【3D计算机视觉】PointConv——在点云上高效实现卷积操作
PointConv: Deep Convolutional Networks on 3D Point Clouds 阅读笔记
- 一、摘要
- 二、模型
-
- 2.1 卷积定义
- 2.2 模型结构
-
- 2.2.1 卷积操作
- 2.2.2 高效卷积
- 2.2.3 反卷积
- 三、实验
论文地址: https://arxiv.org/pdf/1811.07246.pdf
代码地址: https://github.com/DylanWusee/pointconv
一、摘要
在机器人、自动驾驶和虚拟/增强现实应用中,直接获取 3D 数据的传感器日趋普遍。由于深度信息可以消除 2D 图像中的大量分割不确定性(segmentation ambiguity),并提供重要的几何信息,因此具备直接处理 3D 数据的能力在这些应用中非常宝贵。但 3D 数据通常以点云的形式出现。点云通常由一组无排列顺序的 3D 点表示,每个点上具有或不具有附加特征(例如 RGB 信息)。由于点云的无序特性,并且其排列方式不同于 2D 图像中的常规网格状像素点,传统的 CNN 很难处理这种无序输入。
本文提出了一种可以在非均匀采样的 3D 点云数据上高效进行卷积操作的方法。我们称这种操作为 PointConv。PointConv 能够在 3D 点云上构建多层深度卷积网络,其功能与 2D CNN 在栅格图像上的功能类似。但该结构可实现与 2D 卷积网络相同的平移不变性,以及点云中对点顺序的置换不变性。在实验中,PointConv 可以在分类问题上的效果达到当前最佳水平,同时,在 3D 点云的语义分割上能够给出远超论文提交时的最优的分割结果。为了说明 PointConv 可以实现真正的卷积操作,我们还在图像分类数据库 CIFAR-10 上进行了测试。实验表明,PointConv 能够达到类似于传统 CNN 的分类精度。
该研究的主要贡献包括:
- 提出密度加权卷积操作 PointConv,它能够完全近似任意一组 3D 点集上的 3D 连续卷积。
- 通过改变求和顺序,提出了 PointConv 的高效实现。
- 将 PointConv 扩展到反卷积(PointDeconv),以获得更好的分割结果。
二、模型
2.1 卷积定义
两个连续函数 f ( x ) f(x) f(x) 和 g ( x ) g(x) g(x) 关于一个 d d d 维向量 x x x 的卷积操作可以用下式表示:
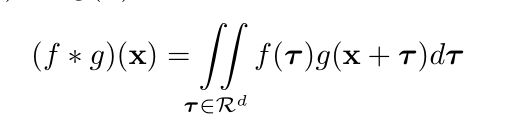
由于图像一般以固定的网格状的矩阵形式存储,因此在图像上,卷积核通常在 3x3,5x5 的固定网格上实现。在 CNN 中,不同的邻域采用同一个卷积核进行卷积,从而实现平移不变性。由此可见,图像上的卷积操作是连续卷积操作的一种特殊的离散化表示。
3D 点云数据的表达方式与图像完全不同。如图 1 所示,不同于图像,3D 点云通常由一些 3D 点组成。3D 点之间没有前后顺序之分,因此,在 3D 点云上的卷积操作应具有排列不变性,即改变 3D 点集中点顺序不应影响卷积结果。此外,点云上的卷积操作应适应于不同形状的邻域。
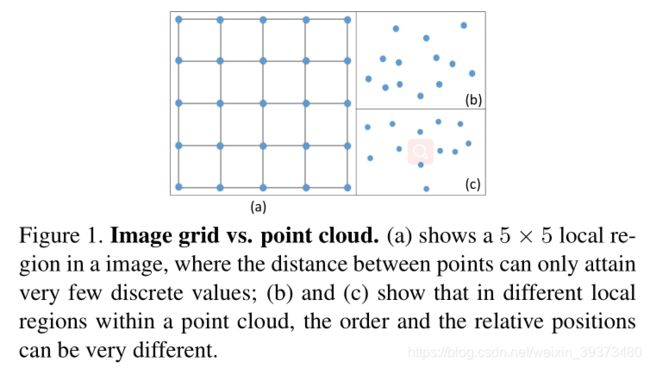
为满足这些要求,在 3D 空间中,可以把连续卷积算子的权重看作关于一个 3D 参考点的局部坐标的连续函数。如下式所示:
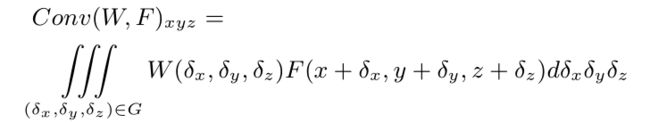
其中,W 和 F 均为连续函数, ( x , y , z ) (x, y, z) (x,y,z) 是 3D 参考点的坐标, ( δ x , δ y , δ z ) (δx,δy,δz) (δx,δy,δz) 表示邻域 G 中的 3D 点的相对坐标。上式可以离散化到一个离散的 3D 点云上。同时,考虑到 3D 点云可能来自于一个不均匀采样的传感器,为了补偿不均匀采样,我们提出使用逆密度对学到的权重进行加权。PointConv 可以由下式表示,
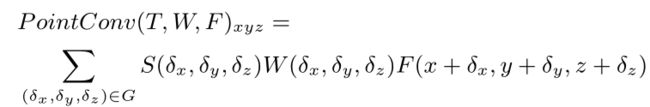
其中,S 表示逆密度系数函数。连续函数 W 可以用多层感知器(MLP)近似。函数 W 的输入是以 (x, y, z) 为中心的 3D 邻域内的 3D 点的相对坐标,输出是每个点对应的特征 F 的权重。S 是一个关于密度的函数,输入是每个点的密度,输出是每个点对应的逆密度系数。这个非线性的函数同样可以用一个多层感知机近似。
2.2 模型结构
2.2.1 卷积操作
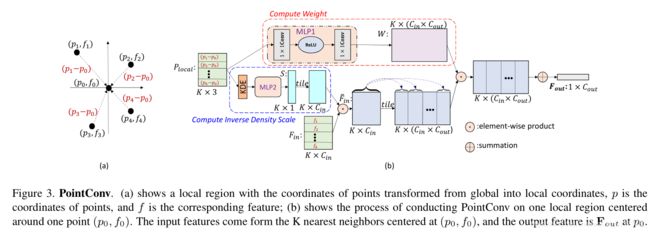
上图展示了在一个由 K 个 3D 点组成的邻域上进行 PointConv 的流程。图中, C i n C_{in} Cin 和 C o u t C_{out} Cout 表示输入和输出的特征的维度, k k k, c i n c_{in} cin, c o u t c_{out} cout 表示索引。对于 PointConv 来说,输入由三部分组成:3D 点的相对坐标 P l o c a l P_{local} Plocal,密度 Density 和特征 F i n F_{in} Fin。3D 点的相对坐标 P l o c a l P_{local} Plocal 经过连续函数 MLP1 之后可以得到对应的每一个点的特征的权重 W;而密度 Density 经过 MLP2 之后得到逆密度系数 S;在得到权重 W, 逆密度系数 S 以及输入的特征 F 之后,可以利用下式进行卷积,以得到输出特征 F o u t F_{out} Fout:
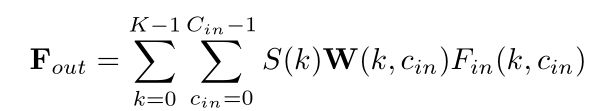
PointConv 通过学习连续的卷积核函数,适应了 3D 点云的不规则的特性,实现了置换不变性,使得卷积操作由传统的图像扩展到了 3D 点云领域。
2.2.2 高效卷积
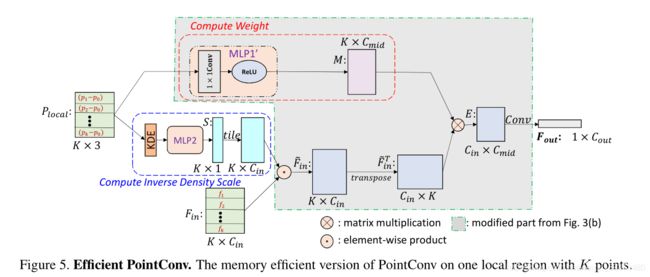
最初版本的 PointConv 实现起来内存消耗大、效率低。为了解决这些问题,我们提出了一种新型重构方法,将 PointConv 简化为两个标准操作:矩阵乘法和 2D 卷积。这个新技巧不仅利用了 GPU 的并行计算优势,还可以通过主流深度学习框架轻松实现。由于逆密度尺度没有这样的内存问题,所以下面的讨论主要集中在权重函数 W 上。
具体来说,令 B 为训练阶段的 mini-batch 大小,N 为点云中的点数,K 为每个局部区域的点数, C i n C_{in} Cin为输入通道数, C o u t C_{out} Cout 为输出通道数。对于点云,每个局部区域共享相同的权重函数,这些可以通过 MLP 学习得到。但不同点处的权重函数计算出的权重是不同的。由 MLP 生成的权重参数张量的尺寸为 B × N × K × ( C i n × C o u t ) B×N×K×(C_{in}×C_{out}) B×N×K×(Cin×Cout)。假设 B = 32,N = 512,K = 32, C i n C_{in} Cin = 64, C o u t C_{out} Cout = 64,并且权重参数以单精度存储,一层网络则需要 8GB 的内存。如此高的内存消耗将使网络很难训练。Edge-Conditioned Convolution使用非常小的网络和少数的滤波器,这显著降低了其性能。
为了解决前面提到的内存问题,我们提出了一个基于 Lemma 1 的内存高效版 PointConv,这也是本文最重要的贡献。

具体的证明可以参考原论文。根据 Lemma 1 重新实现 PointConv,可实现完全相同的卷积操作,但大大减少内存消耗。采用 1 中相同的配置,单层卷积操作的内存占用将由 8G 缩小为 0.1G 左右,变为原来的 1/64. 图 5 展示了高效的 PointConv 卷积操作。
2.2.3 反卷积
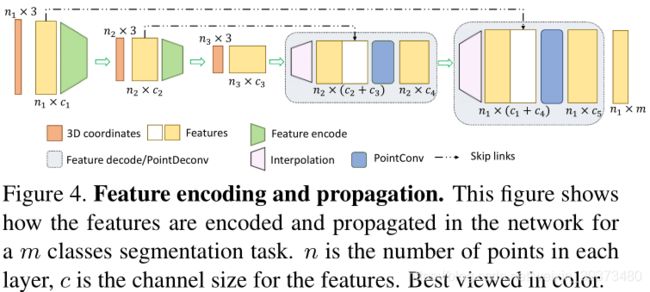
在分割任务中,将信息从粗糙层传递到精细层的能力非常重要。由于 PointConv 可以实现标准卷积操作,因此将 PointConv 扩展为 PointDeconv 是很顺理成章的。PointDeconv 由两部分组成:插值和 PointConv。首先,使用一个线性插值算法来得到精细层的特征的初始值,再在精细层上进行一个 PointConv 进行优化特征,从而获得较高精度的特征值。图 4 展示了反卷积操作的具体流程。
三、实验
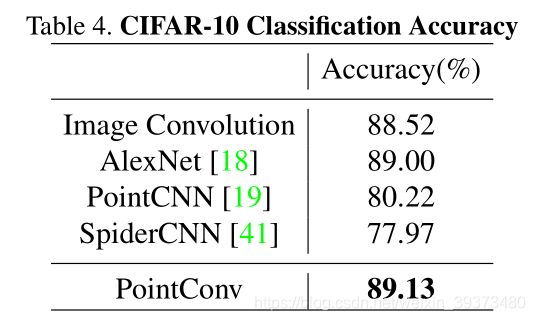
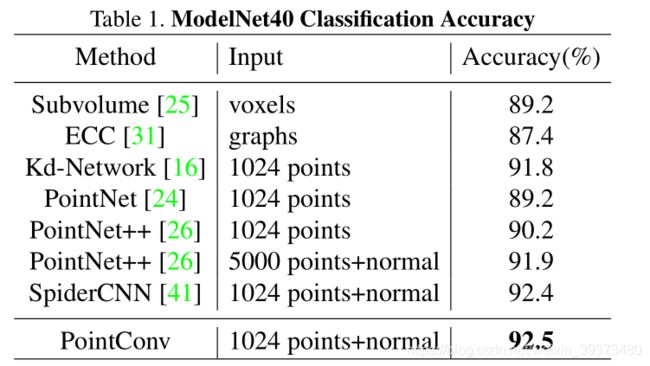
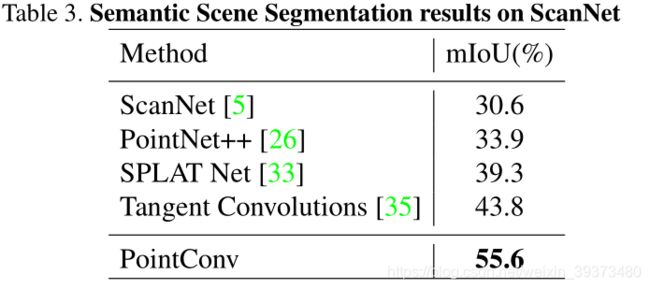
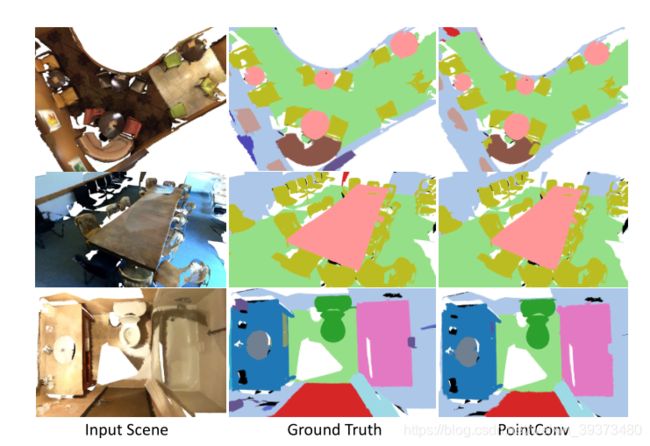
为了说明 PointConv 的有效性,我们在常用的 3D 点云数据库上进行了测试,包括 ModelNet40,ShapeNet 和 ScanNet. 同时,为了说明 PointConv 是可以和图像 CNN 进行等价,我们在 CIFAR10 上进行了测试。这里我们重点介绍在 ScanNet 上的测试结果,更多实验结果请参考论文原文。如表 3 所示,仅使用 4 层 PointConv 网络,即可在场景的的语义分割测试中达到远好于其他算法的效果,达到了当前最优水平。图 7 给出了室内场景语义分割的一些可视化结果
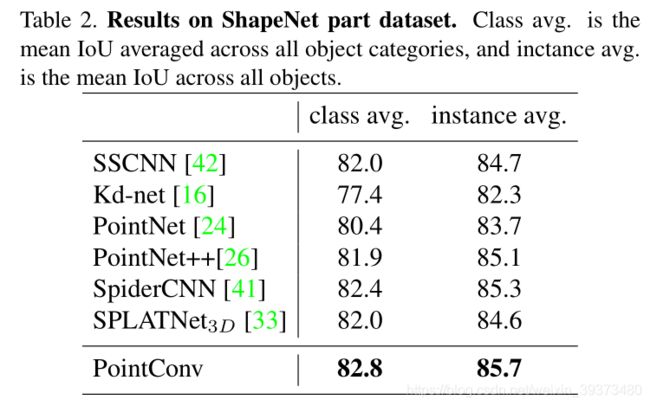
为了说明 PointConv 可以等价于图像上的 CNN,我们在 CIFAR10 上进行了测试。首先,将 CIFAR10 的图像像素转变为网格状排列的点云,再使用 PointConv 进行分类。表格 4 给出了 PointConv 与其他 3D 点云算法和图像 CNN 的分类精度对比。可以看到,5 层的 PointConv 可以达到和 AlexNet(5 层 CNN)相似的精度,同时,PointConv(VGG) 也可以达到和 VGG 相似的分类精度。与此同时,其他的 3D 点云算法,如 PointCNN 等,则仅能取得 80% 左右的分类精度。这项实验说明了 PointConv 可以取得与图像 CNN 同等水平的学习效果。