Zookeeper 与kafka 部署
kafka安装包:
https://kafka.apache.org/downloads
https://archive.apache.org/dist/kafka/
ZooKeeper安装包:
https://zookeeper.apache.org/releases.html#download
https://archive.apache.org/dist/zookeeper/
可选择:
kafka_2.11-0.10.2.2 zookeeper-3.4.9
zookeeper和kafka集群的版本适配
kafka zookeeper
kafka_2.13-2.7.0 zookeeper-3.5.8
kafka_2.13-2.6.x zookeeper-3.5.8
kafka_2.12-2.5.0 zookeeper-3.5.8
kafka_2.12-2.4.0 zookeeper-3.5.6
kafka_2.12-2.3.1 zookeeper-3.4.14
kafka_2.12-2.3.0 zookeeper-3.4.14
kafka_2.12-1.1.1 zookeeper-3.4.10
kafka_2.12-1.1.0 zookeeper-3.4.10
kafka_2.12-1.0.2 zookeeper-3.4.10
kafka_2.12-0.11.0.0 zookeeper-3.4.10
kafka_2.12-0.10.2.2 zookeeper-3.4.9
kafka_2.12-0.10.0.0 zookeeper-3.4.6
kafka_2.12-0.9.0.0 zookeeper-3.4.6
https://zhuanlan.zhihu.com/p/360095145?utm_id=0
配置文件这里不能有空格,不然会报错。
zookeeper.connect=dn1:2181,dn2:2181,dn3:2181
启动加nohup,不然关闭终端,任务就结束了。
nohup ./kafka-server-start.sh …/config/server.properties &
2.2.4 实例3:安装与配置ZookeeperZookeeper是一个分布式应用程序协调服务系统,是大数据生态圈的重要组件。Kafka、Hadoop、HBase等系统均依赖Zookeeper来提供一致性服务。Zookeeper是将复杂且容易出错的核心服务进行封装,然后对外提供简单易用、高效稳定的接口。实例描述Zookeeper安装涉及下载软件包、配置Zookeeper系统文件、配置环境变量、启动Zookeeper等操作。
1.安装Zookeeper(1)下载Zookeeper软件包。按表2-1中的地址下载3.4.6版本安装包,然后将其解压到指定位置。本书所有的安装包都会被解压到/data/soft/new目录下。(2)解压软件包。对Zookeeper软件包进行解压和重命名,具体操作命令如下:
# 解压文件命令
[hadoop@dn1~]$ tar –zxvf zookeeper-3.4.6.tar.gz
# 重命名zookeeper-3.4.6文件夹为zookeeper
[hadoop@dn1~]$ mv zookeeper-3.4.6 zookeeper
# 创建状态数据存储文件夹
[hadoop@dn1~]$ mkdir –p /data/soft/new/zkdata
2.配置Zookeeper系统文件(1)配置zoo.cfg文件。在启动Zookeeper集群之前,需要配置Zookeeper集群信息。读者可以将Zookeeper安装目录下的示例配置文件重命名,即,将zoo_sample.cfg修改为zoo.cfg。按如下所示编辑zoo.cfg文件。
# 配置需要的属性值
# zookeeper数据存放路径地址
dataDir=/data/soft/new/zkdata
# 客户端端口号
clientPort=2181
# 各个服务节点地址配置
server.1=dn1:2888:3888
server.2=dn2:2888:3888
server.3=dn3:2888:3888
(2)配置注意事项。在配置的dataDir目录下创建一个myid文件,该文件里面写入一个0~255的整数,每个Zookeeper节点上这个文件中的数字要是唯一的。本书的这些数字是从1开始的,依次对应每个Kafka节点。主机与代理节点(Broker)的对应关系如图2-7所示。
(3)操作细节。文件中的数字要与DataNode节点下的Zookeeper配置的数字保持一致。例如,server.1=dn1:2888:3888,则dn1主机下的myid配置文件应该填写数字1。在dn1主机上配置好ZooKeeper环境后,可使用scp命令将其传输到其他节点,具体命令如下。
#在/tmp目录中添加一个临时主机名文本文件
[hadoop@dn1~]$ vi /tmp/add.list
# 添加如下内容
dn2
dn3
# 保存并退出
#使用scp命令同步Zookeepers文件夹到指定目录
[hadoop@dn1~]$ for i in `cat /tmp/add.list`; do scp -r
/data/soft/new/zookeeper $i:/data/soft/new; done
完成文件传输后,dn2主机和dn3主机上的myid文件中的数字分别被修改为2和3。
3.配置环境变量在Linux操作系统中,可以对Zookeeper做全局的环境变量配置。这样做的好处是,可以很方便地使用Zookeeper脚本,不用切换到Zookeeper的bin目录下再操作。具体操作命令如下。
# 配置环境变量
[hadoop@dn1~]$ vi ~/.bash_profile
# 配置zookeeper全局变量
export ZK_HOME=/data/soft/new/zookeeper
export PATH=$PATH: $ZK_HOME/bin
# 保存编辑内容,并退出
之后,用以下命令使刚刚配置的环境变量立即生效:
# 使环境变量立即生效
[hadoop@dn1~]$ source ~/.bash_profile
接着,在其他两台主机上也做相同的配置操作。
4.启动Zookeeper在安装了Zookeeper的节点上,分别执行启动进程的命令:
# 在不同的节点上启动zookeeper服务进程
[hadoop@dn1~]$ zkServer.sh start
[hadoop@dn2~]$ zkServer.sh start
[hadoop@dn3~]$ zkServer.sh start
但这样管理起来不够方便。可以对上述启动命令进行改进,例如编写一个分布式启动脚本(zk-daemons.sh),具体如下:
# 编写Zookeeper分布式启动脚本,可以输入start|stop|restart|status等命令
#! /bin/bash
hosts=(dn1 dn2 dn3)
for i in ${hosts[@]}
do
ssh hadoop@$i "source /etc/profile; zkServer.sh $1" &
done
5.验证
完成启动命令后,在终端中输入jps命令。若显示QuorumPeerMain进程名称,即表示服务进程启动成功。也可以使用Zookeeper的状态命令status来查看,具体操作命令如下。
# 使用status命令来查看
[hadoop@dn1~]$ zk-daemons.sh status
结果如图2-8所示。在Zookeeper集群运行正常的情况下,若有三个节点,则会选举出一个Leader和两个Follower。
读者也可以查看Zookeeper的运行日志zookeeper.out文件,其中记录了Zookeeper的启动过程以及运行过程。
2.3 实例4:部署Kafka。
安装Kafka比较简单,单机模式和分布式模式的部署步骤基本一致。由于生产环境所使用的操作系统一般是Linux,所以本书Kafka集群的部署也是基于Linux操作系统来完成的。实例描述:按两种模式部署(单机模式部署和分布式模式)Kafka系统,并观察结果。
2.3.1 单机模式部署
如果是测试环境或需要在本地调试Kafka应用程序代码,则会以单机模式部署一个Kafka系统。部署的步骤也非常简单:启动一个Standalone模式的Zookeeper,然后启动一个Kafka Broker进程。
本书选择的Kafka安装包版本是0.10.2.0,读者在学习本书时,Kafka官方可能发布了更新的版本。读者可以选择更新的版本来安装,其配置过程依然可以参考本书所介绍的,这并不影响对本书的学习。
1.下载Kafka安装包
访问Kafka官方网站,找到下载地址,然后在Linux操作系统中使用wget命令进行下载。具体操作命令如下。
# 使用wget命令下载安装包
[hadoop@dn1~]$ wget https://archive.apache.org/dist/kafka/0.10.2.0\
/kafka_2.11-0.10.2.0.tgz
2.解压Kafka安装包下载了Kafka安装包后,在Linux操作系统指定位置进行解压操作。具体操作命令如下。
# 解压安装包
[hadoop@dn1~]$ tar -zxvf kafka_2.11-0.10.2.0.tgz
# 重命名
[hadoop@dn1~]$ mv kafka_2.11-0.10.2.0 kafka
3.配置Kafka全局变量
在/home/hadoop/.bash_profile文件中,配置Kafka系统的全局变量。具体操作命令如下。
# 编辑.bash_profile文件
[hadoop@dn1~]$ vi ~/.bash_profile
# 添加如下内容
export KAFKA_HOME=/data/soft/new/kafka
export PATH=$PATH:$KAFKA_HOME/bin
# 保存并退出
接着,使用source命令使刚刚配置的环境变量立即生效:
# 使用source命令使配置立即生效
[hadoop@dn1~]$ source ~/.bash_profile
4.配置Kafka系统
配置单机模式的Kafka系统步骤比较简单,只需要在$KAFKA_HOME/conf/server.properties文件中做少量的配置即可。具体操作命令如下。
# 配置server.properties文件
[hadoop@dn1~]$ vi $KAFKA_HOME/conf/server.properties
# 修改如下内容
broker.id=0 # 设置一个broker唯一ID
log.dirs=/data/soft/new/kafka/data # 设置消息日志存储路径
zookeeper.connect=localhost:2181 # 指定Zookeeper的连接地址
# 然后保存并退出
5.启动Zookeeper
以Standalone模式启动Zookeeper进程,具体操作命令如下
# 启动Standalone模式Zookeeper
[hadoop@dn1~]$ zkServer.sh start
# 查看Zookeeper状态
[hadoop@dn1~]$ zkServer.sh status
# 终端会显示如下内容
JMX enabled by default
Using config: /data/soft/new/zookeeper/bin/../conf/zoo.cfg
Mode: standalone
6.启动Kafka单机模式
在当前主机上使用Kafka命令来启动Kafka系统,具体操作命令如下。
# 启动Kafka单机模式
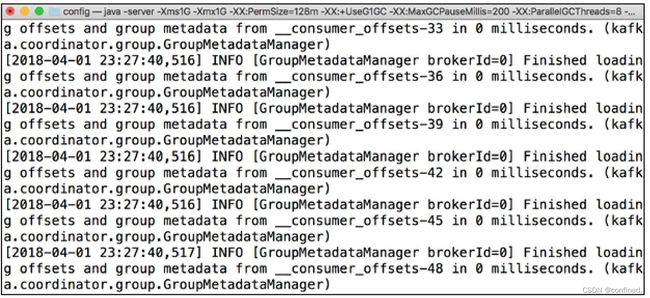
[hadoop@dn1~]$ kafka-server-start.sh $KAFKA_HOME/conf/server.properties &
启动成功后,终端会打印出如图所示信息。
2.3.2 分布式模式部署
在生产环境中,一般会以分布式模式来部署Kafka系统,以便组建集群。
在分布式模式中,不推荐使用Standalone模式的Zookeeper,这样具有一定的风险。如果使用的是Standalone模式的Zookeeper,则一旦Zookeeper出现故障则导致整个Kafka集群不可用。所以,一般在生产环境中会以集群的形式来部署ZooKeeper。
1.下载
和单机模式的下载步骤一致。
2.解压
可参考单机模式的解压模式和重命名方法。
3.配置Kafka全局变量
可参考单机模式的全局配置过程。
4.配置Kafka系统在分布式模式下配置Kafka系统和单机模式不一致。
打开$KAFKA_HOME/conf/server. properties文件,编辑相关属性,具体修改内容见代码2-1。
代码2-1 Kafka系统属性文件配置
# 设置Kafka节点唯一ID
broker.id=0
# 开启删除Kafka主题属性
delete.topic.enable=true
# 非SASL模式配置Kafka集群
listeners=PLAINTEXT://dn1:9092
# 设置网络请求处理线程数
num.network.threads=10
# 设置磁盘IO请求线程数
num.io.threads=20
# 设置发送buffer字节数
socket.send.buffer.bytes=1024000
# 设置收到buffer字节数
socket.receive.buffer.bytes=1024000
# 设置最大请求字节数
socket.request.max.bytes=1048576000
# 设置消息记录存储路径
log.dirs=/data/soft/new/kafka/data
# 设置Kafka的主题分区数
num.partitions=6
# 设置主题保留时间
log.retention.hours=168
# 设置Zookeeper的连接地址(这里好像有空格,不然会报错)
zookeeper.connect=dn1:2181,dn2:2181,dn3:2181
# 设置Zookeeper连接超时时间
zookeeper.connection.timeout.ms=60000
5.同步安装包
配置好一个主机上的Kafka系统后,使用Linux同步命令将配置好的Kafka文件夹同步到其他的主机上。具体操作命令如下。
#在/tmp目录中添加一个临时主机名文本文件
[hadoop@dn1~]$ vi /tmp/add.list
# 添加如下内容
dn2
dn3
# 保存并退出
#使用scp命令同步Kafka文件夹到指定目录中
[hadoop@dn1~]$ for i in `cat /tmp/add.list`; do scp -r /data/soft/new/kafka
$i:/data/soft/new; done
由于Kafka集群中每个代理(Broker)节点的ID必须唯一,所以同步完成后需要将其他两台主机上的broker.id属性值修改为1和2(或者是其他不重复的正整数)。
6.启动Zookeeper集群
在启动Kafka集群之前,需要先启动Zookeeper集群。启动Zookeeper集群无须在每台主机上分别执行Zookeeper启动命令,只需执行分布式启动命令即可:
# 分布式命令启动Zookeeper
[hadoop@dn1~]$ zk-daemons.sh start
7.启动Kafka集群
Kafka系统本身没有分布式启动Kafka集群的功能,只有单个主机节点启动Kafka进程的脚本。可以通过封装单个节点启动Kafka进程的步骤,来实现分布式启动Kafka集群,具体见代码2-2。
代码2-2 Kafka分布式启动
#! /bin/bash
# 配置Kafka代理(Broker)地址信息
hosts=(dn1 dn2 dn3)
for i in ${hosts[@]}
do
# 执行启动Kafka进程命令
ssh hadoop@$i "source /etc/profile; kafka-server-start.sh
$KAFKA_HOME/config/server.properties" &
done
8.验证
启动Kafka集群后,可以通过一些简单的Kafka命令来验证集群是否正常。具体如下。
# 使用list命令来展示Kafka集群的所有主题(Topic)名
[hadoop@dn1~]$ kafka-topics.sh --list -zookeeper
dn1:2181, dn2:2181, dn3:2181
执行后,Linux终端会打印出所有的Kafka主题(Topic)名称,如图2-10所示。

从图2-10中可以看出,除打印Kafka业务数据的主题(Topic)名称外,还打印出Kafka系统内部主题——_ _consumer_offsets,该主题用来记录Kafka消费者(Consumer)产生的消费记录,其中包含偏移量(Offset)、时间戳(Timestamp)和线程名等信息。
转载自:
Kafka并不难学!入门、进阶、商业实战 邓杰编著(第二章)
https://weread.qq.com/web/reader/bb03287071848770bb0d2c4?
http://product.dangdang.com/25580334.html
https://book.douban.com/subject/30376055/