YOLOv5、YOLOv7 注意力机制改进SEAM、MultiSEAM、TripletAttention
用于学习记录
文章目录
- 前言
- 一、SEAM、MultiSEAM
-
- 1.1 models/common.py
- 1.2 models/yolo.py
- 1.3 models/SEAM.yaml
- 1.4 models/MultiSEAM.yaml
- 1.5 SEAM 训练结果图
- 1.6 MultiSEAM 训练结果图
- 二、TripletAttention
-
- 2.1 models/common.py
- 2.2 models/yolo.py
- 2.3 yolov7/cfg/training/TripletAttention.yaml
- 2.4 TripletAttention 训练结果图
前言
一、SEAM、MultiSEAM
1.1 models/common.py
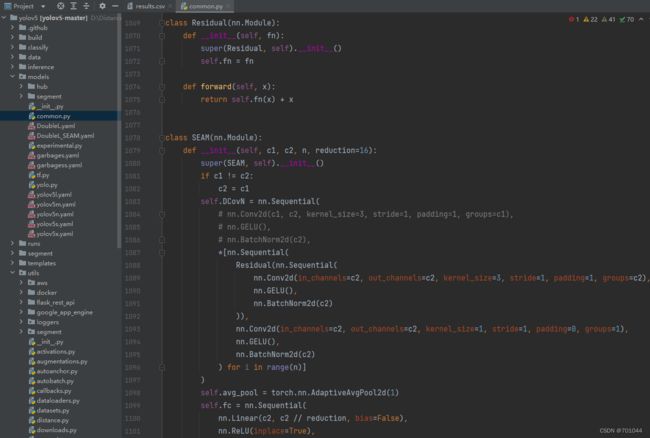
class Residual(nn.Module):
def __init__(self, fn):
super(Residual, self).__init__()
self.fn = fn
def forward(self, x):
return self.fn(x) + x
class SEAM(nn.Module):
def __init__(self, c1, c2, n, reduction=16):
super(SEAM, self).__init__()
if c1 != c2:
c2 = c1
self.DCovN = nn.Sequential(
# nn.Conv2d(c1, c2, kernel_size=3, stride=1, padding=1, groups=c1),
# nn.GELU(),
# nn.BatchNorm2d(c2),
*[nn.Sequential(
Residual(nn.Sequential(
nn.Conv2d(in_channels=c2, out_channels=c2, kernel_size=3, stride=1, padding=1, groups=c2),
nn.GELU(),
nn.BatchNorm2d(c2)
)),
nn.Conv2d(in_channels=c2, out_channels=c2, kernel_size=1, stride=1, padding=0, groups=1),
nn.GELU(),
nn.BatchNorm2d(c2)
) for i in range(n)]
)
self.avg_pool = torch.nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(c2, c2 // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(c2 // reduction, c2, bias=False),
nn.Sigmoid()
)
self._initialize_weights()
# self.initialize_layer(self.avg_pool)
self.initialize_layer(self.fc)
def forward(self, x):
b, c, _, _ = x.size()
y = self.DCovN(x)
y = self.avg_pool(y).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
y = torch.exp(y)
return x * y.expand_as(x)
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.xavier_uniform_(m.weight, gain=1)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def initialize_layer(self, layer):
if isinstance(layer, (nn.Conv2d, nn.Linear)):
torch.nn.init.normal_(layer.weight, mean=0., std=0.001)
if layer.bias is not None:
torch.nn.init.constant_(layer.bias, 0)
def DcovN(c1, c2, depth, kernel_size=3, patch_size=3):
dcovn = nn.Sequential(
nn.Conv2d(c1, c2, kernel_size=patch_size, stride=patch_size),
nn.SiLU(),
nn.BatchNorm2d(c2),
*[nn.Sequential(
Residual(nn.Sequential(
nn.Conv2d(in_channels=c2, out_channels=c2, kernel_size=kernel_size, stride=1, padding=1, groups=c2),
nn.SiLU(),
nn.BatchNorm2d(c2)
)),
nn.Conv2d(in_channels=c2, out_channels=c2, kernel_size=1, stride=1, padding=0, groups=1),
nn.SiLU(),
nn.BatchNorm2d(c2)
) for i in range(depth)]
)
return dcovn
class MultiSEAM(nn.Module):
def __init__(self, c1, c2, depth, kernel_size=3, patch_size=[3, 5, 7], reduction=16):
super(MultiSEAM, self).__init__()
if c1 != c2:
c2 = c1
self.DCovN0 = DcovN(c1, c2, depth, kernel_size