【爬虫】7.4. 字体反爬案例分析与爬取实战
字体反爬案例分析与爬取实战
文章目录
- 字体反爬案例分析与爬取实战
-
- 1. 案例介绍
- 2. 案例分析
- 3. 爬取
本节来分析一个反爬案例,该案例将真实的数据隐藏到字体文件里,即使我们获取了页面源代码,也无法直接提取数据的真实值。
1. 案例介绍
案例网站为https://antispider4.scrape.center/,第一眼看这个网站没有啥特别的,那么我们先用selenium爬取一些信息,例如电影标题、类别、评分等,代码实现如下:
from selenium import webdriver
from pyquery import PyQuery as pq
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
browser = webdriver.Chrome()
browser.get('https://antispider4.scrape.center/')
WebDriverWait(browser, 10) \
.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.item')))
html = browser.page_source
doc = pq(html)
items = doc('.item')
for item in items.items():
name = item('.name').text()
categories = [o.text() for o in item('.categories button').items()]
score = item('.score').text()
print(f'name: {name} categories: {categories} score: {score}')
browser.close()
name: 霸王别姬 - Farewell My Concubine categories: ['剧情', '爱情'] score:
name: 这个杀手不太冷 - Léon categories: ['剧情', '动作', '犯罪'] score:
name: 肖申克的救赎 - The Shawshank Redemption categories: ['剧情', '犯罪'] score:
name: 泰坦尼克号 - Titanic categories: ['剧情', '爱情', '灾难'] score:
......
这里就出现问题了,我们的score字段没有任何信息,通过分析源代码,发现评分对应的节点内并不包含任何的数字信息:
<p data-v-090744c8="" class="score m-t-md m-b-n-sm"><span data-v-090744c8=""><i data-v-090744c8="" class="icon icon-789">i>span><span data-v-090744c8=""><i data-v-090744c8="" class="icon icon-981">i>span><span data-v-090744c8=""><i data-v-090744c8="" class="icon icon-504">i>span>p>
span节点里面什么信息都没有,那页面上的评分结果是怎么出来的?这其实是CSS的结果。
2. 案例分析
<i data-v-090744c8="" class="icon icon-789">
::before
i>
<i data-v-090744c8="" class="icon icon-981">
::before
i>
可以详细观察一下源代码,各个span节点的不同之处在于内部的i节点的class取值不太一样,我们可以看到有3个span节点,对应的class取值分别是icon-789,icon-981,icon-504;接着我们观察i节点的CSS样式可以发现i节点内部有一个::before字段,在CSS中,该字段用于创造一个伪节点,及这个i节点或者span节点不一样,::before可以往特定的节点中插入内容,同时在CSS中使用content字段定义这一个内容。我们可以在浏览器中追踪CSS源代码,代码文件如下所示:

点击右边的app.654ba59e.css:1,进入文件之后可以看到整个CSS源代码都在那里放着
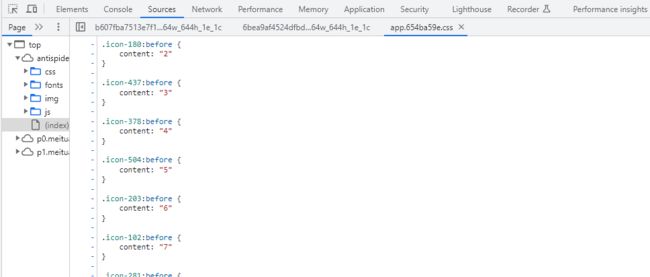
所以我们只需要读取CSS文件并提取映射关系,这个CSS文件就是:https://antispider4.scrape.center/css/app.654ba59e.css,下面是部分截图:

3. 爬取
我们可以用requests库读取结果,并通过正则表达式将映射关系提取出来,我们用findall方法对内容进行匹配,取出每一个关系赋值成字典即可,之后通过索引进行访问:
from selenium import webdriver
from pyquery import PyQuery as pq
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import re
import requests
url = 'https://antispider4.scrape.center/css/app.654ba59e.css'
response = requests.get(url)
pattern = re.compile('.icon-(.*?):before\{content:"(.*?)"\}')
results = re.findall(pattern, response.text)
icon_map = {item[0]: item[1] for item in results}
def parse_score(item):
elements = item('.icon')
icon_values = []
for element in elements.items():
class_name = (element.attr('class'))
icon_key = re.search('icon-(\d+)', class_name).group(1)
icon_value = icon_map.get(icon_key)
icon_values.append(icon_value)
return ''.join(icon_values)
browser = webdriver.Chrome()
browser.get('https://antispider4.scrape.center/')
WebDriverWait(browser, 10) \
.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '.item')))
html = browser.page_source
doc = pq(html)
items = doc('.item')
for item in items.items():
name = item('.name').text()
categories = [o.text() for o in item('.categories button').items()]
score = parse_score(item)
print(f'name: {name} categories: {categories} score: {score}')
browser.close()