嵌入式裸机课程之C语言程序调用和重定位学习笔记
一.汇编写启动代码之关看门狗
前期准备工作
1.1 什么是看门狗
看门狗(watchdog timer)电子设备经常会跑飞或者死机(譬如极端炎热、极端寒冷、工业复杂场合)
这种情况我们需要设备自动复位,看门狗就是实现这种的SOC内部的定时器。
正常情况下,系统会定时给看门狗发送一个信号,也就是“喂狗”,如果遇到异常的状况(即:看门狗在规定的时间里没有收到信号),看门狗会判定系统出了故障,就会发送一个reset信号给系统复位。
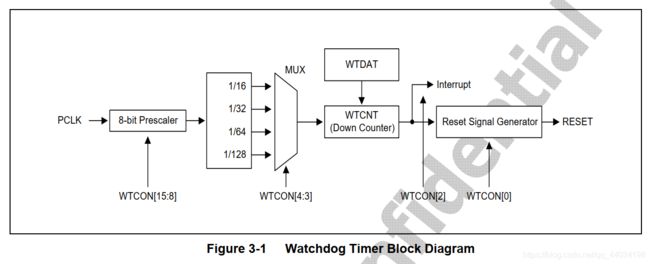
1.2 为什么要关看门狗
因为一般的CPU设计中看门狗都是默认工作的,但是在启动代码段我们不方便去喂狗时,看门狗就会复位,所以我们一般就会先去关闭看门狗,这段时间一般程序不会出现跑飞的状况。
在S5PV210内部的iROM代码(BL0)中,其实已经关过看门狗了。所以我们的启动代码实际上是不用去关也没关系,也就是说今天写的关闭看门狗的代码运行后没有任何现象(没有现象就是正常现象).
很多CPU内部是没有BL0的,因此也没人给你关看门狗,都要在启动代码前段自己写代码关看门狗,所以本次是练习如何关看门狗。
1.3 分析硬件物理特性、原理图、数据手册
物理特性上看门狗其实是个定时器(跟现实中的闹钟类似),硬件上就是SoC内部的一个内部外设。
原理图:看门狗不用分析原理图,因为看门狗属于内部外设,且没有外部相关的原件与他有关,所以不需要原理图分析,原理图上根本找不到和看门狗有关的地方。
1.4 实现关watchdog的重点寄存器
分析数据手册可知,我们只需要设定WTCON寄存器即可
Watchdog Timer Control Register (WTCON, R/W, Address = 0xE270_0000)
 The WTCON register allows you to enable/ disable the watchdog timer.
The WTCON register allows you to enable/ disable the watchdog timer.
编程实战
编程思路:我们只需要将WTCON register中的bit[5]设定为0即可。
汇编源代码:
#define WTCON 0xE2700000
.global _start
_start:
//关看门狗
ldr r0, =0x0
ldr r1, =WTCON
str r0, [r1]
二.汇编写启动代码之设置栈和调用
前期准备工作
2.1 C语言运行时需要和栈的意义
“C语言运行时(runtime)”需要一定的条件,这些条件由汇编来提供。C语言运行时主要是需要栈。
C语言与栈的关系:C语言中的局部变量都是用栈来实现的。如果我们汇编部分没有给C部分预先设置合理合法的栈地址,那么C代码中定义的局部变量就会落空,整个程序就死掉了。
我们平时在编写单片机程序(譬如51单片机)或者编写应用程序时并没有去设置栈,但是C程序还是可以运行的。
原因是:在单片机中由硬件初始化时提供了一个默认可用的栈,在应用程序中我们编写的C程序其实并不是全部,编译器(gcc)在链接的时候会帮我们自动添加一个头,这个头就是一段引导我们的C程序能够执行的一段汇编实现的代码,这个代码中就帮我们的C程序设置了栈及其他的运行时需要。
2.2 CPU模式和各种模式下的栈
在ARM中37个寄存器中,每种模式下都有自己的独立的SP寄存器(r13),为什么这么设计?

如果各种模式都使用同一个SP,那么就意味着整个程序(操作系统内核程序、用户自己编写的应用程序)都是用一个栈的。你的应用程序如果一旦出错(譬如栈溢出),就会连累操作系统的栈也损坏,整个操作系统的程序就会崩溃。这样的操作系统设计是非常脆弱的,不合理的。
解决方案就是各种模式下用不同的栈。我的操作系统内核使用自己的栈,每个应用程序也使用自己独立的栈,这样各是各的,一个损坏不会连累其他人。
我们现在要设置栈,不可能也懒的而且也没有必要去设置所有的栈,我们先要找到自己的模式,然后设置自己的模式下的栈到合理合法的位置,即可。
注意:系统在复位后默认是进入SVC模式的
2.3 SVC模式下的SP设置思路
先把模式设置为SVC,再直接操作SP。但是因为我们复位后就已经是SVC模式了,所以直接设置SP即可。
2.4 设置栈指针至合法位置
栈必须是当前一段可用的内存(可用的意思是这个地方必须有被初始化过可以访问的内存,而且这个内存只会被我们用作栈,不会被其他程序征用)
当前CPU刚复位(刚启动),外部的DRRAM尚未初始化,目前可用的内存只有内部的SRAM(因为它不需初始化即可使用)。因此我们只能在SRAM中找一段内存来作为SVC的栈。
结合iROM_application_note中的memory map,并且在ARM中,ATPCS(ARM关于程序应该怎么实现的一个规范)要求使用满减栈可知SVC栈应该设置为0xd0037D80
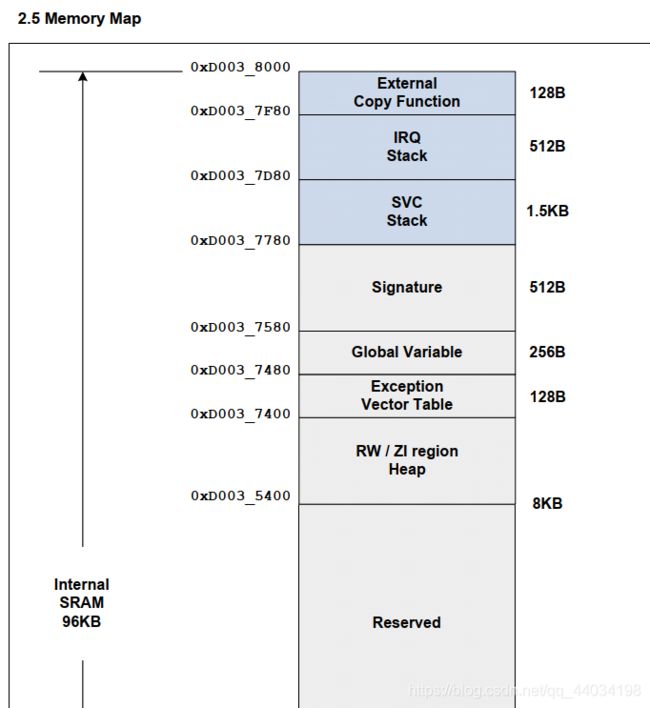
2.4 名词解释
1)ATPCS即ARM-THUMB procedure call standard(ARM-Thumb过程调用标准)的简称。
PCS规定了应用程序的函数可以如何分开地写,分开地编译,最后将它们连接在一起,所以它实际上定义了一套有关过程(函数)调用者与被调用者之间的协议
2)栈(Stack)
栈是限定仅在一端进行插入或删除操作的线性表。
描述一个栈的特点需要两个参数:栈地址的增长方向(增栈/减栈)、栈指针的指向位置(空栈/满栈)
满栈:进栈:先移动指针再存; 出栈:先出数据再移动指针
空栈:进栈:先存再移动指针; 出栈:先移动指针再取数据
减栈:进栈:指针向下移动; 出栈:指针向上移动
增栈:进栈:指针向上移动 出栈:指针向下移动
根据如上分类一般栈可以组成为四种:满减栈 满增栈 空减栈 空增栈
所以我们的满减栈 :进栈指针向上移动,再存数据;出栈先出数据,指针向下移动
栈指令
STM:(STore Multiple data)表示存储数据,即入栈。
LDM:(LoaD Multiple data)表示加载数据,即出栈。
编程实战
因为使用的是FD栈,所以地址选择栈顶的地址。
汇编程序源码,有了如下的设定就可以使用汇编语言对c语言进行调用了。
#define SVC_STACK 0xD0037D80
.global _start
_start:
//设置栈
ldr sp, =SVC_STACK
b.
三.汇编写启动代码之开iCache
前期准备工作
3.1 什么是cache
cache是一种内存,叫高速缓存,cache存储了频繁访问的 RAM 位置的内容及这些数据项的存储地址。当处理器引用存储器中的某地址时,高速缓冲存储器便检查是否存有该地址。如果存有该地址,则将数据返回处理器;如果没有保存该地址,则进行常规的存储器访问。
从容量来说:CPU < 寄存器 < cache < DDR
从速度来说:CPU > 寄存器 > cache > DDR
3.2 为什么有cache的存在
cache的存在,是因为寄存器和ddr之间速度差异太大,ddr的速度远不能满足寄存器的需要(不能满足cpu的需要,所以没有cache会拉低整个系统的整体速度)
整个系统中CPU的供应链由:寄存器+cache+DDR+硬盘/flash四阶组成,这是综合考虑了性能、成本后得到的妥协的结果。
210内部有32KB icache和32kb dcache。icache是用来缓存指令的;dcache是用来缓存数据的。
3.3 cache的意义
指令平时是放在硬盘/flash中的,运行时读取到DDR中,再从DDR中读给寄存器,再由寄存器送给cpu。但是DDR的速度和寄存器(代表的就是CPU)相差太大,如果CPU运行完一句再去DDR读取下一句,那么CPU的速度完全就被DDR给拖慢了。解决方案就是icache。
3.4 cache的一般工作原理
icache工作时,会把我们CPU正在运行的指令的旁边几句指令事先给读取到icache中(CPU设计有一个基本原理:代码执行时,下一句执行当前一句代码旁边代码的可能性要大很多)。当下一句CPU要指令时,cache首先检查自己事先准备的缓存指令中有没这句,如果有就直接拿给CPU,如果没有则需要从DDR中重新去读取拿给CPU,并同时做一系列的动作:清缓存、重新缓存。
3.5 iROM中BL0对cache的操作
首先,icache的一切动作都是自动的,不需人为干预。我们所需要做的就是打开/关闭icache。
其次,在210的iROM中BL0已经打开了icache。所以之前看到的现象都是icache打开时的现象。
3.6 协处理器CP15
在基于ARM的嵌入式应用系统中,存储系统的操作通常是由协处理器CP15完成的。CP15包含16个32位的寄存器,其编号为0~15。
而访问CP15寄存器的指令主要是MCR和MRC这两个指令。
例如协处理器15(CP15),ARM处理器使用协处理器15的寄存器来控制cache、TCM和存储器管理。
而访问CP15寄存器的指令主要是MCR和MRC这两个指令:
MRC:协处理器寄存器到ARM处理器寄存器的数据传送指令(读出协处理器寄存器)。
MCR:ARM处理器寄存器到协处理器寄存器的数据传送指令(写入协处理器寄存器)。
MRC/MCR指令读取CP15寄存器格式:
MRC{cond} p15,<Opcode_1>,<Rd>,<CRn>,<CRm>,<Opcode_2>
MCR{cond} p15,<Opcode_1>,<Rd>,<CRn>,<CRm>,<Opcode_2>
cond:为指令执行的条件码。当cond忽略时指令为无条件执行。
Opcode_1:协处理器的特定操作码. 对于CP15寄存器来说,opcode1=0
Rd:作为源寄存器的ARM寄存器,其值将被传送到协处理器寄存器中,或者将协处理器寄存器的值传送到该寄存器里面 ,通常为R0
CRn:作为目标寄存器的协处理器寄存器,其编号是C~C15。
CRm:协处理器中附加的目标寄存器或源操作数寄存器。如果不需要设置附加信息,将CRm设置为c0,否则结果未知
Opcode_2:可选的协处理器特定操作码。(用来区分同一个编号的不同物理寄存器,当不需要提供附加信息时,指定为0)
查询CP15 的C1 寄存器可知bit[12]为控制cache的位
当数据cache和指令cache是分开的,本控制位禁止/使能指令cache
0 :禁止指令 cache
1 :使能指令 cache
如果系统中使用统一的指令cache和数据cache或者系统中不含cache,读取该位时返回0,写入时忽略。当系统中的指令cache不能禁止时,读取时该位返回1,写入时忽略
编程实战
汇编代码读写cp15以开关icache,我们编程控制icache 的开关,通过LED闪烁实验的现象可以观察到
关了icache 后LED闪烁很明显变慢了。
mrc p15,0,r0,c1,c0,0; // 读出cp15的c1到r0中
bic r0, r0, #(1<<12) // bit12 置0 关icache
orr r0, r0, #(1<<12) // bit12 置1 开icache
mcr p15,0,r0,c1,c0,0;
四.重定位和链接脚本
前期准备工作
4.1 什么是重定位
如下内容转自https://blog.csdn.net/cherisegege/article/details/80708143
一、必须知道的几个概念。
1、链接地址和运行地址。①运行地址,顾名思义就是程序运行的时候的地址,也就是你用工具将代码下载到RAM的那个地址,也叫加载地址。
②链接地址,由链接脚本指定的地址。为什么需要链接脚本指定地址呢?你想一下,在c语言编程中,当我们需要调用一个A函数的时候,编译器是怎么找到这个A函数?编译器肯定是知道它被放在哪里才可以找到它。那就是链接脚本的作用,链接脚本其实在程序被执行之前都已经指定A函数一个地址编号,以后所有的函数调用我们都会去这个地址编号那里寻找A函数。有点类似于c语言的指针变量。
2、位置有关码与位置无关码。
①位置有关码,就是这句代码的执行正确与否还需要取决于当前的地址,也就是说跟地址已经绑定了的,例如:ldr PC,
_main,就是PC指针必须跳转到_main(函数名就是一个地址)这个地址去,代码执行成功与否就相当于受到了这个地址的约束,假如这个地址的内容不存放_main这个函数,就会出错了。②位置无关码,就是这句代码在哪里运行都可以的,跟所处的地址无关,跟位置有关码相反。
二、重定位需要理解的一些问题。
1、链接地址跟运行地址不同的情况下会出现什么情况?
答:以上面举的函数A为例,当链接地址跟运行地址不同的时候,假如链接地址是0x1000,运行地址(加载地址)是0x0000,链接脚本指定函数A将来是要存放到(基地址+偏移量)=0x1000+0x0001=0x1001地址的,但是程序在下载的时候却把这个程序下载到0x0000,所以函数A的地址实际上是存放在(基地址+偏移量)=0x0000+0x0001=0x0001这个地址的。当程序运行到一行位置有关码例如:ldr PC, A
编译器首先就会按照链接脚本指定的A的那个地址0x1001寻找A函数,但是因为加载地址跟链接地址不同的原因,实际上A函数已经被放到了0x0001,所以执行就会出错。所以,当这两个地址不同的时候,执行一段位置有关码的时候就会发生不可预估的错误。2、为什么会出现链接地址跟运行地址不同的情况?
答:当一块芯片启动的时候,依靠内部的SRAM,可以运行一小段代码,而因为DDR还没初始化,注定了开始的运行地址是在内部SRAM中的。当我们需要运行一个操作系统,那么点的内存怎么够运行呢?所以这时候就需要初始化DDR才可,而因为我们知道这代码将来都是在DDR上面运行的,所以链接脚本指定的链接地址肯定是DDR上面的地址,所以这就出现了链接地址跟运行地址不同的情况了。
3、什么是重定位?
答:由于出现1这样的问题,就需要使用重定位这种方式解决上面的问题了。那什么是重定位呢?重定位就是在链接地址跟运行地址不同的情况下,执行一段位置无关码,这段位置无关码的作用就是将原来的那份代码全部复制到链接地址那里去,然后自己再长跳转到新的那份代码的刚刚执行的那个位置。这样就实现了链接地址跟运行地址一致的情况了。
3、为什么需要重定位?
答:就是链接地址跟运行地址不同,在这个情况下我们可以有两种方案: ①全部使用位置无关码。 ②进行重定位让这两个地址相同。
我们知道,如果是一个小代码,使用①时可以的,但是一个大的代码文件很难保证全部都使用位置无关码的,这也是不现实的,所以必须使用重定位解决这个问题。
210中的裸机程序。运行地址由我们下载时确定,下载时下载到0xd0020010,所以就从这里开始运行。(这个下载地址也不是我们随意定的,是iROM中的BL0加载BL1时事先指定好的地址,这是由CPU的设计决定的)。所以理论上我们编译链接时应该将地址指定到0xd0020010,但是实际上我们在之前裸机程序中都是使用位置无关码PIC,所以链接地址可以是0。
4.2 从源码到可执行程序的步骤:预编译、编译、链接、strip
预编译:预编译器执行。譬如C中的宏定义就是由预编译器处理,注释等也是由预编译器处理的。
编译: 编译器来执行。把源码.c .S变成机器码.o文件。
链接: 链接器来执行。把.o文件中的各函数(段)按照一定规则(链接脚本来指定)累积在一起,
形成可执行文件。
strip: strip是把可执行程序中的符号信息给拿掉,以节省空间。(Debug版本和Release版本)
objcopy:由可执行程序生成可烧录的镜像bin文件。
4.3 链接脚本
什么是链接脚本
链接脚本其实是个规则文件,他是程序员用来指挥链接器工作的。链接器会参考链接脚本,并且使用其中规定的规则来处理.o文件中那些段,将其链接成一个可执行程序。
链接脚本的关键内容有2部分:段名 + 地址(作为链接地址的内存地址)
链接脚本的理解:
SECTIONS { } 这个是整个链接脚本
. 点号在链接脚本中代表当前位置。
= 等号代表赋值
什么是程序段
程序段的概念:代码段、数据段、bss段(ZI段)、自定义段
段就是程序的一部分,我们把整个程序的所有东西分成了一个一个的段,给每个段起个名字,然后在链接时就可以用这个名字来指示这些段。
也就是说给段命名就是为了在链接脚本中用段名来让段站在合适的位置。
段名分为2种:一种是编译器链接器内部定好的,先天性的名字;一种是程序员自己指定的、自定义的段名。
先天性段名:
代码段:(.text),又叫文本段,代码段其实就是函数编译后生成的东西
数据段:(.data),数据段就是C语言中有显示初始化为非0的全局变量
bss段:(.bss),又叫ZI(zero initial)段,就是零初始化段,对应C语言中初始化为0的全局变量。
后天性段名:
段名由程序员自己定义,段的属性和特征也由程序员自己定义。
一个完整的链接脚本
链接脚本link.lds
SECTIONS
{
. = 0xd0024000;
.text : {
start.o
* (.text)
}
.data : {
* (.data)
}
bss_start = .;
.bss : {
* (.bss)
}
bss_end = .;
}
1、C语言中全局变量如果未显示初始化,值是0。本质就是C语言把这类全局变量放在了bss段。
2、C运行时环境如何保证显式初始化为非0的全局变量的值在main之前就被赋值了,就是因为它把这类变量放在了.data段中,而.data段会在main执行之前被处理(初始化)。
代码重定位实战
任务介绍
任务:在SRAM中将代码从0xd0020010重定位到0xd0024000
任务解释:本来代码是运行在0xd0020010的,但是因为一些原因我们又希望代码实际是在0xd0024000位置运行的。这时候就需要重定位了。
思路:
第一点:通过链接脚本将代码链接到0xd0024000
第二点:dnw下载时将bin文件下载到0xd0020010
第三点:代码执行时通过代码前段的少量位置无关码将整个代码搬移到0xd0024000
第四点:使用一个长跳转跳转到0xd0024000处的代码继续执行,重定位完成
当我们执行完代码重定位后,实际上在SRAM中有2份代码的镜像(一份是我们下载到0xd0020010处开头的,另一份是重定位代码复制到0xd0024000处开头的),这两份内容完全相同,仅仅地址不同。重定位之后使用ldr pc, =led_blink这句长跳转直接从0xd0020010处代码跳转到0xd0024000开头的那一份代码的led_blink函数处去执行。
adr与ldr伪指令的区别
ldr和adr都是伪指令,区别是ldr是长加载、adr是短加载。
重点:
adr指令加载符号地址,加载的是运行时地址;ldr指令在加载符号地址时,加载的是链接地址。
重定位(代码拷贝)
重定位就是汇编代码中的copy_loop函数,代码的作用是使用循环结构来逐句复制代码到链接地址。
复制的源地址是SRAM的0xd0020010,复制目标地址是SRAM的0xd0024000,复制长度是bss_start减去_start
所以复制的长度就是整个重定位需要重定位的长度,也就是整个程序中代码段+数据段的长度。
bss段(bss段中就是0初始化的全局变量)不需要重定位。
清bss段
清除bss段是为了满足C语言的运行时要求(C语言要求显式初始化为0的全局变量,或者未显式初始化的全局变量的值为0,实际上C语言编译器就
是通过清bss段来实现C语言的这个特性的)。一般情况下我们的程序是不需要负责清零bss段的(C语言编译器和链接器会帮我们的程序自动添加
一段头程序,这段程序会在我们的main函数之前运行,这段代码就负责清除bss)。但是在我们代码重定位了之后,因为编译器帮我们附加的代码
只是帮我们清除了运行地址那一份代码中的bss,而未清除重定位地址处开头的那一份代码的bss,所以重定位之后需要自己去清除bss。
长跳转
清理完bss段后重定位就结束了。然后当前的状况是:
1、当前运行地址还在0xd0020010开头的(重定位前的)那一份代码中运行着。
2、此时SRAM中已经有了2份代码,1份在d0020010开头,另一份在d0024000开头的位置。
然后就要长跳转了。
程序源码
.global _start // 把_start链接属性改为外部,这样其他文件就可以看见_start了
_start:
// 第4步:重定位
// adr指令用于加载_start当前运行地址
adr r0, _start // adr加载时就叫短加载
// ldr指令用于加载_start的链接地址:0xd0024000 ,这个已在链接脚本中设定
ldr r1, =_start // ldr加载时如果目标寄存器是pc就叫长跳转,如果目标寄存器是r1等就叫长加载
// bss段的起始地址
ldr r2, =bss_start // 就是我们重定位代码的结束地址,重定位只需重定位代码段和数据段即可
cmp r0, r1 // 比较_start的运行时地址和链接地址是否相等
beq clean_bss // 如果相等说明不需要重定位,所以跳过copy_loop,直接到clean_bss
// 如果不相等说明需要重定位,那么直接执行下面的copy_loop进行重定位
// 重定位完成后继续执行clean_bss。
// 用汇编来实现的一个while循环
copy_loop:
ldr r3, [r0], #4 // 源
str r3, [r1], #4 // 目的 这两句代码就完成了4个字节内容的拷贝
cmp r1, r2 // r1和r2都是用ldr加载的,都是链接地址,所以r1不断+4总能等于r2
bne copy_loop
// 清bss段,其实就是在链接地址处把bss段全部清零
clean_bss:
ldr r0, =bss_start
ldr r1, =bss_end
cmp r0, r1 // 如果r0等于r1,说明bss段为空,直接下去
beq run_on_dram // 清除bss完之后的地址
mov r2, #0
clear_loop:
str r2, [r0], #4 // 先将r2中的值放入r0所指向的内存地址(r0中的值作为内存地址),
cmp r0, r1 // 然后r0 = r0 + 4
bne clear_loop
run_on_dram:
// 长跳转到led_blink开始第二阶段
ldr pc, =led_blink // ldr指令实现长跳转
// 从这里之后就可以开始调用C程序了
//bl led_blink // bl指令实现短跳转
// 汇编最后的这个死循环不能丢
b .
注意点:
1)在Makefile 中,添加了链接脚本实现了重定位
arm-linux-ld -Ttext 0x0 -o led.elf $^ 变为了现在的arm-linux-ld -Tlink.lds -o led.elf $^
2)通过将运行地址处_start(adr r0, _start 短加载实现)的代码和数据,按照每次4个字节逐步搬移到链接地址处_start(ldr r1, =_start 长加载实现 )
当链接地址处的_start 的地址不断增加到链接地址的bss_start时,说明代码段和数据段已经搬移完毕
adr r0, _start
ldr r1, =_start
ldr r2, =bss_start
copy_loop:
ldr r3, [r0], #4 // 源
str r3, [r1], #4 // 目的 这两句代码就完成了4个字节内容的拷贝
cmp r1, r2 // r1和r2都是用ldr加载的,都是链接地址,所以r1不断+4总能等于r2
bne copy_loop
注:以上的内容均来自朱老师物联网大讲堂裸机课件