51、基于注解方式开发Spring WebFlux,实现生成背压数据,就是实现一直向客户端发送消息
★ Spring WebFlux的两种开发方式
1. 采用类似于Spring MVC的注解的方式来开发。
此时开发时感觉Spring MVC差异不大,但底层依然是反应式API。
2. 使用函数式编程来开发
★ 基于注解开发Spring WebFlux
开发上变化并不大,主要是处理方法的返回值可使用Mono或Flux,但并不强制使用Mono或Flux
WebFlux的变化主要是两点:
- 彻底抛弃Servlet API;
- 基于订阅-发布的异步机制。
这两点的区别主要体现在底层服务器能以较小的线程池处理更高的并发,从而提高应用的可伸缩性
WebFlux支持基于背压(back press)的反应式流。
什么是背压:
这个是Reactive(反应) 的概念,当订阅者的消费能力,远低于发布者时,订阅者(也就是消费者)有通知取消或终止发布者生产数据的机制,这种机制可以称作为“背压”。
说白了就是:当消费者消费积压的时候,反向告诉推送生产者,我不需要你生产了,你慢点,这个叫背压。
比如这个.onBackpressureDrop() 方法,用来给方法开启背压处理功能,机制就是当发布者发送过多的消息给订阅者,订阅者处理不过来的时候,就会把一些数据丢掉,以保证程序不会崩溃。
代码演示:
用 spring webFlux 演示 springmvc 做不到的一个背压功能,就是消息的发布者可以不断的向消息的订阅者推送消息。就是一直向客户端发送消息。
需求:每隔5秒推送消息到客户端。
创建项目的时候,之前是勾选 Spring Web ,是基于Spring MVC 的,现在要勾选这个 Spring Reactive Web ,是基于反应式的。
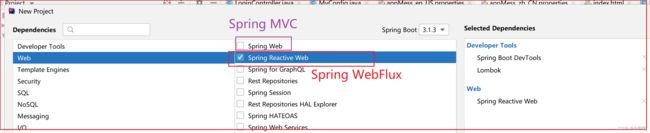
如图:
可以看出 Spring WebFlux 是集成了 Reactor框架 / 基于Reactor框架
Spring WebFlux 和 Reactor 底层默认使用 Netty 作为Web服务器
Spring MVC 是使用 Tomcat 作为 Web 服务器
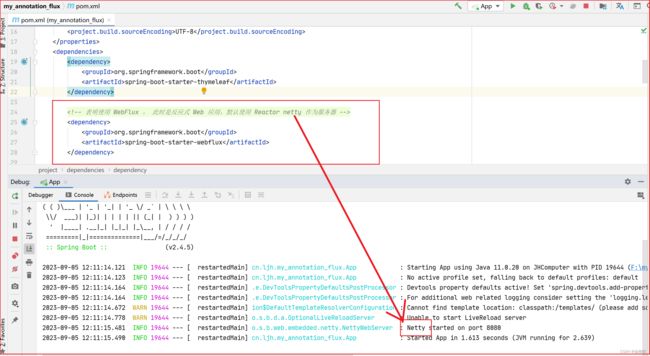
简单写一个通过id查询书本的流程,数据库用 Map 集合代替:
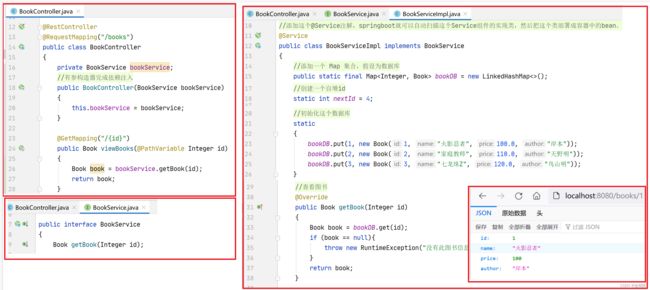
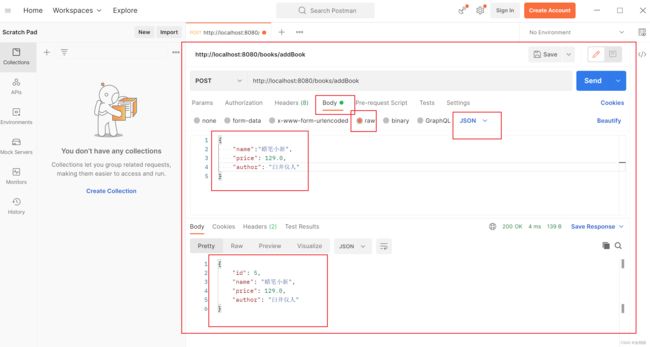
写一个添加书籍的方法,postMapping提交类型,用 postman测试
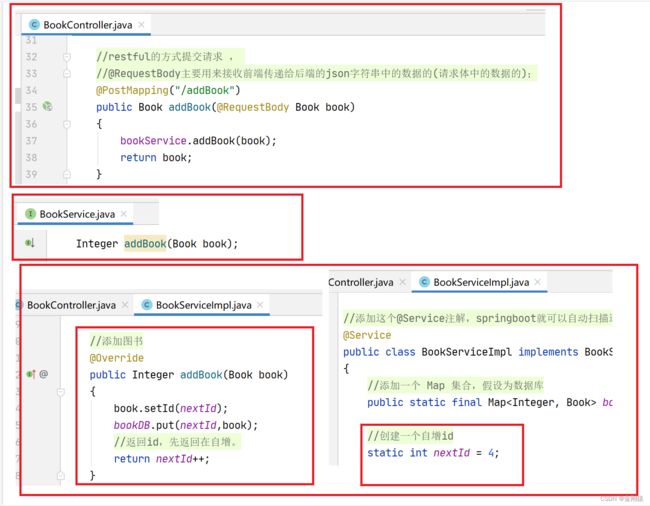
在这里写一个 书籍对象数据,用json格式提交,
后端用 @RequestBody 注解修饰的对象来接收数据。
public Book addBook(@RequestBody Book book){}
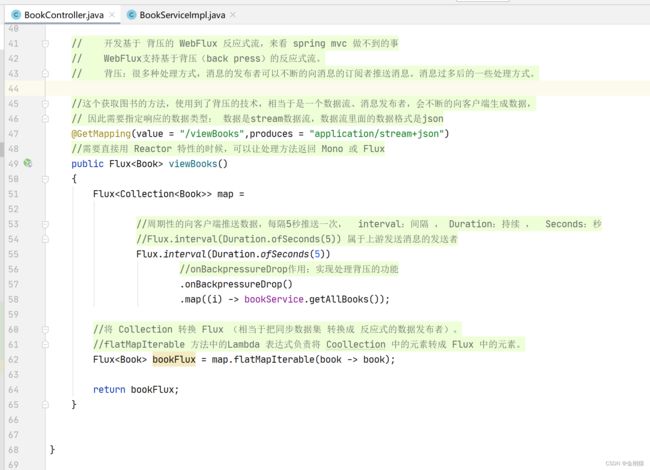
重点是这个方法,体现背压,就是一直向客户端发送数据
代码弄简洁点:

一些注释:
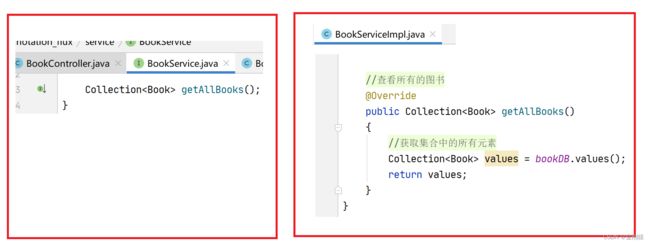
后面的查看所有书本的代码。
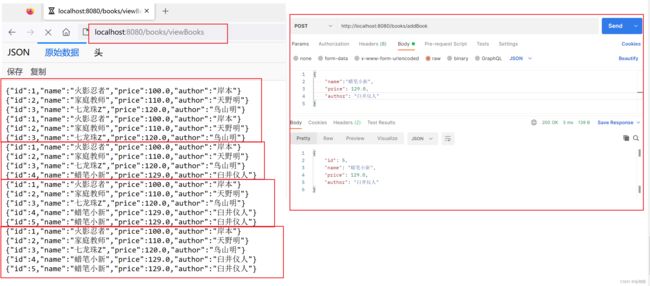
功能实现:
需求:每隔5秒推送消息到客户端。
在项目运行的时候 ,插入一条书本数据,可以看出的确是每5秒执行一次查询,然后向客户端推送数据。
这就是 spring mvc 无法实现的 背压功能。
如果把项目改成 spring mvc ,那么Flux 这个就不能用了。
通过依赖把 spring-boot-starter-webflux
改成 spring-boot-starter-web
就是把 spring webflux 改成 spring mvc 框架
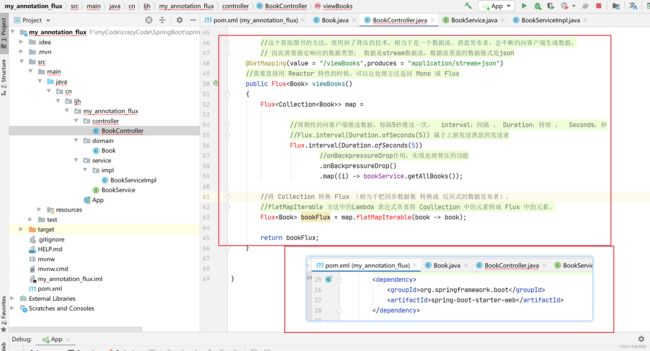
完整代码
pom依赖:
<!-- 表明使用 WebFlux , 此时是反应式 Web 应用,默认使用 Reactor netty 作为服务器 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
domain
package cn.ljh.my_annotation_flux.domain;
import lombok.Data;
@Data
public class Book
{
private Integer id;
private String name;
private double price;
private String author;
public Book(Integer id, String name, double price, String author)
{
this.id = id;
this.name = name;
this.price = price;
this.author = author;
}
}
BookController
package cn.ljh.my_annotation_flux.controller;
import cn.ljh.my_annotation_flux.domain.Book;
import cn.ljh.my_annotation_flux.service.BookService;
import org.springframework.web.bind.annotation.*;
import reactor.core.publisher.Flux;
import java.time.Duration;
import java.util.Collection;
@RestController
@RequestMapping("/books")
public class BookController
{
private BookService bookService;
//有参构造器完成依赖注入
public BookController(BookService bookService)
{
this.bookService = bookService;
}
@GetMapping("/{id}")
public Book viewBooks(@PathVariable Integer id)
{
Book book = bookService.getBook(id);
return book;
}
//restful的方式提交请求 ,
// @RequestBody主要用来接收前端传递给后端的json字符串中的数据的(请求体中的数据的);
@PostMapping("/addBook")
public Book addBook(@RequestBody Book book)
{
bookService.addBook(book);
return book;
}
// 开发基于 背压的 WebFlux 反应式流,来看 spring mvc 做不到的事
// WebFlux支持基于背压(back press)的反应式流。
// 背压:很多种处理方式,消息的发布者可以不断的向消息的订阅者推送消息。消息过多后的一些处理方式。
//这个获取图书的方法,使用到了背压的技术,相当于是一个数据流、消息发布者,会不断的向客户端生成数据,
// 因此需要指定响应的数据类型: 数据是stream数据流,数据流里面的数据格式是json
@GetMapping(value = "/viewBooks",produces = "application/stream+json")
//需要直接用 Reactor 特性的时候,可以让处理方法返回 Mono 或 Flux
public Flux<Book> viewBooks()
{
Flux<Collection<Book>> map =
//周期性的向客户端推送数据,每隔5秒推送一次, interval:间隔 , Duration:持续 , Seconds:秒
//Flux.interval(Duration.ofSeconds(5)) 属于上游发送消息的发送者
Flux.interval(Duration.ofSeconds(5))
//onBackpressureDrop作用:实现处理背压的功能
.onBackpressureDrop()
.map((i) -> bookService.getAllBooks());
//将 Collection 转换 Flux (相当于把同步数据集 转换成 反应式的数据发布者)。
//flatMapIterable 方法中的Lambda 表达式负责将 Coollection 中的元素转成 Flux 中的元素。
Flux<Book> bookFlux = map.flatMapIterable(book -> book);
return bookFlux;
}
}
BookService
package cn.ljh.my_annotation_flux.service;
import cn.ljh.my_annotation_flux.domain.Book;
import java.util.Collection;
public interface BookService
{
Book getBook(Integer id);
Integer addBook(Book book);
Collection<Book> getAllBooks();
}
BookServiceImpl
package cn.ljh.my_annotation_flux.service.impl;
import cn.ljh.my_annotation_flux.domain.Book;
import cn.ljh.my_annotation_flux.service.BookService;
import org.springframework.stereotype.Service;
import java.util.*;
//添加这个@Service注解,springboot就可以自动扫描这个Service组件的实现类,然后把这个类部署成容器中的bean。
@Service
public class BookServiceImpl implements BookService
{
//添加一个 Map 集合,假设为数据库
public static final Map<Integer, Book> bookDB = new LinkedHashMap<>();
//创建一个自增id
static int nextId = 4;
//初始化这个数据库
static
{
bookDB.put(1, new Book(1, "火影忍者", 100.0, "岸本"));
bookDB.put(2, new Book(2, "家庭教师", 110.0, "天野明"));
bookDB.put(3, new Book(3, "七龙珠Z", 120.0, "鸟山明"));
}
//查看图书
@Override
public Book getBook(Integer id)
{
Book book = bookDB.get(id);
if (book == null){
throw new RuntimeException("没有此图书信息!");
}
return book;
}
//添加图书
@Override
public Integer addBook(Book book)
{
book.setId(nextId);
bookDB.put(nextId,book);
//返回id,先返回在自增。
return nextId++;
}
//查看所有的图书
@Override
public Collection<Book> getAllBooks()
{
//获取集合中的所有元素
Collection<Book> values = bookDB.values();
return values;
}
}
.onBackpressureDrop() 作用
查 .onBackpressureDrop() 这个方法的作用:
