【腾讯云 Cloud Studio 实战训练营】使用python爬虫和数据可视化对比“泸州老窖和五粮液4年内股票变化”
Cloud Studio

简介
Cloud Studio是腾讯云发布的云端开发者工具,支持开发者利用Web IDE(集成开发环境),实现远程协作开发和应用部署。
现在的Cloud Studio已经全面支持Java Spring Boot、Python、Node.js等多种开发模板示例库,让开发者们可以更轻松地上手。它还具备在线开发、调试、预览等强大的功能,让你可以轻松实现各种开发需求。而且,我还听说Cloud Studio已经在内测中集成了在线开发协作模块,下一个版本将会全量开放,这意味着你将能够随时随地与团队成员一起设计、讨论和开发项目。
还有一点非常重要的是,Cloud Studio具备SSH连接能力,这意味着你可以安全地连接到云端工作空间,更加方便地连接云资源。这样一来,你可以随时随地享受到云端开发的便利,不再受限于地点和设备。
另外,Cloud Studio还具备标准化的云端安装部署能力,支持主流代码仓库的云端克隆。这就意味着你可以将你的代码库轻松地迁移到云端,让你的开发过程更加规范化和便捷化。
创建账号
Cloud Studio 的官网: https://cloudstudio.net/
目前共有三种登录方式:CODING,微信,GITHUB
如果没有GitHub,可以使用微信登录。
1、搭建前准备
打开Cloud Studio平台,进入个人页面。
点击Cloud Studio官网 Cloud Studio_在线编程_在线IDE_WebIDE_CloudIDE
现在实名认证的话每月会赠送 1000 分钟免费额度。

2、选择环境
选择环境模板
Cloud Studio内置 Node.js、Java、Python 等常见环境,这里我们需要选择一个Python模板


3、开始代码环节
3.1、配置运行环境
打开终端
分别执行以下命令下载依赖包
pip install openpyxl
pip install numpy
pip install pandas
pip install matplotlib

3.2、创建 数据爬取.py

运行如下代码
import requests
from openpyxl import Workbook
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
# 将数据转换为json格式
def getTypeJson(url):
# 发送请求
response = requests.get(url, headers=headers)
# 返回json格式数据
return response.json()
# 获得数据信息
def getInformation(url, ws, name):
# 获取json格式的data数据
data = getTypeJson(url).get("data")
# 获取klines数据
klines = data.get("klines")
for kline in klines:
# 将kline的起始位置加上name字段
kline = name + "," + kline
# 将kline用,切割并保存一行
ws.append(kline.split(","))
# 保存数据
def saveInformationToXlsx():
wb = Workbook()
# 打开第一个表格
ws = wb.worksheets[0]
# 添加第一行数据
ws.append(["名称", "时间", "开盘", "收盘", "最高", "最低", "成交量", "成交额", "振幅", "涨跌幅", "涨跌额", "换手率"])
# 爬取五粮液数据
url = f"http://push2his.eastmoney.com/api/qt/stock/kline/get?fields1=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f11,f12,f13&fields2=f51,f52,f53,f54,f55,f56,f57,f58,f59,f60,f61&beg=20190101&end=20500101&ut=fa5fd1943c7b386f172d6893dbfba10b&rtntype=6&secid=1.600702&klt=101&fqt=1"
getInformation(url, ws, "五粮液")
# 爬取泸州老窖数据
url = f"http://push2his.eastmoney.com/api/qt/stock/kline/get?fields1=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f11,f12,f13&fields2=f51,f52,f53,f54,f55,f56,f57,f58,f59,f60,f61&beg=20190101&end=20500101&ut=fa5fd1943c7b386f172d6893dbfba10b&rtntype=6&secid=0.000568&klt=101&fqt=1"
getInformation(url, ws, "泸州老窖")
# 设置标题
ws.title = "五粮液和泸州老窖"
# 保存数据
wb.save("酿酒行业个股资金流.xlsx")
# 关闭资源
wb.close()
# 程序运行
if __name__ == '__main__':
saveInformationToXlsx()

酿酒行业个股资金流.xlsx 文件内容如下

爬取的数据来自东方财富:泸州老窖和五粮液
3.3、创建 数据分析.py

运行如下代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import random
def viewPlot(fileName):
# 防止中文乱码
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
# 进行数据处理
df = dataHandling(fileName)
viewPlot1(df)
viewPlot2(df)
viewPlot3(df)
# 对xlsx数据进行整理
def dataHandling(xlsxName):
# 读取excel文件
df = pd.read_excel(xlsxName, header=0)
# 对时间进行处理
df['年月'] = df['时间'].str[0:7]
df['时间'] = pd.to_datetime(df['时间'])
df['年'] = df['时间'].dt.year
df['月'] = df['时间'].dt.month
df['时间'] = df['时间'].dt.date
# 处理成交量(将单位从次变为万次)并保留两位小数
df['成交量'] = round(df['成交量'] / 10000, 2)
# 处理成交额(将单位从元变为亿元)并保留两位小数
df['成交额'] = round(df['成交额'] / 100000000, 2)
return df
# 画图
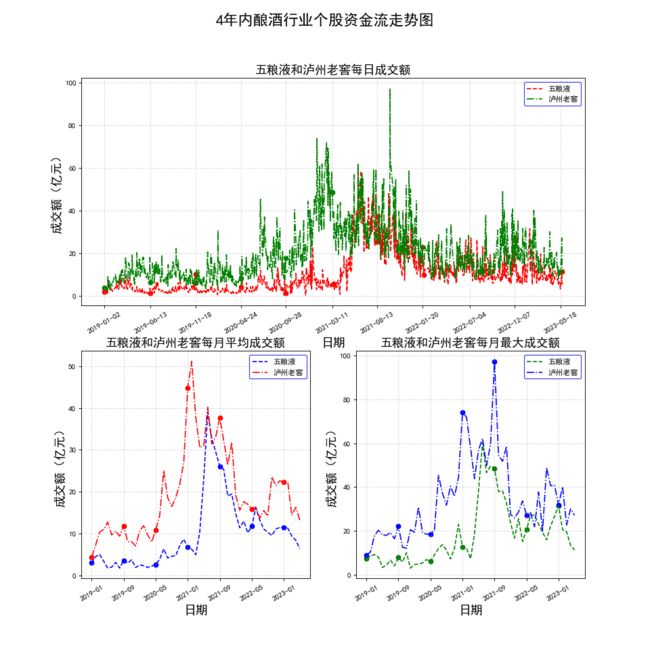
def viewPlot1(df):
# 创建画板
plt.figure(figsize=(12, 12), dpi=80)
# 设置标题
plt.suptitle("4年内酿酒行业个股资金流走势图", fontsize=20)
# 获取名称集合
nameList = df['名称'].unique()
# 绘制第一个子图
plt.subplot(2, 1, 1)
# 以键值对方式存储数据
dic = {}
for name in nameList:
# 获取数据
dic[name] = groupByDayData(df, name)
# 子图标题
title = nameList[0] + '和' + nameList[1] + "每日成交额"
drawSubPlot(dic, title, 10, "成交额(亿元)")
# 绘制第二个子图
plt.subplot(2, 2, 3)
# 以键值对方式存储数据
dic = {}
for name in nameList:
# 获取数据
dic[name] = groupByMonthData(df, name)
# 子图标题
title = nameList[0] + '和' + nameList[1] + "每月平均成交额"
drawSubPlot(dic, title, 6, "成交额(亿元)")
# 绘制第三个子图
plt.subplot(2, 2, 4)
# 以键值对方式存储数据
dic = {}
for name in nameList:
# 获取数据
dic[name] = groupByMonthMaxData(df, name)
# 子图标题
title = nameList[0] + '和' + nameList[1] + "每月最大成交额"
drawSubPlot(dic, title, 6, "成交额(亿元)")
# 存图
plt.savefig('./plot1.png')
# 展示图片
plt.show()
# 封装数据并返回
def getData(group):
# 获取x轴数据
x = group.index
# 获取y轴数据
y = group.values
# 将数据封装为list集合并返回
data = [x, y]
return data
# 按名称和时间分组获取每天成交额
def groupByDayData(df, name):
groupByDay = df.groupby("名称").get_group(name).groupby(['时间'])['成交额'].mean()
return getData(groupByDay)
# 根据名称和年月分组获取每月成交额的平均值
def groupByMonthData(df, name):
groupByMonth = df.groupby("名称").get_group(name).groupby(['年月'])['成交额'].mean()
return getData(groupByMonth)
# 根据名称和年月分组获取每月最大成交额数据
def groupByMonthMaxData(df, name):
groupByMonth = df.groupby("名称").get_group(name).groupby(['年月'])['成交额'].max()
return getData(groupByMonth)
# 折线颜色集合
colors = ['red', 'green', 'blue']
# 折线样式集合
line_style = ['-', '--', '-.']
# 子图绘制dic:数据,title:子图标题,step:x轴显示数据的数量,yTitle:y轴单位
def drawSubPlot(dic, title, step, yTitle):
# 随机生成颜色下标
c = random.randint(0, len(colors) - 1)
# 随机生成样式下标
l = random.randint(0, len(line_style) - 1)
i = 0
# 遍历dic
for name, data in dic.items():
# 折线颜色选取
c = (c + i) % len(colors)
# 折线样式选取
l = (l + i) % len(line_style)
# 为了使第二条线和第一条线不相等
i = i + 1
# 将数据代入x轴和y轴
putData(name, data, step, c, l)
# 设置x轴名称
plt.xlabel("日期", fontdict={'size': 16})
# 设置y轴名称
plt.ylabel(yTitle, fontdict={'size': 16}, rotation=90)
# 设置网格
plt.grid(True, linestyle='--', alpha=0.5)
# 设置子图标题
plt.title(title, fontdict={'size': 16})
# 将数据加载到子图中
def putData(name, data, step, c, l):
# x轴数据
x = data[0]
# y轴数据
y = data[1]
# 将x轴和y轴数据代入并设置颜色折线类型和折线名
plt.plot(x, y, c=colors[c], label=name, linestyle=line_style[l])
# 设置折线上的点
plt.scatter(x[::int(len(x) / step)], y[::int(len(x) / step)], c=colors[c])
# 设置图例边框
plt.legend(loc='best', edgecolor='blue')
# 设置x轴数据
plt.xticks(x[::int(len(x) / step)], rotation=30)
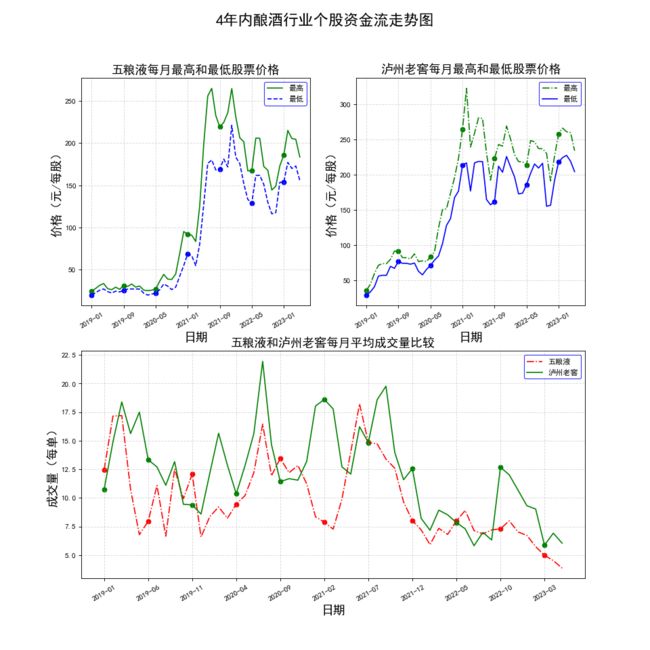
def viewPlot2(df):
# 创建画板
plt.figure(figsize=(12, 12), dpi=80)
# 设置标题
plt.suptitle("4年内酿酒行业个股资金流走势图", fontsize=20)
# 获取名称集合
nameList = df['名称'].unique()
# 绘制第一个子图
plt.subplot(2, 2, 1)
# 以键值对方式存储数据
dic = {}
for name in nameList:
# 获取数据
dic[name] = getMaxAndMinDataByName(df, name)
# 子图标题
title = nameList[0] + "每月最高和最低股票价格"
drawSubPlot(dic[nameList[0]], title, 6, "价格(元/每股)")
# 绘制第二个子图
plt.subplot(2, 2, 2)
# 子图标题
title = nameList[1] + "每月最高和最低股票价格"
drawSubPlot(dic[nameList[1]], title, 6, "价格(元/每股)")
# 绘制第三个子图
plt.subplot(2, 1, 2)
# 以键值对方式存储数据
dic = {}
for name in nameList:
# 获取数据
dic[name] = getMeanDataByName(df, name)
# 子图标题
title = nameList[0] + "和" + nameList[1] + "每月平均成交量比较"
drawSubPlot(dic, title, 10, "成交量(每单)")
# 存图
plt.savefig('./plot2.png')
plt.show()
# 通过名称和年月获取每月最高和最低股票价格数据
def getMaxAndMinDataByName(df, name):
# 保存数据
dic = {}
# 通过名称和年月分组
groupByNameAndMonth = df.groupby("名称").get_group(name).groupby(['年月'])
# 获得每月最大数据
getMax = groupByNameAndMonth['最高'].max()
dic['最高'] = getData(getMax)
# 获得每月最小数据
getMin = groupByNameAndMonth['最低'].min()
dic['最低'] = getData(getMin)
# 返回数据
return dic
# 按名称和年月分组获取每月成交量的平均值
def getMeanDataByName(df, name):
groupByMonth = df.groupby("名称").get_group(name).groupby(['年月'])['成交量'].mean()
return getData(groupByMonth)
# 通过名称和年分组获得每年成交额的平均值
def getInformation(df, nameList):
# 根据名称分组
groupByName = df.groupby("名称")
# 根据年分组获取平均值
groupByYear = groupByName.get_group(nameList[0]).groupby(['年'])['成交额'].mean()
# 将平均值保留两位小数
groupByYear = round(groupByYear, 2)
# 获取x轴数据
x = groupByYear.index
# 获取第一组y轴数据
y1 = groupByYear.values
# 根据年分组获取平均值
groupByYear = groupByName.get_group(nameList[1]).groupby(['年'])['成交额'].mean()
# 将平均值保留两位小数
groupByYear = round(groupByYear, 2)
# 获取第二组y轴数据
y2 = groupByYear.values
# 封装数据并返回
data = [x, y1, y2]
return data
# 柱状图
def viewPlot3(df):
# 获取不同名称集合
nameList = df['名称'].unique()
# 获取数据
information = getInformation(df, nameList)
xData = information[0]
y1 = information[1]
y2 = information[2]
# 设置画板
plt.figure(figsize=(10, 8))
# 条形宽度
width = 0.2
# 生成1到len(xData)的数组
x = np.arange(len(xData))
# 画第一组数据,在x位置画y1的值
pa = plt.bar(x, y1, width=width, label=nameList[0], fc="r")
# 画第一组数据,在 x + width 位置画y2的值
pb = plt.bar(x + width, y2, width=width, label=nameList[1], fc="g")
# 在柱上标数字
autoLabel(pa)
autoLabel(pb)
# 原来这里是刻度值,现在把x轴标题替换为横坐标显示
plt.xticks(x + width / 2, xData)
plt.title(nameList[0] + "和" + nameList[1] + "每年平均成交额对比", fontdict={'size': 20})
# 设置图例边框
plt.legend(loc='best', edgecolor='blue')
# 设置轴名
plt.xlabel('时间', fontdict={'size': 16})
plt.ylabel('成交额(亿元)', fontdict={'size': 16}, rotation=90)
# 存图
plt.savefig('./plot3.png')
plt.show()
# 在柱上显示代表的数量
def autoLabel(rects):
# 遍历所有矩形
for rect in rects:
# 获得矩形高度
height = rect.get_height()
print(type(height))
# 将数据标到柱顶
plt.text(rect.get_x() + rect.get_width() * 0.10, 1.01 * height, height)
# 运行程序
if __name__ == '__main__':
# 读取数据的文件名
filename = r"酿酒行业个股资金流.xlsx"
# 画图方法
viewPlot(filename)
如报 findfont: Generic family ‘sans-serif’ not found because none of the following families were found: SimHei
参考该博客解决:https://blog.csdn.net/ben_na_/article/details/124238611
生成如下三张图

使用感想
Cloud Studio 可以在云端运行代码,帮我们节省了在本地安装和配置软件的成本。
通过我的使用 Cloud Studio 的环境支持功能非常强大,几乎不需要额外配置。
总之,Cloud Studio 操作简单、功能强大,希望这个产品能够越做越好。