Golang协程和Java线程
前言
最近刚读完Java并发编程实战、深入理解Java虚拟机。打算写一篇总结性文章,思来想去文章的内容,最后决定还是不要限定于Java这门语言,应该从提升性能的整体出发,所以就有了这篇文章。
一、什么是串行程序?
串行程序就是一次只能做一件事情。拿一个早上起床去上班的例子来说,它分为以下几个步骤,这些步骤跟串行程序的语义是一样的。它们必须一件一件来完成。

二、什么是并发程序
现在假设人的需求变了,需要在刷牙的时候煮个鸡蛋、热个牛奶当早餐吃。如果完全按照串行程序的语义来执行,事情就会变成这样:我在煮鸡蛋的过程中什么都不能做,必须等鸡蛋煮好后才能走开去热牛奶。显然在现实生活中,鸡蛋放在锅里煮的时候我就可以去刷牙洗脸了,不必一直在这里无意义的等待
,所以,在程序世界中也必须能够支持这些符合现实世界的行为。
等待鸡蛋煮好、牛奶热好的动作,在程序里有一个名词叫“IO等待”。处于IO等待时进程(或线程)将处于一种叫“阻塞”的状态,此时是不消耗CPU时间的,所以可以用来做其他事情。这就叫并发程序。
三、摩尔定律
摩尔定律是由Intel公司创始人之一Gordon Moore发现的规律,意思是随着芯片制造技术的发展,晶体管的体积越来越小,从而有可能将越来越多的晶体管放入一个芯片中(引自Andrew S.Tanenbaum和Herbert Bos的《现代操作系统》)。这种基于经验的法则揭示了CPU运行指令(可比喻现实世界的某个事件)的速度会越来越快,但是实际上并非CPU越快程序就越快了,这中间存在着沟通问题。
比如有个程序员,ta的编程能力很强,但是编程这个动作是需要需求来驱动,如果沟通过程中不够顺畅,很片段化,那么整个开发进度就会被沟通成本拖慢。同样,在计算器系统中也存在这样的问题。假如有一个程序是打印一个“hello world”,hello程序的机器指令最初是存放在磁盘上,当程序加载时,它们被复制到主存,当处理器要运行程序时,指令又被复制到处理器。这其中,CPU从主存读取到寄存器的速度大概是从磁盘读取到主存的1000万倍,从寄存器读取的速度大概是主存的100倍。所以就有了后来的多核处理器,也就是多个cpu组合在一起,这样才能同时做更多的事情。
四、什么是并行程序
1. 进程
进程是处理器对自己的抽象,它由程序加数据两部分组成,进程在创建时候会在寄存器、CPU高速缓存(如果有的话)、主存中加载需要的数据和程序本身(指令集合),主存的数据是每个进程独有的,程序是可以多个进程共享的。在单核处理器系统中,同一时刻只能有一个进程在运行,但是CPU切换进程的速度特别快,导致大家以为程序都是同时执行的,这个叫做伪并发。
人们通常能够感知到的时间大概是以秒为单位的,但现在CPU的时钟周期已经远远超过了人们的感知尺度,比如一个1GHZ的CPU在一秒内能有10的9次方个时钟周期,如果三个时钟周期能运行一个指令,那么在一秒内CPU就能运行大约3亿个指令,很显然在这种速度下人们就会误以为程序是同时执行的了。
2. 线程
线程是在进程之上的抽象,一个进程可以有多个线程,一个线程必须属于某个进程。线程可以共享进程的数据,可以把进程理解为一个主线程。当主线程被譬如磁盘IO之类的进入阻塞状态后,可以再创建一个线程来做其他的操作,这就是上面所说的并发。特别是在互联网服务器的进程上,线程发挥了很大的作用,因为很多的请求都不是CPU密集型的,都是IO密集型的。
3. 超线程技术
为了让单核CPU能够并行执行程序,CPU制造厂商发明了超线程技术。顾名思义,并行就是同一时间做很多事情。比如人在听音乐(是指耳朵)的同时可以摆动身体(手脚等),因为它们都是我们身体的不同部分,所以可以同时运行(暂且用这个词表达。手动狗头)。CPU也是一样,它可以分析指令用到了哪些执行单元,比如一条指令用到了加法器另一条用到了浮点数计算器,那么就可以同时让这两条指令执行。所以大家在买CPU的时候要小心了,需要区分什么是两核四线程和四核CPU。
4. 多核处理器系统
多核CPU大家应该通过上文可以猜到了,它就是将多个CPU集成到一起的一个“CPU”。拥有多核CPU的操作系统就会有并行的能力了。并行就是同时能处理多个任务,比如盖房子的时候,CPU的一个核心就代表一个工人,增加工人就代表着并行搬砖或砌砖的能力。
只有多核处理器才能同时运行多个进程,同时运行进程数等于核心数。多核处理器系统特别适合软件算法中的分治法,将一个规模很大的问题分解为若干个小问题,通过并行解决这些小问题,来解决大问题。随着现在互联网用户越来越多,高并发的场景也就越密集,多核cpu能支撑单核cpu所不能承载的高并发访问。而且多核处理器可以避免一些线程的上下文切换开销,在第六节会讲到。
五、阿姆达尔定律
从摩尔定律提升cpu运算能力的时代,到多核高并发的时代,出来了一个新的概念,叫阿姆达尔定律(Amdahl’s law,由 Gene Amdahl 于1967年提出)。它揭示了一个问题和一个预测公式,问题就是:有些程序并不是增加cpu核心数就可以让它的运行速度成比例增长的,有时甚至是完全没有作用的。就比如,你可以通过增加工人来加快造房子的速度,但你无法通过增加设计师来加快设计房屋图纸的速度。因为很多程序在本质上还是串行的,如果不把串行这部分改为并行程序,将无法利用多核处理器的优势。
预测公式是指:在增加CPU核心的情况下,程序在理论上能够达到的加速比,它的公式如下:
S p e e d u p = 1 F + ( 1 − F ) N Speedup =\cfrac{1}{F+ \cfrac{(1-F)}{N}} Speedup=F+N(1−F)1
其中Speedup代表加速比,F代表程序的串行部分,N代表CPU核心数。在N接近于无穷大时,最大加速比接近于1/F,假设F为50%,那么加速比最多为2(不管多少个CPU核心)。因此需要将程序中串行的部分减少,来利用多处理器的优势。
在阿姆达尔定律的作用下,程序要不仅要提升单线程程序的性能,还要提高程序的可伸缩性,可伸缩性就是指程序在提升计算机资源(CPU核心数、内存、IO带宽等)的情况下,吞吐量或者处理能力能否相应的增加。可伸缩性在并发编程中尤为重要,因为很多程序都还是串行的。
不仅要优化逻辑上的串行,还要尽量避免在访问共享区域时使用同步,将同步锁分解、分段,如果可以的话应该使用CAS(compare and swap)。这些技术能有效地降低线程在访问共享区域时的串行动作。
有一个最快衡量程序并行度的方法,那就是查看服务器的CPU利用率,如果不是你们业务量特别低的话,CPU的利用率应该长期处于接近于满载的状态才是最好的并行程序(虽然并不能由此得出你们的应用程序效率有多低,但是至少知道CPU能力没有被完整开发)。
六、线程实现的模型
实现线程有两种方式,一种是内核线程、一种是用户线程。
1、内核线程
内核线程就是在操作系统内核态实现的线程,是受操作系统直接管理的线程模型。Java的Hot spot虚拟机就是用的这种线程模型,一个轻量级线程(轻量级线程(lightweight process)是专门用来对应内核线程的用户态线程)对应一个内核线程,1:1的关系。在这种模型下,线程调度、上下文切换都是由内核来完成的,Hot spot虚拟机只需要调用操作系统原语即可。
它的缺点就在于线程上下文切换。由于线程是跟进程共享数据的,所以没有虚拟内存的数据需要保存。线程上下文的内容就是:程序计数器: 指令序列中下一条指令的位置、寄存器中的操作数:运算中的变量的值。
通常中断一个线程并运行另一个线程时,需要将当前线程上下文存在主存,然后把下一个要执行的线程的上下文恢复到cpu的寄存器中,并且让cpu从程序计数器处继续执行。这些过程会让CPU重复无效劳动,如果过于频繁的话,就会降低程序的吞吐量。
只要线程的数量超过了CPU的核心数,就会发生上下文切换。有些线程池比如Java的ForkJoinPool,就会默认线程数为CPU可用核心数,防止线程上下文切换的开销。
2、用户线程
用户线程是指在用户态的进程自己实现线程的管理、调度算法等。它采用1:M的模式,即一个轻量级线程多个用户线程。因为内核不知道用户线程的存在,所以内核只能调度内核线程。这种实现模式就是灵活,但缺点也很明显,调度算法实现很复杂,并且这种模型无法利用多核CPU的优势。
七、Golang的线程模型-协程
Golang作为专为并发而生的编程语言,它原生支持并发编程,最大限度的使易于编写和高并发性融合在一起。第六节我们讲到,内核线程和用户线程的实现模型分别是1:1和1:M,它们各有优缺点。而Golang使用的是M:N模型,也就是多个内核线程对应多个用户线程,如下图所示(LWP是轻量级线程的简写)
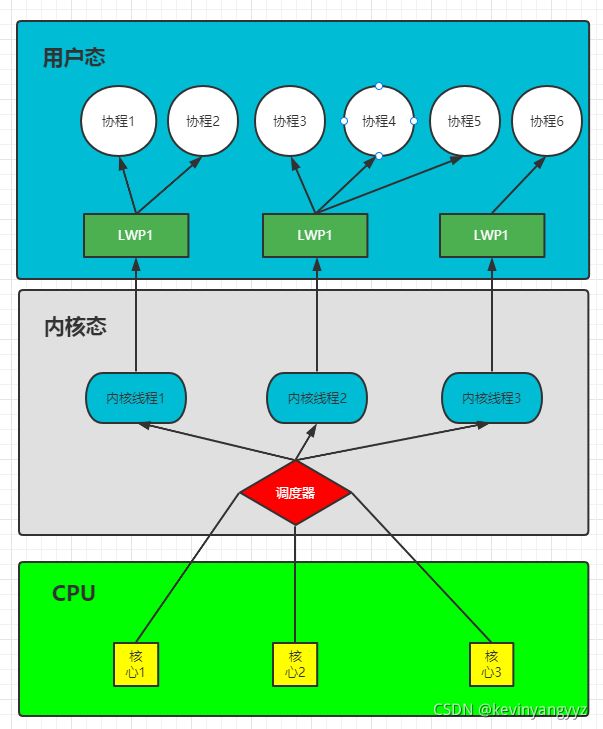
Go会使用M个内核线程来支撑N的名叫goroutine的协程,由于内核线程可以由内核调度,就充分利用了多核CPU的优势,而且goroutine的调度算法是由Go来实现的,所以能够减少内核线程在高并发时频繁的上下文切换问题。
Goroutine非常轻量级,linux操作系统线程的上限是1024个,用满时会占用内存1个G。一个线程大概需要1MB的栈,而协程可能只需要不到1kb,如果按1G的内存算的话,goroutine能创建大约10万个。最重要的是goroutine的调度完全是GO自己实现的机制,它可以在某个goroutine被IO阻塞时,将CPU资源分配给其他协程,再加上用户态的上下文切换,CPU浪费被大大优化。
八. Java的解决方案
golang的协程主要解决了两个大问题,一是:IO等待让CPU处于闲置状态不作为,二是:内核线程频繁的上下文切换导致CPU做无用功。对于这两个问题,Java早就有了自己的解决方案。这些解决方案有些是受到操作系统、Java虚拟机甚至是硬件级别支持的。
1. NIO
NIO(Non-blocking-I/O)就跟它的名字一样,非阻塞IO。跟BIO(Blocking I/O)不同的是,它在接收数据的Buffer处不会发生阻塞,而是通过一个select的系统调用来等待某些Buffer里数据的到来,当数据到来时select会通知等待的线程来处理,也不用线程一直轮询调用系统函数来查询有没有数据,属于多路复用I/O。这样实现的效果就是,线程不会因为某个客户端不发送消息就阻塞在那里不做其他的工作,还可以接收其他客户端发来的数据,从而提高并发性。
2. 自旋锁
除了内核调度算法强制拿走CPU执行权,Java并发程序性能受影响的部分主要就是线程在访问内存共享区的同步操作了。所以Java引入了CAS这种处理器级别的原子操作原语,使用这个原语修改共享数据时不会发生阻塞,而是以测试的方式来判断是否可修改,不能修改就循环尝试,直到可修改为止。
在Java的java.util.concurrent.atomic下有很多原子变量类,可以实现原子的共享数据访问。而且不止是在编码层面,在虚拟机层面也会统计获取锁的时间,如果很短的话也会优化成自旋操作。这么做好处就是不会频繁的上下文切换,但是会占用CPU时间片。
3. 锁消除、锁粗化
Hot spot虚拟机的JIT编译器会自动优化一些不必要的锁获取操作,比如一个引用没有逃逸出方法的StringBuffer的连续append操作,实际上可以不用锁。锁粗化就是指有些地方连续不必要的加锁解锁,就算不存在线程竞争,这种操作会导致性能更低下。于是虚拟机就会把这些锁粗化到包含它们。
4. 锁升级
Jdk1.6后增加新的锁优化机制,分别是偏向锁、轻量级锁。也就是说,在某个需要同步的对象上,被第一个线程加锁时,会使用偏向锁模式,如果后面没有其他线程竞争过这个对象上的锁,第一个线程下次再进入临界区的时候就不会再加锁。当虚拟机发现有其他线程竞争时,就会升级为轻量级锁。轻量级锁是用CAS操作来尝试进入临界区的,如果线程获取锁的操作是断断续续的,轻量级锁就会继续下去。但是如果某个线程在持有锁时,被其他线程发现了,就会升级成重量级锁。重量级锁就会在每次拿不到锁时阻塞并导致上下文切换了。
5. 纤程
纤程(Fiber)是一个实验中的项目,目的也是要做到和Golang的协程一样做自己调度的混合型线程,它属于OpenJDK在2018年开始的Loom项目。
总结
软件开发没有银弹,这是软件界有名的书《人月神话》的作者说的。所谓的没有银弹是指没有任何一项技术或方法可使软件工程的生产力在十年内提高十倍。Golang在近几年的开发者和金融领域的应用确实越来越多,但是Java的整个生态和多年的优化还是不可替代的,特别是还在实验室的一些项目比如Graal VM、Graal编译器、Loom项目都非常有潜力。不管是软件优化还是架构,都没有一套完整而又高性能的框架,是需要一步一步迭代出来,没有最适合的只有更适合的。最后,编写完这篇文章的时间正好是2021年10月24日,1024程序员节,祝各位程序员朋友节日快乐!