时序数据库系列10-SQL引擎
前言
SQL语言是一种申明式的语言,不要求用户具备大量的程序语言基础和编程逻辑思维,只需要使用SQL语言准确表达想获取的最终结果,因此使用门槛比较低。并且SQL语言的规范当前已经比较成熟,几乎很少会变化,带来了使用上的稳定性。因此,对于数据库而言,为了其易用性和用户的广泛性,大部分的数据库产品都会提供SQL语言的接口。
时序数据库作为数据库的一种特殊类型,也具有广大用户对SQL语言支持的强烈诉求。
| 时序数据库 | 是否支持SQL |
|---|---|
| TDEngine | 支持 |
| TimeScale | 支持 |
| GaussDB | 支持 |
| IOTDB | 类SQL语言 |
| influxDB | 类SQL语言 |
| DolphinDB | 类SQL语言 |
| openTSDB | 不支持 |
上图是常见的几款时序数据库对SQL的支持度,可见,大部分的的时序数据库都支持或者部分支持SQL语言,SQL引擎作为数据库的关键必要模块,扮演非常重要的角色,对使用的友好性、代码可扩展性、执行的效率等方面都具有重大意义,一个好的SQL引擎不会受限于用户编写的SQL语句的形式,根据其SQL语句原始表达的结果,优化其执行过程,最终准确、高效、快速的返回。
下面简单介绍在时序数据库中设计和开发一个SQL引擎的相关技术。
时序数据库SQL引擎设计
时序数据库作为数据库的一种,其SQL引擎也是由解析器、逻辑计划、物理计划、优化器等关键组件组成。

SQL引擎负责将SQL语句转换成执行计划,输入到执行器中高效运行,获得返回结果。
SQL引擎的功能一般可以拆解成几个步骤:
-
解析器,负责将用户输入的SQL语句解析成AST抽象语法树
-
逻辑计划生成,通过语法分析,生成具有执行层次结构的逻辑计划树,描述了各个算子的依赖逻辑关系,并没有考虑实际执行
-
物理计划生成,在逻辑计划的基础上进行优化,生成考虑了底层实现和逻辑的物理计划
-
物理计划可以作为执行器的输入,执行后获取结果。
下面将分别解析SQL引擎中的各个核心组成。
解析器
SQL解析器(Parser)负责将SQL进行词法分析、语法分析,最终生成AST抽象语法树。
词法分析:用户输入的SQL语句为一个字符串,从中识别出系统支持的关键字、标识符、运算符、终结符等,确定每个词的固有词性。即,负责分词、识别。
语法分析:根据SQL的标准定义语法规则,使用词法分析中产生的词去匹配语法规则,如果一个 SQL 语句能够成功匹配一个语法规则,则生成对应的抽象语法树(Abstract Syntax Tree,AST), AST用于在程序内部结构化的表达SQL的语义。
Parser的常用工具包括两种,分别为ANTLR和Calcite,可以根据需要将用户的SQL语句自动转换为AST,给开发提供了方便。简单介绍下两个工具:
-
ANTLR
可以根据输入自动生成语法树并可视化的显示出来的开源语法分析器,不仅局限于解析sql,也可以分析任意定义好的语法
如何使用ANTLR需要以下几步:
-
定义词法和语法的g4文件,g4文件描述输入的SQL按照什么规则进行解析,即解析的规则由用户制定。
-
编写SQL解析逻辑类,如何使用AST的结果需要用户编写
-
主服务调用SQL解析逻辑类,获取解析结果
-
-
Calcite
是一款开源SQL解析工具, 可以将各种SQL语句解析成抽象语法术AST(Abstract Syntax Tree), 之后通过操作AST就可以把SQL中所要表达的算法与关系体现在具体代码之中。Calcite已经封装好了很多功能,SQL解析、SQL校验、SQL优化等
Calcite解析SQL的流程相比较ANTLR是比较简单的,开发中无需关注词法和语法文件的定义和编写,只需关注具体的业务逻辑实现。
我们拿到sql时它只是一个字符串,java识别也是一个字符串,除了做一些字符串的操作外我们做不了其他事情。calcite在对这个字符串进行解析的时候将其封装到了自己定义的一个抽象语法树中,这个AST抽象语法树是由若干 Select、From、Where、Join等类递归构建的,其父类为SqlNode,即 calcite将String转换成了SqlNode组成的树结构中,原本仅仅是一个字符串的sql,calcite将其转化成了SqlNode,方便可以递归的去访问SqlNode拿到一些特定内容。
综上,ANTLR工具是一个词法语法的解析器,不专门针对SQL语言,具备较好的扩展性,自己实现会比较灵活,但是使用门槛会高一些,开发需要参与度比较高。Calcite是一个专门的开源SQL解析工具,并且已经在原始SQL输入上做了结构树的转换和优化,相当于在原始的语义树上做了一层Node的封装,方便直接集成和使用。因此,如果想自己去解析实现灵活的关系解析,则可能使用Antlr工具更加适合一些,可以将原始依赖关系解析为项目定义抽象语法树,为后面的分析优化工作做好准备。如果是考虑门槛和易用性,减小编码工作,推荐使用Calcite,利用其转换好的语法树,方便提取其结构关系,并且也省去了一些优化和封装的工作。
逻辑计划
解析器的生成的AST抽象语法树只有语法上的逻辑关系,对AST进行进一步分析,如对语法树进行有效性检查,检查语法树中对应的表、列、函数、表达式是否有对应的元数据,将抽象语法树转换为逻辑执行计划。
因此逻辑计划不再是单纯语法上的依赖关系,而是与项目系统结合的、能够获得准确结果的查询计划。但这只是能够正确性获得结果、对原始语义的初步整理,比如用户输入的一个冗余、性能低下的sql语句,逻辑计划会按照用户输入组织逻辑树的构建,并不会考虑底层是否需要分布式执行、是否删除一些冗余无用步骤、是否将用户用不到的数据提前去除,因此对逻辑计划后续的优化处理,就给交了物理计划生成步骤。
物理计划
物理计划是在逻辑计划的基础上进行的改进优化,很多系统中,逻辑计划树和物理计划树的节点对象类型都是相同的,在逻辑计划树的基础上,进行合并节点、替换节点、增加节点、删除节点,移动节点等操作,使得逻辑树的结构变得简洁,便于高效的执行,优化后的计划成为物理计划。
对逻辑树的节点变换,可以是基于原始逻辑树的等价转换,也可以考虑底层系统实现的物理特点,最终的目的是为了保证用户得到正确性的结果的前提下,让SQL执行变得简单、快速、高效,在磁盘IO、计算步骤顺序、排序规则、分布式系统的数据交换等方面做一些改进,让用户即使在编写了一个看似性能低下、不优雅的情况下,系统也能“智慧”的想出高效执行的方法,好的SQL引擎一定是不太受限于用户的SQL组织方式的。
计划优化器
计划优化器Optimizer,即对物理计划进行优化的组件,目的是为了更好的服务于SQL执行引擎。优化器在很大程度上决定了一个系统的性能。

要设计一个好的SQL引擎,最核心的问题之一是如何更好的优化这棵语义树。从字符输入的SQL语句,生成的AST抽象语法树,最终到执行的物理计划。要较好的实现这个系统,其一是如何优雅、可扩展的将AST转换为项目方便使用的语义树,即逻辑树,其二是如何优化这棵逻辑树,转换为物理计划树,便于给到执行器准确、高效的执行。
优化器的优化工作一般可分为两类,基于规则的RBO(Rule Based Optimization)和基于成本的CBO(cost Based Optimization),目的都是寻找执行的最优路径,使得消耗的资源、时间、代价较小,使得整个引擎的执行效率较高,直接影响整个数据库的执行效率,这里不再具体展开。
总之,时序数据库的SQL引擎,因为底层存储的时序特点,在SQL引擎侧会支持时序函数,比如聚合、降采样、其他时序相关的函数。因此在词法语法层需要添加对这些时序函数的支持,然后转换为相应的逻辑计划,按照底层时序模型的存储设计对逻辑计划进行优化,生成最终的物理计划。
举一个例子,我们在自研时序数据库中合入了时空特点,即支持时空的写入和查询,需要在ANTRL解析器层支持Point数据类型和BBOX的查询语义,首先先定义好词法和语法文件,然后使用对语法树进行解析生成特定的时空相关逻辑计划,然后对逻辑计划进行转换和优化,生成物理计划,根据计划的时空类型先查询时空索引,再查询时序文件。这个过程中,需要从词法语法到底层执行逻辑,需要进行良好的抽象和优化,这基于一个良好的可扩展的架构来统一管理时空相关计划。
下面以IOTDB时序数据库为例,介绍其SQL查询引擎的MPP框架。
IOTDB时序数据库SQL引擎
IOTDB是一款时序数据库,其在2022年发布了原生分布式版本,在此版本中,实现了全新的MPP查询框架,遵循了传统关系型数据库的规则,定义出基础的查询算子,每种查询由多个查询算子组合而成,具有框架统一、易扩展、较好抽象等优点。
下面对其MPP查询框架作一个概览介绍。
主要流程

IOTDB的SQL引擎可以分为三个模块,首先原始SQL经过Parser解析器转换为语义树,然后再经过Analyzer分析语义树,这里考虑了项目内的元数据等信息,经过校验、构造等转换为逻辑计划,最后通过Optimizer优化器,对逻辑计划进行优化,转换为分布式的物理计划DistributedQueryPlan,分布式物理计划进行SubPlan构建,发送到各个机器节点进行真正执行。
在理论概念中,计划优化可以分为对逻辑计划的优化和对物理计划的优化,而两者实际比较难进行概念上的完全切分,因此一些系统中,都是进行一轮优化,直接将逻辑计划进行统一优化转换,以尽可能快速和高效的完成转换,不过IOTDB也对物理计划的优化预留了一个接口。
SQL解析
IOTDB使用了ANTLR作为其解析SQL的工具,定义了内容丰富的g4文件,可以方便的获得原始抽象语法树AST,这个AST是工具的产物,代表原始语义的逻辑关系,不便于后续方便的获取结构内容,因此IOTDB对此进行了一次封装,通过ASTVisitor遍历AST,转换为项目可用的语法树,这个转换后的语法树的节点类型为StatementNode,是所有Statement、component、Expression的父类,至此,所有项目需要用到的对象都成功实例化,并且具有树形结构的逻辑关系。
逻辑计划
对SQL解析后的项目对象结构树进行分析和解析,使用AnalyzeVisitor对象遍历AST,将构建逻辑树需要的对象封装到Analysis对象中。然后使用LogicalPlanVisitor(analysis)遍历器遍历节点,根据Analysis对象生成逻辑计划,逻辑计划将原来的StatementNode转换为PlanNode,也使用树形结构的逻辑结构表示依赖关系,这里完成了LogicalPlan的转换。
物理计划
这里分析IOTDB的第一个分布式版本,即物理计划是分布式计划。
使用查询为例,其物理计划为DistributedQueryPlan。
-
首先对逻辑计划进行rewriteSource重写节点
-
通过addExchangeNode添加shuffle节点,构建了一棵经过调整的计划树
-
然后使用优化器对树进行优化,当前只实现了LimitOffsetPushDown这个优化器,对特定条件下的查询语句能够进行谓词下推计算。
-
进行计划切分,将计划树拆解成许多的子计划subPlan,以ExchangeNode为分界起始节点,创建一个新的SubPlan,以此实现子计划划分。SubPlan也是一个树形结构,维护着拆分PlanFragment信息,PlanFragment是原始树拆分后的部分结构。至此,完成对计划树的分块切分。示意图如下图。
-
将拆分后的PlanFragmentz转化为待执行的FragmentInstance,为了分布式的执行,这里会得到多个FragmentInstance。至此,成功构建了DistributedQueryPlan,维护了分布式执行需要的FragmentInstance,SubPlan等对象,给到集群调度,分配给各个子节点执行。
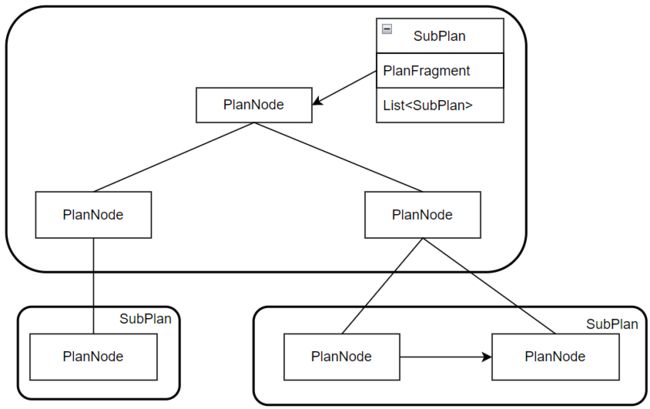
以上,对IOTDB的MPP分布式查询引擎做了简单介绍,其对各个语法和算子做了良好的封装和抽象,并且自始至终都维护着统一方式的树形结构,各个模块界限明确,在此架构上做的调整和修改都不会带来很大的架构调整,值得借鉴和学习。
小结
设计和开发时序数据库的SQL引擎,可以借鉴成熟的SQL引擎设计,选择合适的解析器工具,设计架构时,需要重点考虑函数的可扩展性,对功能的抽象,从一开始设计就应该考虑全面,不然增加一个新功能会需要大量的改动;另外,需要重点考虑和设计执行计划的优化,使用较少代价寻得最优查询路径,对原始树结构做较优的转换和裁剪;希望以上介绍对大家了解时序数据库SQL引擎的设计有所帮助。
参考资料:
1.https://www.jianshu.com/p/187c1ee85262
2.https://zhuanlan.zhihu.com/p/48735419
3.https://zhuanlan.zhihu.com/p/100949808
4.https://zhuanlan.zhihu.com/p/40478975
5.https://github.com/apache/iotdb
6.https://www.makeyourchoice.cn/archives/530/
更多内容,敬请关注同名微信公众号:时空大数据兴趣小组。
