数据湖_Hudi概述
转载自 : 数据湖-hudi概述_懒猫gg的博客-CSDN博客
前言
数据湖是目前比较热的一个概念,许多企业都在构建或者计划构建自己的数据湖。
数据湖是一个集中式存储库,允许您以任意规模存储所有结构化和非结构化数据。您可以按原样存储数据(无需先对数据进行结构化处理),并运行不同类型的分析 – 从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决策。
从数据仓库看数据湖
引用一下AWS数据仓库和数据湖官方对比。
- 数据仓库是一个优化后的数据库,用于分析来自事务系统和业务线应用系统的关系型数据。事先定义好数据结构和Schema,以便提供快速的SQL查询。原始数据经过一些列的ETL转换,为用户提供可信任的“单一数据结果”。
- 数据湖有所不同,因为它不但存储来自业务线应用系统的关系型数据,还要存储来自移动应用程序、IoT设备和社交媒体的非关系型数据。捕获数据时,不用预先定义好数据结构或Schema。这意味着数据湖可以存储所有类型的数据,而不需要精心设计数据结构。可以对数据使用不同类型的分析方式(如SQL查询、大数据分析、全文搜索、实时分析和机器学习)。
总结: 数据湖对数据包融性更强,数据处理方式更多样化。 反之, 数据湖的数据更乱
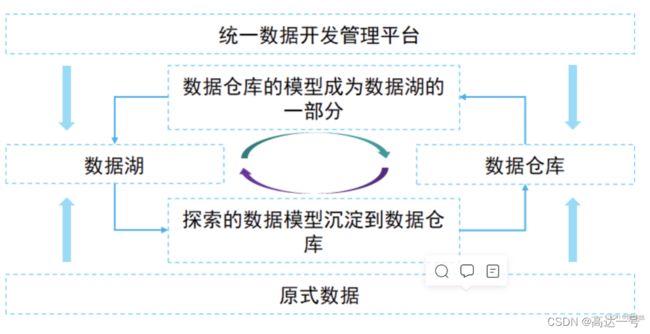
- 湖和仓的元数据无缝打通,互相补充,数据仓库的模型反哺到数据湖(成为原始数据一部分),湖的结构化应用沉淀到数据仓库。
- 统一开发湖和仓,存储在不同系统的数据,可以通过平台进行统一管理。
- 数据湖与数据仓库的数据,根据业务的发展需要决定哪些数据放在数仓,哪些放在数据湖,进而形成湖仓一体化。
- 数据在湖,模型在仓,反复演练转换。
Hudi是什么
Hudi是Uber公司开源的数据湖架构,它是围绕数据库内核构建的流式数据湖,一种新的技术架构。
根据流式的需求,他设计文件存储和管理 实现 “COW vs MOR” 两种数据模型
为了适应这种hudi的数据模型并融入现在的大数环境,他给所有组件写了huid 插件。
Hudi作为一个数据湖方案,他自己本身不产生任何业务数据, 也不用单独布署。完全依附于其它大数据组件

- hudi 底层的数据可以存储到hdfs、s3、azure、alluxio 等存储
- hudi 可以使用spark/flink 计算引擎来消费 kafka、pulsar 等消息队列的数据,而这些数据可能来源于 app 或者微服务的业务数据、日志数据,也可以是 mysql 等数据库的 binlog 日志数据
- spark/hudi 首先将这些数据处理为 hudi 格式的 row tables (原始表),然后这张原始表可以被 Incremental ETL (增量处理)生成一张 hudi 格式的 derived tables 派生表
- hudi 支持的查询引擎有:trino、hive、impala、spark、presto 等
- 支持 spark、flink、map-reduce 等计算引擎继续对 hudi 的数据进行再次加工处理
数据组织结构
Hudi表的数据文件,可以使用操作系统的文件系统存储,也可以使用HDFS这种分布式的文件系统存储。为了后续分析性能和数据的可靠性,一般使用HDFS进行存储。以HDFS存储来看,一个Hudi表的存储文件分为两类。

- .hoodie 文件:由于CRUD的零散性,每一次的操作都会生成一个文件,这些小文件越来越多后,会严重影响HDFS的性能,Hudi设计了一套文件合并机制。 .hoodie文件夹中存放了对应的文件合并操作相关的日志文件。
- amricas和asia相关的路径是实际的数据文件,按分区存储,分区的路径key是可以指定的。
hoodie文件
Hudi把随着时间流逝,对表的一系列CRUD操作叫做Timeline,Timeline中某一次的操作,叫做Instant。
- Instant Action,记录本次操作是一次数据提交(COMMITS),还是文件合并(COMPACTION),或者是文件清理(CLEANS);
- Instant Time,本次操作发生的时间;
- State,操作的状态,发起(REQUESTED),进行中(INFLIGHT),还是已完成(COMPLETED);

hoodie文件夹中存放对应操作的状态记录
Timeline来解决因为延迟造成的数据时序问题
数据文件
Hudi真实的数据文件包含一个metadata元数据文件(记录分区)和数据文件parquet列式存储。
 为了实现数据的CRUD,需要能够唯一标识一条记录,Hudi将把数据集中的唯一字段(record key ) + 数据所在分区 (partitionPath) 联合起来当做数据的唯一键。
为了实现数据的CRUD,需要能够唯一标识一条记录,Hudi将把数据集中的唯一字段(record key ) + 数据所在分区 (partitionPath) 联合起来当做数据的唯一键。
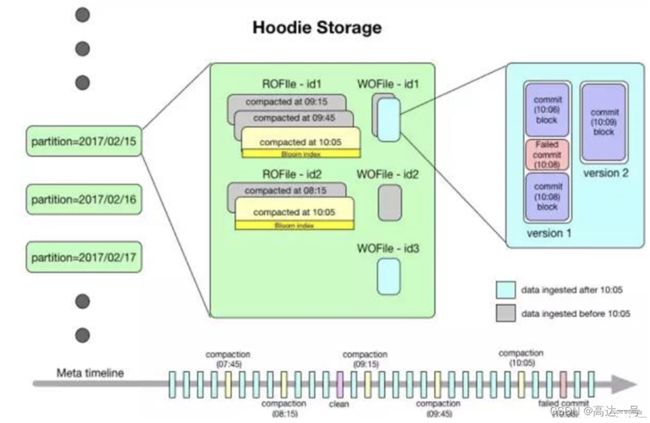
- Hudi数据集的组织目录结构与Hive表示非常相似,一份数据集对应这一个根目录。数据集被打散为多个分区,分区字段以文件夹形式存在,该文件夹包含该分区的所有文件。
- 在根目录下,每个分区都有唯一的分区路径,每个分区数据存储在多个文件中。
- 每个文件都有惟一的fileId和生成文件的commit所标识。如果发生更新操作时,多个文件共享相同的fileId,但会有不同的commit。
Index 索引
Hudi维护着一个索引,以支持在记录key存在情况下,将新记录的key快速映射到对应的fileId。
- Bloom filter:存储于数据文件页脚。默认选项,不依赖外部系统实现。数据和索引始终保持一致。
- Apache HBase :可高效查找一小批key。在索引标记期间,此选项可能快几秒钟。

Hudi的表格式
Hudi提供两类型表:写时复制(Copy on Write,COW)表和读时合并(Merge On Read,MOR)表。
- 对于 Copy-On-Write Table,用户的 update 会重写数据所在的文件,所以是一个写放大很高,但是读放大为 0,适合写少读多的场景。
- 对于 Merge-On-Read Table,整体的结构有点像 LSM-Tree,用户的写入先写入到 delta data 中,这部分数据使用行存,这部分 delta data 可以手动 merge 到存量文件中,整理为 parquet 的列存结构。
Copy on Write
简称COW,顾名思义,它是在数据写入的时候,复制一份原来的拷贝,在其基础上添加新数据。正在读数据的请求,读取的是最近的完整副本,这类似Mysql 的MVCC的思想。

COW表主要使用列式文件格式(Parquet)存储数据,在写入数据过程中,执行同步合并,更新数据版本并重写数据文件,类似RDBMS中的B-Tree更新。
- 更新update:在更新记录时,Hudi会先找到包含更新数据的文件,然后再使用更新值(最新的数据)重写该文件,包含其他记录的文件保持不变。当突然有大量写操作时会导致重写大量文件,从而导致极大的I/O开销。
- 读取read:在读取数据时,通过读取最新的数据文件来获取最新的更新,此存储类型适用于少量写入和大量读取的场景
Merge On Read
简称MOR,新插入的数据存储在delta log 中,定期再将delta log合并进行parquet数据文件。
读取数据时,会将delta log跟老的数据文件做merge,得到完整的数据返回。下图演示了MOR的两种数据读写方式。
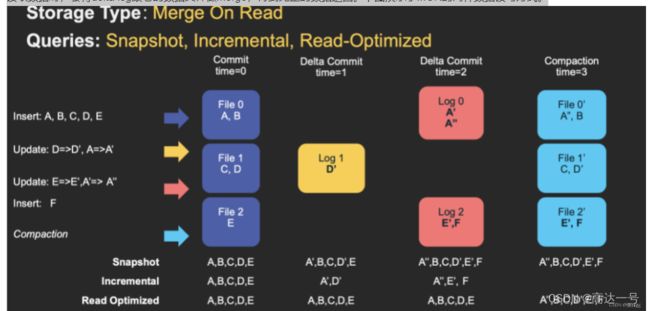
MOR表是COW表的升级版,它使用列式(parquet)与行式(avro)文件混合的方式存储数据。在更新记录时,类似NoSQL中的LSM-Tree更新。
- 更新:在更新记录时,仅更新到增量文件(Avro)中,然后进行异步(或同步)的compaction,最后创建列式文件(parquet)的新版本。此存储类型适合频繁写的工作负载,因为新记录是以追加的模式写入增量文件中。
- 读取:在读取数据集时,需要先将增量文件与旧文件进行合并,然后生成列式文件成功后,再进行查询。
在 READ OPTIMIZED 模式下,只会读最近的经过 compaction 的 commit。
查询
Hudi支持三种不同的查询表的方式:
1. Snapshot Queries(快照查询):
动态合并最新的基本文件(parquet)和增量文件(Avro)来提供近实时数据集
- Copy On Write表读parquet文件,
- Merge On Read表读parquet + log文件。
2. Incremental Queries(增量查询)
仅查询新写入数据集的文件,需要指定一个Commit/Compaction的即时时间(位于Timeline上的某个instant)作为条件,来查询此条件之后的新数据
3. Read Optimized Queries(读优化查询)
直接查询基本文件(数据集的最新快照),其实就是列式文件(Parquet)。
主要参考
《数据湖技术架构演进》
《数据湖系列文章》
《Hudi官方文档》