【笔记】社交媒体事件的Hawkes Process建模教程(2)
在上一篇笔记中,主要介绍了点过程、自激励过程以及泊松过程(最简单的点过程),参见:【笔记】社交媒体事件的Hawkes Process建模教程(1)_Dorothy30的博客-CSDN博客
在本篇笔记中,将接着上一篇笔记继续分享tutorial的第三、四部分内容,谈一谈到底什么是Hawkes Process,如何使用Hawkes Process模拟事件(两个方法)。Tutorial最后的如何估计Hawkes Process的参数和建模实例部分留到后面的笔记继续。
目录
1. Hawkes Process的定义
2. Hawkes Process的强度函数(intensity function)详解
2.1 关于记忆核函数的选择
3 Hawkes Process的分支结构
3.1 Branching factor (branching ratio)
3.2 一个cluster里的后代总事件数量
4 模拟 Hawkes Process中的事件
4.1 The Thinning algorithm (稀疏算法)
4.1.1 齐次泊松过程的到达时间间隔采样
4.1.2 泊松过程的稀疏性质
4.1.3 使用稀疏性质的原因
4.1.4 Thinning algorithm
4.2 通过分解进行有效采样
上一篇笔记里提到过,我们在点过程中,关注的重点从一段时间内事件发生的次数转到了发生事件的间隔。在泊松过程中,事件的到达是具有无记忆性的,即过去到达的历史事件并不影响新事件的到达。而且事件到达的时间间隔可以是恒定的(![]() 恒定,单位时间内到达的事件次数恒定),对应着齐次的泊松过程,也可以是非齐次的(单位时间内事件到达的次数随时间变化,用强度函数
恒定,单位时间内到达的事件次数恒定),对应着齐次的泊松过程,也可以是非齐次的(单位时间内事件到达的次数随时间变化,用强度函数![]() 表示)。
表示)。
在一些实际应用中,我们知道已知事件的到达会增加在不久的将来观察到事件的可能性。例如当模拟地震活动时,余震的发生,或者社交网络中用户的互动对后续交流的影响。这样的过程叫做自激励过程。
Hawkes process就是这样一类经典且应用广泛的自激励过程,即事件到达率取决于历史事件的到达情况。它由Hawkes在1971年提出。
1. Hawkes Process的定义
令![]() 为一个具有关联历史
为一个具有关联历史![]() 的计数过程。其对应的点过程由事件强度函数(intensity function)
的计数过程。其对应的点过程由事件强度函数(intensity function)![]() 表示。如果该条件强度函数的形式为下式的话,则将该点过程称为霍克斯过程(Hawkes Process)。
表示。如果该条件强度函数的形式为下式的话,则将该点过程称为霍克斯过程(Hawkes Process)。
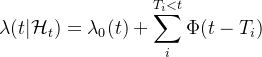
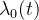 : 一个确定的基础强度函数
: 一个确定的基础强度函数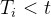 : 所有在当前时间t之前发生事件的时间
: 所有在当前时间t之前发生事件的时间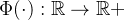 称作记忆核( memory kernel)
称作记忆核( memory kernel)
当然,它也是一类特殊的非齐次泊松过程,其中事件发生的强度是随机的并且通过核函数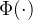 显式地依赖于先前的事件。
显式地依赖于先前的事件。
2. Hawkes Process的强度函数(intensity function)详解
intensity function由两个部分组成,![]() 和
和
- 是基础(背景)强度,描述了由外部来源触发的事件的到来。
- 这些由外部来源触发的事件也叫外生事件或移民事件,它们的到来与过程中的先前事件无关。
- 是体现Hawkes process自激励的地方
Figure 1.2(a) 展示了一个Hawkes Process的实现:有九个事件在
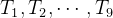 被观察到,这些事件对应的到达时间间隔为
被观察到,这些事件对应的到达时间间隔为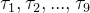 。
。Figure 1.2(b)给出了对应的随时间变化的计数过程
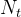 , 它在每个事件时间
, 它在每个事件时间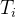 增加一个单位。
增加一个单位。Figure 1.2(c)为随时间变化的强度函数
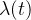 ,从图中可以看到强度函数在每个事件发生的时候()突然上升,然后伴随着指数衰减。你也可以看到在每个衰减对于新事件强度的影响。
,从图中可以看到强度函数在每个事件发生的时候()突然上升,然后伴随着指数衰减。你也可以看到在每个衰减对于新事件强度的影响。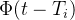 用于调节过去发生在时间的事件在intensity function中对于当前时间t的改变
用于调节过去发生在时间的事件在intensity function中对于当前时间t的改变- 通常情况下,记忆核函数
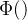 被认为是单调下降的,因此最近的事件对当前事件强度的影响更大
被认为是单调下降的,因此最近的事件对当前事件强度的影响更大
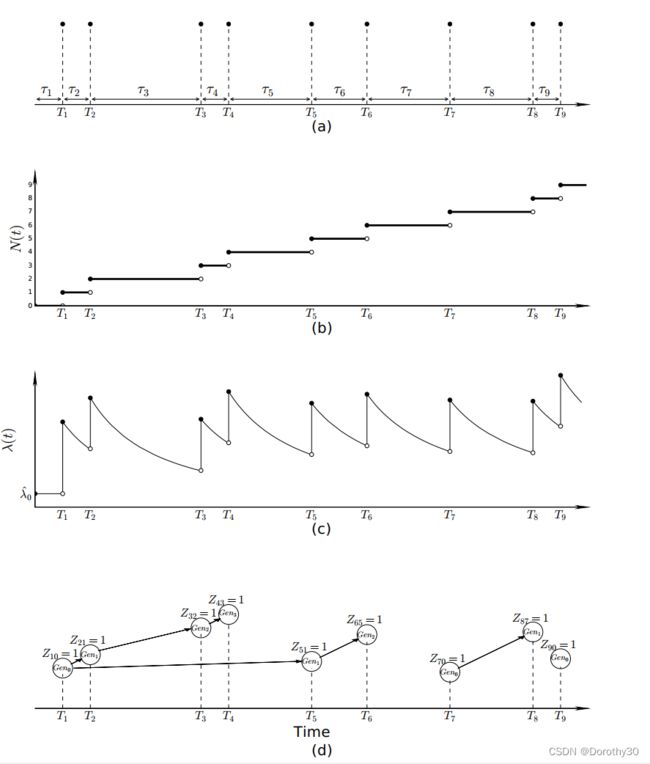 Figure 1.2 带有指数衰减kernel的Hawkes Process (a)点过程示意图(b)随着时间推移的计数过程(c)随着时间推移的强度函数(d)Hawkes process的潜在的分支结构(branching structure)。标题
Figure 1.2 带有指数衰减kernel的Hawkes Process (a)点过程示意图(b)随着时间推移的计数过程(c)随着时间推移的强度函数(d)Hawkes process的潜在的分支结构(branching structure)。标题
2.1 关于记忆核函数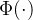 的选择
的选择
事实上,核函数 不是非要单调递减的。 然而,在这个教程中,我们将仅讨论该函数是递减的情况。
一个很常见的衰减函数是指数衰减函数,采用如下形式:
![]()
这里 ![]() 以及
以及 ![]()
还有一个广泛应用在各种文献里的衰减函数是power-law衰减函数:
![]()
- 此处
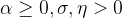 且
且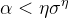
- 这个函数经常在地震学以及社交媒体的文献中使用(因此在后面的建模实例中,我们也将使用这个形式的核函数)
3 Hawkes Process的分支结构
Hawkes Process的另一种等价形式是指泊松簇过程(Poisson cluster process),它将Hawkes process中的事件分为两个类别:移民和后代(immigrants and offspring)。其中,后代是由process中的历史事件触发的,而移民事件是独立到达的,在process中没有关联的parent event。
将后代构造成cluster,且每个cluster和与之对应的移民相关联,这称为分支结构。在这个部分的剩余内容里,将计算两个与分支内容有关的指标:branching factor(在Hawkes process里被给定事件触发的期望事件数量)和一个cluster里的后代总事件数量。
分支结构示例(Figure 1.2 d):移民事件遵循基本强度
的齐次泊松过程的情况,而后代是通过自激励产生的
Figure 1.2(d) 中展示了之前提到的9个事件的分支结构。事件时间
用圆圈表示,“亲子”关系用箭头表示。
在这里,我们引入一个随机变量
- 当事件
是移民时,
- 当事件
- 每个圆圈里的
描述了这个事件属于第几代,即
属于第
代,移民事件属于
。
- 如图所示,
和
是移民事件
的直接后代,那么在数学上可以用随机事件表示为
。

这种cluster的表示方式描述了一个特定的parent事件到达之后,后代如何通过非齐次泊松过程中的强度与parent相关联。例如![]() 和
和![]() 事件的到来来自于包含有强度
事件的到来来自于包含有强度![]() (
(![]() )的非齐次泊松过程。
)的非齐次泊松过程。
产生后代的事件可以称作后代事件的直接祖先或根。例如 ![]() 是
是 ![]() 的直接祖先,
的直接祖先,![]() 是
是![]() 的直接祖先。直接或间接地与一个移民事件相连接的事件组成了后代事件的cluster。例如
的直接祖先。直接或间接地与一个移民事件相连接的事件组成了后代事件的cluster。例如![]() 是移民事件,它与
是移民事件,它与 ![]() 和
和 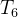 形成了与
形成了与![]() 相关的cluster。同样的,
相关的cluster。同样的,![]() 和
和![]() 自成一个cluster,
自成一个cluster,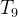 自身是一个clsuter。
自身是一个clsuter。
3.1 Branching factor (branching ratio) 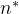
-
定义:由单个事件产生的直接后代的期望数量(这里的单个事件可以是祖先也可以是后代,它衡量的是一个事件的分支能力)。
- 在社交媒体的情景下,也可以将branching factor成为virality(一个帖子或消息被分享或转发的数量)
- branching factor也是判断一个与移民事件相关联的cluster是否是无限集合的指标。如果
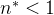 ,这个Hawkes Process就进入了亚临界域,代表着一个事件产生后代的能力有限,那么最终导致的cluster的规模是有界的。而当
,这个Hawkes Process就进入了亚临界域,代表着一个事件产生后代的能力有限,那么最终导致的cluster的规模是有界的。而当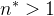 时,这个Hawkes Process进入了超临界状态,这意味着每个集群中的事件总数不受限制。(如果对流行病学有所了解的话,可以将这个branching factor和基本再生数
时,这个Hawkes Process进入了超临界状态,这意味着每个集群中的事件总数不受限制。(如果对流行病学有所了解的话,可以将这个branching factor和基本再生数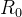 联系起来,基本再生数也是一个衡量传染病传染能力的指标)
联系起来,基本再生数也是一个衡量传染病传染能力的指标)
-
计算:branching factor的计算是通过对
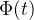 在事件时间 t 上的积分(每个事件的贡献)来计算:
在事件时间 t 上的积分(每个事件的贡献)来计算: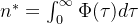
- 对这个公式的理解还要从
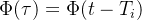 出发,前面提到这个记忆核函数是体现的每个事件发生的时间对当前时刻
出发,前面提到这个记忆核函数是体现的每个事件发生的时间对当前时刻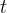 事件发生的影响。(当前时间下,单位时间内发生事件的次数)是通过移民事件的强度与过去事件的累计影响来进行计算的,那么除去外部来源对事件到达的影响,考虑所有历史事件,就是过去历史事件可以导致的当前时间下发生事件的次数,即当前事件可以产生的后代的数量。
事件发生的影响。(当前时间下,单位时间内发生事件的次数)是通过移民事件的强度与过去事件的累计影响来进行计算的,那么除去外部来源对事件到达的影响,考虑所有历史事件,就是过去历史事件可以导致的当前时间下发生事件的次数,即当前事件可以产生的后代的数量。
- 对这个公式的理解还要从
3.2 一个cluster里的后代总事件数量
在branching factor中,显然只有在![]() 时可以得到一个cluster里最终后代规模的更准确的估计。令
时可以得到一个cluster里最终后代规模的更准确的估计。令![]() 为
为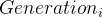 的期望事件数量,且
的期望事件数量,且 ![]() (在第0代只有一个事件,那就是移民事件)。那么最终在一个cluster中的期望事件总数就为
(在第0代只有一个事件,那就是移民事件)。那么最终在一个cluster中的期望事件总数就为![]() ,且按如下方式进行计算
,且按如下方式进行计算
- 以上的计算实际上就是对前后代的事件数量建立归纳关系
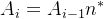 ,并且我们知道
,并且我们知道 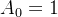 。所以本质上这个计算式就是等比数列求和(
。所以本质上这个计算式就是等比数列求和( ),在我们这里得到的结果应该是
),在我们这里得到的结果应该是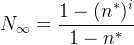 ,然后当i趋于无穷且
,然后当i趋于无穷且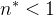 时,
时,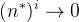 ,所以
,所以
4 模拟 Hawkes Process中的事件
我们将重点关注根据给定Hawkes process模拟一系列随机事件的问题。这将有助于收集有关过程的统计数据,并且是诊断、推理或参数估计的基础。
接下来将会介绍两种Hawkes Process的模拟方法。第一种是Thinning algorithm,适用于所有非齐次泊松过程,而且可以应用在包含任何形式的核函数的Hawkes Process中。第二种方法是2013年由Dassios和Zhao提出来的,它在计算上更有效,这得益于算法设计了一个针对指数衰减kernel的Hawkes process的变量分解方法。
4.1 The Thinning algorithm (稀疏算法)
模拟Hawkes Proess的基本目标就是根据强度函数![]() 采样到达时间间隔
采样到达时间间隔 ![]() 。在正式介绍对Hawkes Process的采样之前,会先回顾其次泊松过程的采样方法,在此基础上引入泊松过程的稀疏(thinning/addvitive)性质。
。在正式介绍对Hawkes Process的采样之前,会先回顾其次泊松过程的采样方法,在此基础上引入泊松过程的稀疏(thinning/addvitive)性质。
4.1.1 齐次泊松过程的到达时间间隔采样
在上一篇笔记中,我们提到齐次的泊松过程服从指数分布:
- 概率密度函数:
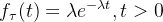
- 累积分布函数:
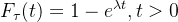

在给定参数 的情况下,我们就可以求出该过程的密度函数和累积分布函数,例如上图为
的情况下,我们就可以求出该过程的密度函数和累积分布函数,例如上图为![]() 的分布情况。若想获得一系列到达时间间隔的采样点(位于x轴),我们可以根据累积分布函数(CDF)在y轴范围为[0, 1]的特点,从y轴生成服从均匀分布
的分布情况。若想获得一系列到达时间间隔的采样点(位于x轴),我们可以根据累积分布函数(CDF)在y轴范围为[0, 1]的特点,从y轴生成服从均匀分布![]() 的n个采样点y,然后根据
的n个采样点y,然后根据![]() 在CDF中通过函数的逆变换
在CDF中通过函数的逆变换![]() 求出对应在x轴的一系列n个采样点
求出对应在x轴的一系列n个采样点![]() 。这个方法称为逆变换采样。
。这个方法称为逆变换采样。
因此,在到达时间间隔服从指数分布的泊松分布中,我们若生成一个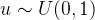 ,我们有
,我们有![]() ,通过变换可得
,通过变换可得![]() 。由于
。由于![]() , 因此对于到达时间间隔
, 因此对于到达时间间隔 的采样可以简化为:
的采样可以简化为:
![]()
4.1.2 泊松过程的稀疏性质
关于泊松过程的稀疏性质,更为具体的内容可以参考这篇知乎笔记(随机过程|笔记整理(6)——泊松过程三大变换,更新过程引入 - 知乎 (zhihu.com))。简而言之,稀疏性质就是说带有强度![]() 的泊松过程可以被拆分为两个单独的强度为
的泊松过程可以被拆分为两个单独的强度为![]() 和
和![]() 过程,且
过程,且![]() 。换言之,原始过程中的每个事件都可以分配给独立的两个新过程之一。
。换言之,原始过程中的每个事件都可以分配给独立的两个新过程之一。
利用这个稀疏性质,我们可以从一个齐次的强度![]() 的泊松过程中以一定概率接受/移出一部分事件,来获得强度函数为
的泊松过程中以一定概率接受/移出一部分事件,来获得强度函数为![]() 的非齐次泊松过程。
的非齐次泊松过程。
4.1.3 使用稀疏性质的原因
- 简单:与直接模拟具有随时间变化强度函数的非齐次过程相比,齐次泊松过程在数学上是直接的并且更容易生成。
- 已知属性:齐次泊松过程的统计属性已广为人知,从齐次的泊松过程开始构建使更复杂的过程会更加方便。
- 高效:从齐次泊松过程生成事件在计算上是高效的,并且通过稀疏性质可以保留事件的子集,这与每个时间间隔从头开始生成事件相比降低了计算复杂性。
4.1.4 Thinning algorithm
使用Thinning algorithm来模拟Hawkes process的过程如下图的伪代码所示。具体来说,就是对于任何时间间隔下的强度函数![]() ,我们都可以找到一个恒定的
,我们都可以找到一个恒定的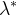 以满足
以满足![]() 。那么根据带有单调下降性质核函数的Hawkes process,我们可以直观地发现对于两个连续的事件时间
。那么根据带有单调下降性质核函数的Hawkes process,我们可以直观地发现对于两个连续的事件时间![]() ,
,![]() 是这段到达时间间隔的强度的上界。
是这段到达时间间隔的强度的上界。
根据逆变换采样,我们采样得到下一个到达时间间隔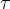 ,以此我们可以得到估计的下一个事件到达的时间
,以此我们可以得到估计的下一个事件到达的时间![]() ,并计算当前的强度
,并计算当前的强度![]() 。在Thinning method中,我们采用生成随机数的方式对每个事件是否到达进行基于概率的决策。也就是说我们生成一个在[0, 1]内的随机数s,并将其与
。在Thinning method中,我们采用生成随机数的方式对每个事件是否到达进行基于概率的决策。也就是说我们生成一个在[0, 1]内的随机数s,并将其与![]() (即
(即![]() )进行比较,如果
)进行比较,如果![]() ,则接受,我们就模拟出了一个新事件的到达。否则拒绝,在
,则接受,我们就模拟出了一个新事件的到达。否则拒绝,在![]() 没有事件到达,但时间变量
没有事件到达,但时间变量 仍然更新。
仍然更新。

4.2 通过分解进行有效采样
这个由Dassios和Zhao提出的算法不需要通过概率进行接受/拒绝的判断,但它只针对于指数的移民率以及指数的记忆核函数。其中,移民率通过一个服从指数函数的非齐次泊松过程来描述:![]() 。对于一个新事件,它的到来对于事件强度的“跳跃”的影响是通过一个常量“
。对于一个新事件,它的到来对于事件强度的“跳跃”的影响是通过一个常量“![]() ”来描述。完整的强度函数如下所示:
”来描述。完整的强度函数如下所示:
![]()
值得注意的是,当记忆核函数是指数形式时,由强度函数产生的过程是马尔科夫过程(Markov process)。这意味着,未来的事件发生只取决于最近的一件事情的发生,而独立于其他过去的历史事件。即,对于任意的![]() , 有
, 有![]() ,在a为常数的情况下,后一个时刻的事件的强度只取决于前一个事件的强度
,在a为常数的情况下,后一个时刻的事件的强度只取决于前一个事件的强度![]() 以及
以及![]() 。
。
因此,我们可以根据这个马尔科夫的特性把到达时间间隔分为两个简单且独立的随机变量![]() 和
和![]() 。
。
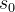 :代表着下一个活动的到达时间间隔取决于恒定的background rate a
:代表着下一个活动的到达时间间隔取决于恒定的background rate a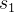 :代表着下一个活动的到达时间间隔来自于指数的immigrant kernel
:代表着下一个活动的到达时间间隔来自于指数的immigrant kernel 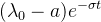 或者来自于受过去事件影响的Hawkes process的自激励核函数
或者来自于受过去事件影响的Hawkes process的自激励核函数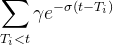
我们假设采样的到达间隔时间是这两种情况中的最小值。详情请参考论文:Exact simulation of Hawkes process with exponentially decaying intensity
该算法的伪代码如图所示:

算法的部分公式推导如下图:

剩下的部分留在下篇笔记继续!如果在公式推导或者理解上有不对的地方欢迎交流讨论~