数据结构零基础入门篇(C语言实现)
前言:数据结构属于C++学习中较难的一部分,对应学习者的要求较高,如基础不扎实,建议着重学习C语言中的指针和结构体,万丈高楼平地起。
一,链表
1)单链表的大致结构实现
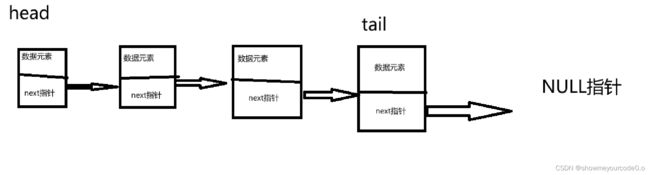
用C语言实现链表一般是使用结构体,首先我们可以通过链表的结构特性反推结构体的成员。单链表是只能通过前一个节点找到下一个节点,并且是单向的,每一个节点还要存储数据元素,我们实现这个的手段是指针,因此我们需要在前一个结点存储下一个地址。
typedef int SLTDateType;//方便以后修改链表类型
typedef struct STLListNode {
SLTDateType n;
struct STLListNode* next;
}SListNode;//减少代码的冗余2)单链表的思考(然后找到链表和判断链表的结束)
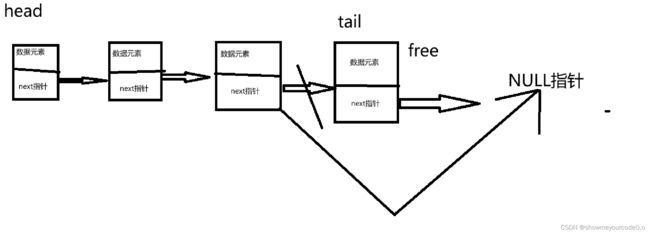
首先是如何找到链表的第一个元素,每次,我们之前的图上给了提示,我们可以用一个head指针来标记第一个结点,但有一个很大的注意事项,我们不能随便改变head的地址,不然我们将会无法找到这个链表。
那如何判断链表的结束呢,看上面的手绘图,最后一个结点所指向的是NULL指针,根据这个特点我们就可以判断链表的结束。
注:我们为什么要考虑这两个问题是因为如果我们不严格的控制指针的指向,当指针指向为开辟的空间,会导致程序出现各种意外甚至无法运行。
3)单链表的程序实现及源代码讲解
1)链表的实现前提准备
#include
#include
typedef int SLTDateType;//方便以后修改链表类型
typedef struct STLListNode {
SLTDateType n;
struct STLListNode* next;
}SListNode;//减少代码的冗余 2)单链表的创建及初始化
SListNode* BuySListNode(SLTDateType x);
SListNode* BuySListNode(SLTDateType x) {
SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));//分配内存空间
assert(newnode);//防止分配失败导致的访问非法空间
newnode->n= x;
return newnode;//返回创建空间地址
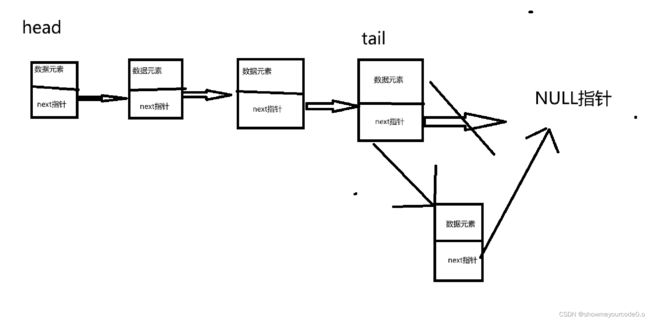
}3)单链表的尾插
void SListPushBack(SListNode** pplist, SLTDateType x);
void SListPushBack(SListNode** pplist, SLTDateType x) {//链表要传地址用二级指针接受,因为头插的时候是要改变链表的地址,是需要二级指针才能改变一级指针
SListNode* ptemp = *pplist;
SListNode** plist = pplist;//防止头指针丢失
if (*plist == NULL) {
*plist = BuySListNode(x);
(*plist)->next = NULL;
return;
}//如果是空链表需要单独处理
while ((*plist)->next != NULL) {
*plist = (*plist)->next;
}//找到尾节点
(*plist)->next = BuySListNode(x);//分配一个新空间
(*plist)->next->next = NULL;//置空方便下次找尾结点
*pplist = ptemp;//维持头指针
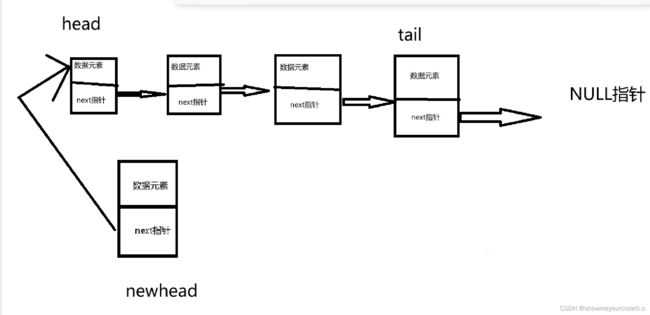
}4)单链表的头插
void SListPushFront(SListNode** pplist, SLTDateType x) {//要改变头指针的地址,需要二级指针
if (*pplist == NULL) {
*pplist = BuySListNode(x);
(*pplist)->next = NULL;
return;//如果链表为空,单独处理
}
SListNode* plist= BuySListNode(x);//分配空间
plist->next = (*pplist);//将新结点的next指针指向原来的头指针
*pplist = plist;//改变头指针
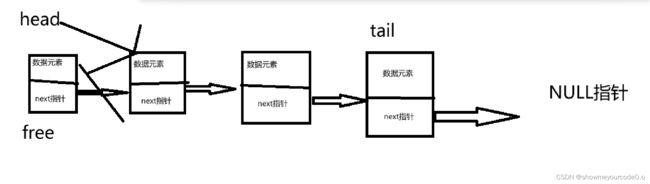
}5)单链表的头删
void SListPopFront(SListNode** pplist){
assert(*pplist);//判断是否为空链表,防止访问非法空间
SListNode* plist = *pplist;
*pplist = (*pplist)->next;//保留新头
plist->next = NULL;//老的头指针置空,防止通过这个非法访问
free(plist);//释放老头指针空间
}6)单链表的尾删
void SListPopBack(SListNode** pplist) {
assert(*pplist);//判断是否为空链表,防止访问非法空间
SListNode* plist = (*pplist);//保存头指针,防止丢失
if (plist->next == NULL) {
free(plist);
plist = NULL;
}//如果只有一个元素,直接释放
while (plist->next->next != NULL) {
plist = plist->next;
}//找到尾结点
free(plist->next);
plist->next = NULL;//置空
}7)在单链表中查找元素
SListNode* SListFind(SListNode* plist, SLTDateType x) {
assert(plist);//判断是否为空链表,防止访问非法空间
while (plist->next != NULL) {
if (plist->n = x)
return plist;//如果找到直接返回地址
plist = plist->next;//否则下一个
}
return NULL;//找到了尾结点都没找到,返回空指针
}8)单链表指定结点的后面插入和删除元素
void SListInsertAfter(SListNode* pos, SLTDateType x) {
assert(pos);//判断是否为空链表,防止访问非法空间
SListNode* temp = pos->next;
pos->next = BuySListNode(x);
pos->next->next = temp;
}
void SListEraseAfter(SListNode* pos) {
assert(pos);//判断是否为空链表,防止访问非法空间
assert(pos->next );//判断是否有下一个元素
SListNode* temp = pos->next;
pos->next = pos->next->next;//改变前一个指针的next指针,防止断层
free(temp);
}9)单链表的内存销毁
void SListDestroy(SListNode* plist) {
assert(plist);//防止多次释放空间
SListNode* cur = plist->next;//记录当前指针,因为当前指针释放后无法访问到下一个指针的地址
while (cur) {
free(plist);
plist = cur;
cur = plist->next;
}
plist = NULL;
}2)带头双向循环链表的提示(自己实现)
与单链表相比,带头双向循环链表,会有多开辟一个空间,不用来存储数据,用来指向head指针,这样可以简化许多操作。还要多一个指针指向前一个结点,并且尾指针不在置空,而且指向第一个结点。
二,队列和栈
1)队列特性
就像如图的核酸检测,你先进入队列,你就能比别人先做完核酸离开。因此队列的特性是先进先出。
2)栈的特性
栈的特性就像往一个一次只能拿出一个石头的瓶子里面投石头,你想要拿到最下面的石头你就需要先拿出前面所有的石头,因此栈的特性就是先进后出。
3)队列用链表实现(源代码及详细讲解)
1)队列结构和功能实现前准备
和链表一样,我们队列也使用结构体指针的方法实现,与链表实现大同小异,但会有一个另外的结构体用来存储队列的第一个元素指针的地址,和最后一个元素指针的地址,这样方便我们接下来的各个功能实现,可以省下很多代码量。
#include
#include
typedef int QDataType;//方便以后将队列修改为其他类型
typedef struct QListNode
{
struct QListNode* _next;//下一个队列的指针
QDataType _data;//数据元素
}QNode;//减少代码长度
typedef struct Queue
{
QNode* _front;//队列第一个元素指针
QNode* _rear;//队列最后一个元素指针
}Queue; 2)初始化队列
void QueueInit(Queue* q) {
q->_front = (QNode*)malloc(sizeof(QNode));//开辟空间
q->_front->_data = -1;//数据随意初始化
q->_rear = q->_front ;//此时只有一个元素,头和尾相等
}3)入列数据
void QueuePush(Queue* q, QDataType data) {
q->_rear->_data = data;//从尾开始入列
q->_rear->_next = (QNode*)malloc(sizeof(QNode));//给下一个队列分配空间
q->_rear = q->_rear->_next;//移动尾指针
}4)出列数据
void QueuePop(Queue* q) {
assert(q->_front!=q->_rear );//防止出列空队列
QNode* list = q->_front ;//保存头指针,防止丢失
while (list->_next != q->_rear) {
list = list->_next;
}//找到尾指针
free(q->_rear);//释放尾指针
q->_rear = list;//重新恢复尾指针
}5)获取队列头部元素
QDataType QueueFront(Queue* q) {
assert(q->_front != q->_rear);
return q->_front->_data;
}6)获取队列尾部元素
QDataType QueueBack(Queue* q) {
assert(q->_front != q->_rear);//判断是否有至少两个元素,防止数组越界
QNode* list = q->_front;//保存头指针,防止丢失
while (list->_next != q->_rear) {
list = list->_next;
}//找到尾结点,队列最后一个元素指针
return list->_data;
}7)销毁队列元素
void QueueDestroy(Queue* q) {
while (q->_front != q->_rear) {
QNode* list = q->_front;//利用list来销毁上一个指针,防止销毁之后找不到下一个元素
q->_front = q->_front->_next;//头指针换为下一个元素
free(list);//销毁
}
free(q->_rear);//不要忘记还落下了一个尾结点
q->_front = NULL;
q->_rear = NULL;//置空,防止非法访问
}4)栈的代码实现(提供另外一种思路,自己实现)
之前说过栈就像往一次只够拿一个石头的瓶子里放石头和取石头,有没有发现栈和数组有很大的相似,当我们打开这个思路,我们会发现如果用数组实现的话,我们的代码思路和代码量突然就小了很多。我这里只提供结构和功能实现前的准备,其他望诸君自己勤练。
#include
#include
// 支持动态增长的栈
typedef int STDataType;
typedef struct Stack
{
STDataType* _a; //到时候用maolloc开辟空间,可以随时调节数组大小
int _top; // 栈顶
int _capacity; // 容量
}Stack; 最后言:数据结构是需要大量题目来练手的,单纯的理论知识是纸上谈兵,真正实现的时候是变化万千。牢记:纸上得来终觉浅,绝知此事要躬行。