Caffe源码精读 - 3 - Caffe Layers之conv_layer(卷积层)
Caffe Layers之conv_layer(卷积层)
概述
卷积层是组成卷积神经网络的基础应用层,也是最常用的层部件。而卷积神经网路有事当前深度学习的根本。在一般算法的Backbone、neck和head基本都是由卷积层组成。
1. 卷积操作
一般从数学角度讲,卷积分两个步骤,第一步做翻转,第二部乘积求和。 DL中的卷积操作是一种无翻转卷积,类似于相关操作。卷积的作用即是提取特征,通过一层层的卷积,使得特征被一步步浓缩。在卷积操作过程中,浅层卷积保留更多的描述信息,而深层卷积描述更多的抽象特征。
如下,描述了一个单通道输入矩阵(输入图像也是矩阵,不过是多通道(3通道))的计算过程。多通道卷积是将单通道卷积的结果对应相加,此处不过多赘述,很多资料中已经讲得很详细。
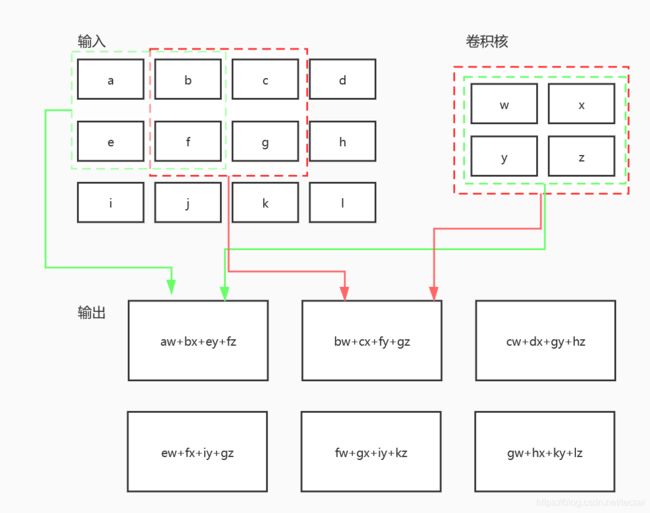
2. 卷积操作所涉及的参数
在进行卷积操作过程中,有一些参数是需要关注的。包括输入矩阵的shape, 卷积核w和h,输入矩阵pad信息,输入矩阵的dilation信息等。
其中在caffe中,输入矩阵的shape为NCHW模式,分别是batch size, 通道数,高,宽信息;卷积核的宽和高;输入矩阵的填充信息,输入矩阵的膨胀信息(一般都不膨胀)。
Caffe在处理卷积层时,为了便于使用cblas_sgemm做矩阵相乘计算,特意推导出出了一些既定的数据。包括im2col的数据,推导卷积后特征矩阵的W和H信息,通道信息,以及每个特征图数据总量等。
3. Caffe卷积层
Caffe在实现卷积层时,用了两个类,分别是base_conv_layer和conv_layer。其中base_conv_layer更底层,用于读进卷积层参数信息,设置卷积层参数(LayerSetUp),Reshape输入输出Blob(Reshape), 用于前向计算的矩阵乘法forward_cpu_gemm和forward_gpu_gemm, 计算权重矩阵的forward_cpu_bias和forward_cpu_bias,反向传播时使用到的矩阵计算backward_cpu_gemm和backward_gpu_gemm,反向时偏置计算backward_cpu_bias和backward_gpu_bias,用于计算权值偏差的weight_cpu_gemm和weight_gpu_gemm。接下来通过详细解读代码,看一看具体的操作流程。
4. LayerSetUp
LayerSetUp是卷积层的配置入口,通过读取Protobuf生成的数据(ConvolutionParameter),配置网络,得到一些预设的参数。
其中:
channel_axis_是卷积的通道轴的索引,在caffe中,数据一般是以NCHW的形式存在的,所以一般取值为1。
first_spatial_axis_是空间轴的第一个索引。一般caffe中将w和h轴称为空间轴。
num_axes是数据轴的总数,NCHW数据形制的话,一般取值为4。
num_spatial_axes_为空间轴数量,因为只有H和W,所以取值为2。
bottom_dim_blob_shape用来保存输入数据的shape信息。由于在进行计算时,只是输入CHW信息,参与计算,所以此处取值是num_spatial_axes_+1, 即当前初始化为三个int型的vector。
spatial_dim_blob_shape用来保存卷积核的shape信息。
接下来初始化kernel_shape_, 通过
kernel_shape_data[0] = conv_param.kernel_h(); ///< kernel高
kernel_shape_data[1] = conv_param.kernel_w(); ///< kernel宽
来指定了protobuf文件中指定的H和W信息。
stride_是卷积步长信息,是通过如下获得。
stride_data[0] = conv_param.stride_h();
stride_data[1] = conv_param.stride_w();
pad_是对卷积输入的x和y方向的填充信息,是通过如下获得。
pad_data[0] = conv_param.pad_h();
pad_data[1] = conv_param.pad_w();
dilation_是对卷积输入的膨胀操作信息,一般不膨胀,通过如下获得:
for (int i = 0; i < num_spatial_axes_; ++i) {
dilation_data[i] = (num_dilation_dims == 0) ? kDefaultDilation :
conv_param.dilation((num_dilation_dims == 1) ? 0 : i);
}
接下来是要判断当前卷积是否是1*1卷积,1*1卷积当前主要作用是维度的升降,如YOLOv3和YOLOv4中都有使用1*1卷积进行降维,以实现特征图的融合。

接下来是配置输入和输出的通道数

weight_shape是权值的shape,首先是初始化为两个成员,分别是conv_out_channels_和conv_in_channels/group_, 前者是卷积输出通道数,代表有几个权值核组,后者设group_=1来看,就是每个卷积核组中有几个卷积核,即是设置了卷积核的N和C信息。之后通过
for (int i = 0; i < num_spatial_axes_; ++i) {
weight_shape.push_back(kernel_shape_data[i]);
}
设置卷积核的H和W信息。
自此,卷积核的NCHW信息设置完毕。
bias_term_设置是否启用偏置项,偏置项的shape为(1, num_output_), 即每一个组数量是(1*输出卷积通道数)。
卷集中,blobs_[0]存储权值信息,blobs_[1]存储偏置项。
kernel_dim_表征一个权值组的总数据量。
weight_offset_表征一个卷机组(只对分组卷积起作用)的卷积核总量。
5. ReShape
ReShape模块主要是对卷积前后过程中的数据,进行shape的定义。
首先拿到第一个空间轴的索引,
const int first_spatial_axis = channel_axis_ + 1; ///< 通道轴索引+1,第一个空间轴索引
前面讲过,caffe中的数据形制是NCHW,通道轴索引是1,那么第一个空间轴索引应该是2.
num_是batch_size。
bottom_shape_是卷积输入的shape信息。
compute_output_shape()用来计算卷积输出的H和W信息。
top_shape是一个vector。
vector
top_shape.push_back(num_output_); ///< 输出通道数
for (int i = 0; i < num_spatial_axes_; ++i) { ///< 赋值输出的宽,高
top_shape.push_back(output_shape_[i]);
}
/** 将所有的输出reshape为上述的(N, C, H, W) */
for (int top_id = 0; top_id < top.size(); ++top_id) {
top[top_id]->Reshape(top_shape);
}
conv_out_spatial_dim_是指卷积输出大小,这个大小指的是卷积输出特征图的W*H,不要被这个dim迷惑了。在卷积层文件里,有很多dim是很具有迷惑性的。
bottom_dim_blob_shape定义了卷积输入的shape,操作如下:
vector
conv_input_shape_.Reshape(bottom_dim_blob_shape);
int* conv_input_shape_data = conv_input_shape_.mutable_cpu_data();
for (int i = 0; i < num_spatial_axes_ + 1; ++i) { ///< i = 0, 1, 2
if (reverse_dimensions()) {
conv_input_shape_data[i] = top[0]->shape(channel_axis_ + i); ///< conv_input_shape_data[0]: channel conv_input_shape_data[1]: height conv_input_shape_data[2]: width
} else {
conv_input_shape_data[i] = bottom[0]->shape(channel_axis_ + i);
}
}
col_buffer_shape_存储的是im2col之后的数据shape信息,对应的col_buffer_存储的是im2col之后的数据。
关于im2col是做什么,后面会另起一篇文章详细介绍。这里简单提一句,就是将一个卷积操作变成两个二维矩阵的矩阵相乘操作。
6. forward_cpu_gemm
forward_cpu_gemm从名字上能够猜出是一个利用CPU完成的矩阵相乘操作,适用于卷积层的前向过程。
最底层其实是调用的cblas_sgemm函数,是一个符合BLAS标准的矩阵相乘接口,此处是使用了GPU加速的实现。
cblas_sgemm(order, transA, transB, M, N, K, ALPHA, A, LDA, B, LDB, BETA, C, LDC);
函数作用:C=alpha*A*B+beta*C
alpha =1,beta =0 的情况下,等于两个矩阵相成。
第一参数 oreder 候选值 有ClasRowMajow 和ClasColMajow 这两个参数决定一维数组怎样存储在内存中,
一般用ClasRowMajow
参数 transA和transB :表示矩阵A,B是否进行转置。候选参数 CblasTrans 和CblasNoTrans.
参数M:表示 A或C的行数。如果A转置,则表示转置后的行数
参数N:表示 B或C的列数。如果B转置,则表示转置后的列数。
参数K:表示 A的列数或B的行数(A的列数=B的行数)。如果A转置,则表示转置后的列数。
参数LDA:表示A的列数,与转置与否无关。
参数LDB:表示B的列数,与转置与否无关。
参数LDC:始终=N
同理,后面还有很多用于前向或后向的矩阵操作或矩阵与向量操作,不在此赘述了。
3.2 conv_layer
conv_layer是卷积层的的顶层接口文件,分为两个文件,分别是cpp文件和cu文件。cpp文件即是使用CPU实现的版本,cu文件是使用cuda实现的GPU硬件加速版本。
conv_layer文件主要是实现了两个函数,分别是Forward_cpu/Forward_gpu和Backward_cpu/Backward_gpu。顾名思义就是实现了卷积层的前向和后向的具体操作。