Spark-RDD
文章目录
-
- 1.RDD是什么
- 2.RDD的主要特征:
- 3.RDD的创建:
-
- 1)从集合中创建RDD:
- 2)从外部存储创建RDD:
- 3)从其它RDD创建:
- 4.RDD两种类型操作:
-
- 1)转换操作(lazy模式):
- 2)行动操作:
- 3)键值对RDD(PairRDD):
- 4)转化操作与行动操作区别:
- 5)map()和mapPartition()的区别:
- 6)reduceByKey和groupByKey的区别
1.RDD是什么
RDD:弹性分布式数据集(Resillient Distributed Dataset),是Spark中最基本的数据抽象。代码中是一个抽象类,它代表一个不可变、可分区、里面的元素可并行计算的集合。
2.RDD的主要特征:
1)RDD是由一系列的partition组成的。
2)函数是作用在每一个partition(split)上的。
3)RDD之间有一系列的依赖关系。
4)RDD提供一系列最佳的计算位置。
5)RDD是只读的,类似于Java中的String。

3.RDD的创建:
(下面的代码都是在spark-shell中完成,后面会写在idea里面完成的)
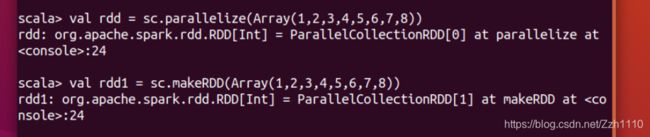
1)从集合中创建RDD:
利用SparkContext类中的两个方法:parallelize和makeRDD。
2)从外部存储创建RDD:
从外部存储创建RDD是指从内部读取数据文件创建RDD。
利用SparkContext对象的textFile方法读取数据集。 用 sc.textFile(“路径”),在路径前面加上"file:///"

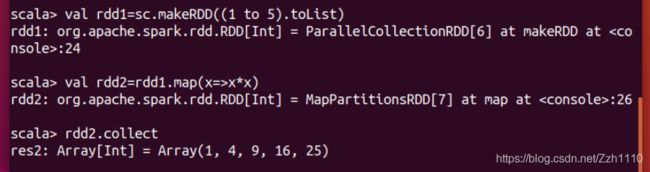
3)从其它RDD创建:
4.RDD两种类型操作:
1)转换操作(lazy模式):
基于现有的数据集创建一个新的数据集。(map、filter、faltMap、sortBy、groupby、distinct、union、groupByKey、reduceByKey)
①map:通过转换已有的RDD生成新的RDD。

②filter:过滤RDD中的元素。
rdd.filter(x=>x.2>1) 也可以写成rdd.filter(._2>1) 2是表示第二个元素。

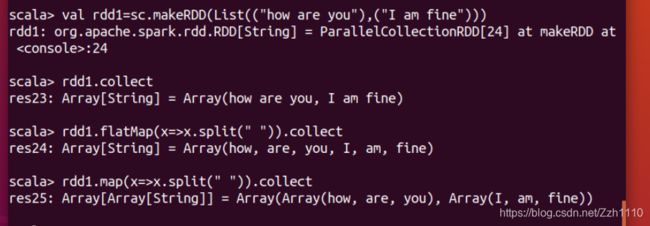
③flatMap:扁平化(压成同一级别,常用来用来切分单词)。
flatMap其实相当于先Map后flatten。(Map+flatten)
④sortBy:排序。
第1、2、3个参数为:进行排序的值、降序、分区设置

groupBy:分组。

⑤distinct:去重。
直接用即可。
⑥Union:将两个RDD元素合并成一个,不进行去重操作。
⑦intersection:求交集。
⑧subtract:求并集。
◉cartesian:笛卡儿积。(将两个集合的元素两两组合成一组,A,B两个RDD有2个元素,则使用cartesian求则会得到4个元组的RDD)
2)行动操作:
在数据集上进行运算,返回计算值。(collect、count、first、take、reduce、sample、saveAsTestFile、foreach)
①collect:以数组的形式返回RDD中所有元素。
②count:RDD中元素的个数。
③first:返回RDD中的第一个元素。
④take(N):取RDD中的前N个元素。
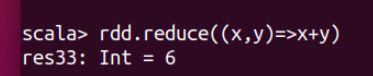
⑤reduce:并行整合RDD中所有数据
⑥sample(withReplacement : scala.Boolean, fraction : scala.Double,seed scala.Long)
sample算子时用来抽样用的,其有3个参数
withReplacement:表示抽出样本后是否在放回去,true表示会放回去,这也就意味着抽出的样本可能有重复
fraction :抽出多少,这是一个double类型的参数,0-1之间,eg:0.3表示抽出30%
seed:表示一个种子,根据这个seed随机抽取,一般情况下只用前两个参数就可以,那么这个参数是干嘛的呢,这个参数一般用于调试,有时候不知道是程序出问题还是数据出了问题,就可以将这个参数设置为定值

⑦saveAsTextFile(path)
将数据集的元素以textfile的形式保存到本地文件系统–HDFS或者任何其他Hadoop支持的文件系统。对于每个元素,Spark将会调用toString方法,将它转换为文件中的文本行。
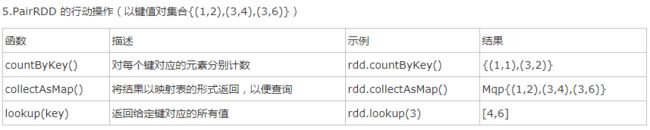
3)键值对RDD(PairRDD):
keys和values:
keys返回一个只包含键的RDD,values返回一个包含值的RDD。
①zip:
将两个RDD组合成Key/Value形式的RDD,这里默认两个RDD的partition数量以及元素数量都相同,否则会抛出异常。
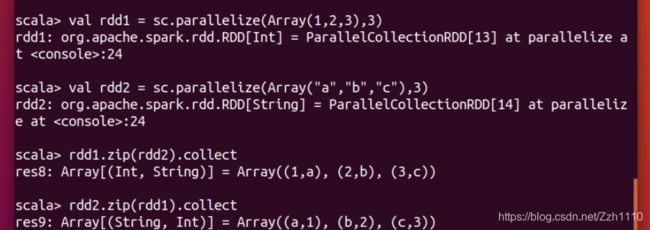
②join:
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD



4)转化操作与行动操作区别:
转化操作返回的是 RDD,而行动操作返回的是其他的数据类型;
RDD的所有转换操作都是懒执行的,只有当行动操作出现的时候Spark才会去真的执行。
5)map()和mapPartition()的区别:
map():每次处理一条数据。
mapPartition():每次处理一个分区的数据,这个分区的数据处理完后,原RDD中分区的数据才能释放,可能导致OOM。
建议:当内存空间较大的时候建议使用mapPartition(),以提高处理效率。
6)reduceByKey和groupByKey的区别
reduceByKey:按照key进行聚合,在shuffle之前有combine(预聚合)操作,返回结果是RDD[k,v]。
groupByKey:按照key进行分组,直接进行shuffle。
注意:reduceByKey比groupByKey,效率更高一些,建议使用。