数据结构——图——弗洛伊德(Floyd)算法
数据结构——图——弗洛伊德(Floyd)算法
为了能讲明白弗洛伊德(Flbyd)算法的精妙所在,我们先来看最简单的案例。图7-7-12的左图是一个最简单的3个顶点连通网图。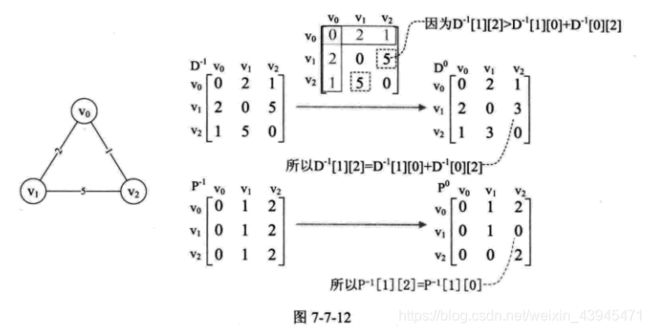
我们先定义两个二维数组D[3][3]和P[3][3],D代表顶点到顶点的最短路径权值和的矩阵。P代表对应顶点的最小路径的前驱矩阵。在未分析任何顶点之前,我们将D命名为D-1,其实它就是初始的图的邻接矩阵。将Р命名为P-1,初始化为图中所示的矩阵。
首先我们来分析,所有的顶点经过V0后到达另一顶点的最短路径。因为只有三个顶点,因此需要查看V1→V0→V2,得到D-1[1][0]+D-1 [0][2]=2+1=3。D-1[1][2]表示的是V1→V2的权值为5,我们发现D-1[1][2]>D-1[1][0]+D-1 [0][2],通俗的话讲就是V1→V0→V2比直接V1→V2距离还要近。所以我们就让D-1[1][2]= D-1[1][0]+D-1[0][2]=3,同样的D-1[2][1]=3,于是就有了D-0的矩阵。因为有变化,所以Р矩阵对应的P-1[1][2]和P-1[2][1]也修改为当前中转的顶点V0的下标0,于是就有了P。也就是说

接下来,其实也就是在D-0和P-0的基础上继续处理所有顶点经过V1和V2后到达另一顶点的最短路径,得到D-1和P-1、D-2和P-2完成所有顶点到所有顶点的最短路径计算工作。
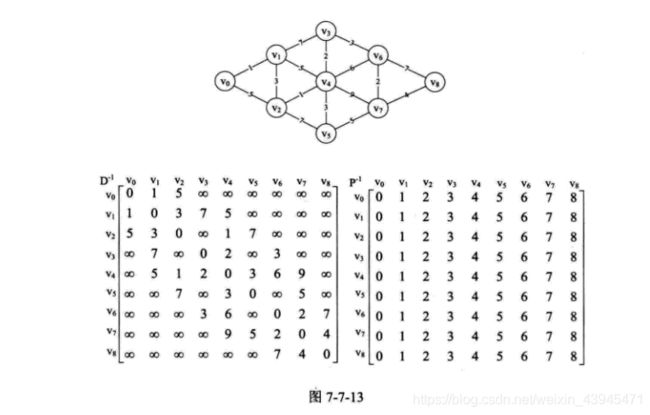
如果我就用这么简单的图形来讲解代码,大家一定会觉得不能说明什么问题。所以我们还是以前面的复杂网图为例,来讲解弗洛伊德(Flbyd)算法。
首先我们针对图7-7-13的左网图准备两个矩阵D-1和P-1,D-1就是网图的邻接矩阵,P-1初设为P[i][们]=j这样的矩阵,它主要用来存储路径。
代码如下,注意因为是求所有顶点到所有顶点的最短路径,因此 Pathmatirx和ShortPathTable都是二维数组。
typedef struct
{
VertexType vexs[MAXVEX]; /*顶点表*/
EdgeType matirx[MAXVEX][MAXVEX]; /*领边矩阵,可看作边表*/
int numVertexes, numEdges; /*图中当前的顶点数和边数*/
} MGraph;
typedef int Pathmatirx[MAXVEX][MAXVEX]; /*用于存储最短路径下标的数组*/
typedef int ShortPathTable[MAXVEX][MAXVEX]; /*用于存储到各点最短路径的权值和*/
/*Floyd算法,求网图G中各顶点V到其余顶点w最短路径p[v][w]及带权长度D[v][w]*/
void ShortestPath_Floyd(MGraph G, Pathmatirx* P, ShortPathTable* D)
{
int v, w, k;
for (v=0;v<G.numVertexes;++v)
{
for (w = 0; w < G.numVertexes; ++w)
{
(*D)[v][w] = G.matirx[v][w]; /*(*D)[v][w]值即为对应点间的权值*/
(*P)[v][w] = w; /*初始化P*/
}
}
for (k=0;k< G.numVertexes;++k)
{
for (v = 0; v < G.numVertexes; ++v)
{
for (w = 0; w < G.numVertexes; ++w)
{
if ((*D)[v][w]>(*D)[v][k]+ (*D)[k][w])
{
/*如果经过下标为K顶点路径比原点间路径更短*/
/*将当前两点间权值设为更小的一个*/
(*D)[v][w] = (*D)[v][k] + (*D)[k][w];
(*P)[v][w] = (*P)[v][k];/*路径设置经过下标为k的顶点*/
}
}
}
}
}


1.程序开始运行,第4~11行就是初始化了D和P,使得它们成为图7-7-13的两个矩阵。从矩阵也得到,V0→V1路径权值是1,V0→V2路径权值是5,V0→V3无边连线,所以路径权值为极大值65535。
2.第12~25行,是算法的主循环,一共三层嵌套,k 代表的就是中转顶点的下标。v代表起始顶点,w代表结束顶点。
3.当 K=0时,也就是所有的顶点都经过V0中转,计算是否有最短路径的变化。可惜结果是,没有任何变化,如图7-7-14所示。
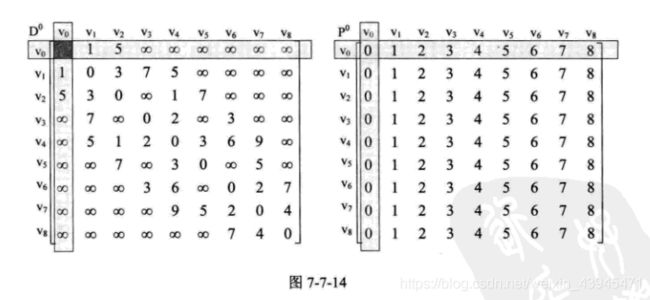
4.当K=1 时,也就是所有的顶点都经过V1中转。此时,当 V=0时,原本D[0][2]=5,现在由于 D[0][1]+D[1][2]=4。因此由代码的第20行,二者取其最小值,得到 D[0][2]=4,同理可得 D[0][3]=8、D[0][4]=6,当v=2、3、4时,也修改了一些数据,请参考如图7-7-15左图中虚线框数据。由于这些最
小权值的修正,所以在路径矩阵P上,也要作处理,将它们都改为当前的P[v][k]值,见代码第21行。

5.接下来就是 k=2一直到8结束,表示针对每个顶点做中转得到的计算结果,当然,我们也要清楚,D-0是以D-1为基础,D-1是以D-0为基础,……,D-8是以D-7为基础,就像我们曾经说过的七个包子的故事,它们是有联系的,路径矩阵Р也是如此。最终当k=8时,两矩阵数据如图7-7-16所示。

至此,我们的最短路径就算是完成了,你可以看到矩阵第vo行的数值与迪杰斯特拉(Dijkstra)算法求得的D数组的数值是完全相同,都是{0,1,4,7,5,8,10,12,16}。而且这里是所有顶点到所有顶点的最短路径权值和都可以计算出。
那么如何由P这个路径数组得出具体的最短路径呢?以V0到V8为例,从图7-7-16的右图第V8列,P[0][8]=1,得到要经过顶点V1,然后将1取代0得到P[1][8]=2,说明要经过V2,然后将2取代1得到P[2][8]=4,说明要经过V4,然后将4取代2得到P[4][8]=3,说明要经过V3,……,这样很容易就推导出最终的最短路径值为V0→V1→V2→V4→V3→V6→V7→V8
求最短路径的显示代码可以这样写。
for ( v = 0; v < G.numVertexes; ++v)
{
for (w = v+1; w < G.numVertexes; w++)
{
printf("v%d-v%d weight: %d", v, w, D[v][w]);
k = P[v][w]; /*获得第一个路径顶点下标*/
printf("path:%d",v); /*打印源点*/
while (k!=w) /*如果路径顶点下标不是终点*/
{
printf("->%d", k); /*打印路径顶点*/
k = P[k][w]; /*获得下一个路径顶点下标*/
}
printf("-> %d\n", w); /*打印终点*/
}
printf("\n");
}
再次回过头来看看弗洛伊德 (Flbyd)算法,它的代码简洁到就是一个二重循环初始化加一个三重循环权值修正,就完成了所有顶点到所有顶点的最短路径计算。几乎就如同是我们在学习C语言循环嵌套的样例代码而已。如此简单的实现,真是巧妙之极,在我看来,这是非常漂亮的算法,不知道你们是否喜欢?很可惜由于它的三重循环,因此也是 O(n3)时间复杂度。如果你面临需要求所有顶点至所有顶点的最短路径问题时,弗洛伊德(Floyd)算法应该是不错的选择。
另外,我们虽然对求最短路径的两个算法举例都是无向图,但它们对有向图依然有效,因为二者的差异仅仅是邻接矩阵是否对称而已。