VGGNet剪枝实战:使用VGGNet训练、稀疏训练、剪枝、微调等,剪枝出只有3M的模型
文章目录
- 摘要
-
- 剪枝的原理
- 剪枝的过程
- 1、项目结构
- 2、测试结果
- 3、VGGNet模型
- 4、需要安装的库
- 5、训练VGGNet
-
- 5.1、导入项目所需要的库
- 5.2、设置随机因子
- 5.3、BN层可视化
- 5.4、定义全局参数
- 5.5、数据增强
- 5.6、加载数据
- 5.7、定义Loss
- 5.8、定义模型、优化器以及学习率调整策略
- 5.9、训练函数
- 5.10、验证函数
- 5.11、训练、验证、保存模型
- 5.12、测试结果
- 6、稀疏训练VGGNet
- 6、剪枝
-
- 6.1、导入库文件
- 6.2、测试函数
- 6.3、定义全局参数
- 6.4、BN通道排序
- 6.5、制作Mask
- 6.6、剪枝操作
- 7、微调
-
- 7.1、微调方法
- 7.2、微调结果
摘要
本文讲解如何实现VGGNet的剪枝操作。采用的剪枝方法是基于BN层系数gamma剪枝。本文用到的代码和数据集详见:
https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/88180649
剪枝的原理
在一个卷积-BN-激活模块中,BN层可以实现通道的缩放。如下:

BN层的具体操作有两部分:
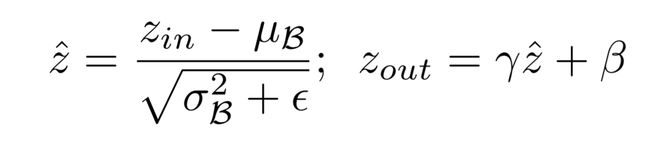
在归一化后会进行线性变换,那么当系数gamma很小时候,对应的激活(Zout)会相应很小。这些响应很小的输出可以裁剪掉,这样就实现了bn层的通道剪枝。
剪枝的过程
在BN层网络中加入稀疏因子,训练使得BN层稀疏化,对稀疏训练的后的模型中所有BN层权重进行统计排序,获取指定保留BN层数量即取得排序后权重阈值thres。遍历模型中的BN层权重,制作各层mask(权重>thres值为1,权重 通过本文你可以学到: 剪枝流程分为: 接下来,我们一起实现对VGGNet的剪枝。 train.py:训练脚本,训练VGGNet原始模型 VGGNet在原有的基础做了修改,增加了模型的cfg,定义了每层卷积的channel,“M”代表池化。 1、tim库 2、sklearn 3、tensorboard 新建 设置随机因子后,再次训练时,图像的加载顺序不会改变,能够更好的复现训练结果。代码如下: 使用tensorboard 可视化BN的状态,方便对比! 全局参数包括学习率、批大小、轮数、类别数量等一些模型用到的超参数。 增强选用了AutoAugment,自动增强,默认是ImageNet的增强。在实际的项目中,需要选用适合的方式来增强图像数据。过多增强或带来负面的影响。 声明MIxUp函数,Mix是一种非常有效的增强方法。加入之后不仅可以提高ACC,对泛化性也有很大的提高。 这里注意下Resize的大小,由于选用的ResNet模型输入是224×224的大小,所以要Resize为224×224。 加载训练集和验证集的数据,并将class_to_idx保存。然后分别声明训练和验证的DataLoader。 多类别分类的loss一般使用交叉熵。代码如下: SoftTargetCrossEntropy,成为软交叉熵,当Label做了平滑之后,使用SoftTargetCrossEntropy。 模型就选用前面定义的VGG模型。 训练的主要步骤: 1、 model.train()切换成训练模型。启用 BatchNormalization 和 Dropout。初始化sum_loss 为0,计算训练集图片的数量赋给total_num。correct设置为0 等待一个epoch训练完成后,计算平均loss。然后将其打印出来。并返回loss和acc。 验证过程增加了对预测数据和Label数据的保存,所以,需要定义两个list保存,然后将其返回! 验证的过程和训练的过程大致相似,主要步骤: 1、model.eval(),切换验证模型,不启用 BatchNormalization 和 Dropout。 将label保存到val_list。 思路: 然后,点击 新建train_sp.py脚本。稀疏化训练的过程和正常训练类似,不同的是在BN层中各权重加入稀疏因子,代码如下: 加入到train函数中,如图: 训练完成后,就可以使用tensorboard观察训练结果,在根目录运行: 然后看到如下信息: 在浏览器中打开 新建prune.py脚本,这个脚本是剪枝脚本。 测试函数,用来测试剪枝后的模型ACC,代码如下: BATCH_SIZE:测试函数的BatchSize。 剪枝后保存模型 微调方法和正常训练类似,加载剪枝后的模型和配置,然后训练、验证即可!
1、如何使用VGGNet训练模型。
2、如何使用VGGNet稀疏训练模型。
3、如何实现剪枝,已及保存剪枝模型和使用剪枝模型预测等操作。
4、如何微调剪枝模型。
第一步、使用VGGNet训练模型。保存训练结果,方便将来的比对!
第二步、在BN层网络中加入稀疏因子,训练模型。
第三步、剪枝操作。
第四步、fine-tune模型,提高模型的ACC。1、项目结构
Slimming_Demo
├─checkpoints
│ ├─vgg
│ ├─vgg_pruned
│ └─vgg_sp
├─data
│ ├─train
│ │ ├─Black-grass
│ │ ├─Charlock
│ │ ├─Cleavers
│ │ ├─Common Chickweed
│ │ ├─Common wheat
│ │ ├─Fat Hen
│ │ ├─Loose Silky-bent
│ │ ├─Maize
│ │ ├─Scentless Mayweed
│ │ ├─Shepherds Purse
│ │ ├─Small-flowered Cranesbill
│ │ └─Sugar beet
│ └─val
│ ├─Black-grass
│ ├─Charlock
│ ├─Cleavers
│ ├─Common Chickweed
│ ├─Common wheat
│ ├─Fat Hen
│ ├─Loose Silky-bent
│ ├─Maize
│ ├─Scentless Mayweed
│ └─Shepherds Purse
├─vgg.py
├─train.py
├─train_sp.py
├─prune.py
└─train_prune.py
vgg.py:模型脚本
train_sp.py:稀疏训练脚本。
prune.py:模型剪枝脚本。
train_prune.py:微调模型脚本。2、测试结果
模型
大小
ACC
VGG模型
67.4M
95.6%
VGG裁剪模型
3.58M
95%
3、VGGNet模型
import torch
import torch.nn as nn
from torch.autograd import Variable
import math # init
class VGG(nn.Module):
def __init__(self, num_classes, init_weights=True, cfg=None):
super(VGG, self).__init__()
if cfg is None:
cfg = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 'M']
self.feature = self.make_layers(cfg, True)
print(self.feature)
self.classifier = nn.Linear(cfg[-2], num_classes)
if init_weights:
self._initialize_weights()
def make_layers(self, cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1, bias=False)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.LeakyReLU(inplace=True)]
else:
layers += [conv2d, nn.LeakyReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
def forward(self, x):
x = self.feature(x)
x = nn.AdaptiveAvgPool2d(1)(x)
x = x.view(x.size(0), -1)
y = self.classifier(x)
return y
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(0.5)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
if __name__ == '__main__':
net = VGG(12)
print(net)
x = Variable(torch.FloatTensor(1, 3, 224, 224))
y = net(x)
print(y.data.shape)
4、需要安装的库
pip install timm
pip install -U scikit-learn
pip install tensorboard
5、训练VGGNet
train.py脚本。接下来,详解train.py脚本中的代码。5.1、导入项目所需要的库
import torch.optim as optim
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
from sklearn.metrics import classification_report
from vgg import VGG
import os
from torchvision import datasets
import json
import matplotlib.pyplot as plt
from timm.data.mixup import Mixup
from timm.loss import SoftTargetCrossEntropy
import warnings
from torch.utils.tensorboard import SummaryWriter
warnings.filterwarnings("ignore")
5.2、设置随机因子
def seed_everything(seed=42):
os.environ['PYHTONHASHSEED'] = str(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
5.3、BN层可视化
writer = SummaryWriter(comment='vgg')
def showBN(model):
# =============== show bn weights ===================== #
module_list = []
module_bias_list = []
for i, layer in model.named_modules():
if isinstance(layer, nn.BatchNorm2d) :
bnw = layer.state_dict()['weight']
bnb = layer.state_dict()['bias']
module_list.append(bnw)
module_bias_list.append(bnb)
size_list = [idx.data.shape[0] for idx in module_list]
bn_weights = torch.zeros(sum(size_list))
bnb_weights = torch.zeros(sum(size_list))
index = 0
for idx, size in enumerate(size_list):
bn_weights[index:(index + size)] = module_list[idx].data.abs().clone()
bnb_weights[index:(index + size)] = module_bias_list[idx].data.abs().clone()
index += size
print("bn_weights:", torch.sort(bn_weights))
print("bn_bias:", torch.sort(bnb_weights))
writer.add_histogram('bn_weights/hist', bn_weights.numpy(), epoch, bins='doane')
writer.add_histogram('bn_bias/hist', bnb_weights.numpy(), epoch, bins='doane')
5.4、定义全局参数
if __name__ == '__main__':
# 创建保存模型的文件夹
file_dir = 'checkpoints/vgg'
if os.path.exists(file_dir):
print('true')
os.makedirs(file_dir, exist_ok=True)
else:
os.makedirs(file_dir)
# 设置全局参数
model_lr = 1e-4
BATCH_SIZE = 16
EPOCHS = 300
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
classes = 12
resume = None
Best_ACC = 0 # 记录最高得分
SEED = 42
seed_everything(42)
start_epoch = 1
5.5、数据增强
t = [transforms.CenterCrop((224, 224)), transforms.GaussianBlur(kernel_size=(5, 5), sigma=(0.1, 3.0)),
transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5)]
# 数据预处理7
transform = transforms.Compose([
transforms.AutoAugment(),
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.48214436, 0.42969334, 0.33318862], std=[0.2642221, 0.23746745, 0.21696019])
])
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.48214436, 0.42969334, 0.33318862], std=[0.2642221, 0.23746745, 0.21696019])
])
mixup_fn = Mixup(
mixup_alpha=0.8, cutmix_alpha=1.0, cutmix_minmax=None,
prob=0.1, switch_prob=0.5, mode='batch',
label_smoothing=0.1, num_classes=classes)
5.6、加载数据
# 读取数据
dataset_train = datasets.ImageFolder('data/train', transform=transform)
dataset_test = datasets.ImageFolder("data/val", transform=transform_test)
with open('class.txt', 'w',encoding='utf-8') as file:
file.write(str(dataset_train.class_to_idx))
with open('class.json', 'w', encoding='utf-8') as file:
file.write(json.dumps(dataset_train.class_to_idx))
# 导入数据
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, pin_memory=True, shuffle=True,
drop_last=True)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, pin_memory=True, shuffle=False)
5.7、定义Loss
# 实例化模型并且移动到GPU
criterion_train = SoftTargetCrossEntropy().cuda()
criterion_val = torch.nn.CrossEntropyLoss().cuda()
5.8、定义模型、优化器以及学习率调整策略
# 设置模型
model_ft = VGG(classes,True)
if resume:
model = torch.load(resume)
model_ft.load_state_dict(model['state_dict'])
Best_ACC = model['Best_ACC']
start_epoch = model['epoch'] + 1
model_ft.to(DEVICE)
print(model_ft)
# 选择简单暴力的Adam优化器,学习率调低
optimizer = optim.AdamW(model_ft.parameters(), lr=model_lr)
cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=20, eta_min=1e-6)
优化器选用AdamW。
学习率调整策略选用CosineAnnealingLR。5.9、训练函数
# 定义训练过程
def train(model, device, train_loader, optimizer, epoch, criterion,epochs):
model.train()
sum_loss = 0
correct = 0
total_num = len(train_loader.dataset)
print(total_num, len(train_loader))
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device, non_blocking=True), target.to(device, non_blocking=True)
samples, targets = mixup_fn(data, target)
output = model(samples)
loss = criterion(output, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print_loss = loss.data.item()
_, pred = torch.max(output.data, 1)
correct += torch.sum(pred == target)
sum_loss += print_loss
if (batch_idx + 1) % 10 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
100. * (batch_idx + 1) / len(train_loader), loss.item()))
ave_loss = sum_loss / len(train_loader)
correct = correct.data.item()
acc = correct / total_num
print('epoch:{},loss:{}'.format(epoch, ave_loss))
return ave_loss, acc
2、进入循环,将data和target放入device上,non_blocking设置为True。如果pin_memory=True的话,将数据放入GPU的时候,也应该把non_blocking打开,这样就只把数据放入GPU而不取出,访问时间会大大减少。
如果pin_memory=False时,则将non_blocking设置为False。
3、samples, targets = mixup_fn(data, target),使用mixup_fn方式,计算Mixup后的图像数据和标签数据。然后,将Mixup后的图像数据samples输入model,输出预测结果,然后再计算loss。
4、 optimizer.zero_grad() 梯度清零,把loss关于weight的导数变成0。
5、反向传播求梯度。
6、获取loss,并赋值给print_loss 。
7、torch.sum(pred == target)计算当前Batch内,预测正确的数量,然后累加到correct 。
8、sum_loss 累加print_loss ,求得总的loss。所以,单个epoch的loss就是总的sum_loss 除以train_loader的长度。5.10、验证函数
# 验证过程
def val(model, device, test_loader,criterion):
model.eval()
test_loss = 0
correct = 0
total_num = len(test_loader.dataset)
print(total_num, len(test_loader))
val_list = []
pred_list = []
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device, non_blocking=True), target.to(device, non_blocking=True)
for t in target:
val_list.append(t.data.item())
output = model(data)
loss = criterion(output, target)
_, pred = torch.max(output.data, 1)
for p in pred:
pred_list.append(p.data.item())
correct += torch.sum(pred == target)
print_loss = loss.data.item()
test_loss += print_loss
correct = correct.data.item()
acc = correct / total_num
avgloss = test_loss / len(test_loader)
print('\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
avgloss, correct, len(test_loader.dataset), 100 * acc))
return val_list, pred_list, avgloss, acc
2、定义参数:
test_loss : 测试的loss
correct :统计正确类别的数量。
total_num:验证集图片的总数。
val_list :保存验证集的Label数据。
pred_list :保存预测的Label数据。
3、torch.no_grad():反向传播时就不会自动求导了。
4、进入循环,迭代test_loader:
5、acc = correct / total_num,计算出acc。 avgloss = test_loss / len(test_loader)计算loss。 最后返回val_list, pred_list,loss,acc
将data和target放入device上,non_blocking设置为True。
遍历target,将Label保存到val_list 。
将data输入到model中,求出预测值,然后输入到loss函数中,求出loss。在验证集中,不用求辅助分类器的loss。
调用torch.max函数,将预测值转为对应的label。
遍历pred,将预测的Label保存到pred_list。
correct += torch.sum(pred == target),计算出识别对的数量,并累加到correct 变量上。5.11、训练、验证、保存模型
# 训练
log_dir = {}
train_loss_list, val_loss_list, train_acc_list, val_acc_list, epoch_list = [], [], [], [], []
if resume and os.path.isfile("result.json"):
with open('result.json', 'r', encoding='utf-8') as file:
logs = json.load(file)
train_acc_list = logs['train_acc']
train_loss_list = logs['train_loss']
val_acc_list = logs['val_acc']
val_loss_list = logs['val_loss']
epoch_list = logs['epoch_list']
for epoch in range(start_epoch, EPOCHS + 1):
epoch_list.append(epoch)
log_dir['epoch_list'] = epoch_list
train_loss, train_acc = train(model_ft, DEVICE, train_loader, optimizer, epoch, criterion_train,epochs=EPOCHS)
showBN(model_ft)
train_loss_list.append(train_loss)
train_acc_list.append(train_acc)
log_dir['train_acc'] = train_acc_list
log_dir['train_loss'] = train_loss_list
val_list, pred_list, val_loss, val_acc = val(model_ft, DEVICE, test_loader, criterion_val)
print(classification_report(val_list, pred_list, target_names=dataset_train.class_to_idx))
val_loss_list.append(val_loss)
val_acc_list.append(val_acc)
log_dir['val_acc'] = val_acc_list
log_dir['val_loss'] = val_loss_list
log_dir['best_acc'] = Best_ACC
with open('result.json', 'w', encoding='utf-8') as file:
file.write(json.dumps(log_dir))
if val_acc >= Best_ACC:
Best_ACC = val_acc
torch.save(model_ft, file_dir + "/" + 'best.pth')
state = {
'epoch': epoch,
'state_dict': model_ft.state_dict(),
'Best_ACC': Best_ACC
}
torch.save(state, file_dir + "/" + 'model_' + str(epoch) + '_' + str(round(val_acc, 3)) + '.pth')
cosine_schedule.step()
fig = plt.figure(1)
plt.plot(epoch_list, train_loss_list, 'r-', label=u'Train Loss')
# 显示图例
plt.plot(epoch_list, val_loss_list, 'b-', label=u'Val Loss')
plt.legend(["Train Loss", "Val Loss"], loc="upper right")
plt.xlabel(u'epoch')
plt.ylabel(u'loss')
plt.title('Model Loss ')
plt.savefig(file_dir + "/loss.png")
plt.close(1)
fig2 = plt.figure(2)
plt.plot(epoch_list, train_acc_list, 'r-', label=u'Train Acc')
plt.plot(epoch_list, val_acc_list, 'b-', label=u'Val Acc')
plt.legend(["Train Acc", "Val Acc"], loc="lower right")
plt.title("Model Acc")
plt.ylabel("acc")
plt.xlabel("epoch")
plt.savefig(file_dir + "/acc.png")
plt.close(2)
定义记录log的字典,声明loss和acc的list。如果是接着上次的断点继续训练则读取log文件,然后把log取出来,赋值到对应的list上。
循环调用train函数和val函数,train函数返回train_loss, train_acc,val函数返回val_list, pred_list, val_loss, val_acc。loss和acc用于绘制曲线。
记录BN的权重状态。
将log字典保存到json文件中。
将val_list, pred_list和dataset_train.class_to_idx传入模型,计算模型指标。
判断acc是否大于Best_ACC,如果大于则保存模型,这里保存的是整个模型。
接下来是保存每个epoch的模型,新建state ,字典的参数:
- epoch:当前的epoch。
- state_dict:权重参数。 model_ft.state_dict(),只保存模型的权重参数。
- Best_ACC:Best_ACC的数值。
然后,调用 torch.save保存模型。
cosine_schedule.step(),执行学习率调整算法。
最后使用plt.plot绘制loss和acc曲线图
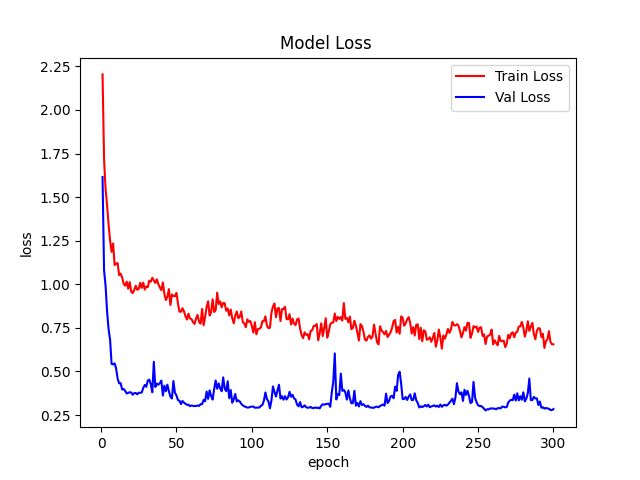
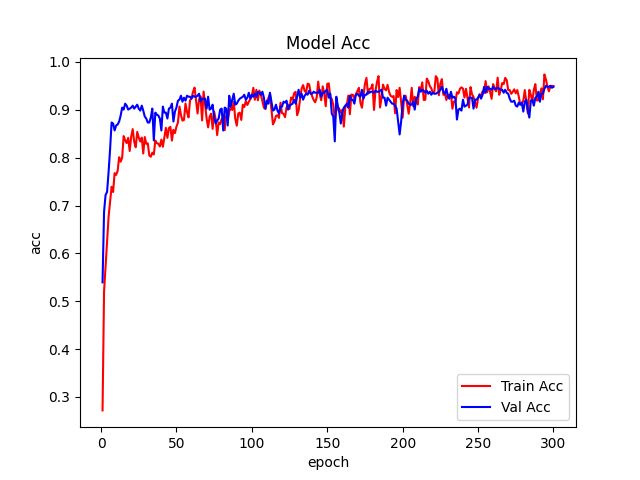
train.py运行脚本。5.12、测试结果
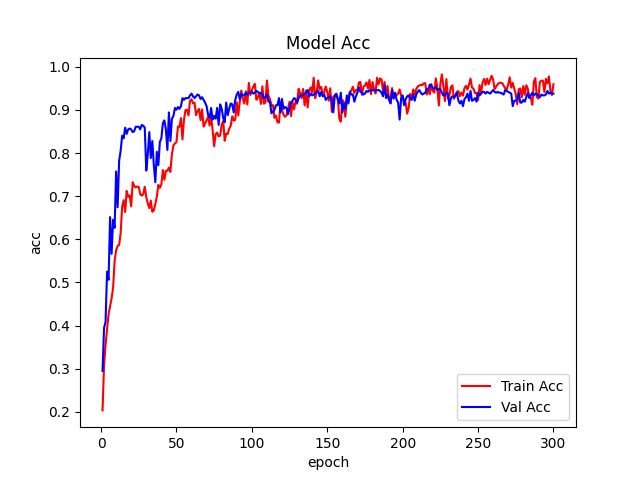
最好的模型ACC是95.6%。6、稀疏训练VGGNet
def updateBN(model,s=0.0001,epoch=1,epochs=1000):
srtmp = s * (1 - 0.9 * epoch / epochs)
for m in model.modules():
if isinstance(m,nn.BatchNorm2d):
m.weight.grad.data.add_(srtmp*torch.sign(m.weight.data))
m.bias.grad.data.add_(s * 10 * torch.sign(m.bias.data))
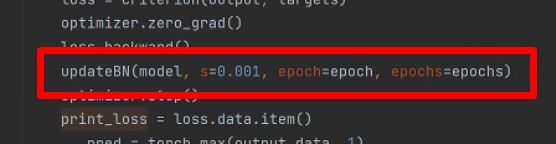
s的设置需要根据数据集调整,可以通过观察tensorboard的map,gamma变化直方图等选择。我在本次训练种使用的是0.001.tensorboard --logdir .
TensorFlow installation not found - running with reduced feature set.
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.13.0 at http://localhost:6006/ (Press CTRL+C to quit)
http://localhost:6006/就能看到。

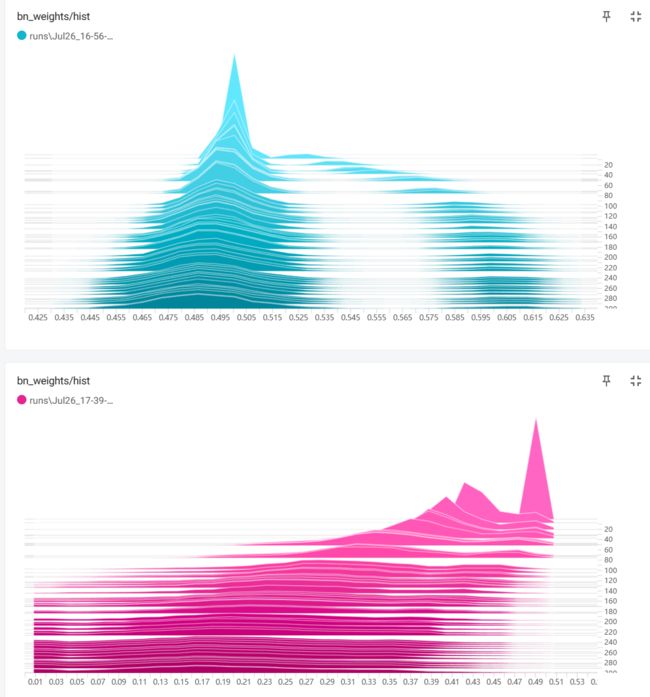
蓝色的是正常训练,BN权重的分布情况。紫红色的是加入稀疏因子后BN权重的分布情况。
稀疏化训练结果:
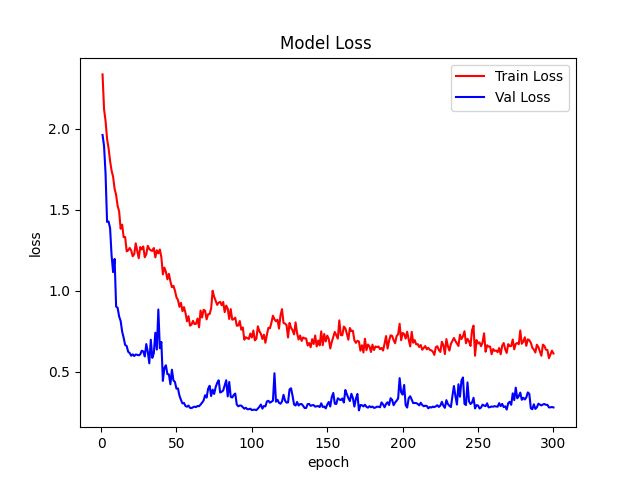

结果基本上和正常训练一致!最终结果也是95.6%。6、剪枝
6.1、导入库文件
import os
import argparse
import torch
import torch.nn as nn
from torch.autograd import Variable
from torchvision import datasets, transforms
from vgg import VGG
import numpy as np
6.2、测试函数
# simple test model after Pre-processing prune (simple set BN scales to zeros)
def test():
# 读取数据
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.48214436, 0.42969334, 0.33318862], std=[0.2642221, 0.23746745, 0.21696019])
])
dataset_test = datasets.ImageFolder("data/val", transform=transform_test)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, pin_memory=True, shuffle=False)
model.eval()
correct = 0
for data, target in test_loader:
data, target = data.to(DEVICE), target.to(DEVICE)
data, target = Variable(data, volatile=True), Variable(target)
output = model(data)
pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
print('\nTest set: Accuracy: {}/{} ({:.1f}%)\n'.format(
correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))
return correct / float(len(test_loader.dataset))
6.3、定义全局参数
if __name__ == '__main__':
BATCH_SIZE=16
percent=0.7
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model_path='checkpoints/vgg_sp/best.pth'
save_name='pruned.pth'
percent:剪枝的比率。
DEVICE :如果有显卡则使用GPU,没有则使用cpu。
model_path:稀疏训练模型的路径。
save_name:剪枝后,模型的路径。6.4、BN通道排序
#加载稀疏训练的模型
model = torch.load(model_path)
print(model)
total = 0 # 统计所有BN层的参数量
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
total += m.weight.data.shape[0] # 每个BN层权重w参数量
bn = torch.zeros(total)
index = 0
for m in model.modules():
#将各个BN层的参数值复制到bn中
if isinstance(m, nn.BatchNorm2d):
size = m.weight.data.shape[0]
bn[index:(index + size)] = m.weight.data.abs().clone()
index += size
#对bn中的weight值排序
y, i = torch.sort(bn)#
thre_index = int(total * percent)
thre = y[thre_index]#取bn排序后的第thresh_index索引值为bn权重的截断阈值
6.5、制作Mask
pruned = 0 #统计BN层剪枝通道数
cfg = []#统计保存通道数
cfg_mask = []#BN层权重矩阵,剪枝的通道记为0,未剪枝通道记为1
for k, m in enumerate(model.modules()):
if isinstance(m, nn.BatchNorm2d):
weight_copy = m.weight.data.clone()
mask = weight_copy.abs().gt(thre).float().cuda()#阈值分离权重
pruned = pruned + mask.shape[0] - torch.sum(mask)
m.weight.data.mul_(mask)#更新BN层的权重,剪枝通道的权重值为0
m.bias.data.mul_(mask)
cfg.append(int(torch.sum(mask)))#记录未被剪枝的通道数量
cfg_mask.append(mask.clone())
print('layer index: {:d} \t total channel: {:d} \t remaining channel: {:d}'.
format(k, mask.shape[0], int(torch.sum(mask))))
elif isinstance(m, nn.MaxPool2d):
cfg.append('M')
pruned_ratio = pruned / total
print('Pre-processing Successful!')
test()
# Make real prune
print(cfg)
6.6、剪枝操作
newmodel = VGG(cfg=cfg,num_classes=12)
newmodel.cuda()
layer_id_in_cfg = 0
start_mask = torch.ones(3)
end_mask = cfg_mask[layer_id_in_cfg]
for [m0, m1] in zip(model.modules(), newmodel.modules()):
if isinstance(m0, nn.BatchNorm2d):
idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy())))
m1.weight.data = m0.weight.data[idx1].clone()
m1.bias.data = m0.bias.data[idx1].clone()
m1.running_mean = m0.running_mean[idx1].clone()
m1.running_var = m0.running_var[idx1].clone()
layer_id_in_cfg += 1
start_mask = end_mask.clone()
if layer_id_in_cfg < len(cfg_mask): # do not change in Final FC
end_mask = cfg_mask[layer_id_in_cfg]
elif isinstance(m0, nn.Conv2d):
idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))
idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy())))
print('In shape: {:d} Out shape:{:d}'.format(idx0.shape[0], idx1.shape[0]))
w = m0.weight.data[:, idx0, :, :].clone()
w = w[idx1, :, :, :].clone()
m1.weight.data = w.clone()
# m1.bias.data = m0.bias.data[idx1].clone()
elif isinstance(m0, nn.Linear):
idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))
m1.weight.data = m0.weight.data[:, idx0].clone()
torch.save({'cfg': cfg, 'state_dict': newmodel.state_dict()}, save_name)
print(newmodel)
model = newmodel
test()
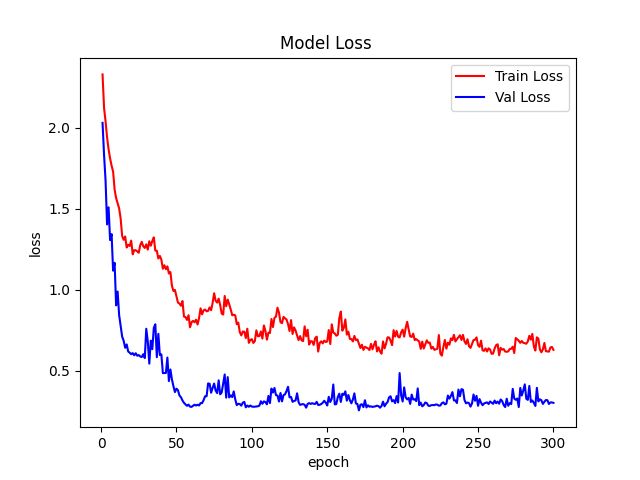
7、微调
7.1、微调方法
if __name__ == '__main__':
# 创建保存模型的文件夹
file_dir = 'checkpoints/vgg_pruned'
if os.path.exists(file_dir):
print('true')
os.makedirs(file_dir, exist_ok=True)
else:
os.makedirs(file_dir)
# 设置全局参数
model_lr = 1e-4
BATCH_SIZE = 16
EPOCHS = 300
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
classes = 12
resume = 'pruned.pth'
# 设置模型
model = torch.load(resume)
model_ft=VGG(cfg=model['cfg'],num_classes=classes)
model_ft.load_state_dict(model['state_dict'])
model_ft.to(DEVICE)
print(model_ft)
7.2、微调结果
Val set: Average loss: 0.2845, Accuracy: 457/482 (95%)
precision recall f1-score support
Black-grass 0.79 0.86 0.83 36
Charlock 1.00 1.00 1.00 42
Cleavers 1.00 0.96 0.98 50
Common Chickweed 0.94 0.91 0.93 34
Common wheat 0.93 1.00 0.97 42
Fat Hen 0.97 0.97 0.97 34
Loose Silky-bent 0.88 0.78 0.83 46
Maize 0.96 1.00 0.98 45
Scentless Mayweed 0.93 0.96 0.95 45
Shepherds Purse 0.97 0.97 0.97 35
Small-flowered Cranesbill 1.00 0.97 0.99 36
Sugar beet 1.00 1.00 1.00 37
accuracy 0.95 482
macro avg 0.95 0.95 0.95 482
weighted avg 0.95 0.95 0.95 482