泛型+通配符(数学角度)
打破常规,换个角度重新认识泛型和通配符!
跳转提示:
- 如果已经熟悉泛型基础知识的小伙伴可以直接跳过引入泛型这一部分,因为这一部分是关于泛型的基础知识的讲解,文章篇幅较长。
- 想看换个角度认识泛型的部分,可以直接跳过引入泛型这部分,直接看从数学函数角度重新认识泛型!
- 想看换个角度认识通配符的部分,也可以直接跳过引入泛型这部分,直接看从数学集合角度重新认识泛型!
文章内容仅我个人思考,全盘接受任何评价!
目录
- 打破常规,换个角度重新认识泛型和通配符!
-
- 引入泛型
-
- 原始代码(未使用泛型)
- 优化代码(使用泛型)
- 解决疑问
- 泛型擦除机制
- 泛型的边界
- 知识点汇总
- 从数学函数角度重新认识泛型
-
- 存疑
- 缘由
- 回答
- 从数学集合角度重新认识通配符
-
- 拓展
- 理论
泛型是在JDK1.5引入的新语法,我们都知道,通俗讲,泛型就是适用广泛的类型。从代码上来讲,就是泛型实现了类型的参数化。而通配符则是用来解决泛型无法协变的问题的。我们通常意义上都是将泛型理解为抽象的数据类型,泛型有众多好处,我们利用泛型可以更高效的编写出更安全,更灵活的代码。
如果我们换一种思考方式来看待泛型,跳出平常从代码角度认识的泛型,而是从数学角度来看待我们平常喜闻乐见的泛型,会有什么样的效果呢?接下来,文章篇幅较长分为两个部分,我会先列举一个例子来引入泛型,然后再从数学的角度分析泛型。
引入泛型
我们自定义一个容器类,该类中可以存放任何引用类型的元素,而且该类中分别有存储元素和获取元素的方法,然后通过测试程序,完成往容器类中存储元素,以及获取元素。这个过程完成之后,分析一下这个例子有什么弊端?
原始代码(未使用泛型)
package day05.bk;
public class Test {
public static void main(String[] args) {
RegularList regularList = new RegularList();
//往容器中添加元素
regularList.add("张三");
regularList.add(1);
//获取容器中的元素
String s1= regularList.get(0);//报错
String s2 = (String)regularList.get(0);
/*当我们使用String类型来接收从容器中获取的数据的时候,会发现报错了
报错的原因是get()方法返回的是Object类型,而我们使用的是String子类来接收方法返回值
这会导致子类型引用指向父类型对象,在java中这是不允许的,不然编译器会报错
必须要强制转型才可以编译通过,那我们这里可以使用强制类型转换符来强转返回值类型
如果我们要取出索引为1的元素,只要不是Object类型的元素都必须强转
一两个还可以接受,而且只有已知我们获取的元素到底是个什么类型才可以知道该强转成什么类型
如果一旦容器中的元素过多,或者这个方法不是我们自身来调用,这样我们就很难甚至无法准确判断取出来的元素是什么类型
不仅效率低下,而且编译器容易报错,很显然,这违背了java语言一种抽象编程的语言的初衷。
那么是否有一个可以避免调用时强制类型转换,而是编译器自动推断取出来的元素类型,提高代码复用性的java语法机制呢?
有,这个时候泛型就被提出来解决上述的问题了。
*/
}
}
class RegularList {
public Object[] arr;
int size ;
public RegularList(){
arr = new Object[10];
size = 0;
}
public void add(Object ele){
if(size<arr.length) {
arr[size] = ele;
size++;
}
}
public Object get(int index) {
if (index >= 0 && index < size) {
return arr[index];
}
return null;
}
}
分析:
我们可以往RegularList这个容器类存储任意类型的引用数据类型,因为容器底层是new了一个Object[]数组,往里面存储元素没有任何负担,不会出现类型转换异常,因为是向上转型。但是当我们要从这个容器中取出元素的时候,声明变量去接收的时候,会出现问题,会出现我们不知道该用什么类型去接收取出的元素,而且取出元素的方法返回的是Object类型的,这就涉及到了强制类型转换,这显然增强了类型转换的风险,编译器会报错概率被提高。同时也不利于程序的拓展性和灵活性,也违背了java面向抽象编程的思想。那么这个时候开发人员就引入了一个新的知识点,把类型参数化,也就是把类型抽象化,这样做意味着什么?就代表我们编写代码的时候,可以写出复用性非常高的抽象的代码,同一个代码灵活的运用在任何使用的场景。这就是泛型的初衷。
优化代码(使用泛型)
package day05.bk;
public class Test1 {
public static void main(String[] args) {
GenericList<Integer> arr1 = new GenericList<>();
arr1.add(10);
Integer val = arr1.get(0);
GenericList<String> arr2 = new GenericList<>();
arr2.add("张三");
String val2 = arr2.get(1);
}
}
class GenericList<T> {
public T[] array;
public int size;
@SuppressWarnings("unchecked")
public GenericList() {
array = (T[]) new Object[10];
size = 0;
}
public void add(T item) {
if (size < array.length) {
array[size] = item;
size++;
}
}
public T get(int index) {
if (index >= 0 && index < size) {
return array[index];
}
return null;
}
}
分析:
当我们使用泛型机制之后,我们的GenericList泛型类,就可以适配很多的使用方,而且使用的时候还要化抽象为具体,比如我们这里是创建GenericList对象的时候是指定泛型T为Integer或者指定为String,这个时候,我们要是再想往容器中添加元素,就不能随意添加了,这个时候就会受到编译器的类型推断机制的阻碍,添加类型不匹配的元素的时候,编译器就会报错。
解决疑问
疑问一:为什么在容器类中创建数组对象的时候,不能直接彻底抽象成以下这样?(也就是把泛型实例化)
public T array =new T[10]; // 错误,不能直接使用泛型创建数组
-
原因:
在Java中,泛型是一种编译时擦除的机制,也就是说,在运行时,泛型类型信息会被擦除,编译后的代码中不再包含泛型的具体类型。这就是为什么不能直接使用泛型来实例化数组或者创建对象。所以在这行代码中,使用泛型创建数组是不合法的,因为Java编译器无法确定具体的泛型类型在运行时应该分配多少内存空间。
-
解决办法:
可以使用Object数组,并在运行时进行强制类型转换。
public T[] arr1 =(T[])new Object[10]; // 正确,使用Object数组并进行强制类型转换
疑问二:使用Object数组并进行强制类型转换一定可靠吗?
-
答案:不可靠
-
原因:
尽管我们使用Object数组并进行强制类型转换,这样的代码虽然可以通过编译和运行,但是需要注意的是,使用Object数组可能会导致在运行时发生类型转换错误。因为在运行时,编译器并不知道数组中具体存储的类型是什么,因此强制类型转换可能会出现ClassCastException。
-
解决办法:
为了避免这种类型的错误,你可以使用其他方式来解决问题。例如,可以使用ArrayList来动态地存储对象而无需强制类型转换:
class MyArray2<T> {
public ArrayList<T> arrList;
public MyArray2() {
arrList = new ArrayList<>();
}
}
在这里,我们使用ArrayList来存储T类型的对象,这样就避免了在运行时进行类型转换,并且可以动态地调整数组的大小。
疑问三:那么我们上述写的容器类的代码中,T的类型信息被擦除为什么类型?
既然我们已经知道了泛型存在擦除机制,而且通过泛型擦除机制的时期是在编译时期进行的,这意味着编译之后的字节码中,泛型类型的信息回被擦除为原始类型或者边界类型,那么既然我们想了解T被擦除成什么类型,那么我们可以查看文件的字节码。
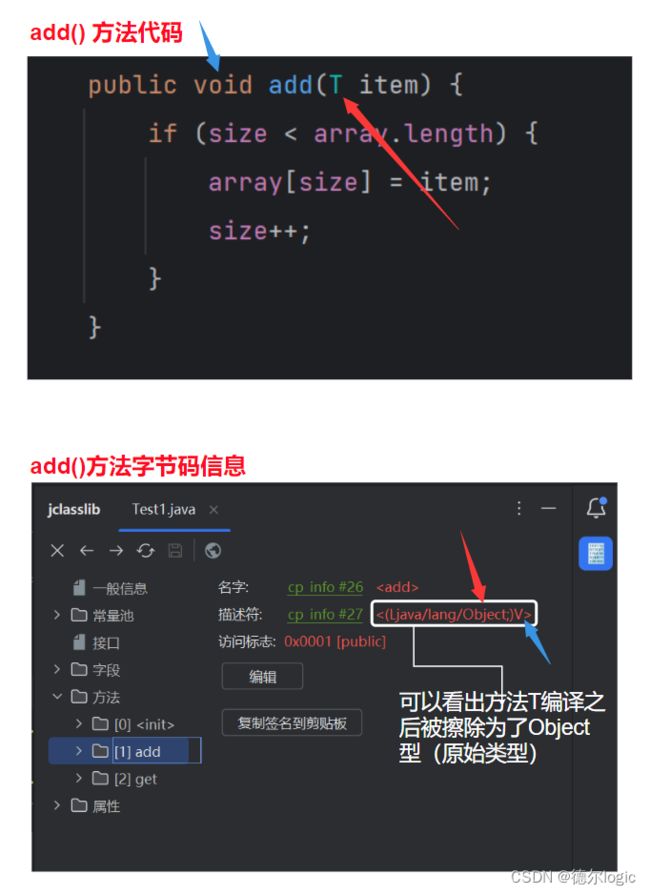
泛型擦除机制
- 概述:在Java中,泛型是一种在编译时期进行类型检查,并在运行时将泛型类型信息擦除的机制。这意味着在编译后的字节码中,泛型的类型信息会被擦除,取而代之的是原始类型(raw type)或者边界类型(bounded type)。
优点:
- 编译时擦除的机制带来了类型安全性和互操作性的好处。因为泛型在编译时进行类型检查,可以避免在运行时发生一些类型相关的错误。同时,由于擦除了泛型类型信息,Java可以保持向后兼容性,使得使用泛型编写的代码可以在不支持泛型的旧版本Java中运行。
- 尽管泛型的类型信息在运行时被擦除了,但是Java通过限定类型参数的边界(bounded type)来保证类型安全性。编译器会确保传入泛型类或方法的对象满足指定的类型边界要求,从而在编译时就避免了类型不匹配的问题。
现在利用泛型的擦除机制我们就可以知道为什么我们举的例子中使用Object[]数组然后强转的方式同样很不好的原因了。如果现在我们要在泛型类中定义一个返回类型是T的方法
class MyArray<T>{
//私有成员变量
private T[] arr = (T[]) new Object[20];
//getter方法
public T getMessage(int pos){
return arr[pos];
}
//setter方法
public void setMessage(int pos,T val){
this.arr[pos] = val ;
}
//获取数组的方法
public T[] getArr(){
return arr;
}
}
查看字节码之后,我们知道上述代码在编译之后的本质是
//编译过后(擦除机制的参与)代码变成以下这样
class MyArray< Object >{
//私有成员变量
private Object[] arr = ( Object[]) new Object[20];
//getter方法
public Object getMessage(int pos){
return arr[pos];
}
//setter方法
public void setMessage(int pos, Object val){
this.arr[pos] = val ;
}
//获取数组的方法
public Object[] getArr(){
return arr;
}
}
现在在测试程序Test2中调用MyArray类中的返回方法
public class Test2 {
public static void main(String[] args) {
MyArray<Integer> array = new MyArray<>();
Integer[] arr = array.getArr();//代码写完,编译器没有报错,但是运行时,报错了
}
}
如下图所示:

这是因为泛型的擦除机制,这也就是为什么我们使用Object[]数组然后强转的方式同样很不好的原因。编译器为了安全考虑,不会然你这样做的,因为Object数组中可以存放任意引用类型的元元素,但是你取出来的时候可就不能随意的取出来了,会出现类型转换异常的运行时异常。所以new 一个Object[]数组其实非常的不好用。
泛型的边界
泛型的边界(Bounds)是一种在泛型类型参数上施加限制的机制,它规定了泛型类型参数必须满足的条件。边界允许你在使用泛型时指定泛型类型参数的类型范围,从而增加类型安全性并限制可以传递的类型。利用泛型的擦除机制,我们又可以知道编译后的字节码中,泛型的类型信息会被擦除,取而代之的是原始类型(raw type)或者边界类型(bounded type)。
上界(Upper Bounds): 使用上界可以限制泛型类型参数为某个特定的类型或该类型的子类型。这意味着传递给泛型类或方法的类型必须是指定类型或其子类型。使用extends关键字指定上界。
例如,以下代码中的泛型类型参数T必须是Number类或Number的子类:
class Container<T extends Number> {
// ...
}
知识点汇总
1、尖括号<>里面写的是什么?
<类型形参列表>
2、定义一个泛型类的语法
class 泛型类类名<类型形参列表,多个泛型使用逗号隔开>{
//这里可以运用类型参数,可以部分使用,也可以全部使用
}
泛型类使用的语法
- 声明变量或者实例化
泛型类类名<实际类型参数> 引用名 = new 泛型类类名<实际类型参数>();
泛型类类名<实际类型参数> 引用名 = new 泛型类类名<>();
//可以省略后面的尖括号里的内容,因为编译器可以根据上下文推断
- 方法参数
方法名(泛型类类名<实际类型参数> 局部变量名){
}
3、代码解释
类名后的代表占位符,表示当前类是一个泛型类,通常用大写字母表示泛型。
4、语法规范
类型参数一般使用一个大写字母表示,常用的名称有
| 意义 | 表示 |
|---|---|
| Element元素 | E |
| Key键 | K |
| Value值 | V |
| Number数字 | N |
| Type类型 | T |
等等其他H、U…
当然这这只是语法规范,不是语法规则,可以不完全严格的遵守,只是较为普遍使用流传的方式。
5、泛型的边界
- 注意事项:泛型只有上界,没有下界。使用extends关键字指定上界。
- 语法:
class 泛型类类名<类型形参 extends 上界类型>{
//...
}
以下内容才是这篇文章的重中之重!!!
从数学函数角度重新认识泛型
存疑
①为什么泛型只有上界没有下界?
②
③
④泛型既然是类型的参数化的结果,那么我们是否可以从数学中的未知数的角度来看待我们的泛型?
缘由
方法又名函数,我们可以给方法传入一个或多个参数,而对参数处理的过程进行封装之后就是我们的方法,我们讨论方法的参数是从数据类型级别上考虑的,是把数据类型进行参数化。现在,我们从类级别上来考虑参数,那就是被类型被参数化,也就是我们了解的泛型的定义。对类型参数进行处理的过程被封装好之后是什么?是类或者接口。那么我们可以把泛型类等同于数学中的函数,按照对应关系,可以得出:泛型类是泛型(类型参数)的函数,而泛型就是自变量。
泛型若被看作是一种函数,它的类型参数相当于函数的参数,而泛型类则是根据这些参数生成具体类型的“函数”。
在数学中,函数可以有定义域(Domain)和值域(Codomain),定义域表示自变量的取值范围,值域表示函数的输出范围。在泛型中,你可以把类型参数看作是自变量,而泛型类的定义和使用过程就类似于函数的使用。因此,将类型参数限定在某个上界就是为了定义泛型的自变量的取值范围,这样上界就像是定义域,它确保了传递给泛型的类型参数是在一定范围内的,从而保证了类型的安全性和一致性。
所以泛型具备上界这个特征是本身就存在的。而设置合适的上界就好比你给自变量设置了合适的定义域,这样优点非常的多,可以带来更强的类型安全性、代码复用、灵活性以及避免类型强制转换等优势。很完美的体现了java程序设计语言的面向抽象编程的特性。
回答
①为什么泛型只有上界没有下界?
泛型类之所以没有下界的概念,与设计的思考和语法的清晰性有关:
- 语法一致性: 在 Java 中,类的继承关系是自上而下的,子类可以继承父类的特性。泛型类的设计也遵循了类的继承关系,上界的概念符合这种继承的逻辑。引入下界可能会破坏这种一致性,因为下界会导致类型关系的混乱。
- 类型的生命周期: 通配符的上界和下界概念主要用于限制类型的可读性和可写性,但对于泛型类来说,这种限制会更加复杂。在泛型类中,不同类型的对象可能会在不同的生命周期中产生和消亡,这就增加了引入下界时的复杂性,可能导致不清晰的编程模式。
- 类型推断: 泛型类的类型参数通常是在实例化时进行指定的。引入下界可能会增加类型推断的复杂性,尤其是在存在多个类型参数的情况下。上界通配符更加直观和易于使用。
②
因为泛型只有上界,由于类的继承特性是自上而下的,
③
直接被擦除为边界类型意思就是 T编译之后取的值就是边界,这虽然违背了定义域只取了最大值,但是java的类的自上而下的继承特性,直接擦除为边界就不会产生任何矛盾。
④泛型既然是类型的参数化的结果,那么我们是否可以从数学中的未知数的角度来看待我们的泛型?
可以,准确地把泛型的上界与数学函数中的自变量的定义域联系起来,深入理解这个观点有助于更好地理解泛型的本质和作用。
从数学集合角度重新认识通配符
拓展
我们是否可以同样用数学的角度来考虑通配符,这样能帮助我们更好的理解为什么:通配符的上界限制了类型的写入操作,而通配符的下界限制了类型的读取操作。
理论
从数学角度来理解通配符可以帮助我们更清晰地把握其含义。在数学集合的视角下,通配符的上界限制了集合的包含内容,使其成为一个特定集合的子集。通配符的下界限制了集合的容纳内容,使其成为一个特定集合的父集。
假设我们有三个类:Food、Fruit 和 Apple,它们之间的继承关系是 Food 是 Fruit 的父类,Fruit 是 Apple 的父类。
-
通配符带有上界(
? extends T):
如果我们把类型T看作是一个数学集合,那么通配符? extends T可以理解为一个子集,这个子集包含了所有属于T类型或其子类的对象。你可以从这个子集中取出元素,但你无法向其中添加元素,因为你无法确定子集的确切类型。举个例子,? extends Fruit表示一个集合,其中包含了所有属于Fruit类型或其子类的对象,你可以从这个集合中取出元素,但无法确定你可以添加什么元素进去。 -
通配符带有下界(
? super T):
类似地,如果我们把类型T看作是一个数学集合,那么通配符? super T可以理解为一个父集,这个父集包含了所有属于T类型或其父类的对象。你可以向这个父集中添加元素,但你只能以更通用的类型来读取元素,因为你无法确定父集中存储的具体类型。举个例子,? super Fruit表示一个集合,其中包含了所有属于Fruit类型或其父类的对象,你可以向这个集合中添加元素,但只能以Object类型的引用来读取元素。
。你可以从这个子集中取出元素,但你无法向其中添加元素,因为你无法确定子集的确切类型。举个例子,? extends Fruit 表示一个集合,其中包含了所有属于 Fruit 类型或其子类的对象,你可以从这个集合中取出元素,但无法确定你可以添加什么元素进去。
- 通配符带有下界(
? super T):
类似地,如果我们把类型T看作是一个数学集合,那么通配符? super T可以理解为一个父集,这个父集包含了所有属于T类型或其父类的对象。你可以向这个父集中添加元素,但你只能以更通用的类型来读取元素,因为你无法确定父集中存储的具体类型。举个例子,? super Fruit表示一个集合,其中包含了所有属于Fruit类型或其父类的对象,你可以向这个集合中添加元素,但只能以Object类型的引用来读取元素。
很高兴在文章末尾看见您,篇幅较长,感谢耐心看完的读者,上述均是个人猜想,如有不妥,欢迎您在评论区留言。创作不易,希望喜欢这篇文章的小伙伴可以点赞,关注加收藏,感谢!
