10.101 /root/.kube/config
server: https://192.168.10.101:6443
#替换所有配置文件中的与apiserver通信地址为集群虚拟漂移VIP地址
sed -i 's#192.168.10.101:6443#192.168.10.244:16443#' /opt/kubernetes/cfg/*
sed -i 's#192.168.10.101:6443#192.168.10.244:16443#' /root/.kube/config
#k8smaster2节点操作
#查看配置文件中和apiserver通讯的地址
grep 192.168.10.102 /opt/kubernetes/cfg/*
/opt/kubernetes/cfg/admin.conf: server: https://192.168.10.102:6443
/opt/kubernetes/cfg/bootstrap.kubeconfig: server: https://192.168.10.102:6443
/opt/kubernetes/cfg/kube-controller-manager.kubeconfig: server: https://192.168.10.102:6443
/opt/kubernetes/cfg/kubelet.kubeconfig: server: https://192.168.10.102:6443
/opt/kubernetes/cfg/kube-proxy.kubeconfig: server: https://192.168.10.102:6443
/opt/kubernetes/cfg/kube-scheduler.kubeconfig: server: https://192.168.10.102:6443
grep 192.168.10.102 /root/.kube/config
server: https://192.168.10.102:6443
#替换所有配置文件中的与apiserver通信地址为集群虚拟漂移VIP地址
sed -i 's#192.168.10.102:6443#192.168.10.244:16443#' /opt/kubernetes/cfg/*
sed -i 's#192.168.10.102:6443#192.168.10.244:16443#' /root/.kube/config
#k8snode1节点操作
#查看配置文件中和apiserver通讯的地址
grep 192.168.10.103 /opt/kubernetes/cfg/*
/opt/kubernetes/cfg/bootstrap.kubeconfig: server: https://192.168.10.103:6443
/opt/kubernetes/cfg/kubelet.kubeconfig: server: https://192.168.10.103:6443
/opt/kubernetes/cfg/kube-proxy.kubeconfig: server: https://192.168.10.103:6443
grep 192.168.10.101 /root/.kube/config
server: https://192.168.10.101:6443
#替换所有配置文件中的与apiserver通信地址为集群虚拟漂移VIP地址
sed -i 's#192.168.10.103:6443#192.168.10.244:16443#' /opt/kubernetes/cfg/*
sed -i 's#192.168.10.101:6443#192.168.10.244:16443#' /root/.kube/config
#k8snode2节点操作
#查看配置文件中和apiserver通讯的地址
grep 192.168.10.104 /opt/kubernetes/cfg/*
/opt/kubernetes/cfg/bootstrap.kubeconfig: server: https://192.168.10.104:6443
/opt/kubernetes/cfg/kubelet.kubeconfig: server: https://192.168.10.104:6443
/opt/kubernetes/cfg/kube-proxy.kubeconfig: server: https://192.168.10.104:6443
grep 192.168.10.101 /root/.kube/config
server: https://192.168.10.101:6443
#替换所有配置文件中的与apiserver通信地址为集群虚拟漂移VIP地址
sed -i 's#192.168.10.104:6443#192.168.10.244:16443#' /opt/kubernetes/cfg/*
sed -i 's#192.168.10.101:6443#192.168.10.244:16443#' /root/.kube/config
所有k8smaster节点操作
#启动节点服务
systemctl daemon-reload
systemctl start kubelet kube-proxy
systemctl enable kubelet kube-proxy
5、查看kubelet_kubeconfig客户端发送的申请——(k8smaser1节点操作)
#所有k8smaster节点都可操作
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
node-csr-6zTjsaVSrhuyhIGqsefxzVoZfjklkdiKJFI-MCIDmia 89s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending
node-csr-4zTjsaVSrhuyhIGqsefxzVoZDCNKei-aE2jyTP81Uro 59s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending
7、在所有k8smaster节点给kubelet授权——(所有k8smaster节点操作)
kubectl certificate approve node-csr-6zTjsaVSrhuyhIGqsefxzVoZfjklkdiKJFI-MCIDmia
kubectl certificate approve node-csr-4zTjsaVSrhuyhIGqsefxzVoZDCNKei-aE2jyTP81Uro
**************************************************************k8smaster1节点操作*******************************************************************************
kubectl get node
NAME STATUS ROLES AGE VERSION
k8smaster1 Ready 21h v1.20.4
k8smaster2 Ready 21h v1.20.4
k8snode1 Ready 3d18h v1.20.4
k8snode2 Ready 3d18h v1.20.4
#现在就可以看到所有节点状态了
k8s群集——新增node节点
**************************************************************k8snode1节点操作********************************************************************************
1、这里就省略节点初始化+时间同步+安装docker前面已经都演示过了照前面的做就行了
2、部署k8snode3节点
#拷贝已部署好的Node相关文件到新节点
scp -r /opt/* root@192.168.10.103:/opt/
scp -r /root/.kube root@192.168.10.103:/root/
scp -r /usr/bin/kubectl 192.168.10.103:/usr/bin/
scp -r scp -r /usr/lib/systemd/system/kube* root@192.168.10.103:/usr/lib/systemd/system/
**************************************************************k8snode3节点操作********************************************************************************
rm -rf /opt/kubernetes/ssl/kubelet*
#修改相关配置文件的节点名为k8snode3
vim /opt/kubernetes/cfg/kubelet.conf
--hostname-override=k8snode3
vim /opt/kubernetes/cfg/kube-proxy-config.yml
hostnameOverride: k8snode3
#启动节点服务
systemctl daemon-reload
systemctl start kubelet kube-proxy
systemctl enable kubelet kube-proxy
**************************************************************k8smaster1节点操作*******************************************************************************
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
node-csr-4zTjsaVSrhuyhIGqsefxzVoZDCNKei-aE2jyTP81Uro 89s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending
**************************************************************所有k8smaster节点操作***************************************************************************
kubectl certificate approve node-csr-4zTjsaVSrhuyhIGqsefxzVoZDCNKei-aE2jyTP81Uro
**************************************************************k8smaster1节点操作*******************************************************************************
kubectl get node
NAME STATUS ROLES AGE VERSION
k8smaster1 Ready 21h v1.20.4
k8smaster2 Ready 21h v1.20.4
k8snode1 Ready 3d18h v1.20.4
k8snode2 Ready 3d18h v1.20.4
k8snode3 Ready 1m18s v1.20.4
安装openebs和KubeSphere
安装kubesphere的前提是必须要有k8s群集,k8s群集我们前面已经部署过了,下面开始安装kubesphere
1、检查k8s集群的资源——(k8smaster1节点操作)
kubectl cluster-info
Kubernetes control plane is running at https://192.168.10.244:16443
CoreDNS is running at https://192.168.10.244:16443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8smaster1 Ready 11d v1.20.4
k8smaster2 Ready 11d v1.20.4
k8snode1 Ready 13d v1.20.4
k8snode2 Ready 13d v1.20.4
2、查看k8smaster是否打污点,如果有请先去掉污点,不然后续安装openebs时会出现报错——(所有k8smaster节点)
kubectl describe node k8smaster1 |grep Taint
Taints:
kubectl describe node k8smaster2 |grep Taint
Taints:
3、安装openebs
由于 在已有 Kubernetes 集群之上安装 KubeSphere 需要依赖集群已有的存储类型(StorageClass)
前提条件:
已有 Kubernetes 集群,并安装了 kubectl 或 Helm
Pod 可以被调度到集群的 master 节点(可临时取消 master 节点的 Taint)
关于第二个前提条件,是由于安装 OpenEBS 时它有一个初始化的 Pod 需要在 master 节点启动并创建 PV 给 KubeSphere 的有状态应用挂载。
因此,若您的 master 节点存在 Taint,建议在安装 OpenEBS 之前手动取消 Taint,待 OpenEBS 与 KubeSphere 安装完成后,再对 master 打上 Taint
创建openebs命名空间
kubectl create ns openebs
namespace/openebs created
#下载openebs.yaml文件
wget https://openebs.github.io/charts/openebs-operator.yaml
#修改openebs-operator.yaml
vim openebs-operator.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-hostpath
annotations:
openebs.io/cas-type: local
cas.openebs.io/config: |
- name: StorageType
value: hostpath
- name: BasePath
value: /var/openebs/local #这里可自定义数据落地的位置
provisioner: openebs.io/local
reclaimPolicy: Delete
volumeBindingMode: WaitForFirstConsumer
#查看StorgaeClass
kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
openebs-device openebs.io/local Delete WaitForFirstConsumer false 7m54s
openebs-hostpath openebs.io/local Delete WaitForFirstConsumer false 7m54s
#设置为默认的StorgaeClass(这里先设置,之后安装ceph存储后在更改设置具体哪个为默认的StorgaeClass)
kubectl patch storageclass openebs-hostpath -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
4、扩展知识(在安装完kubesphere后在给master节点打上污点)
#去掉某节点的污点
kubectl taint nodes 节点名 node-role.kubernetes.io/master:NoSchedule-
#添加某节点的污点
kubectl taint nodes 节点名 node-role.kubernetes.io/master=:NoSchedule
5、安装kubespere(最小化安装)
最小化安装最低要求node节点1c/2g
完整安装最低要求node节点4c/8g
k8s群集为1.20.4 kubesphere版本< v3.3.*(我这里安装的为v3.2.1)不然报错版本不兼容
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.3.2/kubesphere-installer.yaml
kubectl apply -f https://github.com/kubesphere/ks-installer/releases/download/v3.3.2/cluster-configuration.yaml
#在开一个终端查看安装日志
kubectl logs -n kubesphere-system $(kubectl get pod -n kubesphere-system -l 'app in (ks-install, ks-installer)' -o jsonpath='{.items[0].metadata.name}') -f
PLAY RECAP *********************************************************************
localhost : ok=33 changed=22 unreachable=0 failed=0 skipped=14 rescued=0 ignored=0
Start installing monitoring
Start installing multicluster
Start installing openpitrix
Start installing network
**************************************************
Waiting for all tasks to be completed ...
task network status is successful (1/4)
task openpitrix status is successful (2/4)
task multicluster status is successful (3/4)
task monitoring status is successful (4/4)
**************************************************
Collecting installation results ...
Retrying (Retry(total=2, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ProtocolError('Connection aborted.', RemoteDisconnected('Remote end closed connection without response'))': /apis/installer.kubesphere.io/v1alpha1/namespaces/kubesphere-system/clusterconfigurations/ks-installer
#####################################################
### Welcome to KubeSphere! ###
#####################################################
Console: http://192.168.10.101:30880 #访问地址
Account: admin #管理账号
Password: P@88w0rd #初始密码
NOTES:
1. After you log into the console, please check the
monitoring status of service components in
"Cluster Management". If any service is not
ready, please wait patiently until all components
are up and running.
2. Please change the default password after login.
#####################################################
https://kubesphere.io 2023-04-11 12:05:47
#####################################################
出现这些就说明kubesphere已经安装好了
访问http://192.168.10.101:30880
Ceph群集——mimic版
Ceph群集主机配置表
| 主机名 | IP地址 | 组件 | 系统 | 配置 |
|---|---|---|---|---|
| ceph-admin | 192.168.10.105 | ceph-deploy、ceph-common | Centos7.9 | 1C/1G |
| ceph-mon-mgr1 | 192.168.10.106 | monitor、manager、ceph、ceph-radowgw | Centos7.9 | 1C/1G |
| ceph-mon-mgr2 | 192.168.10.107 | monitor、manager、ceph、ceph-radowgw | Centos7.9 | 1C/1G |
| ceph-mon-mgr3 | 192.168.10.108 | monitor、manager、ceph、ceph-radowgw | Centos7.9 | 1C/1G |
3个mon=monitor 生产环境至少三个以上(测试可2个)这里是3个monitor节点
2个mgr=manager 生产环境至少两个以上(测试可2个)这里是3个manager节点
Ceph存储群集架构图
 Ceph没有目录的概念,它不是文件系统所以没有目录,只有pool存储池的概念
Ceph没有目录的概念,它不是文件系统所以没有目录,只有pool存储池的概念
RBD:(块存储接口)接入Ceph群集的客户端api服务
ceph-radowgw(RGW):(对象存储接口)接入Ceph群集的客户端api服务
Mentdata(MDS):(文件系统存储接口)接入Ceph群集的客户端api服务
File:文件
DataObject:数据对象(固定大小的对象)
Pool:存储池
PG:归置组、安置组、放置组
RADOS Cluster:多主机的多osd集合称为RADOS群集
Host:主机/各个节点
osd:对象存储(存储块/磁盘)
mon:monitor监视器(集群的元数据服务管理监视器)负责管理整个存储集群的
mgr:manager管理器(主要做周期性的采集数据)专门维护数据查询操作的
Ceph的网络
public_network(主机网络):面向客户端(ceph)提供服务的网络,主要是承载来自客户端传输请求流量的
cluster_network(集群网络):专用于实现集群内部维护传输流量的通道(集群网络/私有网络)
一、初始化群集主机——(所有ceph节点操作)
1、所有节点修改主机名
#192.168.10.105
hostnamectl set-hostname ceph-admin
su
#192.168.10.106
hostnamectl set-hostname ceph-mon-mgr1
su
#192.168.10.107
hostnamectl set-hostname ceph-mon-mgr2
su
#192.168.10.108
hostnamectl set-hostname ceph-mon-mgr3
su
2、关闭防火墙、内核安全机制、swap交换分区
#关闭放火墙
systemctl stop firewalld
systemctl disable firewalld
#关闭内核安全机制
sed -i "s/.*SELINUX=.*/SELINUX=disabled/g" /etc/selinux/config
#关闭swap交换分区
swapoff -a
sed -i '/swap/s/^\(.*\)$/#\1/g' /etc/fstab
3、添加hosts解析可以使用主机名进行访问
cat >> /etc/hosts << EOF
192.168.10.105 ceph-admin
192.168.10.106 ceph-mon-mgr1
192.168.10.107 ceph-mon-mgr2
192.168.10.108 ceph-mon-mgr3
EOF
4、添加配置国内yum源
cd /etc/yum.repos.d/
wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo
mv aliyun.repo aliyun.repo.bak
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
yum clean all
yum makecache
yum update
5、配置时间同步
#安装chrony服务
yum -y install chrony
#启动chronyd服务
systemctl start chronyd
#设置为开机自启动
systemctl enable chronyd
#查看确认时间同步
chronyc sources -v
二、部署Ceph群集
1、部署前期准备安装ceph的国内yum源——(ceph-admin节点操作)

#安装ceph的yum源
cd /etc/yum.repos.d/
rpm - ivh https://mirrors.aliyun.com/ceph/rpm-mimic/el7/noarch/ceph-release-1-1.el7.noarch.rpm
2、创建部署ceph群集的特定用户账号——(所有ceph节点操作)

首先需要在各个节点以root(管理员)的身份创建一个专用于ceph-deploy的特定用户账户,如cephadmin,建议不要使用ceph,并为其设置密码密码为123456
#创建用户并设置密码
useradd cephadmin
echo “123456” | passwd --stdin cephadmin
#确保这些节点上新创建的用户cephadmin都有无密码运行sudo命令的权限
echo "cephadmin ALL = (root) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/cephadmin
chmod 0440 /etc/sudoers.d/cephadmin
[cephadmin@ceph-admin ~]$ sudo -l
匹配 %2$s 上 %1$s 的默认条目:
!visiblepw, always_set_home, match_group_by_gid, always_query_group_plugin, env_reset, env_keep="COLORS DISPLAY HOSTNAME HISTSIZE
KDEDIR LS_COLORS", env_keep+="MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE", env_keep+="LC_COLLATE LC_IDENTIFICATION
LC_MEASUREMENT LC_MESSAGES", env_keep+="LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE", env_keep+="LC_TIME LC_ALL LANGUAGE
LINGUAS _XKB_CHARSET XAUTHORITY", secure_path=/sbin\:/bin\:/usr/sbin\:/usr/bin
用户 cephadmin 可以在 ceph-admin 上运行以下命令:
(root) NOPASSWD: ALL #免密以root的身份运行任何命令
3、配置cephadmin用户基于密钥的ssh免密认证——(ceph-admin节点操作)
ceph-deploy命令不支持运行中途的输入密码,因此必须在管理节点(ceph-admin)上生成ssh密钥的公钥将其分发到ceph群集的各个节点上
#切换为cephadmin用户
su - cephadmin
ssh-keygen -t rsa -P "" #一路回车
#将生成的公钥文件传到各个节点
ssh-copy-id -i .ssh/id_rsa.pub cephadmin@ceph-admin
ssh-copy-id -i .ssh/id_rsa.pub cephadmin@ceph-mon-mgr1
ssh-copy-id -i .ssh/id_rsa.pub cephadmin@ceph-mon-mgr2
ssh-copy-id -i .ssh/id_rsa.pub cephadmin@ceph-mon-mgr3
4、在ceph-admin(管理节点)部署ceph-deploy——(ceph-admin节点操作)
#切换回root用户
exit
#ceph存储群集的部署过程可通过管理节点使用ceph-deploy全程进行,这里首先在管理节点安装ceph-deploy及其依赖的程序包
yum update
yum install ceph-deploy python-setuptools python2-subprocess32
三、部署RADOS存储群集
初始化RADOS集群
1、创建存储群集相关配置文件目录——(ceph-admin节点操作)
#切换为cephadmin用户
su - cephadmin
#在管理节点以cephadmin用户创建集群相关配置文件的目录
mkdir ceph-cluster
cd ceph-cluster
2、给所有monitor节点安装monitor组件
#给所有monitor节点安装monitor组件
ceph-deploy new ceph-admin ceph-mon-mgr1 ceph-mon-mgr2 ceph-mon-mgr3
[cephadmin@ceph-admin ceph-cluster]$ ll
总用量 272
-rw-rw-r-- 1 cephadmin cephadmin 298 4月 4 16:45 ceph.conf #生成的ceph整个集群的配置文件
-rw-rw-r--. 1 cephadmin cephadmin 248063 4月 4 17:01 ceph-deploy-ceph.log #生成的集群部署日志文件
-rw-------. 1 cephadmin cephadmin 73 4月 4 11:34 ceph.mon.keyring #生成的所有monitor之间内部通讯所使用的密钥环
#编辑生成的ceph.conf配置文件配置ceph集群的网络
vim ceph.conf
[global]
fsid = eb271f7f-1ac4-4b71-bd63-12b6ee7b8eec #集群id
public_network = 192.168.10.0/24 #主机网络网段对外网络
cluster_network=192.168.0.0/24 #集群网络自定义网络网段集群内网络
mon_initial_members = ceph-mon-mgr1, ceph-mon-mgr2, ceph-mon-mgr3
mon_host = 192.168.10.106,192.168.10.107,192.168.10.108
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
3、安装ceph群集——(ceph-admin节点操作)
#给各个节点安装ceph程序安装包
ceph-deploy命令能够以远程的方式连入ceph集群的各个节点完成程序包安装等操作
ceph-deploy install ceph-mon-mgr1 ceph-mon-mgr2 ceph-mon-mgr3
#上面这种方式在安装时可能因为是一个节点一个节点部署的,会出现因下载包慢而导致出现的错误,如果这种方式实在不行就使用下面的方式进行部署
4、在各个节点以root用户手动执行如下命令——(所有ceph节点操作)
rpm - ivh https://mirrors.aliyun.com/ceph/rpm-mimic/el7/noarch/ceph-release-1-1.el7.noarch.rpm
yum -y install ceph ceph-radosgw
5、各个节点执行完后回到ceph-admin节点执行如下命令初始化各个节点——(ceph-admin节点操作)
ceph-deploy install --no-adjust-repos ceph-mon-mgr1 ceph-mon-mgr2 ceph-mon-mgr3
--no-adjust-repos:跳过已安装的程序
初始monitor节点并收集所有密钥
1、初始monitor节点并收集所有密钥,这里不需要指定主机,它会自动找集群中的monitor节点——(ceph-admin节点操作)
ceph-deploy mon create-initial
#把配置文件和admin密钥拷贝到ceph群集各个节点,以免每次执行ceph命令时不得不明确指定mon节点 地址
ceph-deploy admin ceph-mon-mgr1 ceph-mon-mgr2 ceph-mon-mgr3
admin:就是一起复制ceph.conf和ceph.client.admin.keyring
2、然后在ceph群集中需要运行ceph命令的节点上以(root)用户的身份设定用户cephadmin能够读——(所有ceph节点操作)取/etc/ceph/ceph.client.admin.keying文件
setfacl -m u:cephadmin:rw /etc/ceph/ceph.client.admin.keyring
#如果没有setfacl命令,可以使用如下命令
cd /etc/ceph/
chown cephadmin:cephadmin ceph.client.admin.keyring
ll /etc/ceph/
总用量 12
-rw-rw----+ 1 cephadmin cephadmin 151 4月 4 14:12 ceph.client.admin.keyring
-rw-r--r-- 1 root root 298 4月 4 17:00 ceph.conf
-rw-r--r--. 1 root root 92 4月 24 2020 rbdmap
-rw-------. 1 root root 0 4月 4 13:54 tmp4iSvjf
-rw------- 1 root root 0 4月 4 16:46 tmpmqgMek
给manager节点配置manager并启动manager进程
1、配置manager节点并启动manager进程——(ceph-admin节点操作)
#安装配置manager并启动
ceph-deploy mgr create ceph-mon-mgr1 ceph-mon-mgr2 ceph-mon-mgr3
#给ceph-admin节点配置ceph命令,使ceph-admin节点能够使用ceph命令
yum -y install ceph-common
#把配置文件和admin密钥给本地节点复制以下并更改属组属主
ceph-deploy admin ceph-admin
#切换会root用户执行如下
setfacl -m u:cephadmin:rw /etc/ceph/ceph.client.admin.keyring
#在切换回cephadmin用户执行如下
[cephadmin@ceph-admin ceph-cluster]$ ceph -s
cluster:
id: eb271f7f-1ac4-4b71-bd63-12b6ee7b8eec
health: HEALTH_WARN
services:
mon: 3 daemons, quorum ceph-mon-mgr1,ceph-mon-mgr2,ceph-mon-mgr3
mgr: ceph-mon-mgr2(active), standbys: ceph-mon-mgr1, ceph-mon-mgr3
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
RADOS存储群集添加osd
1、查看其他节点磁盘——(ceph-admin节点操作)
#列出其他节点上的磁盘,我这里没办法正常显示,显示需要 sudo fdisk -l权限,我们也以到其他节点上使用fdisk -l手动查看一下
[cephadmin@ceph-admin ceph-cluster]$ ceph-deploy disk list ceph-mon-mgr1 ceph-mon-mgr2 ceph-mon-mgr3
[ceph_deploy.conf][DEBUG ] found configuration file at: /home/cephadmin/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /bin/ceph-deploy disk list ceph-mon-mgr1 ceph-mon-mgr2 ceph-mon-mgr3
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] debug : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] subcommand : list
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : .conf.cephdeploy.Conf instance at 0x7ff60f62b248>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] host : ['ceph-mon-mgr1', 'ceph-mon-mgr2', 'ceph-mon-mgr3']
[ceph_deploy.cli][INFO ] func : <function disk at 0x7ff60f5f8a28>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph-mon-mgr1][DEBUG ] connection detected need for sudo
[ceph-mon-mgr1][DEBUG ] connected to host: ceph-mon-mgr1
[ceph-mon-mgr1][DEBUG ] detect platform information from remote host
[ceph-mon-mgr1][DEBUG ] detect machine type
[ceph-mon-mgr1][DEBUG ] find the location of an executable
[ceph-mon-mgr1][INFO ] Running command: sudo fdisk -l
[ceph-mon-mgr2][DEBUG ] connection detected need for sudo
[ceph-mon-mgr2][DEBUG ] connected to host: ceph-mon-mgr2
[ceph-mon-mgr2][DEBUG ] detect platform information from remote host
[ceph-mon-mgr2][DEBUG ] detect machine type
[ceph-mon-mgr2][DEBUG ] find the location of an executable
[ceph-mon-mgr2][INFO ] Running command: sudo fdisk -l
[ceph-mon-mgr3][DEBUG ] connection detected need for sudo
[ceph-mon-mgr3][DEBUG ] connected to host: ceph-mon-mgr3
[ceph-mon-mgr3][DEBUG ] detect platform information from remote host
[ceph-mon-mgr3][DEBUG ] detect machine type
[ceph-mon-mgr3][DEBUG ] find the location of an executable
[ceph-mon-mgr3][INFO ] Running command: sudo fdisk -l
2、查看节点磁盘,存储节点操作——(所有RADOS群集节点操作)
fdisk -l
磁盘 /dev/sda:64.4 GB, 64424509440 字节,125829120 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘标签类型:dos
磁盘标识符:0x000a753a
设备 Boot Start End Blocks Id System
/dev/sda1 * 2048 2099199 1048576 83 Linux
/dev/sda2 2099200 125829119 61864960 8e Linux LVM
磁盘 /dev/sdb:21.5 GB, 21474836480 字节,41943040 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘 /dev/sdc:21.5 GB, 21474836480 字节,41943040 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
可以看到没有挂载使用的磁盘都有什么
**************************************************************ceph-admin节点操作***************************************************************************
#擦除各个节点/dev/sdb盘的数据
ceph-deploy disk zap ceph-mon-mgr1 /dev/sdb
ceph-deploy disk zap ceph-mon-mgr2 /dev/sdb
ceph-deploy disk zap ceph-mon-mgr3 /dev/sdb
#添加osd
ceph-deploy osd create ceph-mon-mgr1 --data /dev/sdb
ceph-deploy osd create ceph-mon-mgr2 --data /dev/sdb
ceph-deploy osd create ceph-mon-mgr3 --data /dev/sdb
#查看列出osd的状态
[cephadmin@ceph-admin ceph-cluster]$ ceph-deploy osd list ceph-mon-mgr1 ceph-mon-mgr2 ceph-mon-mgr3
[ceph_deploy.conf][DEBUG ] found configuration file at: /home/cephadmin/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (2.0.1): /bin/ceph-deploy osd list ceph-mon-mgr1 ceph-mon-mgr2 ceph-mon-mgr3
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] debug : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] subcommand : list
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : .conf.cephdeploy.Conf instance at 0x7f5b4846b368>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] host : ['ceph-mon-mgr1', 'ceph-mon-mgr2', 'ceph-mon-mgr3']
[ceph_deploy.cli][INFO ] func : <function osd at 0x7f5b484b19b0>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph-mon-mgr1][DEBUG ] connection detected need for sudo
[ceph-mon-mgr1][DEBUG ] connected to host: ceph-mon-mgr1
[ceph-mon-mgr1][DEBUG ] detect platform information from remote host
[ceph-mon-mgr1][DEBUG ] detect machine type
[ceph-mon-mgr1][DEBUG ] find the location of an executable
[ceph_deploy.osd][INFO ] Distro info: CentOS Linux 7.9.2009 Core
[ceph_deploy.osd][DEBUG ] Listing disks on ceph-mon-mgr1...
[ceph-mon-mgr1][DEBUG ] find the location of an executable
[ceph-mon-mgr1][INFO ] Running command: sudo /usr/sbin/ceph-volume lvm list
[ceph-mon-mgr1][DEBUG ]
[ceph-mon-mgr1][DEBUG ]
[ceph-mon-mgr1][DEBUG ] ====== osd.0 =======
[ceph-mon-mgr1][DEBUG ]
[ceph-mon-mgr1][DEBUG ] [block] /dev/ceph-4f90b38b-47a1-4ce2-b862-16fb76815d2c/osd-block-b285cfce-98a0-42e7-9510-960f2e9e9aff
[ceph-mon-mgr1][DEBUG ]
[ceph-mon-mgr1][DEBUG ] block device /dev/ceph-4f90b38b-47a1-4ce2-b862-16fb76815d2c/osd-block-b285cfce-98a0-42e7-9510-960f2e9e9aff
[ceph-mon-mgr1][DEBUG ] block uuid c46Ybp-g4wG-hDVS-SZoD-vTO6-PFTG-BwuUPH
[ceph-mon-mgr1][DEBUG ] cephx lockbox secret
[ceph-mon-mgr1][DEBUG ] cluster fsid eb271f7f-1ac4-4b71-bd63-12b6ee7b8eec
[ceph-mon-mgr1][DEBUG ] cluster name ceph
[ceph-mon-mgr1][DEBUG ] crush device class None
[ceph-mon-mgr1][DEBUG ] encrypted 0
[ceph-mon-mgr1][DEBUG ] osd fsid b285cfce-98a0-42e7-9510-960f2e9e9aff
[ceph-mon-mgr1][DEBUG ] osd id 0
[ceph-mon-mgr1][DEBUG ] type block
[ceph-mon-mgr1][DEBUG ] vdo 0
[ceph-mon-mgr1][DEBUG ] devices /dev/sdb
[ceph-mon-mgr2][DEBUG ] connection detected need for sudo
[ceph-mon-mgr2][DEBUG ] connected to host: ceph-mon-mgr2
[ceph-mon-mgr2][DEBUG ] detect platform information from remote host
[ceph-mon-mgr2][DEBUG ] detect machine type
[ceph-mon-mgr2][DEBUG ] find the location of an executable
[ceph_deploy.osd][INFO ] Distro info: CentOS Linux 7.9.2009 Core
[ceph_deploy.osd][DEBUG ] Listing disks on ceph-mon-mgr2...
[ceph-mon-mgr2][DEBUG ] find the location of an executable
[ceph-mon-mgr2][INFO ] Running command: sudo /usr/sbin/ceph-volume lvm list
[ceph-mon-mgr2][DEBUG ]
[ceph-mon-mgr2][DEBUG ]
[ceph-mon-mgr2][DEBUG ] ====== osd.1 =======
[ceph-mon-mgr2][DEBUG ]
[ceph-mon-mgr2][DEBUG ] [block] /dev/ceph-22584a19-41a3-4d56-a304-7f7770db9168/osd-block-c8cbcd3a-45bf-405b-aaa7-f09495f27915
[ceph-mon-mgr2][DEBUG ]
[ceph-mon-mgr2][DEBUG ] block device /dev/ceph-22584a19-41a3-4d56-a304-7f7770db9168/osd-block-c8cbcd3a-45bf-405b-aaa7-f09495f27915
[ceph-mon-mgr2][DEBUG ] block uuid iT0rHg-XWqb-jabr-M3x2-YsB8-JeRj-uHHfEE
[ceph-mon-mgr2][DEBUG ] cephx lockbox secret
[ceph-mon-mgr2][DEBUG ] cluster fsid eb271f7f-1ac4-4b71-bd63-12b6ee7b8eec
[ceph-mon-mgr2][DEBUG ] cluster name ceph
[ceph-mon-mgr2][DEBUG ] crush device class None
[ceph-mon-mgr2][DEBUG ] encrypted 0
[ceph-mon-mgr2][DEBUG ] osd fsid c8cbcd3a-45bf-405b-aaa7-f09495f27915
[ceph-mon-mgr2][DEBUG ] osd id 1
[ceph-mon-mgr2][DEBUG ] type block
[ceph-mon-mgr2][DEBUG ] vdo 0
[ceph-mon-mgr2][DEBUG ] devices /dev/sdb
[ceph-mon-mgr3][DEBUG ] connection detected need for sudo
[ceph-mon-mgr3][DEBUG ] connected to host: ceph-mon-mgr3
[ceph-mon-mgr3][DEBUG ] detect platform information from remote host
[ceph-mon-mgr3][DEBUG ] detect machine type
[ceph-mon-mgr3][DEBUG ] find the location of an executable
[ceph_deploy.osd][INFO ] Distro info: CentOS Linux 7.9.2009 Core
[ceph_deploy.osd][DEBUG ] Listing disks on ceph-mon-mgr3...
[ceph-mon-mgr3][DEBUG ] find the location of an executable
[ceph-mon-mgr3][INFO ] Running command: sudo /usr/sbin/ceph-volume lvm list
[ceph-mon-mgr3][DEBUG ]
[ceph-mon-mgr3][DEBUG ]
[ceph-mon-mgr3][DEBUG ] ====== osd.2 =======
[ceph-mon-mgr3][DEBUG ]
[ceph-mon-mgr3][DEBUG ] [block] /dev/ceph-eeb2563e-ab88-400b-93a0-029ce893f639/osd-block-bb99c029-3278-4423-a6c5-bf7305928931
[ceph-mon-mgr3][DEBUG ]
[ceph-mon-mgr3][DEBUG ] block device /dev/ceph-eeb2563e-ab88-400b-93a0-029ce893f639/osd-block-bb99c029-3278-4423-a6c5-bf7305928931
[ceph-mon-mgr3][DEBUG ] block uuid iShoJ6-QI6t-m40J-QcHM-DNA8-6gVw-rcHVUB
[ceph-mon-mgr3][DEBUG ] cephx lockbox secret
[ceph-mon-mgr3][DEBUG ] cluster fsid eb271f7f-1ac4-4b71-bd63-12b6ee7b8eec
[ceph-mon-mgr3][DEBUG ] cluster name ceph
[ceph-mon-mgr3][DEBUG ] crush device class None
[ceph-mon-mgr3][DEBUG ] encrypted 0
[ceph-mon-mgr3][DEBUG ] osd fsid bb99c029-3278-4423-a6c5-bf7305928931
[ceph-mon-mgr3][DEBUG ] osd id 2
[ceph-mon-mgr3][DEBUG ] type block
[ceph-mon-mgr3][DEBUG ] vdo 0
[ceph-mon-mgr3][DEBUG ] devices /dev/sdb
[cephadmin@ceph-admin ceph-cluster]$ ceph -s
cluster:
id: eb271f7f-1ac4-4b71-bd63-12b6ee7b8eec
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-mon-mgr1,ceph-mon-mgr2,ceph-mon-mgr3
mgr: ceph-mon-mgr2(active), standbys: ceph-mon-mgr1, ceph-mon-mgr3
osd: 3 osds: 3 up, 3 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs:
四、Ceph存储集群的访问接口
ceph块设备接口(rbd)

对象存储rbd既是对象存储也是块存储还是文件系统存储,后面和K8s对接时就是使用rbd对接的
这里创建rbd演示是为了让大家更好理解rbd是怎样工作的。
客户端基于librdb库即可将RADOS存储集群用作块设备,不过用于rbd的存储池需要实现启用rbd功能并进行初始化,如下创建一个名为test_pool的存储池,在启动rbd功能后对其进行初始化
存取数据时,客户端必须首先连接至RADOS集群上某存储池,然后根据对象名称由相关的CRUSH规则完成数据对象寻址,这里首先创建一个用于测试的存储池test_pool,并设定其pg数量为64个
计算 PG数的方法
计算正确的 PG 数是构建一个企业级的 Ceph 存储集群中至关重要的一步。因为 PG在一定程度上能够提高或者影响存储性能。
计算 Ceph 集群中 PG 数的公式如下:
PG 总数= (OSD 总数 100) /最大副本数
结果必须舍入到最接近2的N次幕的值(也就是转换成2进制看是2的几次方幂)。比如:如果 Ceph 集群有 160个 OSD 且副本数是3 ,这样根据公式计算得到的 PG 总数是 5333.3 ,因此舍入这个值到最接近的2的N次幕的结果就是 8192个 PG。
我们还应该计算 Ceph 集群中每一个池中的 PG 总数 计算公式如下:
PG 总数= ((OSD 总数 100) /最大副本数) /池数
同样使用前面的例子: OSD 总数是 160 ,副本数是3 ,池总数是3。 根据上面这个公式,计算得到每个池的 PG 总数应该是 1777.7 ,最后舍入到 2的N次幕(也就是转换成2进制看是2的几次方幂)得到结果为每个池 2048个PG。平衡每个池中的 PG 数和每个 OSD 中的 PG 数对于降低 OSD 的方差、避免速度缓慢的恢复进程是相当重要的。
1、切换到root用户执行如下命令查看主机是否支持rbd——(RADOS群集的各个节点/存储节点操作)
modprobe rbd
lsmod | grep rbd
rbd 83733 0
libceph 314775 1 rbd
2、创建存储池
#切换到cephadmin用户
[root@ceph-admin ~]# su - cephadmin
上一次登录:四 4月 6 16:02:27 CST 2023pts/0 上
[cephadmin@ceph-admin ~]$ cd ceph-cluster/
ceph osd pool create test_pool 64 #64是pg的数量
pool 'test_pool' created
ceph -s
cluster:
id: eb271f7f-1ac4-4b71-bd63-12b6ee7b8eec
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-mon-mgr1,ceph-mon-mgr2,ceph-mon-mgr3
mgr: ceph-mon-mgr2(active), standbys: ceph-mon-mgr3, ceph-mon-mgr1
osd: 3 osds: 3 up, 3 in
data:
pools: 1 pools, 64 pgs
objects: 16 objects, 14 MiB
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs: 64 active+clean
3、启用rbd功能并对rbd进行初始化
#启用rbd功能
ceph osd pool application enable 池的名字 rbd
#对rbd功能进行初始化
rbd pool init -p 池的名字
#列出存储池
[cephadmin@ceph-admin ceph-cluster]$ ceph osd pool ls
test_pool
[root@ceph-admin test_pool_img1]# ceph osd lspools
1 test_pool
[cephadmin@ceph-admin ceph-cluster]$ ceph osd pool application enable test_pool rbd #test_pool启用rbd的功能
enabled application 'rbd' on pool 'test_pool'
[cephadmin@ceph-admin ceph-cluster]$ rbd pool init -p test_pool #初始化rbd功能
注意:rbd存储池并不能直接用于块设备,需要事先在其中按需创建映像,并把映像文件作为块设备使用,
rbd命令可用于创建、查看、删除块设备相应的映像(image),以及克隆映像,创建快照、将映像回滚到快照和查看快照等管理操作,
4、创建(image)映像块
#创建一个名为test_pool_img1的映像
rbd create test_pool_img1 --size 1024 --pool test_pool #在test_pool池中创建一个名为test_pool_img1,大小为1024Mb的映像(image)
rbd --image test_pool_img1 --pool test_pool info #查看rbd映像的相关信息
rbd image 'test_pool_img1':
size 1 GiB in 256 objects
order 22 (4 MiB objects)
id: 281486b8b4567
block_name_prefix: rbd_data.281486b8b4567
format: 2
features: layering
op_features:
flags:
create_timestamp: Mon Apr 10 10:17:50 2023
#在客户端(ceph)主机上,用户通过内核级的rbd驱动识别相关的设备,即可对其进行分区,创建文件系统并挂载使用
#映射映像块设备到自己机器
rbd feature disable test_pool_img1 object-map fast-diff deep-flatten --pool test_pool #需禁用,否则可能挂载不了
#出现如下错误,有三种解决办法
[cephadmin@ceph-admin ceph-cluster]$ rbd map test_pool_img1 --pool test_pool
rbd: failed to set udev buffer size: (1) Operation not permitted
rbd: sysfs write failed
In some cases useful info is found in syslog - try "dmesg | tail".
rbd: map failed: (13) Permission denied
#请访问以下地址:
https://blog.csdn.net/styshoo/article/details/60863041
https://www.cnblogs.com/sisimi/p/7761179.html
#也可能是当前用户没有权限执行,切换到root用户在执行就可以了
[cephadmin@ceph-admin ~]$ exit
登出
rbd map test_pool_img1 --pool test_pool
/dev/rbd0
ls /dev/rbd
rbd/ rbd0
可以看到test_pool_img1映像块已经映射到本机上面生成为/dev/rbd0了,接下来我们就可以把/dev/rbd0挂载到本机的某个目录上面了
5、把创建好的rbd的(image)挂载使用
#创建挂载目录
mkdir -p /home/cephadmin/mnt/test_pool_img1
mkfs -t xfs /dev/rbd0 #修改文件格式为xfs的
[root@ceph-admin dev]# lsblk -f
NAME FSTYPE LABEL UUID MOUNTPOINT
sda
├─sda1 xfs f330f36a-cb9d-4b3f-9d82-51a30672bf6c /boot
└─sda2 LVM2_member cSad2F-JQFr-Sowc-9K84-ekP9-p45u-KmOAE0
├─centos-root xfs 22477e9c-98e5-4fd5-b191-e49eecac5004 /
├─centos-swap swap cc6f699d-fe76-4f5e-95cd-4e0258ef252e
└─centos-home xfs cbaadd22-2efc-4687-b407-260fcaeae700 /home
sdb
sdc
sr0 iso9660 CentOS 7 x86_64 2020-11-04-11-36-43-00
rbd0 xfs 16c292d8-d7ed-483b-bf97-77e15a5cc5b2
mount /dev/rbd0 /home/cephadmin/mnt/test_pool_img1/
[root@ceph-admin ~]# cd /home/cephadmin/mnt/test_pool_img1/
[root@ceph-admin test_pool_img1]# ls
[root@ceph-admin test_pool_img1]# mkdir aaa
[root@ceph-admin test_pool_img1]# ls
aaa
这样我们就可以创建、删除、存储数据了
K8s群集对接ceph存储
基于StorageClass动态生成pv和pvc绑定
一、k8s各个节点配置ceph——(ceph-admin节点操作)
1、各个节点安装ceph-common、复制ceph的repo文件和配置文件到k8s各个节点
#让k8s各个节点都能执行ceph和rbd命令
scp -r ceph.repo 192.168.10.101:/etc/yum.repos.d/
scp -r ceph.repo 192.168.10.102:/etc/yum.repos.d/
scp -r ceph.repo 192.168.10.103:/etc/yum.repos.d/
scp -r ceph.repo 192.168.10.104:/etc/yum.repos.d/
scp -r /etc/ceph/* 192.168.10.101:/etc/ceph/
scp -r /etc/ceph/* 192.168.10.102:/etc/ceph/
scp -r /etc/ceph/* 192.168.10.103:/etc/ceph/
scp -r /etc/ceph/* 192.168.10.104:/etc/ceph/
k8s所有节点操作安装ceph-common——(k8s集群所有节点操作)
#安装ceph-common
yum -y install ceph-common
这样k8s节点就能调用使用ceph命令了
2、在ceph-admin(ceph-deply)节点创建新的池、归置组(pg)——(ceph-admin节点操作)
#切换到cephadmin用户
[root@ceph-admin ~]# su - cephadmin
上一次登录:一 4月 10 10:16:30 CST 2023pts/0 上
#切换到ceph-cluster目录下
[cephadmin@ceph-admin ~]$ cd ceph-cluster/
#创建一个名为k8s_pool的池pg暂时设置为128
ceph osd pool create k8s_pool 128
pool 'k8s_pool' created
#初始化k8s_pool池
rbd pool init -p k8s_pool
#查看池可看现在有两个池,一个是之前创建的test_pool,一个是现在创建的
ceph osd lspools
1 test_pool
2 k8s_pool
注意:为 Kubernetes 和 ceph-csi 创建一个新用户k8s_pool_admin,执行以下命令并 记录生成的密钥:(这里生成密钥的命令因ceph版本问题会有差异我这里是m版,m、L版可以使用这个命令生成)
ceph auth get-or-create client.用户名 mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=pool名' -o ceph.client.k8s_pool_admin.keyring
3、创建新用户并生成用户密钥
#创建k8s_pool_admin用户,并生成密钥
ceph auth get-or-create client.k8s_pool_admin mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=k8s_pool' -o ceph.client.k8s_pool_admin.keyring
L版之后的请尝试使用以下命令
ceph auth get-or-create client.用户名 mon 'profile rbd' osd 'profile rbd pool=pool名' mgr 'profile rbd pool=pool名'
[client.kubernetes]
key = AQD9o0Fd6hQRChAAt7fMaSZXduT3NWEqylNpmg==
#[cephadmin@ceph-admin ceph-cluster]$ ceph auth get-key client.k8s_pool_admin | base64
#QVFEN0NEWmtHcFlhRlJBQXJaVEhEbXhEVG0wOFJOOUI2VlJwMmc9PQ==
#查看k8s_pool_admin用户密钥及相关信息
[cephadmin@ceph-admin ceph-cluster]$ ceph auth get client.k8s_pool_admin
exported keyring for client.k8s_pool_admin
[client.k8s_pool_admin]
key = AQD7CDZkGpYaFRAArZTHDmxDTm08RN9B6VRp2g==
caps mon = "allow r"
caps osd = "allow class-read object_prefix rbd_children, allow rwx pool=k8s_pool"
4、生成ceph-csi配置映射
ceph-csi 需要一个存储在 k8s 中的 ConfigMap 对象来定义 Ceph 集群的 Ceph 监视器地址。收集两个 Ceph 集群 唯一的 FSID 和监视器地址
[cephadmin@ceph-admin ceph-cluster]$ ceph mon dump
dumped monmap epoch 1
epoch 1
fsid eb271f7f-1ac4-4b71-bd63-12b6ee7b8eec
last_changed 2023-04-04 13:54:45.779492
created 2023-04-04 13:54:45.779492
0: 192.168.10.106:6789/0 mon.ceph-mon-mgr1
1: 192.168.10.107:6789/0 mon.ceph-mon-mgr2
2: 192.168.10.108:6789/0 mon.ceph-mon-mgr3
二、配置ceph-csi相关的ConfigMap文件(k8smaster1节点操作)
1、编辑生成一个以下示例的 csi-config-map.yaml 文件,替换其中 “clusterID”的 fsid 和“监视器”的监视器地址
cat < csi-config-map.yaml
---
apiVersion: v1
kind: ConfigMap
data:
config.json: |-
[
{
"clusterID": "eb271f7f-1ac4-4b71-bd63-12b6ee7b8eec",
"monitors": [
"192.168.10.106:6789",
"192.168.10.107:6789",
"192.168.10.108:6789"
]
}
]
metadata:
name: ceph-csi-config
EOF
kubectl apply -f csi-config-map.yaml
kubectl get cm ceph-csi-config
NAME DATA AGE
ceph-csi-config 1 88s
最新版本的 ceph-csi 还需要一个额外的 ConfigMap 对象来 定义密钥管理服务 (KMS) 提供程序详细信息。如果未设置 KMS,请将 CSI-KMS-config-map.yaml 文件中的空配置或参考示例 在 https://github.com/ceph/ceph-csi/tree/master/examples/kms
2、创建KMS的ConfigMap
cat < csi-kms-config-map.yaml
---
apiVersion: v1
kind: ConfigMap
data:
config.json: |-
{
"vault-test": {
"encryptionKMSType": "vault",
"vaultAddress": "http://vault.default.svc.cluster.local:8200",
"vaultAuthPath": "/v1/auth/kubernetes/login",
"vaultRole": "csi-kubernetes",
"vaultBackend": "kv-v2",
"vaultDestroyKeys": "true",
"vaultPassphraseRoot": "/v1/secret",
"vaultPassphrasePath": "ceph-csi/",
"vaultCAVerify": "false"
}
}
metadata:
name: ceph-csi-encryption-kms-config
EOF
[root@k8smaster1 ~]# kubectl apply -f csi-kms-config-map.yaml
configmap/ceph-csi-encryption-kms-config created
最新版本的 ceph-csi 还需要另一个 ConfigMap 对象 定义要添加到 CSI 容器内的 ceph.conf 文件的 Ceph 配置
3、配置添加到容器内的ceph.conf文件的ceph的ConfigMap
cat < ceph-config-map.yaml
---
apiVersion: v1
kind: ConfigMap
data:
ceph.conf: |
[global]
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
# keyring is a required key and its value should be empty
keyring: |
metadata:
name: ceph-config
EOF
[root@k8smaster1 ~]# kubectl apply -f ceph-config-map.yaml
configmap/ceph-config created
[root@k8smaster1 ~]# kubectl get cm
NAME DATA AGE
ceph-config 2 11s
ceph-csi-config 1 36m
ceph-csi-encryption-kms-config 1 85s
kube-root-ca.crt 1 15d
4、生成 CEPH-CSI CEPHX 秘密
Ceph-CSI 需要 Cephx 凭证才能与 Ceph 通信 簇。生成一个类似于以下示例的 csi-rbd-secret.yaml 文件, 使用新创建的 k8s_pool_admin 用户 ID 和 cephx 密钥
cat < csi-rbd-secret.yaml
---
apiVersion: v1
kind: Secret
metadata:
name: csi-rbd-secret
namespace: default
stringData:
userID: k8s_pool_admin
userKey: AQD7CDZkGpYaFRAArZTHDmxDTm08RN9B6VRp2g==
EOF
[root@k8smaster1 ~]# kubectl apply -f csi-rbd-secret.yaml
secret/csi-rbd-secret created
[root@k8smaster1 ~]# kubectl get secret csi-rbd-secret
NAME TYPE DATA AGE
csi-rbd-secret Opaque 2 30s
5、配置 CEPH-CSI 插件
创建所需的 ServiceAccount 和 RBAC ClusterRole/ClusterRoleBinding Kubernetes 对象。这些对象不一定需要自定义 您的 Kubernetes 环境,因此可以从 ceph-csi 部署 YAML 中按原样使用
特别提醒:一定要先把yaml文件下载下来,修改文件中镜像地址,如果不修改会出现镜像拉取不下来的问题,因为文件中默认的镜像地址为国外的地址,后面会有提示国内的镜像地址
kubectl apply -f https://raw.githubusercontent.com/ceph/ceph-csi/master/deploy/rbd/kubernetes/csi-provisioner-rbac.yaml
kubectl apply -f https://raw.githubusercontent.com/ceph/ceph-csi/master/deploy/rbd/kubernetes/csi-nodeplugin-rbac.yaml
最后,创建 ceph-csi 配置器和节点插件。随着 Ceph-CSI 容器发布版本的可能例外,这些对象确实如此 不一定需要针对您的 Kubernetes 环境进行定制,并且 因此,可以从 ceph-csi 部署 YAML 中按原样使用
6、下载修改ceph-csi配置器和节点插件文件
#下载到本地
wget https://raw.githubusercontent.com/ceph/ceph-csi/master/deploy/rbd/kubernetes/csi-rbdplugin-provisioner.yaml
wget https://raw.githubusercontent.com/ceph/ceph-csi/master/deploy/rbd/kubernetes/csi-rbdplugin.yaml
#编辑下载到本地的yaml文件
vim csi-rbdplugin-provisioner.yaml
image: registry.k8s.io/sig-storage/csi-provisioner:v3.3.0
image: registry.k8s.io/sig-storage/csi-snapshotter:v6.1.0
image: registry.k8s.io/sig-storage/csi-attacher:v4.0.0
image: registry.k8s.io/sig-storage/csi-resizer:v1.6.0
vim csi-rbdplugin.yaml
image: registry.k8s.io/sig-storage/csi-node-driver-registrar:v2.6.2
把其中镜像地址以:registry.k8s.io/sig-storage/开头的地址
替换为以:registry.aliyuncs.com/google_containers/开的的地址
也就是国内阿里云的镜像地址后面的版本号不变
[root@k8smaster1 ~]# kubectl apply -f csi-rbdplugin-provisioner.yaml
service/csi-rbdplugin-provisioner created
deployment.apps/csi-rbdplugin-provisioner created
[root@k8smaster1 ~]# kubectl apply -f csi-rbdplugin.yaml
daemonset.apps/csi-rbdplugin created
service/csi-metrics-rbdplugin created
三、使用 CEPH 块设备——创建存储类
Kubernetes StorageClass 定义了一类存储。可以创建多个 StorageClass 对象以映射到不同的服务质量级别(即 NVMe 与基于 HDD 的池相比)和功能。
1、创建一个映射到上面创建的 k8s_pool 池的 ceph-csi StorageClass,可以在确保 “clusterID” 属性与 Ceph 集群的 fsid 匹配
cat < csi-rbd-sc.yaml
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: csi-rbd-sc
provisioner: rbd.csi.ceph.com
parameters:
clusterID: eb271f7f-1ac4-4b71-bd63-12b6ee7b8eec
pool: k8s_pool
imageFeatures: layering
csi.storage.k8s.io/provisioner-secret-name: csi-rbd-secret
csi.storage.k8s.io/provisioner-secret-namespace: default
csi.storage.k8s.io/controller-expand-secret-name: csi-rbd-secret
csi.storage.k8s.io/controller-expand-secret-namespace: default
csi.storage.k8s.io/node-stage-secret-name: csi-rbd-secret
csi.storage.k8s.io/node-stage-secret-namespace: default
reclaimPolicy: Delete
allowVolumeExpansion: true #允许容量扩展
mountOptions:
- discard
EOF
#请注意,在 Kubernetes v1.14 和 v1.15 中,卷扩展功能处于 alpha 状态 状态和需要启用 ExpandCSIVolumes 功能门。
kubectl apply -f csi-rbd-sc.yaml
[root@k8smaster1 ~]# kubectl apply -f csi-rbd-sc.yaml
storageclass.storage.k8s.io/csi-rbd-sc created
[root@k8smaster1 ~]# kubectl apply -f csi-rbd-sc.yaml
storageclass.storage.k8s.io/csi-rbd-sc configured
[root@k8smaster1 ~]# kubectl get storageclass.storage.k8s.io/csi-rbd-sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
csi-rbd-sc rbd.csi.ceph.com Delete Immediate false 7m17s
[root@k8smaster1 ~]# kubectl get storageclass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
csi-rbd-sc rbd.csi.ceph.com Delete Immediate false 7m31s
openebs-device openebs.io/local Delete WaitForFirstConsumer false 43h
openebs-hostpath (default) openebs.io/local Delete WaitForFirstConsumer false 43h
四、使用StorageClass (最终方式)
Storage Class的作用
简单来说,storage配置了要访问ceph RBD的IP/Port、用户名、keyring、pool,等信息,我们不需要提前创建image;当用户创建一个PVC时,k8s查找是否有符合PVC请求的storage class类型,如果有,则依次执行如下操作:
1.到ceph集群上创建image
2.创建一个PV,名字为pvc-xx-xxx-xxx,大小pvc请求的storage。
3.将上面的PV与PVC绑定,格式化后挂到容器中
通过这种方式管理员只要创建好storage class就行了,后面的事情用户自己就可以搞定了。如果想要防止资源被耗尽,可以设置一下Resource Quota。
当pod需要一个卷时,直接通过PVC声明,就可以根据需求创建符合要求的持久卷。
一、创建持久卷声明(StorageClass)——(k8smaster1节点操作)
PersistentVolumeClaim是用户对抽象存储资源的请求。 然后,PersistentVolumeClaim将与Pod资源相关联,以 预配一个持久卷,该卷将由 Ceph 块映像提供支持。 可以包括可选的卷模式,以便在挂载的文件系统之间进行选择 (默认)或基于原始块设备的卷。
使用 ceph-csi,为 volumeMode 指定文件系统可以同时支持 ReadWriteOnce 和 ReadOnlyMany accessMode 声明,为 volumeMode 指定 Block 可以支持 ReadWriteOnce、ReadWriteMany 和 ReadOnlyMany accessMode 声明。
1、创建一个基于块的 PersistentVolumeClaim,该声明利用 上面创建的基于 ceph-csi 的 StorageClass,以下 YAML 可以是 用于从 CSI-RBD-SC StorageClass 请求原始块存储
cat < raw-block-pvc.yaml
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: raw-block-pvc
spec:
accessModes:
- ReadWriteOnce
volumeMode: Block #块
resources:
requests:
storage: 1Gi
storageClassName: csi-rbd-sc
EOF
kubectl apply -f raw-block-pvc.yaml
[root@k8smaster1 ceph-csi]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
raw-block-pvc Pending csi-rbd-sc 33s
下面演示了将上述 PersistentVolumeClaim 作为原始块设备绑定到 Pod 资源的示例
cat < raw-block-pod.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: pod-with-raw-block-volume
spec:
containers:
- name: fc-container
image: fedora:26
command: ["/bin/sh", "-c"]
args: ["tail -f /dev/null"]
volumeDevices:
- name: data
devicePath: /dev/xvda
volumes:
- name: data
persistentVolumeClaim:
claimName: raw-block-pvc
EOF
kubectl apply -f raw-block-pod.yaml
2、要创建利用上面创建的基于 ceph-csi 的 StorageClass 的基于文件系统的 PersistentVolumeClaim,可以使用以下 YAML 来 从 CSI-RBD-SC 存储类请求挂载的文件系统(由 RBD 映像支持)
cat < pvc.yaml
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rbd-pvc
spec:
accessModes:
- ReadWriteOnce
volumeMode: Filesystem #文件系统
resources:
requests:
storage: 1Gi
storageClassName: csi-rbd-sc
EOF
kubectl apply -f pvc.yaml
下面演示了将上述 PersistentVolumeClaim 作为挂载文件系统绑定到 Pod 资源的示例
cat < pod.yaml
---
apiVersion: v1
kind: Pod
metadata:
name: csi-rbd-demo-pod
spec:
containers:
- name: web-server
image: nginx
volumeMounts:
- name: mypvc
mountPath: /var/lib/www/html
volumes:
- name: mypvc
persistentVolumeClaim:
claimName: rbd-pvc
readOnly: false
EOF
kubectl apply -f pod.yaml
3、验证pv有没有引用成功
[root@k8smaster1 ceph-csi]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
raw-block-pvc Bound pvc-22cdcfb0-4c5f-4701-a866-0ac6389e8e9a 1Gi RWO csi-rbd-sc 44h
rbd-pvc Bound pvc-093a0273-8a51-4e9c-be20-96626d5db440 1Gi RWO csi-rbd-sc 44h
#可以看到pvc状态为Bound说明pvc自动创建并调用pv成功了
#查看pv可以看到pv被哪个pvc调用了
[root@k8smaster1 ceph-csi]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-093a0273-8a51-4e9c-be20-96626d5db440 1Gi RWO Delete Bound default/rbd-pvc csi-rbd-sc 41h
pvc-1102bacd-e2b5-47d5-845e-7bddba37a2de 20Gi RWO Delete Bound kubesphere-monitoring-system/prometheus-k8s-db-prometheus-k8s-0 openebs-hostpath 2d22h
pvc-22cdcfb0-4c5f-4701-a866-0ac6389e8e9a 1Gi RWO Delete Bound default/raw-block-pvc csi-rbd-sc 41h
pvc-a00fdbc9-0acc-40ca-842d-54a09843f312 20Gi RWO Delete Bound kubesphere-monitoring-system/prometheus-k8s-db-prometheus-k8s-1 openebs-hostpath 2d22h
4、验证节点上是否有rbd的产生并查看容器挂载到宿主机的位置
#查看容器调度到哪个节点上面了
[root@k8smaster1 ceph-csi]# kubectl get pods -n default -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
csi-rbd-demo-pod 1/1 Running 0 43h 10.244.185.217 k8snode2
csi-rbdplugin-22tp9 3/3 Running 0 42h 192.168.10.104 k8snode2
csi-rbdplugin-cklgk 3/3 Running 0 42h 192.168.10.103 k8snode1
csi-rbdplugin-provisioner-79565c5f56-8tm2g 7/7 Running 31 40h 10.244.185.216 k8snode2
csi-rbdplugin-provisioner-79565c5f56-dnr2l 7/7 Running 27 40h 10.244.249.24 k8snode1
pod-with-raw-block-volume 1/1 Running 0 43h 10.244.249.25 k8snode1
#以我们上面创建的文件系统的存储为例,就是csi-rbd-demo-pod这个容器调用的存储
#进入到csi-rbd-demo-pod的容器中
[root@k8smaster1 ceph-csi]# kubectl exec -it csi-rbd-demo-pod -n default /bin/bash
kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl exec [POD] -- [COMMAND] instead.
root@csi-rbd-demo-pod:/#
root@csi-rbd-demo-pod:/# df -lhT
Filesystem Type Size Used Avail Use% Mounted on
overlay overlay 39G 9.8G 29G 26% /
tmpfs tmpfs 64M 0 64M 0% /dev
tmpfs tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
/dev/mapper/centos-root xfs 39G 9.8G 29G 26% /etc/hosts
shm tmpfs 64M 0 64M 0% /dev/shm
/dev/rbd0 ext4 976M 2.6M 958M 1% /var/lib/www/html #可以看到这个目录挂载到/dev/rbd0下面了
tmpfs tmpfs 2.0G 12K 2.0G 1% /run/secrets/kubernetes.io/serviceaccount
tmpfs tmpfs 2.0G 0 2.0G 0% /proc/acpi
tmpfs tmpfs 2.0G 0 2.0G 0% /proc/scsi
tmpfs tmpfs 2.0G 0 2.0G 0% /sys/firmware
#生成一个文件
root@csi-rbd-demo-pod:/var/lib/www/html# echo '1111111111111' > 111.txt
root@csi-rbd-demo-pod:/var/lib/www/html# ls
111.txt lost+found
#到csi-rbd-demo-pod这个pod的调度到的节点也就是k8snode2节点查看有没有/dev/rbd0
[root@k8snode2 ~]# df -lhT |grep rbd
tmpfs tmpfs 2.0G 12K 2.0G 1% /var/lib/kubelet/pods/3c3a7fe5-e63a-435b-8490-d3df67d592b4/volumes/kubernetes.io~secret/rbd-csi-nodeplugin-token-btq6l
tmpfs tmpfs 2.0G 12K 2.0G 1% /var/lib/kubelet/pods/29c57443-bb78-44dd-99ed-9b00075d3bce/volumes/kubernetes.io~secret/rbd-csi-provisioner-token-m9fq6
/dev/rbd0 ext4 976M 2.6M 958M 1% /var/lib/kubelet/pods/2e54f5fd-c165-4635-94b8-b76f829a1ee5/volumes/kubernetes.io~csi/pvc-093a0273-8a51-4e9c-be20-96626d5db440/mount
#宿主机上产生的/dev/rbd0/这磁盘和我们之前演示的创建rbd的生成原理是一样的,这里只是把所有步骤都自动化了,包括我们这个映像(image)挂载,如果这个节点挂掉这个image(映像)也会随着pod调度到其他节点,存储不会消失的。(仅个人看法,如果有错误请大佬们指正)
#可以看到有一个/dev/rbd0的产生,然后切换到它挂载到的目录下面验证我们刚才在容器中生成的文件按是否存在
[root@k8snode2 ~]# cd /var/lib/kubelet/pods/2e54f5fd-c165-4635-94b8-b76f829a1ee5/volumes/kubernetes.io~csi/pvc-093a0273-8a51-4e9c-be20-96626d5db440/mount
[root@k8snode2 mount]# ls
111.txt lost+found
[root@k8snode2 mount]# cat 111.txt
1111111111111
#可以看到这个挂载目录中的pvc-093a0273-8a51-4e9c-be20-96626d5db440目录和我们在k8s主节点查看到的对应的pvc是一样的
[root@k8smaster1 ceph-csi]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
raw-block-pvc Bound pvc-22cdcfb0-4c5f-4701-a866-0ac6389e8e9a 1Gi RWO csi-rbd-sc 44h
rbd-pvc Bound pvc-093a0273-8a51-4e9c-be20-96626d5db440 1Gi RWO csi-rbd-sc 44h
#到这个里k8s群集接入ceph存储就完成了
关于这些部署也可以参考以下链接
https://docs.ceph.com/en/latest/rbd/rbd-kubernetes/?highlight=provisioner
https://cloud.tencent.com/developer/article/2024192
https://www.cnblogs.com/hsyw/p/14541073.html
https://blog.csdn.net/cumt_TTR/article/details/117997055
https://support.huaweicloud.com/cce_faq/cce_faq_00277.html
https://blog.csdn.net/co1590/article/details/122060369