Python学习笔记·
一、Python简介
Python:Guido(龟叔)发明的,丹麦的。

Python解释器,和java虚拟机差不多。
人生苦短,我用Python。
Python:蟒蛇,源于作者喜欢的一部电视剧
import this:查看Python之禅
优点:简单,易学,免费,开源,高层语言,可移植性,面向对象,可扩展性(可以在中间用C或C++编写),丰富的库
缺点:运行速度慢,国内市场小,中文资料匮乏,框架选择太多。
应用:
- web应用开发
- 操作系统管理,服务器运维的自动化脚本
- 科学计算
- 桌面软件:PyQt、PySide、wxPython、PyGTK是Python开发桌面应用程序的利器
- 服务器软件(网络软件)
- 游戏
二、Python基础知识
2.1注释:多行注释:'''........ ''',"""……."""。
2.2Python2中不能有中文,解决方法:在第一行加上
#coding=utf-8或者
#-*- coding:utf-8 -*-(Python官方推荐)
2.3定义变量:直接写变量名,money=3 不需要说明类型。
2.4输入与输出
输入input:
height=input(“请输入你的升高:”)input输入的默认是字符串类型,type(a),查看变量类型
输出print
使用print同时输出两个变量:
age=24
age2=25
print("age=%d,age2=%d"%(age,age2))print("")默认自动换行,print("\n")会换两行。
print("",end=""),就不换行了。
整型%d,字符串%s,和C一样。
2.5Python2和Python3区别
input时候的区别
#Python3中控制行测试
a=input("请输入你的名字")
请输入你的名字>? 1+4
a
Out[3]: '1+4'
Python3中输入1+4,它会当成字符串,不会进行运算a="1+4"
Python2中输入1+4,它会进行计算,a=5
2.6Python基本数据类型

2.7if....else
age=input("pleat input your age:")#默认input是str类型
age_num=int(age)#转换为int类型,注意和C语言中区别
if age_num>18:#if后面一般不带括号,if后面的冒号
print("可以去网吧了")
else:#注意else后面也有冒号
print("回家写作业吧")
if...elif
sex = input("请输入你的性别:")
if sex=="男":
print("你是男性")
elif sex=="女":
print("你是女性")
elif sex=="中":#elif后面不一定要else,语法上是对的
print("你是中性")
C语言中也是一样。但是总觉得elif后面不更上else感觉很别扭,少了点什么。
if...if,if嵌套
ticket=1#1表示有车票,0表示没有车票
knifelength=18#cm
if ticket==1:
print("通过了车票的检查")
if knifelength<=10:
print("通过了安检,进入了候车厅")
else:
print("没有通过安检")
else:
print("兄弟,你还没买票了。")
if里面一般只嵌套一个if,太多了程序就差劲。
2.8变量命名规则
和C中一样
2.9关键字
查看Python中关键字
import keyword
keyword.kwlist| 关键字 | 含义 |
|---|---|
False |
布尔类型的值,表示假,与 True 相反 |
None |
None 比较特殊,表示什么也没有,它有自己的数据类型 - NoneType。 |
True |
布尔类型的值,表示真,与 False 相反 |
and |
用于表达式运算,逻辑与操作 |
as |
用于类型转换 |
assert |
断言,用于判断变量或者条件表达式的值是否为真 |
break |
中断循环语句的执行 |
class |
用于定义类 |
continue |
跳出本次循环,继续执行下一次循环 |
def |
用于定义函数或方法 |
del |
删除变量或序列的值 |
elif |
条件语句,与 if、else 结合使用 |
else |
条件语句,与 if、elif 结合使用。也可用于异常和循环语句 |
except |
except 包含捕获异常后的操作代码块,与 try、finally 结合使用 |
finally |
用于异常语句,出现异常后,始终要执行 finally 包含的代码块。与 try、except 结合使用 |
for |
for 循环语句 |
from |
用于导入模块,与 import 结合使用 |
global |
定义全局变量 |
if |
条件语句,与 else、elif 结合使用 |
import |
用于导入模块,与 from 结合使用 |
in |
判断变量是否在序列中 |
is |
判断变量是否为某个类的实例 |
lambda |
定义匿名函数 |
nonlocal |
用于标识外部作用域的变量 |
not |
用于表达式运算,逻辑非操作 |
or |
用于表达式运算,逻辑或操作 |
pass |
空的类、方法或函数的占位符 |
raise |
异常抛出操作 |
return |
用于从函数返回计算结果 |
try |
try 包含可能会出现异常的语句,与 except、finally 结合使用 |
while |
while 循环语句 |
with |
简化 Python 的语句 |
yield |
用于从函数依次返回值 |
2.10运算符
a=5
b=2
a/b#2.5
a//b#2
2**10=1024#乘方
“H”*10=“HHHHHHHHHH”#乘以10次
三、流程控制
3.1逻辑运算符
3.1.1and,or
if..else中注意缩进问题。
age=int(input("请输入你的年龄:"))
if (age>0) and (age<120):
print("是正常年龄")
else:
print("不是正常年龄")
#Python中不能随意缩进,否则会报unexpected indent错误。3.1.2not
相当于C中的!
3.2while循环
Python中没有do..while,也没有switch。
i=1
while i<=10:#Python中不喜欢加括号,就不加吧。
print(i)
i=i+1while...while
#九九乘法表专用
i=1
while(i<=9):
j=1
while(j<=i):
print("%d*%d=%d\t"%(j,i,i*j),end="")#\t,久久乘法表专用
j+=1
print("")
i+=13.3for循环
name = "laowang"
for temp in name:
print(temp,end="")3.4break,continue
和C中一样
3.5随机数
import random
random.randint(0,2)#生成0,1,2的随机整数3.6复合运算符
i+=1, Python中没有i++,++i。
四、常见数据类型
4.1字符串
- 转换为字符串类型:str(x)
- 求字符串长度:len(x)
- 求字符的Unicode编码:ord()
- 给定Unicode字符编码,使用函数chr()来获取对应的字符
ord('a')
97
chr(97)
'a'
ord('黄')
40644
chr(40644)
'黄'name="laowang"
len(name)=7#不算\0- 字符串的连接:“+”,格式化
a = "lao"
b = "wang"
#第一种连接方式
c = a +b #c="laowang"
#第二种连接方式
d = "===%s==="%(a+b) #和格式化输出一样
print(c)
print(d)- 字符串中的下标,用中括号[ ]表示,
name=“laowang”
name[0]#l
name[-1]#g,从后往前取
name[-2]#n,倒数第二个
name[len(name)-1]#太麻烦- 字符串切片name[start:end],name[start:end:step]
包括start,不包括end,注意步长在最后
name="laowang"
name[0:2]#la
name[0:-1]#laowan
name[1:]#取到最后,包括最后,aowang
name[0:-1:2]#loa,步长为2
#逆序
name[-1::-1]#从-1开始,向左取,步长为-1
name[::-1]#逆序,-1可以省略
#正序
name[::]
- 字符串常见操作
dir('')查看字符串自带的操作函数,dir(任意一个字符串)
dir('')
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
| find | 查找字符串中是否有指定的字符串,如果有返回第一个找到的字符串的首字母下标,否则返回-1 |
| rfind | 从右向前找,功能同find,用于获取文件后缀名 |
| index | 查找到时find,查找不到时出现异常 |
| rindex | 从右向前找,功能同index |
| count | 统计子字符串出现的个数 eg:name="aaaa" name.count("aa") #2 |
| replace | replace("str1","str2",n),把str1替换成str2,n为替换的次数,n省略时,默认全部替换。产生一个新字符串,原字符串不变 |
| split | 切割字符串。作用:按照空格切割,统计单词个数 |
| capitalize | 首字母大写 |
| title | 字符串中每个单词的首字母都大写 |
| lower | 所有字母转换为小写。作用:用户输入yes,YES,Yes时候,同意转换为yes,进行判断 |
| upper | 所有小写字母转换为大写 |
| swapcase | 将小写字母转换为大写字母,大写字母转换为小写字母 |
| startwith | startwith("obj"),判断字符串是否以"obj"开头,name=“wang XXXX” 判断是不是以“王”姓开头 |
| endwith | endwith("obj"),判断文件格式时候用的多。file_name="xxxx.txt" file_name.endwith(".txt")#True |
| center(n,ch) | 居中对齐,n为总长度,两边用ch填充,默认填充空格 |
| ljust(n,ch) | 左对齐 |
| rjust(n,ch) | 右对齐 |
| strip |
删除字符串两边空字符串 |
| lstrip | 删除字符串左边空字符串 |
| rstrip | 删除字符串右边空字符串 |
| partition | partition("obj"),按照obj进行分割,返回分割后的元组。从左向右,找到第一个截止 |
| rpartition | 从右向左,功能同上 |
| splitlines | 按照换行符分割,返回列表 |
| isalpha | 判断字符串是不是都是字母 |
| isdigit | 判断字符串是不是都是数字 |
| isalnum | 判断字符串是不是都是由字母和数字组成的。作用:网站注册账号时,只能是字母和数字 |
| isspace | 判断是不是都是空格 |
| join | join(str),将序列中的元素以指定的字符连接生成一个新的字符串。 |
| format |
#rfind获取文件后缀名
def get_extension(filename):
dot = filename.rfind('.')
if dot==-1:
return ''
else:
return filename[dot+1:]
print(get_extension("hello.txt"))#txt#split
mystr="lao wang ni hao a "
mystr.split(" ")
Out[43]: ['lao', 'wang', 'ni', 'hao', 'a', '']
#partition
mystr="lao wang ni hao a lao wang"
mystr.partition("wang")
Out[47]: ('lao ', 'wang', ' ni hao a lao wang')
#splitlines
test="hello\nworld"
test.splitlines()
Out[49]: ['hello', 'world']
#join
a=["aaa","bbb","ccc"]
b=" "
b.join(a)
Out[52]: 'aaa bbb ccc'
#isdigit()
a = "df"
a.isdigit()
Out[55]: False
列表连接成字符串
a = ["h","u","a","n","g"]
"".join(a)
Out[20]: 'huang'
面试题:
#删除字符串中的空格以及\t
a="lao wang \t ni hao \t laowang"
result = a.split()
b = "".join(result)
print(b)
格式化字符串:
format%value形式,值是以元素的方式存储的
a,b=1,2
print("a=%d,b=%d"%(a,b))
a=1,b=2
print("a=%e"%(a))
a=1.000000e+00
使用format
按位置替换
命名替换
#format
'{0} likes {1}'.format('jack','ice cream')
'jack likes ice cream'
print('{0} likes {1}'.format('jack','ice ceram'))
jack likes ice ceram
print('{who} like {pet}'.format(who='jack',pet='ice cream'))
jack like ice cream"1/81={x}".format(x=1/81)
'1/81=0.012345679012345678'
"1/81={x:f}".format(x=1/81)
'1/81=0.012346'
"1/81={x:.3f}".format(x=1/81)
'1/81=0.012'
"1/81={x:.{d}f}".format(d=4,f=1/81)
"1/81={x:.{d}f}".format(d=4,x=1/81)
'1/81=0.0123'正则表达式
Python中正则表达式库:import re
用于复杂字符串处理,可以高效低执行常见的字符串处理任务,如匹配,分拆和替换。

4.2列表
和C不同,Python中列表可以包含不同类型
a=["d","Fsdf",111,3.24]
一般用来存储相同类型
#列表相加是列表合并
[100]+[100]
Out[62]: [100, 100]
遍历列表:
a = ["d","Fsdf",111,3.24]
for i in a:
print(i)
d
Fsdf
111
3.24一个列表元素指向列表本身:
snake=[1,2,3]
snake[1]=snake
snake
[1, [...], 3]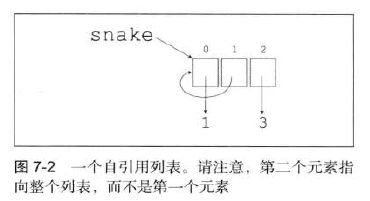
- 增
| append() |
追加,没有返回值 |
| insert() | 插入 |
| extend() | 延伸,合并两个列表 |
names=["老王","老李","老张"]
#追加
names.append("老赵")
names.append("悟空")
#插入
names.insert(0,"八戒")
names.insert(2,"沙僧")
print(names)
names2=["huangyang","yuanmei","zhonglingqian"]
#合并两个列表
names.extend(names2)#常用
result=names+names2#不常用,两个列表可以相加
print(names)
print(result)#append,extend小区别
a=[11,22,33,44]
b=[55,66]
a.extend(b)
a
Out[95]: [11, 22, 33, 44, 55, 66]
a.append(b)
a
Out[97]: [11, 22, 33, 44, 55, 66, [55, 66]]
a.extend(77)#报错,这里extend只能填可迭代的类型,不能直接添加一个数字。
a = [1,2,3]
a.extend('hello')
a
[1, 2, 3, 'h', 'e', 'l', 'l', 'o']
- 删
| pop(n) | 删除第n个元素,n为空时默认删除最后一个元素,返回删除的那个元素 |
| remove(x) | 根据内容删除,删除列表第一个x,没有返回值 |
| del xxx[index] | 根据下标删除,没有返回值 |
names=["老王","老李","老张","老王","huangyang","yuanmei","zhonglingqian"]
names.pop()
Out[54]: 'zhonglingqian'
names
Out[55]: ['老王', '老李', '老张', '老王', 'huangyang', 'yuanmei']
names.remove("老王")
names
Out[57]: ['老李', '老张', '老王', 'huangyang', 'yuanmei']
name.pop(2)
'老王'
name
['老李', '老张', 'huangyang', 'yuanmei']
del name[0]
name
['老张', 'huangyang', 'yuanmei']
列表切片还是列表
names=["老王","老李","老张","老王","huangyang","yuanmei","zhonglingqian"]
names[0:2]
Out[62]: ['老王', '老李']
- 改
直接改
names=["老王","老李","老张","老王","huangyang","yuanmei","zhonglingqian"]
names[0]="老刘"
names
Out[65]: ['老刘', '老李', '老张', '老王', 'huangyang', 'yuanmei', 'zhonglingqian']
列表反转:直接改变原列表的值
name
['老张', 'huangyang', 'yuanmei']
name.reverse()
name
['yuanmei', 'huangyang', '老张']列表排序:sort
a = [3,2,5,1,6]
a.sort()
a
[1, 2, 3, 5, 6]
a.sort(reverse=True)
a
[6, 5, 3, 2, 1]列表中元素为元组时排序:首选按元祖的第一个元素排序,如果第一个元素相同,则按第二个元素排序,依次类推。
a = [(1,2),(1,-2),(3,4),(2,3)]
a.sort()
a
[(1, -2), (1, 2), (2, 3), (3, 4)]查
| in | 在 if "老王" int names: |
| not in | 不在 if "老黄" not in names: |
names=["老王","老李","老张","老王","huangyang","yuanmei","zhonglingqian"]
if "老王" in names:
print("老王在")
老王在
if "老黄" not in names:
print("老黄不在")
老黄不在
#名字管理系统
#1.打印功能提示
print("="*50)
print(" 名字关系系统 ")
print("1:添加一个新的名字")
print("2:删除一个名字")
print("3:修改一个名字")
print("4:查询一个名字")
print("0:退出")
print("="*50)
names=[]
while True:
#2.获取用户输入的序号
num = int(input("请输入功能序号:"))
if num==1:
new_name=input("请输入名字:")
names.append(new_name)
elif num==2:
pass
elif num==3:
pass
elif num==4:
find_name=input("请输入你要查找的名字:")
if find_name in names:
print("有")
else:
print("没有此人")
elif num==0:
break
else:
print("你的输入有误,请重新输入:")列表解析
range(1,10)
Out[18]: range(1, 10)
Python3中range生成的不是列表,Python2中生成的是列表,避免了range占用大的内存。
a = [i for i in range(1,8)]
a
Out[20]: [1, 2, 3, 4, 5, 6, 7]
b = [1 for i in range(1,8)]
b
Out[22]: [1, 1, 1, 1, 1, 1, 1]
c = [i for i in range(10) if i %2 ==0]
c
Out[27]: [0, 2, 4, 6, 8]
d = [i for i in range(3) for j in range(2)]
d
Out[29]: [0, 0, 1, 1, 2, 2]
e = [(i,j) for i in range(3) for j in range(2)]
e
Out[31]: [(0, 0), (0, 1), (1, 0), (1, 1), (2, 0), (2, 1)]
a = [2,3,4,5]
b = [i if i%2==0 else 1 for i in a]#if在for前面的时候,必须紧跟着else
b
[2, 1, 4, 1]a = [2,3,4,5]
b = [i for i in a if i%2==0 else 1]#if在for后面的时候,后面不能跟着else
b#报错
a = 1
b = 2
c = a if a>b else b
c
2列表中元素首字母大写:
name = ['hy','hd','lc'];
newname = [i.capitalize() for i in name]
newname
['Hy', 'Hd', 'Lc']4.3字典
字典也称为关联数组、映射或散列表。
字典中的每个键都被转换为一个数字---散列值,这是使用专门设计的散列函数完成的。字典的值存储在一个底层列表中,并将其散列值用作索引。访问值时,把提供的键转换为散列值,再跳到列表的相应位置。

infor={"name":"班长","addr":"山东","age":18}
print("%s %d %s"%(infor["name"],infor["age"],infor["addr"]))
#名片管理系统
#1.打印功能提示
print("="*50)
print(" 名片管理系统 ")
print(" 1.添加一个新的名片:")
print("2.删除一个名片:")
print("3.修改一个名片")
print("4.查询一个名片")
print("5.显示所有的名片")
print("6.退出")
card_infor=[]
while True:
#获取用户的输入
num = int(input("请输入操作序号:"))
#根据用户的输入进行操作
if num==1:
new_name=input("请输入名字:")
new_qq=input("请输入qq:")
new_addr=input("请输入地址:")
#定义一个字典,用来存储新的名片
new_dic={}
new_dic["name"]=new_name
new_dic["qq"]=new_qq
new_dic["addr"]=new_addr
#将字典添加到列表中
card_infor.append(new_dic)
print(card_infor)
elif num==2:
pass
elif num==3:
pass
elif num==4:
find_name=input("请输入你要查找的名字:")
flag=0#0:没有找到,1:找到了
for card in card_infor:
if card["name"]==find_name:
flag=1
print("找到了")
break
if flag==0:
print("没有找到")
elif num==5:
print("姓名\tqq\t\t地址")#这里后面不知道为什么要加两个\t才能对齐
for card in card_infor:
print("%s\t%s\t%s"%(card["name"],card["qq"],card["addr"]))
elif num==6:
break
else:
print("你的输入有误,请从新输入:")增删查改
infor={"name":"laowang"}
infor["age"]=18#增加
infor["qq"]=231321
infor
Out[76]: {'age': 18, 'name': 'laowang', 'qq': 231321}
infor["qq"]=11111#没有就增加,有就修改
infor
Out[78]: {'age': 18, 'name': 'laowang', 'qq': 11111}
del infor["qq"]#删除,没有就报错
infor
Out[80]: {'age': 18, 'name': 'laowang'}
infor.get("qq")#查询,没有返回None
infor.get("age")#返回18
dic[key],key不存在时报错情况。
color
{'red': 0, 'green': 2, 'blue': 3, 'black': 1}
color['white']#没有会报错
Traceback (most recent call last):
File "", line 1, in
KeyError: 'white' pop()、popitem()、clear()
color
{'red': 4, 'green': 2, 'blue': 3}
color.pop('red')#删除对应的键值对,并返回对应的值。
4
color
{'green': 2, 'blue': 3}
color.popitem()#随机返回字典中的某个键值对
('blue', 3)
color.clear()#清空字典
color
{}遍历
dic={"name":"huang","age":18}
for key in dic.keys():
print(key)#列表
for value in dic.values():
print(value)#列表
for item in dic.items():
print(item)#元组
for a,b in dic.items():
print("key=%s,value=%s"%(a,b))
#拆包
a=(1,2)
b,c=a
a
Out[109]: (1, 2)
b
Out[110]: 1
对键的限制:
1.字典中的键必须是独一无二的,即在同一个字典中,任何两个键值对的键都不能相同;使用了多次相同的键时,Python值存储最后的键值对。
color = {'red':1,'green':2,'blue':3,'red':4}
color
{'red': 4, 'green': 2, 'blue': 3}2.键必须是不可变的。因此键不能是列表,也不能是字典。
dict_keys
a = ['name', 'age', 'gender']
b = a.keys()
b
dict_keys(['name', 'age', 'gender'])
type(b)
isinstance(b,Iterable)
True
isinstance(b,Iterator)
False
b[0]
Traceback (most recent call last):
File "", line 1, in
TypeError: 'dict_keys' object does not support indexing
list(b)
['name', 'age', 'gender'] python3中dict.keys是一个 dict_keys类,是可迭代对象,不是迭代器,不是列表,不能被所以,可以使用list转换为列表。
4.4while,for循环遍历列表
#for,简单
nums=[11,22,33,44,55]
for num in nums:
print(num)#while,麻烦
nums=[11,22,33,44,55]
nums_length=len(nums)
i=0
while i < nums_length:
print(nums[i])
i+=14.5for...else
for中break只要终止了for,else也一并跳过,不执行。
nums=[11,22,33,44]
for num in nums:
print(num)
else: # else在for循环执行完之后才执行,如果for循环里面有break,导致for循环没有执行完,else就不执行。
print("====")#此行执行nums=[11,22,33,44]
for num in nums:
print(num)
if num==22:
break
else: # else在for循环执行完之后才执行,如果for循环里面有break,导致for循环没有执行完,else就不执行。
print("====") #只输出11,22。此行不执行for i in range(5):
print(i)
if i == 4:
break
else:
print(100)#1,2,3,4
4.6元组
与列表类似,元组的元素不能修改,元组使用小括号
num=(11,22,33)
type(num)
Out[10]: tuple
与字符串一样,也可以用+和*来拼接元祖:
tup1 = (1,2,3)
tup2 = (4,5,6)
tup1+tup2
(1, 2, 3, 4, 5, 6)
tup1*2
(1, 2, 3, 1, 2, 3)
tup1.index(2)
1
4.7集合
集合是一系列不重复的元素,集合分两类:可变集合和不可变集合。对于可变集合,你可以删除和添加元素,而不可变集合一旦创建就不能修改。
集合最常见用途是用于删除序列中重复元素:
a = [1,2,3,2,1]
set(a)
{1, 2, 3}五、函数
5.1定义函数
在文件中,可以在任意位置定义函数,但是一般都在开始定义函数,否则会被打的。
#定义函数
def print_menu():
print("menu")
print_menu()注意格式,def,后面有冒号,函数体要缩进。
#定义带有参数的函数:计算两个数的和
def sum(a,b):
return a+b
print(sum(1,2))#返回多个参数时
def test():
a = 11
b = 12
c = 13
#return [a,b,c]#第一种
#return (a,b,c)#第二种
return a,b,c#第三种,其实和第二种一样。返回(a,b,c) a = test() a,b,c=test()#两种接收方法都可以
#不能直接定义空函数,最少也得有个pass。
def test():
pass
def test(): #只有这个会报错。
5.2局部变量与全局变量
局部变量:函数内定义的,局部变量会屏蔽全局变量
全局变量:函数外定义的
#全局变量
def fun():
print("a=%d"%a)
a=100
fun() #100#局部变量与全局变量,函数内修改全局变量值注意点。
wendu = 0
def get_wendu():
#wendu = 33 #如果wendu这个变量已经在全局变量的位置定义了,这里wendu=33,有歧义,可以理解为修改全局wendu的值,也可以理解为定义一个局部变量wendu,
# 所以为了消除这种歧义,Python中这里表示定义了一个局部变量。如果要修改全局变量的值,使用下面的方法。
global wendu #要表示使用的是全局变量需要这样写
wendu = 33
a = 1
wendu = 40 #后面的wendu都是全局变量温度
def print_wendu():
print("temperature is %d"%wendu)
get_wendu()
print_wendu()#40
- 全局变量定义位置说明
#全局变量定义位置说明
a = 100#可以
def test():
print("a=%d"%a)
print("b=%d"%b)
print("c=%d"%c)
b = 200#可以
test()
c=300#不可以,定义得放在函数调用之前。编程时:先全局变量定义,再函数定义,把全局变量定义放到函数定义前面。
- 函数文档说明
#函数文档说明
def print_haha():
"""这个函数的目的是print出haha"""
print("haha")
print_haha()
#help(print_haha)按引用传递
向函数传递参数的时候,Python采用按引用传递的方式,不支持按值传递。
def add(a,b):
return a+b
x,y = 3,4
add(x,y)#7
函数中无法改变实参的值
def set(x):
x=1
m = 5
set(m)
m
55.3缺省参数
函数的形参有一个默认值,带有默认值的参数一定要位于参数列表的最后面,可以有多个。
#缺省参数
def test(a,b=22,c=33):#缺省参数
print(a)
print(b)
print(c)
test(11,22,c=44)位置实参
关键字实参:只放放在位置实参后面
- 不定长参数
#不定长参数,求任意个数的和
def sum(a,b,*args):#最后一个参数写成*args的格式,多余的元素存在args中,args是一个元素,如果没哟多余的元素,args就是空元组
print(a)
print(b)
print(args)
result = a +b
for num in args:
result += num
print(result)
sum(1,2,3,4,5)#缺省实参与不定长实参
def test(a,b,c=33,*args): #缺省形参会被赋予值
print(a)
print(b)
print(c)
print(args)
test(1,2,3,4,5)#1,2,3,(4,5)#完整的不定长参数
def test(a,b,c=33,*args,**kwargs):#args保存多余的没有变量名的变量,kwargs保存有名字的变量,以字典格式.
print(a)#1
print(b)#2
print(c)#3
print(args)#(4,5)
print(kwargs)#{'task': 99, 'done': 89}
test(1,2,3,4,5,task=99,done=89)#1,2,3,(4,5),{'task': 99, 'done': 89}
- 拆包
#拆包
def test(a,b,c=33,*args,**kwargs):#args保存多余的没有变量名的变量,kwargs保存有名字的变量,以字典格式.
print(a)#1
print(b)#2
print(c)#3
print(args)#(((4, 5, 6), {'name': 'laowang', 'age': 18})
print(kwargs)#{}
A = (4,5,6)
B = {"name":"laowang","age":18}
test(1,2,3,A,B)
#拆包
def test(a,b,c=33,*args,**kwargs):#args保存多余的没有变量名的变量,kwargs保存有名字的变量,以字典格式.多余的位置实参,多余的关键字实参
print(a)#1
print(b)#2
print(c)#3
print(args)#(4, 5, 6)
print(kwargs)#{{'name': 'laowang', 'age': 18}
A = (4,5,6)
B = {"name":"laowang","age":18}
test(1,2,3,*A,**B) #拆包,*A对元组进行拆包,将元素拆成一个个元素;*B对字典进行拆包,将字典拆成一个个键值对。
print(*A),4,5,6
#print(**B)#直接输出会报错
- 引用
C语言中的复制都是引用
A = [11,22,33]
B = A
A.append(44)
A
Out[42]: [11, 22, 33, 44]
B
Out[43]: [11, 22, 33, 44]
a = 10
b = a#a,b指向同一个内存地址
a = 20#改变a的值,a指向了别的地方
b
Out[47]: 10
- 不可变,可变类型
不可变:数值、字符串、元组
可变:列表、字典
a = "hello"
id(a)
Out[52]: 1714343478528
a = "world"#a指向了其他地方
id(a)
Out[54]: 1714378747552
a[0] = "h"#会报错数值,字符串,元组都可以当成字典的key。
列表和字典不能当key。
- 递归
#递归
def factorial(n):
if n==0 or n==1:
return 1
else:
return factorial(n-1)*n
print(factorial(10))- 列表排序
nums= [2,3,5,1,10,5,8]
nums.sort()
nums
Out[59]: [1, 2, 3, 5, 5, 8, 10]
nums.sort(reverse=True)#从大到小
nums
Out[61]: [10, 8, 5, 5, 3, 2, 1]
#列表元素为字典排序
list1 = [{"name":"laowang","age":18},{"name":"xiaoming","age":20},{"name":"banzhang","age":19}]
#list1.sort()#列表中是数组进行排序时,函数内还得有参数,没参数会报错。
list1.sort(key=lambda x:x["name"])
print(list1)#[{'name': 'banzhang', 'age': 19}, {'name': 'laowang', 'age': 18}, {'name': 'xiaoming', 'age': 20}]- 匿名函数
定义:
lambda [arg1 [,arg2,.....argn]]:expression
# lambda 参数列表:return [表达式] 变量
# 由于lambda返回的是函数对象(构建的是一个函数对象),所以需要定义一个变量去接收冒号翻开,前面参数,后面是表达式。只能有一个表达式,不用写return,
感觉没有多大用,除了不用显示用def定义函数。
def test(a,b,func):
result = func(a,b)
return result
num = test(11,22,lambda x,y:x+y)
print(num)#输入匿名函数
def test(a,b,func):
result = func(a,b)
return result
func = eval(input("请输入一个匿名函数:"))#input输入为字符串,eval()去掉引号,将字符串转换为表达式
num = test(11,22,func)
print(num)- 交换两个变量的值
a = 5
b = 10
a = a + b
b = a - b
a = a -b
print("a=%d,b=%d"%(a,b)) #交换两个变量的值
a = 5
b = 10
a,b = b,a #Python独有
print("a=%d,b=%d"%(a,b))
- num+=num与num=num+num区别
不可修改类型时结果一样,可修改类型时结果不一样。
#num+=num 与num = num+num区别
a = [100]
def test(num):
num += num#,num为可修改类型时,直接在原基础上该
print(num)#[100,100]
test(a)
print(a)#[100,100]#num+=num 与num = num+num区别
a = [100]
def test(num):
num = num + num#指向了别的地方
print(num)#[100,100]
test(a)
print(a)#[100]六、文件
cwd:current working directory
查看文件和文件夹

import os
os.getcwd()#查看当前工作目录
'D:\\Python\\python_review'
os.listdir(os.getcwd())#查看目录包含的文件及文件夹
['.idea', 'test.py', 'venv', '_private.py']
os.path.isfile('D:\\Python\\python_review\\_private.py')#查看是不是文件
True
os.stat('D:\\Python\\python_review\\_private.py')#查看文件的信息
os.stat_result(st_mode=33206, st_ino=2533274790686796, st_dev=639071, st_nlink=1, st_uid=0, st_gid=0, st_size=0, st_atime=1533367817, st_mtime=1533367817, st_ctime=1533365166)import os
#查看目录下所有文件
def files_cwd():
return [p for p in os.listdir(os.getcwd()) if os.path.isfile(p)]
#查看目录下所有文件夹
def foldes_cwd():
return [p for p in os.listdir(os.getcwd()) if os.path.isdir(p)]
print(files_cwd())#['test.py', '_private.py']
print(foldes_cwd())#['.idea', 'venv']#获取当前工作目录中的.py文件
import os
#path=None时,自动把当前工作目录视为目录文件夹,否则将指定的目录视为目录文件夹
def list_py(path = None):
if path == None:
path = os.getcwd()
return [fname for fname in os.listdir(path) if os.path.isfile(fname) if fname.endswith('.py')]
print(list_py())#['test.py', '_private.py']| r | 只读,文件必须存在 |
| w | 只写,不存在则创建,已存在则覆盖 |
| a | 不存在则创建,已存在则在末尾追加 |
| rb | 以二进制格式打开,只读.... |
| wb | 以二进制格式... |
| ab | 以二进制格式... |
| r+ | 可读可写... |
| w+ | 可读可写... |
| a+ | 可读可写... |
| rb+ | |
| rw+ | |
| ra+ |
读写文件
1.英文路径,英文内容
filename='D:\\Python\\python_review\\Tieniu Huang.txt'
f = open(filename,'r')
f = f.read()
print(f)
hello
world
the
file
can
open
2.中文路径,中文内容
原文件使用什么编码方式,encoding就填什么。
#file使用utf-b编码
filename='D:\\Python\\python_review\\黄铁牛.txt'
f = open(filename,'r')#这里使用gbk,gb2312都不行
f = f.read()
print(f)
hello
world
榛勬磱 #乱码
filename='D:\\Python\\python_review\\黄铁牛.txt'
f = open(filename,'r',encoding='utf-8')#使用utf-8变好了
f = f.read()
print(f)
hello
world
黄洋
#当file使用ansi编码时,ansi,gbk,gb2312都正确,utf-8报错。f = open("if_else.py","r",encoding="utf-8",)#打开文件,如果报解码错误,就加上encoding="utf-8",默认以只读"r"打开
print(f.read())#读文件,默认读取所有文件
#print(f.read(4))#读1个字符文件,指针自动后移
f.close()#关闭
f = open("test.py","w")
f.write("haha")#写文件
f = open("test.py","r",encoding="utf-8")
print(f.read())
f.close()Python中open函数不能直接打开word文件,只能打开txt文本文件。如果要打开word文件的话,需要安装python-doxc包。
刚开始2了,在pycharm中弄了好久发现都不能读出word内容,后来才发现目录中docx文件都是打问号的,根本就无法识别。如下如所示

这为老铁666:https://blog.csdn.net/woshisangsang/article/details/75221723
word文档内容:

#打开一个word看看
import docx
filename='D:\\Python\\python_review\\黄铁牛.docx'
file=docx.Document(filename)
for paragraph in file.paragraphs:
print(paragraph.text)
啊
我看见一座大山
这山真高啊
是真的高
复制文件
#复制一个文件,将f复制到f1
f = open("if_else.py","r",encoding="utf-8")
content = f.read()
f1 = open("if_else_copy.py","w+",encoding="utf-8")
f1.write(content)
#print(f1.read())#这是f1指向了文件的末尾,直接输出为空
f.close()
f1.close()文件重命名小技巧
将huangyang.txt改为huangyang[附件].txt
file = "huangyang.txt"
position = file.rfind(".")
new_file = file[:position] + "[附件]"+file[position:]
print(new_file)
read一下子读取多有内容,返回字符串。type(f.read())
readline()逐行读取文件,返回字符串
readlines()按行读取文件,一下子读取所有行,返回列表,列表中每一个元素是一个字符串。type(f.readlines())
filename='D:\\Python\\python_review\\黄铁牛.txt'
f = open(filename,'r',encoding='gbk')
for line in f:
print(line,end='')#这里要加一个end='',因为文件中的各行都以\n结尾不然会多一个空白行
f.close()#可选,会自动关闭文件
啊
我看见一座大山
这山真高啊
是真的高
#上面代码和这个效果一模一样
filename='D:\\Python\\python_review\\黄铁牛.txt'
f = open(filename,'r',encoding='gbk')
for line in f.readlines():
print(line,end='')
f.close()#可选,会自动关闭文件
filename='D:\\Python\\python_review\\黄铁牛.txt'
f = open(filename,'r',encoding='gbk')
print(f.readlines())#['啊\n', '我看见一座大山\n', '这山真高啊\n', '是真的高\n']
#readline
filename='D:\\Python\\python_review\\黄铁牛.txt'
f = open(filename,'r',encoding='gbk')
print(f.readline(),end='')#啊
print(f.readline(),end='')#我看见一座大山
print(f.readline(),end='')#这山真高啊写的紧凑一点:
print(open('D:\\Python\\python_review\\黄铁牛.txt','r',encoding='gbk').read())with读取文件
使用with时,for循环结束后立即指向文件对象清理操作(即关闭文件)
#每行前加一个行号
num=1
#使用with时,for循环结束后立即指向文件对象清理操作(即关闭文件)
with open("D:\\Python\\python_review\\黄铁牛.txt",'r',encoding='gbk') as f:
for line in f:
print("%4d %s"%(num,line),end='')
num +=1
1 啊
2 我看见一座大山
3 这山真高啊
4 是真的高
#这段代码和上面作用一样
num=1
#这里不知道文件对象f在何时关闭,f通常在for循环结束后关闭,但不知道准确时间
f = open("D:\\Python\\python_review\\黄铁牛.txt",'r',encoding='gbk')
for line in f:
print("%4d %s"%(num,line),end='')
num +=1
大文件读取,一点一点读
文件内容:

filename = 'D:\\Python\\python_review\\黄铁牛2号.txt'
f = open(filename,'r',encoding='gbk')
f.read(4)
'黄铁牛爱'
type(f.read(4))
#复制一个文件,将f复制到f1
f = open("if_else.py","r",encoding="utf-8")
f1 = open("if_else_copy.py","w+",encoding="utf-8")
while True:
content = f.read(1024)#一点一点读
if len(content)==0:
break
f1.write(content)
#print(f1.read())#这是f1指向了文件的末尾,直接输出为空
f.close()
f1.close()写文件:
如果文件已经存在,将被覆盖;
filename='D:\\Python\\python_review\\黄铁牛2号.txt'#如果文件已经存在,将覆盖
f = open(filename,'w',encoding='gbk')
f.write("黄铁牛爱吃肉\n")
f.write("黄铁牛爱吃草\n")
黄铁牛爱吃肉
黄铁牛爱吃草
附加到文本文件末尾(附加模式‘a’):
将字符串加入到文本文件时,一种常见的方式是将它们附加到文件末尾。与模式'w'不同的是,这种模式不会删除文件既有的内容。例如:在上面的基础上,
filename='D:\\Python\\python_review\\黄铁牛2号.txt'
f = open(filename,'a',encoding='gbk')
f.write("黄铁牛爱吃瓜\n")
黄铁牛爱吃肉
黄铁牛爱吃草
黄铁牛爱吃瓜
将字符串插入到文件开头
将文件读取到一个字符串中,将新文本插入到该字符串中,再将这个字符串写入原来的文件:
在上面文本内容的基础上:
filename='D:\\Python\\python_review\\黄铁牛2号.txt'
f = open(filename,'r+',encoding='gbk')
temp = f.read()
temp = '黄铁牛爱吃饭\n'+ temp #连接起来
f.seek(0)
f.write(temp)
黄铁牛爱吃饭
黄铁牛爱吃肉
黄铁牛爱吃草
黄铁牛爱吃瓜
文件的定位读写
| seek(a,b) | 第一个参数表示偏移量,第二个参数表示是文件的位置,0:从头开始;1:从当前位置开始,2:从尾开始 |
| tell() | 返回当前指针位置 |
#文件的定位读写
f = open("test.py","r",encoding="utf-8")
f.seek(3,0)#第一个参数表示偏移量,第二个参数表示是文件的位置,0:从头开始;1:从当前位置开始,2:从尾开始
print(f.readline())
print(f.tell())#获取当前指针的位置
f.seek(0,0)#指针指向文件第一个元素,下标为0
print(f.tell())处理二进制文件
例如:检查一张图片是否是gif图像,方法是检查其前4个字节是不是(0x47,0x49,0x46,0x38),其实就是gif8的ascii编码
#处理二进制文件
filename = 'D:\\Python\\python_review\\hy.gif'
f = open(filename,'br')
first4 = tuple(f.read(4))
print(first4 == (0x47,0x49,0x46,0x38))#True
f.read(4)
b'GIF8'
tuple(b'GIF8')
(71, 73, 70, 56)
type(f.read(4))
访问二进制文件的各个字节是一种非常低级的操作。在处理二进制文件方面,pickle通常是一种方便的方式。
以二进制格式存储,再以二进制格式读入。
#使用pickle处理二进制文件
import pickle
personal_information = {"name": "hy", "gender": 1, "age": 4}
outfile = open('personal_information.dat', 'wb')#这.dat后缀是随便取得,知识为了表示存放数据,你高兴的话,也可以起为.data1啥的。
pickle.dump(personal_information, outfile)
infile = open('personal_information.dat', 'rb')
personal_information = pickle.load(infile)
print(personal_information)#{'name': 'hy', 'gender': 1, 'age': 4}
#这两段代码不能同时运行,不然报错
Traceback (most recent call last):
File "D:/Python/python_review/test.py", line 9, in
personal_information = pickle.load(infile)
EOFError: Ran out of input 打开网页
#打开网页
import webbrowser
webbrowser.open('http://www.baidu.com')
文件的相关操作
- 文件重命名
os模块中的rename()可以完成对文件的重命名操作
rename(需要修改的文件名,新的文件名)
- 删除文件
remove()
remove(待删除的文件名)
- 获取当前路径目录列表
listdir()
import os
os.rename("testtest.txt","testhehe.txt")#重命名
os.remove("testhehe.txt")#删除
os.listdir()#获取当前路径目录列表
批量修改文件名
#批量修改文件名
import os
folder_name = input("请输入要重命名的文件夹")
file_names = os.listdir(folder_name)
for name in file_names:
print(name)
old_file_name = folder_name + "/" + name
new_file_name = folder_name + "/" +"[京东出品]" + name
os.rename(old_file_name,new_file_name)
file_names = os.listdir(folder_name)
for name in file_names:
print(name)上面是批量增加一个东西,如果要批量减少一个东西怎么写了?
七、面向对象
类
名称:类名
属性:一组数据
方法:允许进行操作的方法
例子:坦克类
类名:Tank
属性:重量、速度、材料。。。
方法:开炮,移动,转弯。。
class 类名:
#属性
#方法
定义类与对象
class Cat:
#属性
#方法
def eat(self):#必须写上self
print("猫在吃鱼")
def introduce(self):
print("%s的年龄是%d" % (tom.name, tom.age))#错误写法示例,这样写会被打死
#创建一个对象
tom = Cat()
tom.eat()
#给对象添加属性
tom.name="汤姆"
tom.age=18
print("%s的年龄是%d"%(tom.name,tom.age))
#创建另一个对象
lanmao = Cat()
lanmao.nam2="蓝猫"
lanmao.age=10
lanmao.introduce()#这里是找得到tom的,tom是全局变量,找得到tom,就找得到tom.age。
class Cat:
#属性
#方法
def eat(self):#必须写上self
print("猫在吃鱼")
def introduce(self):#self参数放在第一个,对象指向谁,self就指向谁
print("%s的年龄是%d"%(self.name, self.age))
#创建一个对象
tom = Cat()
tom.eat()
#给对象添加属性
tom.name="汤姆"
tom.age=18
#print("%s的年龄是%d"%(tom.name,tom.age))
tom.introduce()
#创建另一个对象
lanmao = Cat()
lanmao.name="蓝猫"
lanmao.age=10
lanmao.introduce()__init__方法
创建对象流程:
1.创建一个对象,Python自动调用__init__方法 ,返回创建的对象的引用
__str__方法
print(object),打印对象时候自动调用
class Cat:
#属性
#方法
def __init__(self,name,age):
self.name = name#对象中自动添加name属性
self.age = age
def __str__(self):
return "%s的年龄是:%d"%(self.name,self.age)
def eat(self):#必须写上self
print("猫在吃鱼")
def introduce(self):#self参数放在第一个,对象指向谁,self就指向谁
print("%s的年龄是%d"%(self.name, self.age))
#创建一个对象
tom = Cat("tom",18)
tom.eat()
tom.introduce()
#创建另一个对象
lanmao = Cat("laomao",10)
lanmao.introduce()
print(tom)#直接打印对象时候,系统自动调用__str__方法。
print(lanmao)
隐藏(保护)对象属性
通过方法来修改对象的属性,而不是直接修改对象的属性。
好处:
dog=Dog()
dag.age=-10
可以在函数中进行一些判断,对不正确的设置进行处理。
#保护对象属性
class Dog:
def set_age(self,new_age):
if new_age>0 and new_age<120:
self.age=new_age
else:
self.age=0
def get_age(self):
return self.age
#dog.age=10#不直接这样写
dog=Dog()
dog.set_age(10)#要先set_age,再get_age,不然会说dog对象没有属性age
print(dog.get_age())私有属性
私有方法
#私有方法
class Dog:
#私有方法
def __send_msg(self):#前面加两个下划线
print("正在发送短信")
def send_msg(self,new_money):
if new_money>10000:
self.__send_msg()
else:
print("余额不足,请先充值,再发送短信.")
dog = Dog()
dog.send_msg(100)__del__(self)方法
对象彻底消失时执行
class Dog():
def __del__(self):#程序结束之前,清空内存,所有对象都会调用这个方法。程序中,对象被删除后,会调用这个方法
print("英雄over")
dog1=Dog()
dog2=dog1#dog1和dog2指向同一个对象
del dog1
del dog2
print("========")![]()
class Dog():
def __del__(self):#程序结束之前,清空内存,所有对象都会调用这个方法。程序中,对象被删除后,会调用这个方法
print("英雄over")
dog1=Dog()
dog2=dog1#dog1和dog2指向同一个对象
del dog1
print("========")
注意两个程序打印的顺序。
测量对象的引用个数
sys.getrefcount()函数,测量结果比实际多1。
import sys
class T():
pass
t1 = T()
print(sys.getrefcount(t1))#2,比实际的多1
t2 = t1
print(sys.getrefcount(t1))#3
继承、重写、调用父类中被重写的方法
#继承
class Animal():
def eat(self):
print("-----吃-----")
def drink(self):
print("-----喝-----")
def sleep(self):
print("-----睡-----")
def run(self):
print("-----跑-----")
class Dog(Animal):#继承Animal类
def bark(self):
print("-----汪汪叫----")
class Cat(Animal):
def catch(self):
print("----抓老鼠------")
class Xiaotq(Dog):#哮天犬
def fly(self):
print("-----飞-------")
def bark(self):#重写父类函数
print("----哮天犬专有叫声------")
#调用被重写的父类的方法1
#Dog.bark(self)#这里要加self
#方法2
super().bark()
dog1 = Dog()
cat1 = Cat()
xiaotq1 = Xiaotq()
dog1.eat()
cat1.eat()
xiaotq1.eat()
xiaotq1.bark()#默认先在子类中寻找,子类中没有时,调用父类的私有方法、私有属性在继承中的表现
class A():
def __init__(self):
self.num1 = 100
self.__num2 = 200
def test1(self):
print("-----test1-----")
def __test2(self):
print("-----test2-----")
def test3(self):
self.__test2()
print(self.__num2)
class B(A):
def test4(self):
self.__test2()#这里不能访问父类的私有方法
print(self.__num2)#这里不能访问父类的私有属性
b = B()
b.test1()
#b.test2()#私有方法不会被继承
print(b.num1)
#print(b.__num2)#私有属性不会被继承
b.test3()
b.test4()如果调用的是继承的父类中的公有方法,可以在这个公有方法中访问父类中的私有属性和私有方法,
如果在子类中实现了一个公有方法,那么这个方法是不能够调用继承的父类中的私有方法和私有属性。
多继承
#多继承,一个子类继承自多个父类
class Base(object):#所有类都继承自object类
def test(self):
print("base")
class A(Base):
def test1(self):
print("test1")
class B(Base):
def test2(self):
print("test2")
class C(A,B):#多继承
pass
c1 = C()
c1.test1()
c1.test2()
c1.test()多继承_调用顺序
#多继承调用顺序
class Base(object):#所有类都继承自object类
def test(self):
print("base")
class A(Base):
def test(self):
print("A")
class B(Base):
def test(self):
print("B")
class C(A,B):#多继承
def test(self):
print("C")
c1 = C()
c1.test()
print(C.__mro__)#查看类中方法调用的顺序,如果在某个类中找到了方法,就停止搜索。
#C3算法
#实际开发中,尽量不要在不同的类中定义相同的方法。多态
#多态
class Dog(object):
def print_self(self):
print("大家好,我是XXXX")
class Xiaotq(Dog):
def print_self(self):
print("hello everybody,我是你们的老大")
def introduce(temp):#Python是弱类型语言,多态不明显
temp.print_self()
dog1 = Dog()
dog2 = Xiaotq()
introduce(dog1)
introduce(dog2)
类属性,实例属性
#类属性,实例属性
class Tool(object):
#类属性
num = 0#每个对象都可以访问
#方法
def __init__(self,new_name):
self.name = new_name#self.name:实例属性,相当于这个对象里面的全局变量,这个对象的所有方法都可以访问
age = 2#这里相当于定义了一个方法里面的局部变量age,只能在这个方法里面访问,不能在其他方法里面访问
#num += 1#这里使用global也不行,global表示使用的是类外面的全局变量,不是类属性
Tool.num += 1#访问类属性格式:类名.属性名
tool1 = Tool("铁锹")
tool2 = Tool("工兵铲")
tool3 = Tool("水桶")
print(Tool.num)1、什么是类对象,实例对象
类对象:类名
实例对象:类创建的对象
2、类属性就是类对象所拥有的属性,它被所有类对象的实例对象所共有,在内存中只存在一个副本
公有类属性:
如果在类外修改类属性,必须通过类对象去引用然后进行修改。如果通过实例对象去修改, 会产生一个同名的实例属性,这种方式修改的是实例属性,不会影响到类属性,并且如果通过实例对象引用该名称的属性,实例属性会强制屏蔽掉类属性,即引用的是实例属性,除非删除了该实例属性。
class people(object):
name = "tom"
p = people()
p.age = 18#相当于在实例对象中添加了一个实例变量age
print(p.name)
print(p.age)#
print(people.name)
print(people.age)#错误,实例属性,不能通过类对象调用# 类属性,实例属性
class Tool(object):
# 类属性
name = 'ym ' # 每个对象都可以访问
# 方法
def __init__(self, new_name):
self.name = new_name
t = Tool('hy')
print(t.name)#'hy',实例属性会屏蔽类属性
print(Tool.name)#'ym'
类方法,实例方法,静态方法
#类方法,实例方法,静态方法
class Game(object):
#类属性
num = 0
#实例方法
def __init__(self):
#实例属性
self.name = "老王"
#类方法
@classmethod
def add_num(cls):
cls.num = 100
#静态方法
@staticmethod
def print_menu():#不需要参数
print("---------")
print(" 穿越火线V11.1 ")
print("---------")
game = Game()
#Game.add_num()#可以通过类名和对象来调用类方法
game.add_num()
print(Game.num)
Game.print_menu()#可以通过类名和对象来访问静态方法
game.print_menu()property:
以后再看吧。
设计类
#设计类
#设计一个现代的4s店
class CarStore(object):#店铺类
def order(self,car_type):
if car_type == "索纳塔":
return Suonata()
elif car_type =="名图":
return Mingtu()
elif car_type == "ix35":
return Ix35()
class Car(object):#车类
def move(self):
print("车在移动")
def music(self):
print("正在播放音乐")
def stop(self):
print("车在停止")
class Suonata(Car):
pass
class Mingtu(Car):
pass
class Ix35(Car):
pass
car_store = CarStore()
car = car_store.order("索纳塔")
car.move()
car.music()
car.stop()#设计类,使用函数解耦合
#设计一个现代的4s店
class CarStore(object):#店铺类
def order(self,car_type):
return select_car_by_type(car_type)
def select_car_by_type(car_type):#使用函数解两个类的耦合,两个类由两个不同的人开发,一个类改了之后,另一个类跟着变不好
if car_type == "索纳塔":#使用函数来解除两个类的耦合,这样函数和Car()类可以由一个人开发,CarStore()类由一个人开发。
return Suonata()
elif car_type == "名图":
return Mingtu()
elif car_type == "ix35":
return Ix35()
class Car(object):#车类
def move(self):
print("车在移动")
def music(self):
print("正在播放音乐")
def stop(self):
print("车在停止")
class Suonata(Car):
pass
class Mingtu(Car):
pass
class Ix35(Car):
pass
car_store = CarStore()
car = car_store.order("索纳塔")
car.move()
car.music()
car.stop()#使用类解耦
class CarStore(object):#店铺类
def __init__(self):
self.factory = Factory()
def order(self,car_type):
return self.factory.select_car_by_type(car_type)
class Factory():
def select_car_by_type(self,car_type):
if car_type == "索纳塔":
return Suonata()
elif car_type == "名图":
return Mingtu()
elif car_type == "ix35":
return Ix35()
class Car(object):#车类
def move(self):
print("车在移动")
def music(self):
print("正在播放音乐")
def stop(self):
print("车在停止")
class Suonata(Car):
pass
class Mingtu(Car):
pass
class Ix35(Car):
pass
car_store = CarStore()
car = car_store.order("索纳塔")
car.move()
car.music()
car.stop()
__new__方法:创建对象
#__new__方法
class Dog(object):
def __init__(self):
print("----init方法----")
def __del__(self):
print("----del方法-----")
def __str__(self):
print("----str方法----")
return "对象的描述信息"
def __new__(cls):#自己重写了new方法后,就不能创建对象了,需要调用父类的new方法创建对象。
print(id(cls))
print("----new方法-----")
return object.__new__(cls)#这里有返回值
print(id(Dog))#输出对象指向的地址
dog1 = Dog()#做了三件事情1.调用new方法创建对象2.调用__init__方法初始化,3返回对象的应用
创建单例对象
#创建单例对象,无论创建多少个对象,这些对象都指向同一块内存地址.
class Dog(object):
__instance = None#隐藏的类属性
def __new__(cls, *args, **kwargs):
if cls.__instance == None:
cls.__instance = object.__new__(cls)
return cls.__instance
else:
return cls.__instance
a = Dog()
b = Dog()
print(id(a))
print(id(b))只初始化一次对象
class Dog(object):
__instance = None
def __new__(cls, name):
if cls.__instance == None:
cls.__instance = object.__new__(cls)
return cls.__instance
else:
return cls.__instance
def __init__(self,name):
self.name = name
a = Dog("旺财")
print(id(a))#2618025477120
print(a.name)#旺财
b = Dog("哮天犬")
print(id(b))#2618025477120
print(b.name)#哮天犬#只初始化一次对象
class Dog(object):
__instance = None
__init__flag = 0
def __new__(cls, name):
if cls.__instance == None:
cls.__instance = object.__new__(cls)
return cls.__instance
else:
return cls.__instance
def __init__(self,name):
if Dog.__init__flag == 0:
self.name = name
Dog.__init__flag = 1
a = Dog("旺财")
print(id(a))#2618025477120
print(a.name)#旺财
b = Dog("哮天犬")
print(id(b))#2618025477120
print(b.name)#旺财八、异常处理
try:
print(num)
print("-------")
except 异常名:
print("捕获到异常后,进行的操作")
常见异常:
https://docs.python.org/3/library/exceptions.html
| exception name | description |
| IOError | 读取不存在的文件 |
| ZeroDivisionError | 0除错误 |
| SyntaxError | 语法错误,pirnt('hello) |
| ValueError | 传入的参数无效,int('abc') |
异常
def get_age():
while True:
try:
n = int(input("please input you age:"))
return n
except ValueError:
print("please input again")
print(get_age())
please input you age:fds
please input again
please input you age:sdf
please input again
please input you age:22
22
#异常
try:
open("xxx.txt")
print(name)
print("----1----")
except NameError:
print("变量未定义")
except FileNotFoundError:
print("文件不存在")
print("----2----")
#try,except,else,finally
try:
open("xxx.txt")
print(name)
print("----1----")
except (NameError,FileNotFoundError): #一个except捕获多个异常
print("变量未定义")
print("文件不存在")
except Exception as ret:#捕获所有异常,这里可以直接写except:
print("如果用了Exception,只要上面的except没有捕获到异常,这个except一定会执行")
print(ret)#查看异常信息
else:
print("没有异常执行的功能")
finally:
print("有没有异常都会执行")
print("----2----")
异常的传递
#异常的传递,函数里面发生的异常会传递到调用函数的地方
def test1():
print("------test1-1-------")
print(num)
print("-----test1-2--------")
def test2():
print("------test2-1--------")
test1()
print("------test2-2--------")
def test3():
try:
print("-----test3-1--------")
test1()
print("------test3-2--------")
except Exception as result:
print("捕获到了异常,信息是:%s"%result)
print(result)
test3()
print("-----华丽的分割线-------")
test2()
人为抛出异常
raise IOError("This is a test!")
Traceback (most recent call last):
File "", line 1, in
OSError: This is a test!
抛出自定义异常
#自定义异常
class ShortInputException(Exception):
def __init__(self,length,atleast):
self.length = length
self.atleast = atleast
def main():
try:
s = input("请输入...")
if len(s) < 3:
raise ShortInputException(len(s),3)#抛出异常
except ShortInputException as result:
print("ShortInputException:输入的长度是%d,长度至少是%d"%(result.length,result.atleast))
else:
print("没有发生异常")
main()
异常处理中抛出异常
class Test(object):
def __init__(self,switch):
self.switch = switch
def calc(self,a,b):
try:
return a/b
except Exception as result:
if self.switch:
print("捕获开启,已经捕获到了异常")
else:
raise
a = Test(True)
a.calc(11,0)
print("-----华丽的分割线-------")
a.switch = False
a.calc(11,0)
if判断中"",None,0,[],{},()都为假
非空为真
if "a":
print("真")
真
九、模块
模块其实就是一个.py文件
查看模块存放路径
import random
random.__file__
Out[9]: 'E:\\python\\lib\\random.py'
查看模块中包含函数:dir(模块名)
模块文档说明:模块名.__doc__
自定义模块:
放在当前文件目录下,或者系统自带的模块路径下
#创建HY.py模块
def test():
print("hy")#在其他文件中使用
import HY
HY.test()当使用HY模块时,Python会将HY模块文件转换成字节码.pyc文件,保存在当前文件路径,相当于一个缓存文件。
![]()
cpython-36:
c表示Python解释器是C语言写的
36表示Python3.6版本。
多种导入方式
import HY
HY.test()
from HY import test
test()
from HY import test,test1
from HY import *#尽量少用这种方法,可能存在覆盖问题
import HY as hy#起一个别名导入模块时,默认会把导入的模块执行一遍
#HY模块
def test():
print("hy")
def test1():
print("hy")
test()
test1()
#module.py
import HY#会自动指向HY模块中的test(),test1()import HY
HY.test()
HY.test1()
__name__
直接运行这个模块时,__name__的值为"__main__"
当在其他.py文件中调用这个模块时,__name__的值为自己的名字
利用__name__来进行测试
#HY模块
def test():
print("hy")
def test1():
print("hy")
if __name__ == "__main__":#测试时执行,调用时不执行
test()
test1()
#module.py,调用模块
import HY
HY.test()
HY.test1()
__all__
控制模块中哪些东西可以被调用者使用
__all__ = ["test1","Test"]#__all__是一个列表,只有这里写的,才能在调用模块中使用
def test():
print("hy")
def test1():
print("hy")
num = 100
class Test(object):
pass
module.py中调用
from HY import *
#test()#不能使用
test1()
module.py中调用
import HY
HY.test()#这种方法可以调用
HY.test1()
包
例:建立了两个模块recvmsg.py,sendmsg.py,把他们放到同一个文件夹TestMsg下,这个文件夹就是一个包。只不过现在还不能直接用recvmsg,sendmsg这两个模块。需要在TestMsg文件夹下面新建立__init__.py文件,在__init__.py文件中通过__all__变量来指明哪些模块可以被使用。
如果不建立__init__.py文件的话,可以导入import TestMsg成功,但是不能访问它下面的模块。
#recemsg.py
def test1():
print("recvmsg--test1")
#sendmsg.py
def test2():
print("send--test2")
#__init__.py
__all__ = ["recvmsg"]
#testmsg.py
from TestMsg import *
recvmsg.test1()
#sendmsg.test2()#不能访问import TestMsg#这种导入方法不行,会把TestMsg当成模块,
TestMsg.recvmsg.test1()#这里会报错,说TestMsg模块中没有recemsg解决方法
#__init__.py
__all__ = ["recvmsg"]
from . import recvmsg #从当前路径下导入revemsg#testmsg.py
import TestMsg
TestMsg.recvmsg.test1()#这时就可以访问了
在导入TestMsg时,会自动把__init__.py执行一遍
模块的发布,安装
给程序传递参数
#给程序传递参数
import sys
print(sys.argv)#argv是一个列表,默认是程序名#['E:/TensorFlow/Python/Python_Learn/Python_Foundation/program_argv.py', '老王']
print("热烈欢迎%s的到来"%sys.argv[1])#热烈欢迎老王的到来pycharm中通过run->Edit Configurations->Script parameters来给程序传递参数,多个参数之间用空格分开。
集合,元组,列表
a = (11,22,33,11,22,33)
a
Out[3]: (11, 22, 33, 11, 22, 33)
b = [11,22,33,11,22,33]
b
Out[5]: [11, 22, 33, 11, 22, 33]
c = {11,22,33,11,22,33}
c
Out[7]: {11, 22, 33}#集合set,没有重复元素
列表去重
a = [11,22,33,44,11,22,33]
a = list(set(a))#通过集合去重
a
Out[11]: [33, 11, 44, 22]
模块重新导入
查看模块导入的路径
import sys
sys.path
Out[13]:
['E:\\PyCharm 2017.2.3\\helpers\\pydev',
'E:\\PyCharm 2017.2.3\\helpers\\pydev',
'E:\\python\\python36.zip',
'E:\\python\\DLLs',
'E:\\python\\lib',
'E:\\python',
'E:\\python\\lib\\site-packages',
'E:\\python\\lib\\site-packages\\IPython\\extensions',
'E:\\TensorFlow\\Python\\Python_Learn\\Python_Foundation',
'E:/TensorFlow/Python/Python_Learn/Python_Foundation']
sys.path是一个列表,可以自己修改。更改后查找的路径就变了。
#test.py
def test():
print("------1----")
print("------2----")#_reload.py
import test
test.test()感觉不用reload呀,test.py中的内容改变后,reload.py中会自动更新。
模块循环导入问题
我导入你,你导入我,会报错
a.py
from b import b
def a():
print("--a--")
b()
a()b.py
from a import a
def b():
print("--b--")
def c():
print("--c--")
a()
c()上面在a中导入b,在b中导入a,会报错。
== 和 is
==判断值是不是一样
is判断是不是指向同一个内容
a = [1,2,3]
b = [1,2,3]
a == b
Out[17]: True
a is b
Out[18]: False
c = b
c is b
Out[20]: True
id(a)
Out[21]: 2367509601160
id(b)
Out[22]: 2367509599944
id(c)
Out[23]: 2367509599944
#注意点,有点意思。在某个整数范围内 a is b是真的
a = 100
b = 100
a is b
Out[28]: True
a = 10000
b = 10000
a is b
Out[31]: False
深拷贝,浅拷贝
深拷贝:复制一份
浅拷贝:指向同一个地方
#浅拷贝
a = [11,22,33]
b = a
id(a)
Out[34]: 2367509628552
id(b)
Out[35]: 2367509628552
#深拷贝
import copy
a = [11,22,33]
c = copy.deepcopy(a)
id(a)
Out[39]: 2367509629896
id(c)
Out[40]: 2367509628680
b = [44,55,66]
c = [a,b]
c
Out[5]: [[11, 22, 33], [44, 55, 66]]

a = [11,22,33]
b = [44,55,66]
c = [a,b]
c
Out[5]: [[11, 22, 33], [44, 55, 66]]
import copy
e = copy.deepcopy(c)
e[0]
Out[9]: [11, 22, 33]

#copy.copy
a = [1,2,3]
b = [4,5,6]
c = [a,b]
import copy
e = copy.copy(c)
a.append(4)
c[0]
Out[8]: [1, 2, 3, 4]
e[0]
Out[9]: [1, 2, 3, 4]
id(c)
Out[10]: 2819516398984
id(e)
Out[11]: 2819516564040

#元组与copy.copy
a = [1,2,3]
b = [4,5,6]
c = (a,b)
import copy
e = copy.copy(c)
id(c)
Out[7]: 2480767999880
id(e)
Out[8]: 2480767999880
a.append(4)
a
Out[10]: [1, 2, 3, 4]
c[0]
Out[11]: [1, 2, 3, 4]
e[0]
Out[12]: [1, 2, 3, 4]
进制



位运算
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0 | (a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| | | 按位或运算符:只要对应的二个二进位有一个为1时,结果位就为1 | (a | b) 输出结果 61 ,二进制解释: 0011 1101 |
| ^ | 按位异或运算符:当两对应的二进位相异时,结果为1 | (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
| ~ | 按位取反运算符:对数据的每个二进制位取反,即把1变为0,把0变为1 | (~a ) 输出结果 -61 ,二进制解释: 1100 0011, 在一个有符号二进制数的补码形式。 |
| << | 左移动运算符:运算数的各二进位全部左移若干位,由”<<”右边的数指定移动的位数,高位丢弃,低位补0 | a << 2 输出结果 240 ,二进制解释: 1111 0000 |
| >> | 右移动运算符:把”>>”左边的运算数的各二进位全部右移若干位,”>>”右边的数指定移动的位数 | a >> 2 输出结果 15 ,二进制解释: 0000 1111 |
# -*- coding: UTF-8 -*-
a = 60 # 60 = 0011 1100
b = 13 # 13 = 0000 1101
c = 0
c = a & b; # 12 = 0000 1100
print "1 - c 的值为:", c
c = a | b; # 61 = 0011 1101
print "2 - c 的值为:", c
c = a ^ b; # 49 = 0011 0001
print "3 - c 的值为:", c
c = ~a; # -61 = 1100 0011
print "4 - c 的值为:", c
c = a << 2; # 240 = 1111 0000
print "5 - c 的值为:", c
c = a >> 2; # 15 = 0000 1111
print "6 - c 的值为:", c输出:
1 - c 的值为: 12
2 - c 的值为: 61
3 - c 的值为: 49
4 - c 的值为: -61
5 - c 的值为: 240
6 - c 的值为: 15
~9
Out[20]: -10

私有化
参考http://python.jobbole.com/81129/
xx:公有变量
_:作为一个名称使用,临时使用,不关心它的值,在后面不会再用到。这样别人读你的代码的时候,就知道它在后面不会再用到。
例如:
for _ in range(5):
print(_)
0
1
2
3
4_x:单前置下划线,from module import *时无法访问(一个以上_),当是 import modue时可以访问。
程序员使用名称前的单下划线,用于指定该名称属于"私有"。这有点类似与惯例,为了使其他人(或者自己)使用这些代码时知道以"_"开头的名称只供内部使用。但是还是可以对象访问到它。
__xx:类里面定义私有化方法或属性
名称(具体为一个方法名)前双下划线(__)的用法并不是一种惯例,对解释器来说它有特定的意义。Python中的这种用法是为了避免与子类定义的名称冲突。Python文档指出,“__spam”这种形式(至少两个前导下划线,最多一个后续下划线)的任何标识符将会被“_classname__spam”这种形式原文取代,在这里“classname”是去掉前导下划线的当前类名
>>> class A(object):
... def _internal_use(self):
... pass
... def __method_name(self):
... pass
...
>>> dir(A())
['_A__method_name', ..., '_internal_use']class B(A):
... def __method_name(self):
... pass
...
>>> dir(B())
['_A__method_name', '_B__method_name', ..., '_internal_use']__xx__
这种用法表示Python中特殊的方法名。其实,这只是一种惯例,对Python系统来说,这将确保不会与用户自定义的名称冲突。通常,你将会覆写这些方法,并在里面实现你所需要的功能,以便Python调用它们。例如,当定义一个类时,你经常会覆写“__init__”方法。
虽然你也可以编写自己的特殊方法名,但不要这样做。
>>> class C(object):
... def __mine__(self):
... pass
...
>>> dir(C)
... [..., '__mine__', ...]#_private.py
name1 = 100
_name2 = 200
__name3 = 300
from _private import *
name1
Out[3]: 100
_name2
NameError: name '_name2' is not defined
__name3
NameError: name '_name3' is not defined
为什么定义成私有属性之后在类外就无法访问了?
Python通过名字重整会将定义的私有属性改写为_类名+属性名
class Dog():
def __init__(self):
self.__age = 10
dog = Dog()
print(dog._Dog__age)#10
生成器
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,需要占用很大的空间。
有时,如果列表元素可以按照某种算法推算出来,我们是否可以在循环的过程中不断推算出后序的元素了?这样就不必创建完整的list,从而节省大量的空间。在Python中,这样一边循环一边计算的机制,称为生成器:generator。
要创建一个生成器,有很多方法,方法一,只要把一个列表的生成式[]改成(),就创建了一个generator。
生成器只有在调用时才会生成相应的数据
只记录当前位置,只有一个__next__()方法,不能找到它的前一个数据。
a = (i*2 for i in range(10))
a
at 0x000000000360E150>
for i in a:
print("%d "%(i),end='')#0 2 4 6 8 10 12 14 16 18
a[0]#报错,不能直接这样取,数据都没有生成了
next(a)
StopIteration#进过上面的循环a已经取到最后一个数了,再next就报错了。
b = (i*i for i in range(10))
b
at 0x000000000360E2B0>
next(b)
0
next(b)
1
b.__next__()
4
generator非常强大,如果推算的算法比较复杂,用类似列表解析的for循环无法实现的时候,可以使用函数来实现。
例如:Fibonacci数列:1,1,2,3,5,8,13,21,34...
插入一个小知识点:
a = 1
b = 2
a,b = b,a+b
a
2
b
3a,b=b,a+b 相当于t=b,a+b t=(a,a+b),a=t[0],b=t[1]。
def Fib(max):
n,a,b = 1,0,1
while(n<=max):
yield b
a,b = b,a+b
n +=1
a = Fib(10)
print(a)#
for i in a:
print("%d "%(i),end='')#1 1 2 3 5 8 13 21 34 55
def Fib(max):
n,a,b = 1,0,1
while(n<=max):
yield b
a, b = b, a + b
n +=1
return "异常发生了"#异常发生时执行
a = Fib(10)
print(a)#
while True:
try:
print("%d "%(a.__next__()),end='')
except StopIteration as e:
print(e.value)
break
1 1 2 3 5 8 13 21 34 55 异常发生了
在每次调用next函数的时候,遇到yield语句就返回,再次执行的时候从上次返回的yield语句处继续执行。
def odd():
print("step1")
yield 1
print("step2")
yield 2
print("step3")
yield(3)
o = odd()
o.__next__()
step1
1
o.__next__()
step2
2
o.__next__()
step3
3
o.__next__()
Traceback (most recent call last):
File "", line 1, in
StopIteration send(),发送数据给yield
def generator_test():
print("start")
a = yield
print("stop " + a)
yield 1
g = generator_test()#执行这一句时,generator_test()中的内容不指向,print("start")不输出
g.__next__()#start
g.send("hello")#stop helloimport time
def generator_test():
print("start")
a = yield#没有东西传入时,返回None
print(a)
yield 1
g = generator_test()
for i in g:
print(i)
start
None
None
1
迭代器
可迭代对象:
一类是list,tuple,dict,set,str等
一类是generator,包括生成器和带yield的generator function。
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable
判断是否可迭代
可以使用isinstance()判断一个对象是否是Iterable对象
isinstance()其实是用来判断一个对象是不是某各类或者这个类的子对象的。

class A(object):
pass
a = A()
print(isinstance(a,A))#Truefrom collections import Iterable
isinstance([],Iterable)
Out[4]: True
isinstance({},Iterable)
Out[5]: True
isinstance("abc",Iterable)
Out[6]: True
isinstance(100,Iterable)
Out[7]: False
迭代器
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator
可以使用isinstance()判断一个对象是否是Iterator对象
from collections import Iterator
isinstance([],Iterator)
Out[9]: False
isinstance((x for x in range(10)),Iterator)
Out[10]: True
range(10)是可迭代对象,不是生成器,不是迭代器;
http://www.php.cn/python-tutorials-391253.html
range(10)
range(0, 10)
type(a)
isinstance(a,Iterable)
True
isinstance(a,Iterator)
False
from collections import generator
isinstance(a,types.GeneratorType)
False iter()函数
生成器都是Iterator对象,但list,dict,str虽然是Iterable,而不是Iterator对象。
把list,dict,str等Iterable编程Iterator可以使用iter()函数
a = [1,2,3,4]
type(a)
Out[12]: list
dir(a)#没有next方法
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
iter(a)
Out[13]:
b = iter(a)
type(b)
Out[15]: list_iterator
next(b)
Out[16]: 1
next(b)
Out[17]: 2
dir(b)#包含next方法
['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__length_hint__', '__lt__', '__ne__', '__new__', '__next__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__'] 为什么list,dict,str等数据不是Iterator?
这是因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但是我们却不能提前知道序列的长度,只能不断通过next函数来计算下一个数据,所以Iterator的计算是惰性的。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。
Python中的for循环本质上就是通过不断调用next方法实现的,例如:
for i in [1,2,3,4,5]:
print(i)
#等价于
it = iter([1,2,3,4,5])
while True:
try:
print(next(it))
except StopIteration:
break
闭包
def test():
print("-----1----")
test
Out[19]:
b = test
b()
-----1----
b
Out[22]:
定义:
在函数内部再定义一个函数,并且这个函数用到了外边函数的变量,那么将这个函数以及用到的变量成为闭包。
def test(number):
print("------1-----")
def test_in():
print("-----2-----")
print(number+100)
print("-----3-----")
return test_in
test(100)()
#输出
------1-----
-----3-----
-----2-----
200 test函数在运行结束后,没有销毁,因为里面的test_in函数还要使用。
闭包运用
'''
#闭包
def test(number):
print("------1-----")
def test_in():
print("-----2-----")
print(number+100)
print("-----3-----")
return test_in
test(100)()
'''
#闭包运用,计算y=a*x+b的值,调用的时候只需要穿x的值,不需要传递a,b,x的值
def test(a,b):
def test_in(x):
print(a*x+b)
return test_in
line1 = test(1,1)
line1(0)#1
line2 = test(10,4)
line2(0)#4

装饰器
装饰器是程序开发中经常用到的一个功能,用好了装饰器,开发效率如虎添翼,是Python中必问的问题。装饰器是程序开发的基础知识,这个都不会,别跟别人说你会Python。
#函数重定义
def test():
print("--1--")
def test():#有提示,但不报错
print("--2--")
test()#2装饰器距离
A开发的代码需要供其他人使用,现在需要加一个权限认证,需要A对自己开发的代码进行更改,调用方调用方式不改。
#开始,A的代码
def f1():
print("---f1---")
def f2():
print("---f2---")#调用方
f1()
f2()
现在需要加权限认证,但是尽量不要对f1,f2函数内部的代码进行更改。
#初级更改
def w1(func):
def inner():
print("----正在验证权限----")
func()
return inner
def f1():
print("---f1---")
def f2():
print("---f2---")
f1 = w1(f1)
f1()
使用装饰器方法
def w1(func):
def inner():
print("----正在验证权限----")
func()
return inner
#f1 = w1(f1)
@w1#装饰器
def f1():
print("---f1---")
@w1
def f2():
print("---f2---")
f1()#有装饰器时,先默认运行f1 = w1(f1)@w1内部执行的操作
执行w1函数,并将@w1下面的函数作为w1函数的参数
将执行完的w1函数返回值赋值给@w1下面的函数的函数名。
两个装饰器
#两个装饰器,将字体加粗,变斜体
def makeBold(fn):
def wrapped():
print("---1---")
return "" + fn() + ""
return wrapped
def makeItalic(fn):
def wrapped():
print("---2---")
return "" + fn() + ""
return wrapped
@makeBold#后执行
@makeItalic#先执行
def test3():
print("---3---")
return "hello world"
ret = test3()
print(ret)#结果
---1---
---2---
---3---
hello world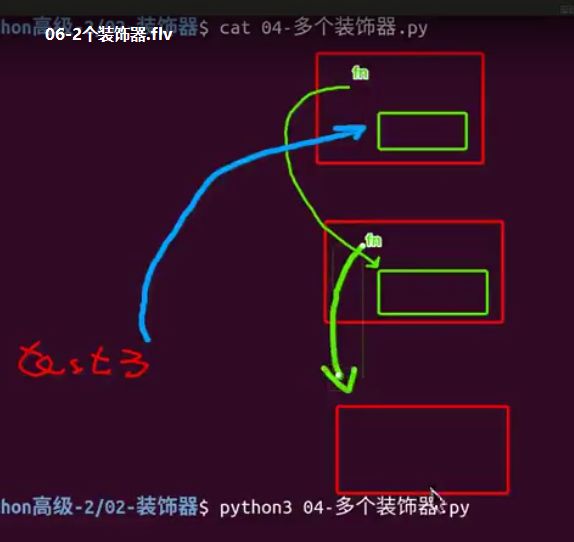
装饰器什么时候进行装饰
example1:
#装饰器执行时间
def w1(func):
print("---正在装饰---")
def inner():
print("---正在验证权限---")
func()
return inner #这里不要加()
@w1 #只要Python解释器执行到了这个代码,那么就会自动的进行装饰,而不是等到调用的时候才装饰
def f1():
print("---f1---")
#在调用f1之前,已经进行装饰了
f1()example2:
def w1(func):
print("---正在装饰1---")
def inner():
print("---正在验证权限1---")
func()
return inner
def w2(func):
print("---正在装饰2---")
def inner():
print("---正在验证权限2---")
func()
return inner
@w1# f1 = w1(f1),后执行
@w2 # f1 = w2(f1),先执行
def f1():
print("---f1---")
f1()#结果
---正在装饰2---
---正在装饰1---
---正在验证权限1---
---正在验证权限2---
---f1---
使用装饰器对有参数的函数进行装饰
def func(functionName):
print("---func---1---")
def func_in(a,b):#注意这里写法
print("---func_in---1---")
functionName(a,b)#注意这里写法
print("---func_in---2---")
print("---func---2---")
return func_in
@func
def test(a,b):
print("---test-a=%d,b=%d---"%(a,b))
test(11,22)
#使用装饰器对可变长参数函数进行装饰
def func(functionName):
print("---func---1---")
def func_in(*args,**kwargs):#注意这里写法
print("---func_in---1---")
functionName(*args,**kwargs)#注意这里写法
print("---func_in---2---")
print("---func---2---")
return func_in
@func
def test(a,b):
print("---test-a=%d,b=%d---"%(a,b))
test(11,22)