MySQL——单行处理函数和多行处理函数
数据处理函数:
单行处理函数:一个输入对应一个输出
多行处理函数:多个输入对应一个输出
单行处理函数:
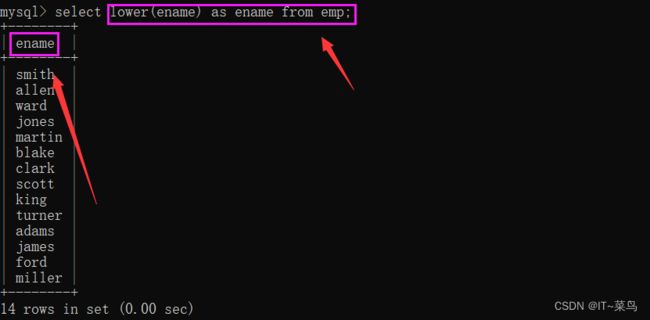
将大写转换为小写:lower(); select lower(ename) as ename from emp;
将小写转换为大写:upper(); select upper(ename) from emp;

截取字符串:substr(被截取字符串名字,截取位置下标,截取长度);注意:截取位置下标是从1 开始,不是 0!
select substr(ename,1,3) from emp;

我们利用substr 来查询第一个字母为A的名字:select ename from emp where substr(ename,1,1)='A';

让员工姓名首字母小写:select concat(lower(substr(ename,1,1)),substr(ename,2,length(ename)-1)) as newname from emp;

连接两个字符串:concat(字符串1,字符串2);
算字符串长度:length();
去除前后空格:trim();

当我们用trim就可以避免这个问题:

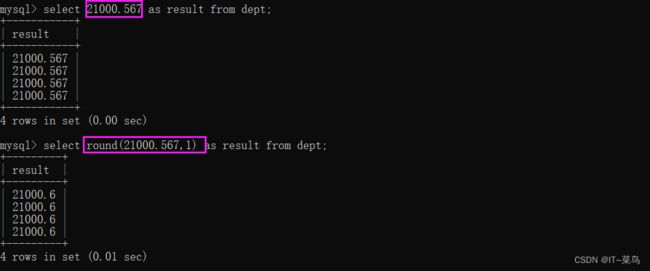
四舍五入:round(要四舍五入的数据,保留小数位数)
select 后面可以根 字段名(相当于变量名)也可以跟字面量/字面值(数据)

生成随机数:rand();
select rand() from emp;

rand()配合round()使用:
select round(rand()*100,0) from emp;

可以将null转换为想要的数:ifnull(字段,如果字段为null需要让其变成的数)
注意:在数据库运算当中,任何数于null进行数学运算的时候结果都是null
当这俩个字段的数据求和运算的时候,当某一个对应的数据为null的时候,不想其为null,所以可以将其变成想要变成的数!!!

case ......when......then........when.........then.......else.......end
当你是什么的情况下,如果是.......就.......如果是........就........否则.......结束
select ename,job,sal,(case job when 'MANAGER' then sal*1.1 when 'SALESMAN' then sal*1.5 else sal end) as result from emp;

分组函数(多行处理函数):
分组函数:必须是先分组后才能查询,分组用group by ,当没有group by 的时候,默认整张表为一组
没有分组之前不能用分组函数!!!
总览:

计数:count()

求和:sum()

平均数:avg()

最大值:max()

最小值:min()

注意:
1.分组函数自动忽略NULL,当数据当中有NULL的时候,自动跳过。
本来总共有14个数据,但最后只有4个!


2.count(*) 和count(具体字段)的区别:

‘*’:代表使用代表着一行当中所有的字段
因为没有group by ,一张表只有一个组,所以只要一行当中的数据有一个不为NULL,那么这一行数据就有效。
3.分组函数不能使用在where 当中,因为在select.....from .....where......group by.......having.......order by.....当中先是from ,然后是where ,然后是group by ,之后是having ,然后是select 最后是order by.
因为分组函数是先分组后才能使用,where 在group by 之前,那个时候group by 还没有分组,所以不能使用在where 当中!
4.所有的分组函数可以同时使用:

分组查询:
假如先给每个部门分组,然后再求每个部门的平均工资:

那我们可以加一个ename 吗?我们知道这个是毫无意义的,这个算的每个部门的平均工资,显然加上ename 毫无意义。
在mysql57 版本还能运行,在mysql80和oracle数据库当中就会报错!!!
所以在查询语句当中含有group by ,那么select 后只能跟 参与分组的字段,分组函数,其他的字段不行!!!
在select deptno,avg(sal) from emp group by deptno;当中deptno是参与分组的字段,avg(sal)是分组函数。
根据不同多个的字段进行分组:
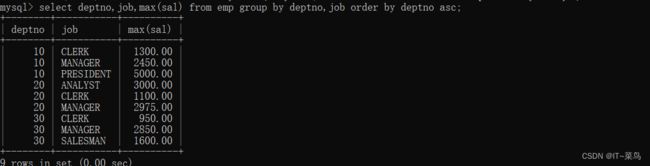
查询不同部门,不同岗位下的最高工资:
select deptno,job,max(sal) from emp group by deptno,job order by deptno;
having 必须是和group by 连用的,是对group by 进行补充的,因为有时候where 不能分组函数,所以不能解决,这个时候having 的作用就来了!
如果说where 和having同时能解决,优先使用where ,这样效率更高!
例如:找出每个部门的平均薪资,然后要求显示平均薪资高于2500的!
平均薪资这个时候要用分组函数,而且还有选择判断大于2500,这个时候where 就不行了,用having就刚刚好!

distinct 关键字
distinct:原表记录不会被修改,只是会去重。

注意:distinct 只能写在所有字段的最前面,不能只写在某一个字段的前面!
例如:当俩个字段的时候,就是结合俩个字段进行去重!

同时:distinct 也可以结合 分组函数进行使用:select count(distinct job,deptno) from emp;
