(二)使用Dom4j对XML文件进行解析
目录
- 1、XML解析概念
- 2、Dom4j解析过程
1、XML解析概念
XML解析技术:
HTML和XML都是标记型文档,可以使用W3C组织制定的DOM技术来解析。(DOM把所有标签表示为对象)
dom4j解析技术:
早期JDK提供了两种方式对XML进行解析,分别是DOM和SAX,目前已经不使用。
第三方解析:
dom➡jdom,
jdom➡dom4j,
pull主要用在Android手机开发,是和sax类似为事件机制解析xml文件。
2、Dom4j解析过程
使用dom4j解析XML文件,首先新建一个XML文件内容为:
<books>
<book sn="SN15456489">
<name>疯子在左name>
<price>99price>
<authosr>作者authosr>
book>
<book sn="SN15412129">
<name>你好name>
<price>58price>
<authosr>作者2authosr>
book>
books>
然后新建一个软件包,生成一个BOOK类,在BOOK类中生成对应的函数。
package com.my.pojo;
import java.math.BigDecimal;
public class Book {
private String sn;
private String name;
private BigDecimal price;
private String author;
public Book(String sn, String name, BigDecimal price, String author) {
this.sn = sn;
this.name = name;
this.price = price;
this.author = author;
}
public Book() {
}
public String getSn() {
return sn;
}
public void setSn(String sn) {
this.sn = sn;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public BigDecimal getPrice() {
return price;
}
public void setPrice(BigDecimal price) {
this.price = price;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
@Override
public String toString() {
return "Book{" +
"sn='" + sn + '\'' +
", name='" + name + '\'' +
", price=" + price +
", author='" + author + '\'' +
'}';
}
}
新建lib目录导入dom4j包,并进行jar包操作,在jar包处右键添加库。
同时新建一个类文件,创建输入流读取XML配置文件生成document对象。
package com.my.pojo;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.io.SAXReader;
import org.junit.Test;
public class Dom4jTest {
@Test
public void test1() throws Exception {
//创建一个输入流读取xml配置文件,生成document对象
SAXReader saxReader = new SAXReader();
Document document = saxReader.read("src/books.xml");
System.out.println(document);
}
}
最终输出结果为:
org.dom4j.tree.DefaultDocument@26653222 [Document: name src/books.xml]
说明document对象成功获取到XML文件里的内容。
上述方法可以优化为:
package com.my.pojo;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
import org.junit.Test;
import java.util.List;
public class Dom4jTest {
@Test
public void test1(){
SAXReader saxReader = new SAXReader();
try {
Document doc = saxReader.read("src/books.xml");
System.out.println(doc);
}catch (Exception e){
e.printStackTrace();
}
}
/*读取XML文件生成BOOK类*/
@Test
//文件路径作参数的方法需要抛异常,否则找不到文件会出现问题
public void test2() throws Exception{
//1.读取books.xml文件
SAXReader reader = new SAXReader();
//Junit测试中相对路径从模块名开始算
Document document = reader.read("src/books.xml");
//2.通过Document对象获取根元素
Element rootElement = document.getRootElement();
System.out.println(rootElement);
//3.通过根元素获取book标签对象
//element()和elements()都是通过标签名查找子元素
List<Element> books = rootElement.elements("book");
//4.遍历,处理每个book标签更改为book类
for(Element book: books){
//asXML()把标签对象转化为标签字符串
System.out.println(book.asXML());
}
}
}
输出结果:

每个book里包含了XML标签信息。
取出book子元素,以name为例。
for(Element book: books){
//asXML()把标签对象转化为标签字符串
// System.out.println(book.asXML());
Element nameElement = book.element("name");
System.out.println(nameElement.asXML());
}
输出:
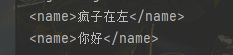
获取标签中文本内容使用getText()方法。
//getText()方法可以获取标签中文本内容
String nameText = nameElement.getText();
直接获取指定标签内容:elementText()方法。
String authorname = book.elementText("author");
System.out.println(authorname);

属性获取采用attributeValue()
String snValue = book.attributeValue("sn");
把所有的参数新建为BOOK对象打印出。
public void test2() throws Exception{
//1.读取books.xml文件
SAXReader reader = new SAXReader();
//Junit测试中相对路径从模块名开始算
Document document = reader.read("src/books.xml");
//2.通过Document对象获取根元素
Element rootElement = document.getRootElement();
System.out.println(rootElement);
//3.通过根元素获取book标签对象
//element()和elements()都是通过标签名查找子元素
List<Element> books = rootElement.elements("book");
//4.遍历,处理每个book标签更改为book类
for(Element book: books){
String nameText = book.elementText("name");
String priceText = book.elementText("price");
String authorText = book.elementText("author");
String snValue = book.attributeValue("sn");
//转换成BOOK对象
System.out.println(new Book(snValue,nameText, BigDecimal.valueOf(Double.parseDouble(priceText)),authorText);
}
}
}

就得到解析完后的XML对象了。