爬虫项目(二):中国大学排名
《Python网络爬虫入门到实战》京东购买地址,这里讲解了大量的基础知识和实战,由本人编著:https://item.jd.com/14049708.html
配套代码仓库地址:https://github.com/sfvsfv/Crawer
文章目录
-
- 分析
- 第一步:获取源码
- 分析第一页
- 获取页数
- AJAX分析,获取完整数据
- 数据保存到CSV文件中
- 完整源码
- 视频讲解
分析
目标:https://www.shanghairanking.cn/rankings/bcur/2023
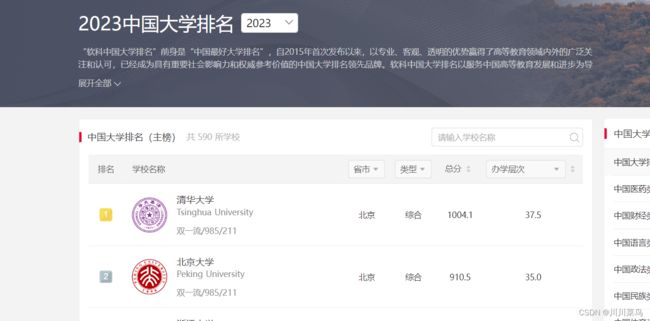
感兴趣的会发现:
2022年为:https://www.shanghairanking.cn/rankings/bcur/202211
2021年为:https://www.shanghairanking.cn/rankings/bcur/202111
同理。。。。
第一步:获取源码
def get_one_page(year):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'
}
# https://www.shanghairanking.cn/rankings/bcur/%s11
url = 'https://www.shanghairanking.cn/rankings/bcur/%s11' % (str(year))
print(url)
response = requests.get(url, headers=headers)
if response.content is not None:
content = response.content.decode('utf-8')
print(content.encode('gbk', errors='ignore').decode('gbk'))
else:
content = ""
print(content.encode('gbk', errors='ignore').decode('gbk'))
except RequestException:
print('爬取失败')
get_one_page(2023)
输出如下:
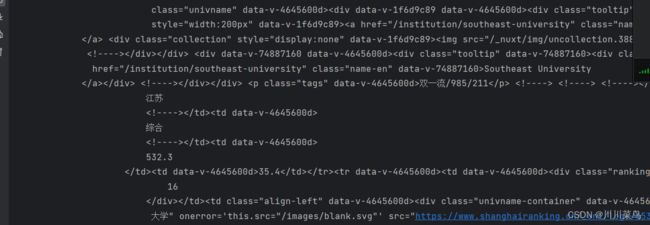
正式则改为return即可:
return content.encode('gbk', errors='ignore').decode('gbk')
于是你就完成了一个完整的源码获取函数:
# coding= gbk
import pandas as pd
import csv
import requests
from requests.exceptions import RequestException
from bs4 import BeautifulSoup
import time
import re
start_time = time.time() # 计算程序运行时间
# 获取网页内容
def get_one_page(year):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'
}
# https://www.shanghairanking.cn/rankings/bcur/%s11
url = 'https://www.shanghairanking.cn/rankings/bcur/%s11' % (str(year))
# print(url)
response = requests.get(url, headers=headers)
if response.content is not None:
content = response.content.decode('utf-8')
# print(content.encode('gbk', errors='ignore').decode('gbk'))
return content.encode('gbk', errors='ignore').decode('gbk')
else:
content = ""
return content.encode('gbk', errors='ignore').decode('gbk')
# print(content.encode('gbk', errors='ignore').decode('gbk'))
except RequestException:
print('爬取失败')
data = get_one_page(2023)
print(data)
运行如下:
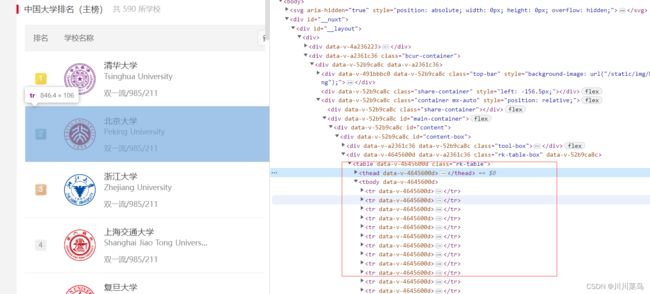
分析第一页
定位内容:

代码如下:
def extract_university_info(data):
soup = BeautifulSoup(data, 'html.parser')
table = soup.find('table', {'data-v-4645600d': "", 'class': 'rk-table'})
tbody = table.find('tbody', {'data-v-4645600d': ""})
rows = tbody.find_all('tr')
university_info = []
for row in rows:
rank = row.find('div', {'class': 'ranking'}).text.strip()
univ_name_cn = row.find('a', {'class': 'name-cn'}).text.strip()
univ_name_en = row.find('a', {'class': 'name-en'}).text.strip()
location = row.find_all('td')[2].text.strip()
category = row.find_all('td')[3].text.strip()
score = row.find_all('td')[4].text.strip()
rating = row.find_all('td')[5].text.strip()
info = {
"排名": rank,
"名称": univ_name_cn,
"Name (EN)": univ_name_en,
"位置": location,
"类型": category,
"总分": score,
"评分": rating
}
university_info.append(info)
return university_info
data = get_one_page(2023)
print(extract_university_info(data))
运行如下:

获取页数
数据在多个页面中,如下:

获取总页面代码如下:
def get_total_pages(pagination_html):
soup = BeautifulSoup(pagination_html, 'html.parser')
pages = soup.find_all('li', class_='ant-pagination-item')
if pages:
return int(pages[-1].text)
return 1
total_pages = get_total_pages(data)
print(total_pages)
运行如下:

AJAX分析,获取完整数据
由于页面的 URL 在切换分页时不发生变化,这通常意味着页面是通过 AJAX 或其他 JavaScript 方法动态加载的。所以直接循环行不通。所以只能用selenium来。
完整代码如下:
# coding= gbk
import pandas as pd
import csv
import requests
from requests.exceptions import RequestException
from bs4 import BeautifulSoup
import time
from selenium.webdriver.chrome.service import Service # 新增
from selenium.webdriver.common.by import By
start_time = time.time() # 计算程序运行时间
# 获取网页内容
def get_one_page(year):
try:
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36'
}
# https://www.shanghairanking.cn/rankings/bcur/%s11
url = 'https://www.shanghairanking.cn/rankings/bcur/%s11' % (str(year))
# print(url)
response = requests.get(url, headers=headers)
if response.content is not None:
content = response.content.decode('utf-8')
# print(content.encode('gbk', errors='ignore').decode('gbk'))
return content.encode('gbk', errors='ignore').decode('gbk')
else:
content = ""
return content.encode('gbk', errors='ignore').decode('gbk')
# print(content.encode('gbk', errors='ignore').decode('gbk'))
except RequestException:
print('爬取失败')
def extract_university_info(data):
soup = BeautifulSoup(data, 'html.parser')
table = soup.find('table', {'data-v-4645600d': "", 'class': 'rk-table'})
tbody = table.find('tbody', {'data-v-4645600d': ""})
rows = tbody.find_all('tr')
university_info = []
for row in rows:
rank = row.find('div', {'class': 'ranking'}).text.strip()
univ_name_cn = row.find('a', {'class': 'name-cn'}).text.strip()
univ_name_en = row.find('a', {'class': 'name-en'}).text.strip()
location = row.find_all('td')[2].text.strip()
category = row.find_all('td')[3].text.strip()
score = row.find_all('td')[4].text.strip()
rating = row.find_all('td')[5].text.strip()
info = {
"排名": rank,
"名称": univ_name_cn,
"Name (EN)": univ_name_en,
"位置": location,
"类型": category,
"总分": score,
"评分": rating
}
university_info.append(info)
# 打印数据
print(
f"排名: {rank}, 名称: {univ_name_cn}, Name (EN): {univ_name_en}, 位置: {location}, 类型: {category}, 总分: {score}, 评分: {rating}"
)
return university_info
# data = get_one_page(2023)
# 获取一个页面内容
# print(extract_university_info(data))
def get_total_pages(pagination_html):
soup = BeautifulSoup(pagination_html, 'html.parser')
pages = soup.find_all('li', class_='ant-pagination-item')
if pages:
return int(pages[-1].text)
return 1
html = get_one_page(2023)
def get_data_from_page(data):
content = extract_university_info(data)
return content
total_pages=get_total_pages(html)
print(total_pages)
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.keys import Keys
service = Service(executable_path='chromedriver.exe')
browser = webdriver.Chrome(service=service)
browser.get("https://www.shanghairanking.cn/rankings/bcur/202311")
for page in range(1, total_pages + 1):
jump_input_locator = (By.XPATH, '//div[@class="ant-pagination-options-quick-jumper"]/input')
jump_input = WebDriverWait(browser, 10).until(
EC.element_to_be_clickable(jump_input_locator)
)
jump_input.clear()
jump_input.send_keys(page) # 输入页码
jump_input.send_keys(Keys.RETURN) # 模拟 Enter 键
time.sleep(3) # 等待页面加载
html = browser.page_source
get_data_from_page(html)
time.sleep(3)
browser.quit()
运行如下:

数据保存到CSV文件中
写一个函数用来存储:
def write_to_csv(data_list, filename='output.csv'):
with open(filename, 'w', newline='', encoding='utf-8') as csvfile:
fieldnames = ["排名", "名称", "Name (EN)", "位置", "类型", "总分", "评分"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader() # 写入表头
for data in data_list:
writer.writerow(data)
添加到获取部分:
content = get_data_from_page(html)
write_to_csv(content)
完整源码
到我的仓库复制即可:
https://github.com/sfvsfv/Crawer
视频讲解
https://www.bilibili.com/video/BV1j34y1T7WJ/