实现读写分离SpringBoot+MyBatis+Druid
实现读写分离
SpringBoot+MyBatis+Druid
1.读写分离概念理解
读写分离要做的事情就是对于一条SQL该选择哪个数据库去执行,至于谁来做选择数据库这件事儿,无非两个,要么中间件帮我们做,要么程序自己做。因此,一般来讲,读写分离有两种实现方式。第一种是依靠中间件(比如:MyCat),也就是说应用程序连接到中间件,中间件帮我们做SQL分离;第二种是应用程序自己去做分离。这里我们选择程序自己来做,主要是利用Spring提供的路由数据源,以及AOP。然而,应用程序层面去做读写分离最大的弱点(不足之处)在于无法动态增加数据库节点,因为数据源配置都是写在配置中的,新增数据库意味着新加一个数据源,必然改配置,并重启应用。当然,好处就是相对简单。
读写分离涉及到数据库主从同步
数据库主从同步:https://www.cnblogs.com/cjsblog/p/9706370.html
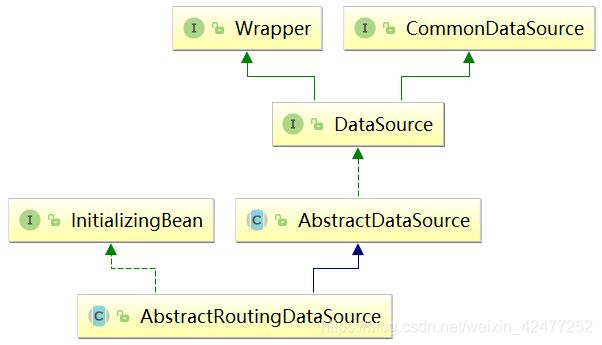
2. AbstractRoutingDataSource
基于特定的查找key路由到特定的数据源。它内部维护了一组目标数据源,并且做了路由key与目标数据源之间的映射,提供基于key查找数据源的方法。
开始吧!
工程结构

1.引入maven依赖
4.0.0
org.springframework.boot
spring-boot-starter-parent
2.4.0
com.example
multidatasource
0.0.1-SNAPSHOT
multidatasource
读写分离多数据源
1.8
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-aop
org.mybatis.spring.boot
mybatis-spring-boot-starter
2.1.2
org.springframework.boot
spring-boot-configuration-processor
true
mysql
mysql-connector-java
runtime
com.alibaba
druid-spring-boot-starter
1.1.10
org.springframework.boot
spring-boot-starter-jdbc
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
org.springframework.boot
spring-boot-maven-plugin
2.数据源配置
spring.datasource.master.url=jdbc:mysql://localhost:3306/db01?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC
spring.datasource.master.username=root
spring.datasource.master.password=
spring.datasource.master.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.slave1.url=jdbc:mysql://localhost:3306/db02?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC
spring.datasource.slave1.username=root
spring.datasource.slave1.password=
spring.datasource.slave1.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.slave2.url=jdbc:mysql://localhost:3306/db03?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC
spring.datasource.slave2.username=root
spring.datasource.slave2.password=
spring.datasource.slave2.type=com.alibaba.druid.pool.DruidDataSource
#Spring Boot 默认是不注入这些属性值的,需要自己绑定
#druid 数据源专有配置
#配置初始化大小、最小、最大
spring.datasource.initialSize= 5
spring.datasource.minIdle= 5
spring.datasource.maxActive= 20
#配置获取连接等待超时的时间
spring.datasource.maxWait= 60000
#配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
spring.datasource.timeBetweenEvictionRunsMillis= 60000
#配置一个连接在池中最小生存的时间,单位是毫秒
spring.datasource.minEvictableIdleTimeMillis= 300000
#用来检测连接是否有效的sql,要求是一个查询语句,常用select 'x'。
# 如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用。
spring.datasource.validationQuery=SELECT 1 FROM DUAL
spring.datasource.testWhileIdle=true
spring.datasource.testOnBorrow=false
spring.datasource.testOnReturn=false
#配置监控统计拦截的filters,stat:监控统计、log4j:日志记录、wall:防御sql注入
#如果允许时报错 java.lang.ClassNotFoundException: org.apache.log4j.Priority
#则导入 log4j 依赖即可,Maven 地址: https://mvnrepository.com/artifact/log4j/log4j
spring.datasource.filters=stat,wall,log4j
#是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。
pring.datasource.poolPreparedStatements= true
spring.datasource.maxPoolPreparedStatementPerConnectionSize= 20
spring.datasource.useGlobalDataSourceStat= true
# 配置监控统计拦截的filters
spring.datasource.stat-view-servlet.url-pattern=/druid/*
spring.datasource.stat-view-servlet.reset-enable= false
spring.datasource.druid.stat-view-servlet.login-username=admin
spring.datasource.druid.stat-view-servlet.login-password=123
spring.datasource.druid.stat-view-servlet.enabled=true
#设置ip黑名单和白名单
#spring.datasource.druid.stat-view-servlet.allow=127.0.0.1
#spring.datasource.druid.stat-view-servlet.deny=
#过滤所有请求
spring.datasource.url-pattern= /*
#排除哪些请求
spring.datasource.web-stat-filter.exclusions= "*.js,*.gif,*.jpg,*.bmp,*.png,*.css,*.ico,/druid/*"3.加载数据库配置DataSourceConfig
package com.example.multidatasource.config;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceBuilder;
import com.example.multidatasource.bean.MyRoutingDataSource;
import com.example.multidatasource.type.DBTypeEnum;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.jdbc.DataSourceBuilder;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import sun.rmi.runtime.Log;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
/**
* @create: 2020-11-16 00:28
**/
@Configuration
@Slf4j
public class DataSourceConfig {
/*
* HikariDataSource改为druid
* */
@Bean
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource masterDataSource(){
return DruidDataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource.slave1")
public DataSource slave1DataSource(){
return DruidDataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource.slave2")
public DataSource slave2DataSource(){
return DruidDataSourceBuilder.create().build();
}
@Bean
public DataSource myRoutingDataSource(@Qualifier("masterDataSource") DataSource masterDataSource,
@Qualifier("slave1DataSource") DataSource slave1DataSource,
@Qualifier("slave2DataSource") DataSource slave2DataSource) {
Map targetDataSources = new HashMap<>();
targetDataSources.put(DBTypeEnum.MASTER, masterDataSource);
targetDataSources.put(DBTypeEnum.SLAVE1, slave1DataSource);
targetDataSources.put(DBTypeEnum.SLAVE2, slave2DataSource);
log.info(targetDataSources.toString());
MyRoutingDataSource myRoutingDataSource = new MyRoutingDataSource();
myRoutingDataSource.setDefaultTargetDataSource(masterDataSource);
myRoutingDataSource.setTargetDataSources(targetDataSources);
return myRoutingDataSource;
}
/*
SpringBoot 默认使用 HikariDataSource
@Bean
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource masterDataSource(){
log.info(DataSourceBuilder.create().build().toString());
return DataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource.slave1")
public DataSource slave1DataSource(){
return DataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource.slave2")
public DataSource slave2DataSource(){
return DataSourceBuilder.create().build();
}*/
/* spring.datasource.master.jdbc-url= jdbc:mysql://localhost:3306/db01?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC
spring.datasource.master.username= root
spring.datasource.master.password=
spring.datasource.master.driver-class-name= com.mysql.jdbc.Driver
spring.datasource.slave1.jdbc-url= jdbc:mysql://localhost:3306/db02?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC
spring.datasource.slave1.username= root
spring.datasource.slave1.password=
spring.datasource.slave1.driver-class-name= com.mysql.jdbc.Driver
spring.datasource.slave2.jdbc-url= jdbc:mysql://localhost:3306/db03?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC
spring.datasource.slave2.username= root
spring.datasource.slave2.password=
spring.datasource.slave2.driver-class-name= com.mysql.jdbc.Driver*/
}
4.MyBatis配置
package com.example.multidatasource.config;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.transaction.PlatformTransactionManager;
import org.springframework.transaction.annotation.EnableTransactionManagement;
import javax.annotation.Resource;
import javax.sql.DataSource;
/**
* @create: 2020-11-16 01:08
**/
@EnableTransactionManagement
@Configuration
public class MybatisConfig {
@Resource(name = "myRoutingDataSource")
private DataSource myRoutingDataSource;
/*由于Spring容器中现在有4个数据源,所以我们需要为事务管理器和MyBatis手动指定一个明确的数据源。*/
@Bean
public SqlSessionFactory sqlSessionFactory() throws Exception {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(myRoutingDataSource);
//我采取的是注解式sql,如果加上扫描,但包下无mapper.xml会报错
//sqlSessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mapper/*.xml"));
return sqlSessionFactoryBean.getObject();
}
@Bean
public PlatformTransactionManager platformTransactionManager() {
return new DataSourceTransactionManager(myRoutingDataSource);
}
}
5.数据源名枚举区分
public enum DBTypeEnum {
MASTER,SLAVE1,SLAVE2
}6. 线程上下文工具
contextHolder 是线程变量,因为每个请求是一个线程,所以通过这样来区分使用哪个库
determineCurrentLookupKey是重写的AbstractRoutingDataSource的方法,
主要是确定当前应该使用哪个数据源的key,因为AbstractRoutingDataSource 中保存的多个数据源是通过Map的方式保存的
package com.example.multidatasource.bean;
import com.example.multidatasource.type.DBTypeEnum;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import java.util.concurrent.atomic.AtomicInteger;
/**
* @create: 2020-11-16 01:00
**/
@Slf4j
@Component
public class DBContextHolder {
/*
* contextHolder 是线程变量,因为每个请求是一个线程,所以通过这样来区分使用哪个库
determineCurrentLookupKey是重写的AbstractRoutingDataSource的方法,
主要是确定当前应该使用哪个数据源的key,因为AbstractRoutingDataSource 中保存的多个数据源是通过Map的方式保存的
* */
private static final ThreadLocal contextHolder=new ThreadLocal<>();
private static final AtomicInteger counter =new AtomicInteger(-1);
//设置当前线程所用数据库类型
public static void set(DBTypeEnum dbType){
contextHolder.set(dbType);
}
//获取当前线程所用数据类型
public static DBTypeEnum get() {
return contextHolder.get();
}
public static void master() {
set(DBTypeEnum.MASTER);
log.info("切换到master");
}
public static void slave() {
// 轮询
int index = counter.getAndIncrement() % 2;
if (counter.get() > 9999) {
counter.set(-1);
}
if (index == 0) {
set(DBTypeEnum.SLAVE1);
log.info("切换到slave1");
}else {
set(DBTypeEnum.SLAVE2);
log.info("切换到slave2");
}
}
}
7.获取路由Key
package com.example.multidatasource.bean;
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
import org.springframework.lang.Nullable;
/**
* @program: learn
* @description:获取路由key
**/
public class MyRoutingDataSource extends AbstractRoutingDataSource {
@Override
@Nullable
protected Object determineCurrentLookupKey() {
return DBContextHolder.get();
}
}
8.默认情况下,所有的查询都走从库,插入/修改/删除走主库。我们使用AOP面向切面通过方法名来区分操作类型(CRUD)
package com.example.multidatasource.aop;
import com.example.multidatasource.bean.DBContextHolder;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.springframework.stereotype.Component;
/**
* @create: 2020-11-16 01:18
**/
@Aspect
@Component
public class DataSourceAspect {
@Pointcut("!@annotation(com.example.multidatasource.annotation.Master) " +
"&& (execution(* com.example.multidatasource.service..*.select*(..)) " +
"|| execution(* com.example.multidatasource.service..*.get*(..)))")
public void readPointcut(){
}
@Pointcut("@annotation(com.example.multidatasource.annotation.Master) " +
"|| execution(* com.example.multidatasource.service..*.insert*(..)) " +
"|| execution(* com.example.multidatasource.service..*.add*(..)) " +
"|| execution(* com.example.multidatasource.service..*.update*(..)) " +
"|| execution(* com.example.multidatasource.service..*.edit*(..)) " +
"|| execution(* com.example.multidatasource.service..*.delete*(..)) " +
"|| execution(* com.example.multidatasource.service..*.remove*(..))")
public void writePointcut(){
}
@Before("readPointcut()")
public void read() {
DBContextHolder.slave();
}
@Before("writePointcut()")
public void write() {
DBContextHolder.master();
}
}
8.1 有一般情况就有特殊情况,特殊情况是某些情况下我们需要强制读主库,针对这种情况,我们定义一个主键,用该注解标注的就读主库
/*特殊情况是某些情况下我们需要强制读主库,针对这种情况,我们定义一个主键,用该注解标注的就读主库*/
public @interface Master {
}9.实体类+DAO+Service
package com.example.multidatasource.entity;
import lombok.Data;
@Data
public class User {
private String id;
private String name;
public User(String id, String name) {
this.id = id;
this.name = name;
}
}package com.example.multidatasource.dao;
import com.example.multidatasource.entity.User;
import org.apache.ibatis.annotations.Insert;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Param;
import org.apache.ibatis.annotations.Select;
import org.springframework.stereotype.Repository;
import java.util.List;
@Mapper
@Repository
public interface UserDao {
@Select("select * from user")
public List selectAllUser();
@Insert("insert into user(id,name) values(#{user.id},#{user.name})")
public int insertUser(@Param("user") User user);
} package com.example.multidatasource.service;
import com.example.multidatasource.dao.UserDao;
import com.example.multidatasource.entity.User;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class UserService {
@Autowired
private UserDao userDao;
public List selectAllUser(){
return userDao.selectAllUser();
}
public int insertUser(User user){
return userDao.insertUser(user);
}
} 10.测试类
package com.example.multidatasource;
import com.example.multidatasource.entity.User;
import com.example.multidatasource.service.UserService;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
import java.util.Random;
import java.util.UUID;
@SpringBootTest
class MultidatasourceApplicationTests {
@Autowired
UserService userService;
@Test
void contextLoads() {
}
@Test
public void testWrite() {
userService.insertUser(new User(UUID.randomUUID().toString(),"XXX"));
}
@Test
public void testRead() {
for (int i = 0; i < 4; i++) {
List users = userService.selectAllUser();
System.out.println(users.toString());
}
}
}
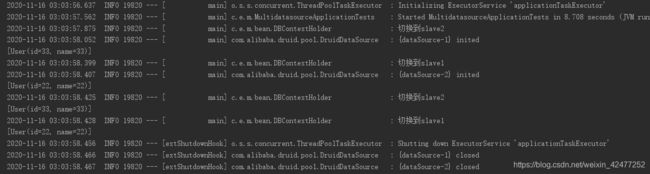
测试插入,走master

测试查询,轮询走slave1/2
6. 参考
- www.jianshu.com/p/f2f4256a2310
- www.cnblogs.com/gl-developer/p/6170423.html
- www.cnblogs.com/huangjuncong/p/8576935.html
- blog.csdn.net/liu976180578/article/details/77684583
- cnblogs.com/cjsblog/p/9712457.html