DeepHawkes算法报告
作者介绍:
这篇论文是沈华伟老师团队发表在CIKM 2017上的一篇关于热度预测方向的论文,提出了模型DeepHawkes,模型结合了RNN和Hawkes模型,能够解释性地使用生成式方法(霍克斯模型),并利用神经网络的计算优势,完成对社交网络中流行度的预测。
背景介绍:
论文把对于信息的传播预测分为两类:基于特征提取和基于生成式的方法。
基于特征提取的方法主要就是特征提取,如果所选择的提取方法合适,那么最终效果会比较好。但是这种方法可解释性不高,也就是不知道怎么去解释这种特征为什么好,而且特征是需要人工提取的,费时费力有时候还不讨好。
而基于生成式的方法是用一些前辈提出的相关公式和模型,一般是基于数学或统计学方法来设计算法来拟合数据,通过深度学习或者别的网络模型,来完成流行度预测,这种方法具有很好地可解释性,但一般效果没有特征提取来的好。
Hawkes过程
论文把Hawkes过程强度函数中的增量定义如下:
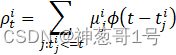
其中ρti![]() 表示的是消息mi在时间t的到达率,tji
表示的是消息mi在时间t的到达率,tji![]() 是原始帖子直到第j次转发经过的时间,μji
是原始帖子直到第j次转发经过的时间,μji![]() 是直接受到第j条转发影响的用户的潜在数量,ϕ
是直接受到第j条转发影响的用户的潜在数量,ϕ![]() 是时间衰退函数,Hawkes过程中捕捉到了三个关键因素: 用户的影响力——有影响力的用户对新转发的到达率的贡献更大,表明有影响力的用户转发的推文往往被更多地转发;自激机制——每条转发都会影响未来新转发的到达率;时间衰减效应——转发的影响随着时间的增加而衰减。
是时间衰退函数,Hawkes过程中捕捉到了三个关键因素: 用户的影响力——有影响力的用户对新转发的到达率的贡献更大,表明有影响力的用户转发的推文往往被更多地转发;自激机制——每条转发都会影响未来新转发的到达率;时间衰减效应——转发的影响随着时间的增加而衰减。
通过上式可以看出,霍克斯过程针对时间点t的到达率预测,其实就是把时间t之前的所有转发用户的影响大小与其转发时间的衰减系数乘积的算数加和。
问题定义
流行度预测:给定观察时间窗口 [0,T) 中的级联,它预测观察到的流行度和每个级联 Ci 的最终流行度之间的增量流行度 ΔRi 。
预测增量流行度而不是最终流行度,以避免观察到的流行度和最终流行度之间的内在相关性。
DeepHawkes
虽然Hawkes过程可以很好地解释观察到的转发,但它独立地学习每个级联的参数,并且没有针对未来的流行度进行优化。接下来,我们将对端到端监督深度学习框架下的霍克斯过程的可解释因素进行类比。模型具体如下:
DeepHawkes
虽然Hawkes过程可以很好地解释观察到的转发,但它独立地学习每个级联的参数,并且没有针对未来的流行度进行优化。接下来,我们将对端到端监督深度学习框架下的霍克斯过程的可解释因素进行类比。模型具体如下:
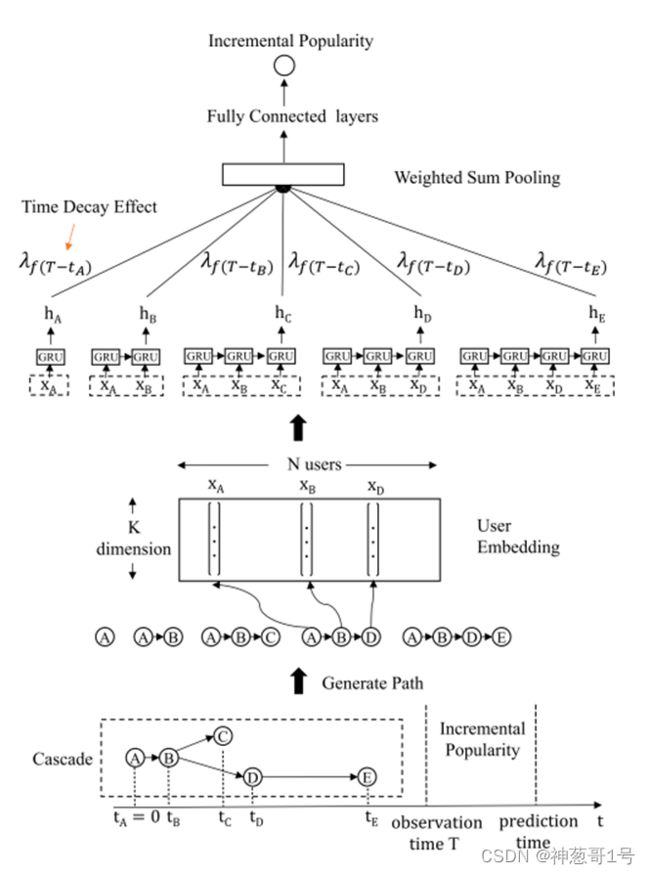
DeepHawkes 模型的框架以级联作为输入,输出增量流行度(如图所示)。它首先将级联转换为一组扩散路径,每个路径都描述了在观察时间内向每个转发用户传播信息的过程。模型主要分为四部分:
- 用户编码。(2)路径编码跟和池化。(3),时间衰减效应。(4)全连接
用户编码
embedding层就是对用户的one-hot向量进行线性变换到K维,完成用户 ID 的embedding过程,最终得到的是一组词向量
路径编码跟和池化
Hawkes过程的关键因素是自激机制,即每次转发都会增加未来新转发的到达率。在本文中,论文通过循环神经网络对整个转发路径的影响进行编码,而不是仅对转发用户本身进行建模。
路径的意思,举例:

级联的根节点触发,一直到目标结点,完成路径分割。有N个结点,就会有n-1个箭头,代表了n条路径,如图所示。
路径编码就是将这些生成的路径输入到GRU中,得到的最终隐藏层的状态来表示该路径的最终表示![]() ,然后对所有的路径表示进行求和,得到不带时间权重的最终向量和
,然后对所有的路径表示进行求和,得到不带时间权重的最终向量和![]() ,这个向量和体现出来乐自激励机制。具体地GRU计算公式就不再详细介绍。
,这个向量和体现出来乐自激励机制。具体地GRU计算公式就不再详细介绍。
非参数时间衰减效应
用户转发的影响会随着时间的推移不断缩减,如果按照上面的方式计算级联的向量表示 ci,则存在一个问题,就是不管是帖子刚发布就进行转发,还是过了好久才进行转发的行为,两者的重要程度都是一样的,这与霍克斯过程不符,与我们的认知也不相符合。所以论文设置了一个时间权重来模拟用户影响力衰减的过程。将时间窗口[0,T)的长度分为 L 个同样大小的小范围。每个小范围对应一个![]() ,并且从连续时间到时间间隔的映射函数 f 定义为
,并且从连续时间到时间间隔的映射函数 f 定义为![]()
f函数就是一个将连续值转换为离散值的阶跃函数. 最终的级联的向量ci![]() 为时间衰减因子加权的路径向量之和,如下表示
为时间衰减因子加权的路径向量之和,如下表示

全连接(MLP多层感知器)
最后得到的最终级联向量当做输入,通过一个全连接层,也就是MLP多层感知器,得到最后的输出:增量流行度 ΔRi。该算法采用对数均方误差

实验
实验任务两个:分别是预测新浪微博转发级联的未来规模和预测论文的引用次数。
采用的数据集为新浪微博数据集和来自美国物理学会(APS)的数据集。与基线进行比较,然后得出实验效果比基线好。
总结
这篇论文使用Hawkes过程和GRU结合,是属于很经典的流行度预测方法。这个方法的提出既结合了特征提取方法,又结合了基于生成式的方法。DeepHawkes模型在端到端直接通过未来流行度监督的深度学习框架之下,充分刻画了Hawkes模型的信息传播过程。并且还对Hawkes进行一定的改进,比如说我觉得非常好的地方是,在用户编码模块使用的One-hot embedding来学习而不是通过原先启发式的用户粉丝数,而且模型采用了GRU神经网络来建模整个转发路径的影响,而不仅仅是当前的转发用户。最后作者还考虑到了时间的影响因素,这是我觉得非常好的一个点,因为一个帖子对人的影响不可能是一直不变的,它总会随着时间的推进而淡化。所以作者在这里加了一个时间衰减效应,使得最后GRU最后得出的向量跟时间衰减函数相乘,得到最终的增量流行度。
文章对于级联序列的采样采用的是按箭头进行分割,我觉得这个序列的生成可以使用别的方法,可以在这里做文章,查阅文献后,发现另一篇论文CasCN《Information Diffusion Prediction via Recurrent Cascades Convolution》,=中思想和DeepHawkes都差不多,但是在子图序列采样和差生传播图的向量表示的过程不太一样,后续我会完成这篇论文的阅读。