JVM笔记-黑马-2
文章目录
- 视频资源地址
- 笔记资源地址
- 我的笔记
-
- 27.stringtable·面试题 + 28.常量池与串池的关系
- 29.字符串变量拼接
- 30.编译器优化
- 31.字符串延迟加载
- 32-33.stringtable_intern_1.8与1.6
- 34. string_table 面试题
- 35-36. string_table 位置
- 37. string_table 垃圾回收
- 38-40. string_table 性能调优
视频资源地址
B站 https://www.bilibili.com/video/av70549061
笔记资源地址
https://nyimac.gitee.io/
我的笔记
27.stringtable·面试题 + 28.常量池与串池的关系
首先写一段声明字符串的代码,通过反编译查看他的常量池的样子。
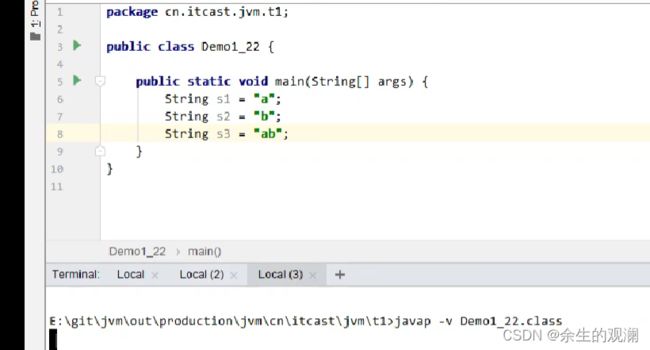
关键指令:javap -v class地址

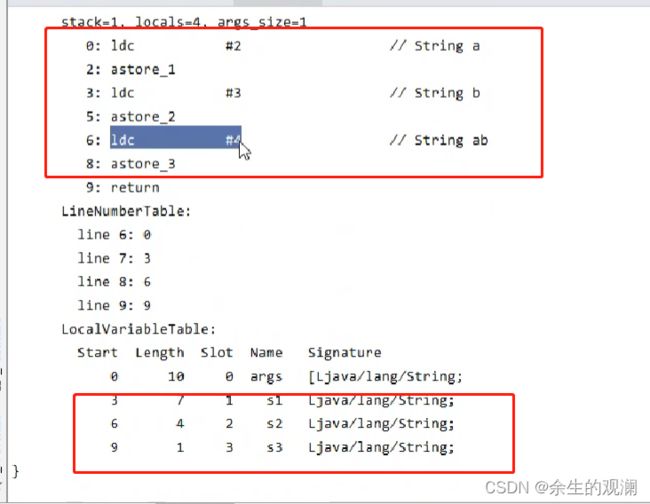
看字节码的内容,这一行:去常量池2位置中加载信息。 然后存入局部变量1中。如下图局部变量表。

以此类推,下图中三个变量都是这样加载进来,并赋值在局部变量表的。
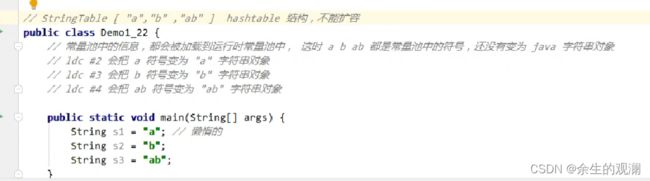
常量池是存在字节码文件中的,上面这个例子已经证明了,但是这个静态的,当它运行起来之后,就会被加载到运行时常量池。如下图这些都会被加载到运行时常量池: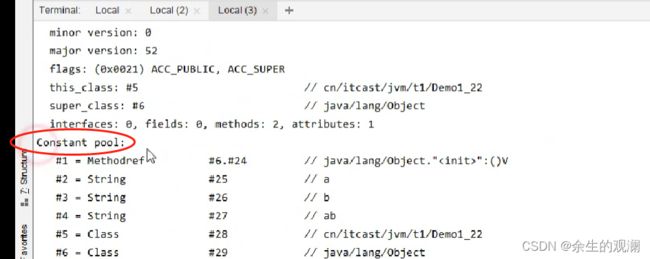
注意:
![]()
当字节码执行到ldc的时候,才会将符号跟java对象联系起来。
![]()
此时,会去查看Stringtable,。也就是所谓的串池,有没有包含a,如果不包含就加入进去。
这个行为是一个懒惰的行为,代码中用到这个对象,才会去串池中查找或者添加。
原文笔记:
29.字符串变量拼接
反编译之后如下图所示。相当于执行了注释中的操作。
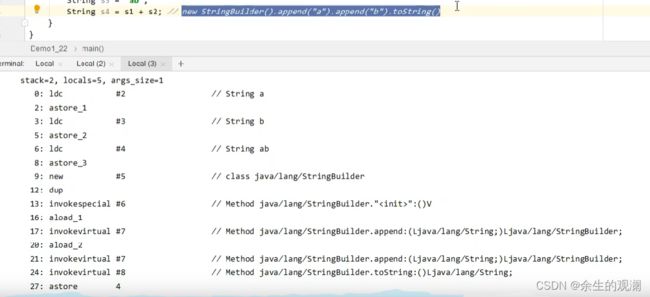
问题:
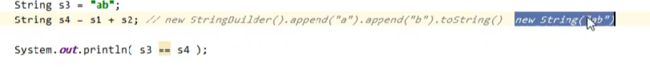
答案是fasle。因为s3在串池里,s4在堆里。 tostring方法的本质是调用了new string(“ab”) 方法。他俩的位置不一样,是两个对象。
30.编译器优化
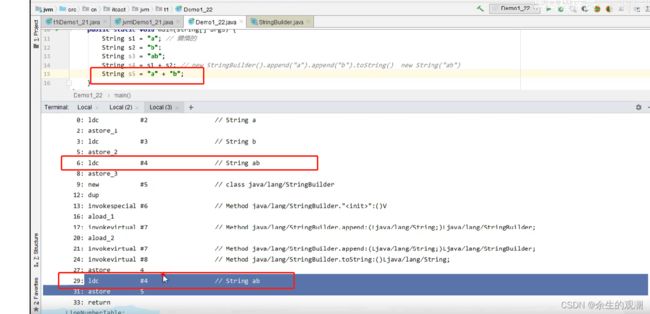
新建一个string s5 = “a” + “b”; 然后反编译。
他是直接去常量池中加载的#4这个常量。并且存入了5号局部变量表。
所以s3和s5的变量都是存储的串池中的同一个字符串常量,所以他俩是相等的。
“a” + “b” 是 javac在编译期的优化。 这俩都是常量,相加不会变了,结果在编译期间已经确定为“ab”。
跟s4不一样,s4的生成是两个变量相加,需要动态拼接。就到了堆中了。
31.字符串延迟加载

上面这个例子。只会在串池中创建10个对象,再下面继续打印,就是用的串池中的了。
32-33.stringtable_intern_1.8与1.6

调用字符串对象的intern方法,会将该字符串对象尝试放入到串池中.
- 如果串池中没有该字符串对象,则放入成功
- 如果有该字符串对象,则放入失败
无论放入是否成功,都会返回串池中的字符串对象
注意:此时如果调用intern方法成功,堆内存与串池中的字符串对象是同一个对象;如果失败,则不是同一个对象。
public class Main {
public static void main(String[] args) {
//"a" "b" 被放入串池中,str则存在于堆内存之中
String str = new String("a") + new String("b");
//调用str的intern方法,这时串池中没有"ab",则会将该字符串对象放入到串池中,此时堆内存与串池中的"ab"是同一个对象
String st2 = str.intern();
//给str3赋值,因为此时串池中已有"ab",则直接将串池中的内容返回
String str3 = "ab";
//因为堆内存与串池中的"ab"是同一个对象,所以以下两条语句打印的都为true
System.out.println(str == st2);
System.out.println(str == str3);
}
}
public class Main {
public static void main(String[] args) {
//此处创建字符串对象"ab",因为串池中还没有"ab",所以将其放入串池中
String str3 = "ab";
//"a" "b" 被放入串池中,str则存在于堆内存之中
String str = new String("a") + new String("b");
//此时因为在创建str3时,"ab"已存在与串池中,所以放入失败,但是会返回串池中的"ab"
String str2 = str.intern();
//false
System.out.println(str == str2);
//false
System.out.println(str == str3);
//true
System.out.println(str2 == str3);
}
}
intern方法 1.6 :
调用字符串对象的intern方法,会将该字符串对象尝试放入到串池中:
- 如果串池中没有该字符串对象,会将该字符串对象复制一份,再放入到串池中
- 如果有该字符串对象,则放入失败
无论放入是否成功,都会返回串池中的字符串对象。
注意:此时无论调用intern方法成功与否,串池中的字符串对象和堆内存中的字符串对象都不是同一个对象
34. string_table 面试题
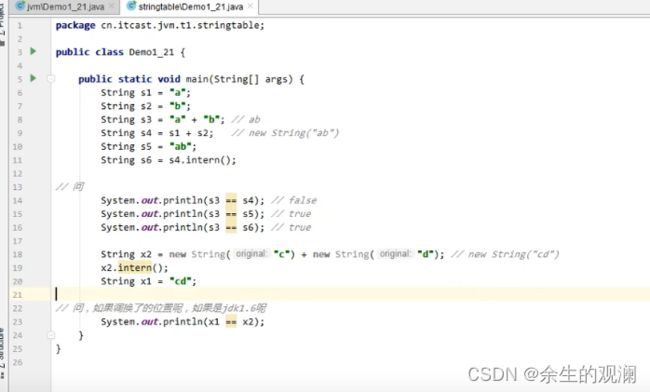
19与20行调换位置之前: 最后的答案是true,因为jdk1.8中,x2会从堆中也把同一对象放到串池中,所以x1=“cd”,直接从串池拿的对象。
19与20行调换位置之后:false,x1的“cd”来自于串池,是新建的,x2来自于堆,把x2放入串池的操作,实际晚了一步。
jdk1.6,调换位置之前:false,因为1.6会从堆中复制一个对象去串池,实际上两个对象不同。
jdk1.6,调换位置之后:false,一个是堆中的,一个是串池的,2个对象不同。intern没起到作用。
35-36. string_table 位置

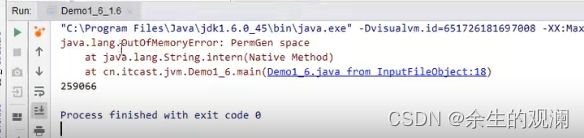
1.6 :string table 是常量池的一部分,跟常量池一起存在永久代中,永久代的内存回收效率很低,只有在full gc的时候才会触发垃圾回收机制,full gc只在老年代空间不足时候才会触发,触发的时机不对,但是stringtable用的是十分频繁的,这种垃圾回收频显然不行。1.7之后,stringtable就转移到了堆中,年轻代的垃圾回收机制很频繁,所以性能好。验证程序如下:

1.6版本报错:
1.8版本报错:并没有出现heap关键词
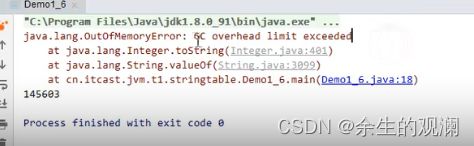

jvm原文:如果百分之98的时间用来垃圾回收,就说明癌症晚期。就会报上面的错,也说明堆空间不足了。
如果把这个功能 -XX:-xxxx,就可以出现堆内存溢出了。

37. string_table 垃圾回收
stringtable在堆中,虽然是字符串常量,那么也得被垃圾回收。
将jvm做如下设置:

Xmx:规定堆内存的大小
-XX:+pringtStringTableStatistics 答应串池的统计信息
后面两个参数:打印垃圾回收的相关信息
运行一段代码,代码没有做任何事情。

打印内容如下:
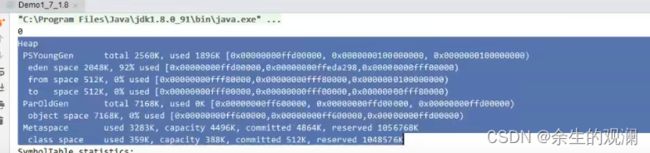
上述是堆的信息:新生代,老年代,元空间分别的大小喝使用情况。

符号统计:类的字节码里那些类名、方法名、变量名,也是需要读入到内存中,以查表的方式去读出来。也是属于常量池的一部分。

stringtable的统计信息:底层的实现是hashtable,是数组+链表的结构。
主要看前三个number,number of literal 是说明的字符串常量的统计。因为jvm中本身是有很多字符串常量的。
这时候,main函数中增加字符串常量往串池中intern的操作。

运行结果如下:增加了100个对象

如果增加的常量变成1w个,那么10m的堆空间肯定不够,就会触发gc了。
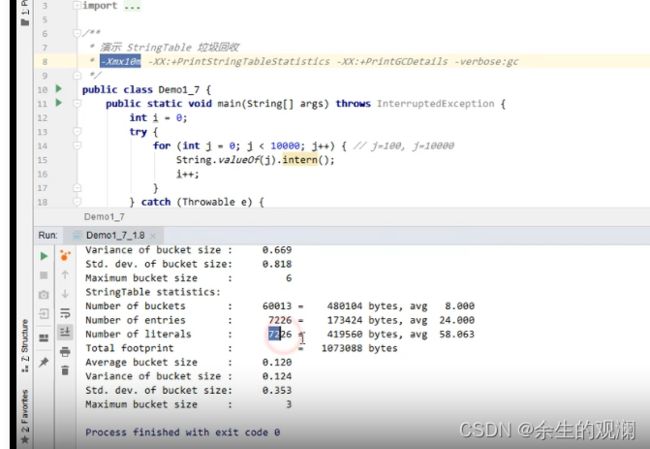
实际上只存进去7000多(含有本身的1754)。过程中肯定因为内存分配失败触发了gc。无用的字符串常量被清掉了。

38-40. string_table 性能调优
stringtable底层是一个hash表,性能跟他的大小相关。
tips:垃圾回收只有在内存紧张时才会触发。

文件中有50w行关键字数据。流读入之后,放入串池。
首先,进行jvm的参数设置,

进行入池:0.4秒,速度是非常快的。


然后把stringtablesize 这个配置去掉,性能明显降低了。这个参数是调节默认桶大小的,大了,性能会高。

建议:如果你的系统中字符串常量很多,建议调大stringtablesize,必须大于1009,默认是60000.减少has冲突,提升效率。
调优:对于地址等信息,拆分省市县区和具体地址,然后用串池的方法载入到内容,比一次性全部载入要节省空间。
demo实验,证明调优:
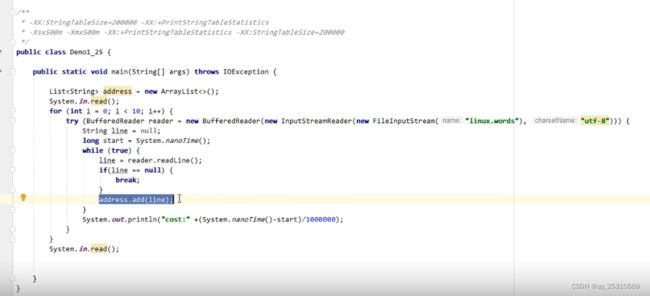
不加line.intern():
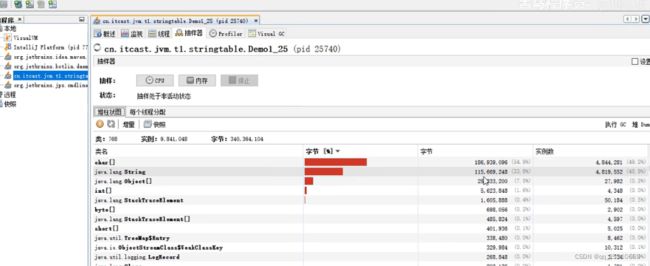
加line.intern(): 会发现string和char明显的掉下来了。
