爬虫:从入门到入狱,进去一起做兄弟
〇、从入门到入狱
中国爬虫违法违规案例汇总[1]

一、什么是爬虫

二、爬虫的分类
搜索引擎:百度、谷歌
数据采集:天眼查、企查查
薅羊毛:抢票机器人、秒杀软件,比价软件,微博僵尸粉
……
三、爬虫与反爬虫
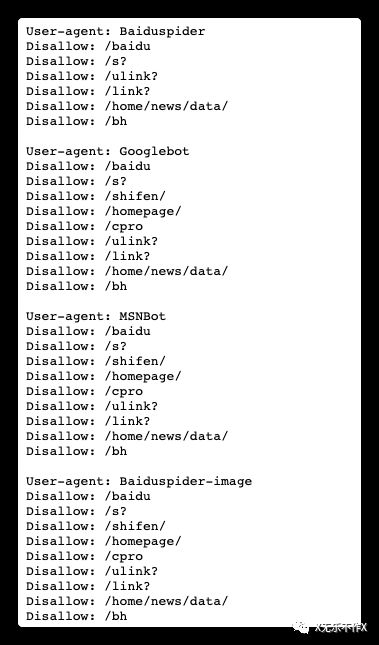
- 1. 君子协议:robots.txt
www.baidu.com/robots.txt[2]
-
- 最简单的爬虫
Python版
import requests rsp = requests.get('http://www.httpbin.org/user-agent')
Java版
@Test public void testHttpclient() throws IOException { CloseableHttpClient client = HttpClientBuilder.create().build(); HttpGet get = new HttpGet("http://www.httpbin.org/user-agent"); CloseableHttpResponse response = client.execute(get); HttpEntity entity = response.getEntity(); String string = EntityUtils.toString(entity); System.out.println(string); } @Test public void testHtmlUnit() throws IOException { WebClient edge = new WebClient(BrowserVersion.FIREFOX); edge.getOptions().setCssEnabled(false); edge.getOptions().setJavaScriptEnabled(true); edge.getOptions().setThrowExceptionOnFailingStatusCode(false); edge.getOptions().setThrowExceptionOnScriptError(false); edge.waitForBackgroundJavaScript(600*1000); UnexpectedPage page = edge.getPage("http://www.httpbin.org/user-agent"); System.out.println(page.getWebResponse().getContentAsString()); }
加入依赖
org.apache.httpcomponents httpclient 4.5.3 net.sourceforge.htmlunit htmlunit 2.45.0
但是这样的爬虫很容易通过检测UA头被发现,服务器就可以对这样的爬虫做出反爬的措施。
-
- 修改爬虫的UA
Python版
header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36' } rsp = requests.get('http://www.httpbin.org/user-agent', headers = header)
Java版
@Test public void testHttpclient() throws IOException { CloseableHttpClient client = HttpClientBuilder.create().build(); HttpGet get = new HttpGet("http://www.httpbin.org/user-agent"); get.setHeader("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36"); CloseableHttpResponse response = client.execute(get); HttpEntity entity = response.getEntity(); String string = EntityUtils.toString(entity); System.out.println(string); }
-
- 控制爬虫的频率
修改UA只是第一步,服务器还会针对每个ip地址的请求频率来识别爬虫,比如一分钟内请求几百几千次,一天24小时不间断的请求,这些特征都可以被识别为爬虫程序。所以在大规模抓取数据时,需要对降低抓取频率,比如每次请求后sleep 3~5 秒;但是这样会大大降低抓取的效率,所以这里就需要用到代理IP池——当然也可以通过部署集群的方式来提高爬的速度
代理服务器会转发爬虫请求,这样服务器针对IP的限制就会被绕过。
proxy = { 'http': '', 'https': '' } header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36' } rsp = requests.get('http://www.httpbin.org/user-agent', headers = header, proxies = proxy)
代理IP分透明代理,匿名代理和高匿代理,透明代理其实并不会隐藏爬虫的真实IP,匿名代理会在请求头里带上爬虫的IP,有一定几率会被识别,高匿代理则会完全隐藏爬虫的IP,更推荐使用。
据说现在互联网上50%以上的流量都是由爬虫产生的,针对一些热门资源这一比例可以高达98%以上。针对这种情况,服务器会需要用户登录才能访问,而简单的登录验证就是将浏览器上的cookie和服务器session绑定起来。
-
- 验证码(Completely Automated Public Turing test to tell Computers and Humans Apart,简称CAPTCHA)
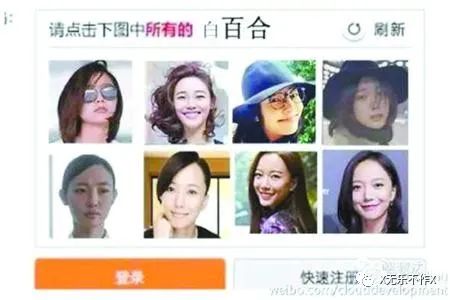

对于简单的字母和数字组成的验证码,可以通过自己训练模型来识别,或者使用第三方的打码平台来验证。

def bypassWithDama(): rec_url = "http://pred.fateadm.com" tm = str(int(time.time())) sign = CalcSign(pd_id, pd_key, tm) asign = CalcSign(app_id, app_key, tm) param = { "user_id": pd_id, "timestamp": tm, "appid": app_id, "sign":sign, "asign": asign, "predict_type": "30600", "up_type": "mt" } url = rec_url + "/api/capreg" img_data = open('/Users/xuhang/Desktop/captcha.jpeg', 'rb') files = { "img_data": ('img_data', img_data) } header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36' } rsp_data = requests.post(url, param, files=files, headers=header) print('【斐斐打码】' + rsp_data.text) return rsp_data.json() // 【斐斐打码】{"RetCode":"0","ErrMsg":"","RequestId":"20220303110050322d81ed0007a58386","RspData":"{\"result\": \"yfx5\"}"}
对于像Google的CAPTCHA或者 Intuition的hCaptcha或者arkoselabs的FunCaptcha,这类复杂的验证码,需要识别图片中的物品并点击符合要求的图片,或者将图片旋转到正确的角度,可以使用打码平台的人工打码,由人工完成后将结果返回。
-
- 带上登录后的cookie
对于一般安全性不强的网站,并没有针对登录验证做太多的设计,所以爬虫很容易就能实现带cookie访问。
header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36' } url = 'https://store.steampowered.com/account/' rsp = requests.get(url, headers=header, verify=False)
将响应的文本复制到文件中保存为html格式,然后用浏览器打开,虽然是乱码,但是可以看到Login的按钮,说明是未登录的状态。登录steam之后将请求中的cookie复制出来,修改header后再次请求
header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.66 Safari/537.36', 'Cookie': '...' }
可以从页面中找到该账号绑定的邮箱和余额等信息,说明登录成功。虽然可以爬到有限制的信息,但是爬虫和账号绑定了,这里代理就不起作用了,频繁爬取的话可能会导致被封号,这里就需要准备多个账号了,好在爬虫可以代替人工申请账号,只是成本会高一些。
虽然上面的操作或多或少可以骗过服务器的检测,但是相比与真实的浏览器,爬虫程序还是会在很多方面存在差异。比如真是浏览器通常会有document,setInterval等对象,爬虫程序缺少这些对象可能会导致某些关键性步骤无法执行,从而被服务器识别出来。另外有些网站需要post提交请求数据,但是某些必需的参数又是经过各种复杂加密混淆之后的结果,有时候可能追踪一个参数忙碌了好几天,成功的爬取了一天,第二天网站改参数了。针对这种情况,我们可以使用真实的浏览器的爬取。
如果是个人网站的站长,通常没有过多的精力来对抗爬虫,简单点的方法就是上面的随机生成验证码,然后加点干扰线。或者接入第三方的验证码平台,比如极验。但是验证码通常只用在有敏感操作的地方,不可能每个请求都要验证码,这时就可以使用网页防火墙之类的服务,通过检查客户端的引擎和一些特征来识别是不是爬虫,这样就可以拦截大部分的爬虫了。
该防火墙最开始是通过浏览器的引擎进行一些计算任务,只有计算正确才能成功跳转,但是已经有人成功用python模拟了计算过程,目前使用的是hCaptcha的验证码。


-
- headless浏览器

PhantomJS[3]是一个可以执行javascript脚本的无头网页浏览器,由于Chrome浏览器在17年开始支持无头模式,PhantomJS的作者已经停止维护了,推荐大家去使用Chrome。
下面是PhantomJS的一个demo
var page = require('webpage').create(); page.open('http://www.google.com', function() { setTimeout(function() { page.render('google.png'); phantom.exit(); }, 200); });
这里推荐使用Selenium,这个工具可以驱动Chrome、Firefox、IE、Safari、Opera和PhantomJS,并且提供多种语言的版本,只需要安装相应的浏览器并指定浏览器的驱动路径即可。
# -*- coding: utf-8 -*- from selenium import webdriver import time from selenium.webdriver.common.keys import Keys from selenium.webdriver import ActionChains """ 如果控制台出现乱码,尝试修改编码格式:chcp <编码> 65001 UTF-8 950 繁体中文 936 GBK 437 MS-DOS """ options = webdriver.ChromeOptions() # 以Headless模式启动 # options.add_argument('headless') # 窗口大小(通过截图可以反映窗口大小) options.add_argument('window-size=1200x600') # 设置User-Agent options.add_argument('user-agent=Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36') # 创建实例 browser = webdriver.Chrome(chrome_options = options, executable_path='/Users/xuhang/Downloads/chromedriver') # 窗口最大化 browser.maximize_window() # Part Ⅰ # 请求网址 browser.get(url = "https://www.smzdm.com") time.sleep(2) # 截图 browser.save_screenshot('smzdm_1.png') # 下拉滑动页面 - 通过JS脚本 browser.execute_script("window.scrollTo(10000, document.body.scrollHeight)") # 下拉滑动页面 - 通过模拟鼠标移动 # from selenium.webdriver.support.wait import WebDriverWait # WebDriverWait(browser, 20, 0.5).until(lambda x: x.find_element_by_id('feed-main-list')) # actionChain = browser.find_element_by_css_selector("#feed-main-list li:last-child") # ActionChains(browser).move_to_element(actionChain).perform() browser.save_screenshot('smzdm_2.png') # 新开窗口打开百度首页 browser.execute_script("window.open('https://www.baidu.com')") handlers = browser.window_handles # print(handlers) # 切换到第2个窗口 browser.switch_to_window(handlers[1]) # 在第2个窗口操作 browser.find_element_by_id('kw').send_keys('selenium') browser.find_element_by_id('su').click() # 获取cookies cookies = browser.get_cookies() cookie = browser.get_cookie('BAIDUID') time.sleep(2) browser.save_screenshot('baidu_1.png') browser.switch_to_window(handlers[0]) time.sleep(2) print(cookie) browser.quit()
到这里,配合上代理IP和账号登陆已经可以绕开大部分的网站验证了,但是即使用上了真实的浏览器,Selenium操控的浏览器还是会暴露出一部分特征。比如window.navigator.webdriver属性,这个属性是正常浏览器没有的,但是Chrome Headless里有,虽然可以通过参数关闭该属性,但是仍有其他属性会暴露出来。
除了以上用到的Selenium,还有Pupperteer和Python版本的Pypperteer,器中Pupperteer是Google官方推出的基于Chrome DevTool protocol 协议的Nodejs包,通常在Selenium失败之后尝试使用Pupperteer,还是不行可以考虑开发Chrome的插件来爬,因为Chrome插件是运行在真正的浏览器上面,和平时使用的一样,它还能使用浏览器以往的缓存,不容易被识别出来。

四、扩展
反爬虫除了在服务端对可疑请求进行拦截,还可以在客户端增加爬虫的开发难度,其中就包括代码混淆、干扰调试、数据投毒、图片替换数据、字体乱序。
-
- 代码混淆
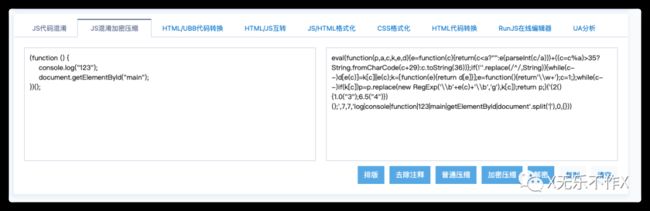
base62加密最明显的特征是以eval(function(p,a,c,k,e,r))开头,这样加密后的代码没有可读性,对于不熟悉此加密的人有一定难度,但是由于此方法最终要执行eval方法,所以只需要通过console.log将内容打印出来就是加密前的代码。
-
- 干扰调试
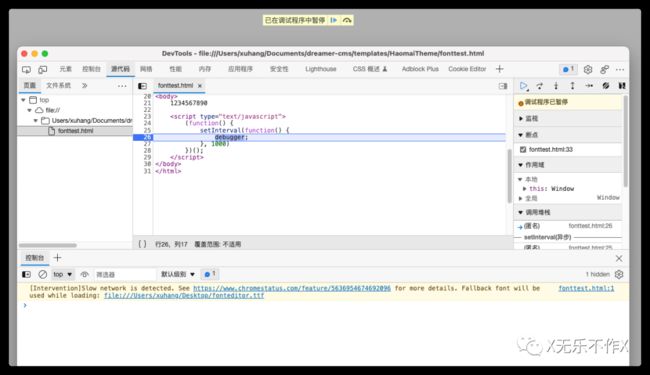
由于爬虫必须通过找出数据接口才能进行数据抓取,对于浏览器最基础的操作就是打开DevTools来分析请求和数据,所以一旦发现用户打开DevTools就可以做一些干扰来增加难度。比如debugger;本来是开发人员用来在调试代码时使用的命令,该命令会强制在此处打断点,所以可以对爬虫的开发人员进行一定的干扰。但是此方法也可以通过浏览器的停用断点使其失效。类似的方法还有检测到DevTools后立即删除所有关键的信息,这样也就不会暴露数据接口了。(微信读书用到了此方法)
-
- 数据投毒
此方法会有一定几率误伤到正常用户,所以使用得很少,而且使用也必须很谨慎。如果后台在检测到是爬虫之后,将原本正确的数据替换掉,让爬虫拿到的是毫无意义的数据,这样爬虫方就会因为这些异常数据做出错误的策略。
-
- 图片替换
因为爬虫主要抓取的是文本类型的数据,比如价格、邮箱等,而爬虫处理文本数据的成本是很低的。如果将关键的数据用图片进行替换,图片上展示的是正常的数据,这样不会对正常访问的用户造成影响,只会增加爬虫获取数据的难度。
-
- 字体乱序
这种方法和数据投毒的效果类似,但是不会误伤正常访问的用户。具体操作是在页面上加载乱序过的字体文件,但是乱序的规则后台是知道的,后台在返回数据的时候只要根据乱序的规则做一次反向的替换,就能让html的源数据和页面上展示的不一致,而爬虫是根据html源里的数据来进行处理的。
在线字体编辑器-JSON在线编辑器 (qqe2.com)[4]

这个字体文件里,数字7和1交换了顺序(为演示方便,只乱序了2个数字,通常是越乱越好),在页面上定义这个字体并指定文件路径,然后使用定义的字体。

源文件里的数字是1234567890,页面上展示的是7234561890。


对于中文也是类似的,只不过中文字符过多,乱序之后映射关系复杂,会让维护变得困难。
题外话
“不是只有程序员才要学编程?!”
认真查了一下招聘网站,发现它其实早已变成一项全民的基本技能了。
连国企都纷纷要求大家学Python!

世界飞速发展,互联网、大数据冲击着一切,各行各业对数据分析能力的要求越来越高,这便是工资差距的原因,学习编程顺应了时代的潮流。
在这个大数据时代,从来没有哪一种语言可以像Python一样,在自动化办公、爬虫、数据分析等领域都有众多应用。
更没有哪一种语言,语法如此简洁易读,消除了普通人对于“编程”这一行为的恐惧,从小学生到老奶奶都可以学会。
《2020年职场学习趋势报告》显示,在2020年最受欢迎的技能排行榜,Python排在第一。

它的角色类似于现在Office,成了进入职场的第一项必备技能。
如果你也想增强自己的竞争力,分一笔时代的红利,我的建议是,少加点班,把时间腾出来,去学一学Python。
因为,被誉为“未来十年的职场红利”的Python,赚钱、省钱、找工作、升职加薪简直无所不能!
目前,Python人才需求增速高达**174%,人才缺口高达50万,**部分领域如人工智能、大数据开发, 年薪30万都招不到人!
感兴趣的小伙伴,赠送全套Python学习资料,包含面试题、简历资料等具体看下方。
CSDN大礼包:全网最全《Python学习资料》免费赠送!(安全链接,放心点击)

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典


简历模板