element中有多个合计_一文弄清Python网络爬虫解析库!内含多个实例讲解
在了解爬虫基础、请求库和正则匹配库以及一个具体豆瓣电影爬虫实例之后,可能大家还对超长的正则表达式记忆犹新,设想如果想要匹配的条目更加多那表达式长度将会更加恐怖,这显然不是我们想要的,因此本文介绍的解析库可以帮助我们更加轻松地提取到特定信息。

一、Xpath库
1.库简介
XPath(XML Path Language)即XML 路径语言,它是一门在XML文档中查找信息的语言,但它同样适用于HTML 文档的搜索。所以在做爬虫时,我们完全可以使用XPath 来做相应的信息抽取。
2.入门测试
需要导入lxml库(若未安装推荐用pip install lxml安装即可),然后使用下面代码进行简单测试:
from lxml import etreetext = ''' first second third fourth
'''html = etree.HTML(text)result = etree.tostring(html)print(result.decode('utf-8'))
结果如下:可以看到,etree模块不仅将缺少的标签闭合了,而且还加上了html、body节点。
first second third fourth
3.基本方法
xpath的常用规则及基本方法如下:
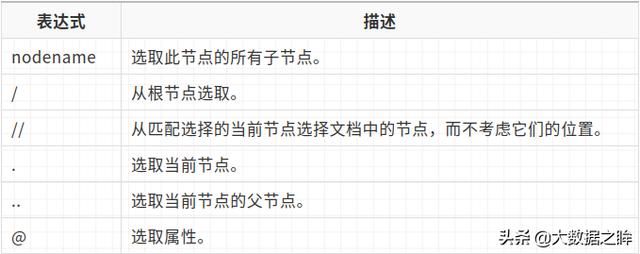
- 初始化html
上文中的入门测试即为初始化html。其中etree.parse()是初始化html构造一个XPath解析对象;etree.tostring()是修复html文件中代码,把缺的头或尾节点补齐;result.deode('utf-8')修复后的HTML代码是字节类型,转化成字符串。
- 获取所有节点
print(html.xpath('//*')) # 获取所有的节点print(html.xpath('//li')) # 获取所有li节点- 子节点、子孙节点
print(html.xpath('//li/a')) # 所有li下是所有直接a子节点print(html.xpath('//ul//a')) # 所有ul下的子孙a节点- 父节点
# 找到所有a节点中href为links.html的父节点的class值# .. 来实现查找父节点print(html.xpath('//a[@href="link1.html"]/../@class'))- 属性匹配
# 找到class值为item-0是节点print(html.xpath('//li[@class="item-0"]'))- 文本获取
# 匹配到class值为item-0节点中的a标签中的文本print(html.xpath('//li[@class="item-0"]/a/text()'))- 属性获取
print(html.xpath('//li/a/@href')) # 找到li下a中的href属性值- 属性多值匹配
#只要节点属性class中包含item就能匹配出来print(html.xpath('//li[contains(@class,"item")]/a/text()'))
二、BeautifulSoup库
1.库简介
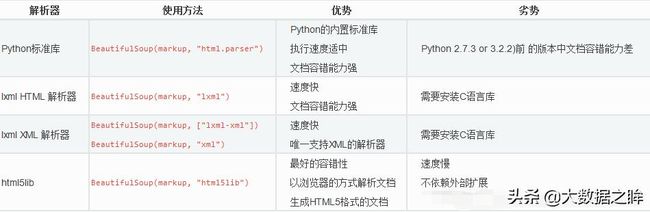
BeautifulSoup4和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐使用lxml 解析器。
2.入门测试
假设有这样一个Html(即从百度网页源代码截取一段),具体内容如下:
html = ''' 百度一下,你就知道
新闻 hao123 地图 视频 贴吧 更多产品
'''
如果将字符串单独保存为html文件,则使用谷歌浏览器打开后即为:

通过导入bs4库中的BeautifulSoup子类可以输入以下命令观察输出:
from bs4 import BeautifulSoup bs = BeautifulSoup(html,"html.parser") # 缩进格式print(bs.prettify()) # 获取title标签的所有内容 print(bs.title) # 获取title标签的名称print(bs.title.name) # 获取title标签的文本内容print(bs.title.string) # 获取head标签的所有内容print(bs.head) # 获取第一个div标签中的所有内容print(bs.div) # 获取第一个div标签的id的值print(bs.div["id"]) # 获取第一个a标签中的所有内容print(bs.a) # 获取所有的a标签中的所有内容print(bs.find_all("a")) # 获取id="u1"print(bs.find(id="u1")) # 获取所有的a标签,并遍历打印a标签中的href的值for item in bs.find_all("a"): print(item.get("href")) # 获取所有的a标签,并遍历打印a标签的文本值for item in bs.find_all("a"): print(item.get_text())3.基本方法
BeautifulSoup4将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
- Tag:Tag通俗点讲就是HTML中的一个个标签,我们可以利用 soup 加标签名轻松地获取这些标签的内容,这些对象的类型是bs4.element.Tag。但是注意,它查找的是在所有内容中的第一个符合要求的标签。
# [document] #bs 对象本身比较特殊,它的 name 即为 [document]print(bs.name) # head #对于其他内部标签,输出的值便为标签本身的名称print(bs.head.name) # 在这里,我们把 a 标签的所有属性打印输出了出来,得到的类型是一个字典。print(bs.a.attrs) #还可以利用get方法,传入属性的名称,二者是等价的print(bs.a['class']) # 等价 bs.a.get('class')# 可以对这些属性和内容等等进行修改bs.a['class'] = "newClass"print(bs.a) # 还可以对这个属性进行删除del bs.a['class'] print(bs.a)- NavigableString:既然我们已经得到了标签的内容,那么问题来了,我们要想获取标签内部的文字怎么办呢?很简单,用 .string 即可,例如:
print(bs.title.string) print(type(bs.title.string))- BeautifulSoup:BeautifulSoup对象表示的是一个文档的内容。大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag,我们可以分别获取它的类型,名称,以及属性,例如:
print(type(bs.name)) print(bs.name) print(bs.attrs)- Comment:Comment 对象是一个特殊类型的 NavigableString 对象,其输出的内容不包括注释符号。
print(bs.a)# 此时不能出现空格和换行符,a标签如下:# print(bs.a.string) # 新闻print(type(bs.a.string)) # 接下来具体讲解BeautifulSoup的使用方法。我们可以通过BeautifulSoup遍历文档树:
- .contents:获取Tag的所有子节点,返回一个list
# tag的.content 属性可以将tag的子节点以列表的方式输出print(bs.head.contents)# 用列表索引来获取它的某一个元素print(bs.head.contents[1])- .children:获取Tag的所有子节点,返回一个生成器
for child in bs.body.children: print(child)- .descendants:获取Tag的所有子孙节点
- .strings:如果Tag包含多个字符串,即在子孙节点中有内容,可以用此获取,而后进行遍历
- .stripped_strings:与strings用法一致,只不过可以去除掉那些多余的空白内容
- .parent:获取Tag的父节点
- .parents:递归得到父辈元素的所有节点,返回一个生成器
- .previous_sibling:获取当前Tag的上一个节点,属性通常是字符串或空白,真实结果是当前标签与上一个标签之间的顿号和换行符
- .next_sibling:获取当前Tag的下一个节点,属性通常是字符串或空白,真是结果是当前标签与下一个标签之间的顿号与换行符
- .previous_siblings:获取当前Tag的上面所有的兄弟节点,返回一个生成器
- .next_siblings:获取当前Tag的下面所有的兄弟节点,返回一个生成器
- .previous_element:获取解析过程中上一个被解析的对象(字符串或tag),可能与previous_sibling相同,但通常是不一样的
- .next_element:获取解析过程中下一个被解析的对象(字符串或tag),可能与next_sibling相同,但通常是不一样的
- .previous_elements:返回一个生成器,可以向前访问文档的解析内容
- .next_elements:返回一个生成器,可以向后访问文档的解析内容
- .has_attr:判断Tag是否包含属性
也可以通过BeautifulSoup进行搜索文档树:
- find_all(name, attrs, recursive, text, **kwargs)
在上面的示例中我们简单介绍了find_all的使用,接下来介绍一下find_all的更多用法-过滤器。这些过滤器贯穿整个搜索API,过滤器可以被用在tag的name中,节点的属性等。
from bs4 import BeautifulSoup import re bs = BeautifulSoup(html,"html.parser") t_list = bs.find_all(re.compile("a")) for item in t_list: print(item)- find()
find()将返回符合条件的第一个Tag,有时我们只需要或一个Tag时,我们就可以用到find()方法了。当然了,也可以使用find_all()方法,传入一个limit=1,然后再取出第一个值也是可以的,不过未免繁琐。
from bs4 import BeautifulSoup import re # 返回只有一个结果的列表t_list = bs.find_all("title",limit=1) print(t_list) # 返回唯一值t = bs.find("title") print(t) # 如果没有找到,则返回Nonet = bs.find("abc") print(t)- CSS选择器
BeautifulSoup支持发部分的CSS选择器,在Tag获取BeautifulSoup对象的.select()方法中传入字符串参数,即可使用CSS选择器的语法找到Tag:
- 通过标签名查找
print(bs.select('title'))print(bs.select('a'))- 通过类名查找
print(bs.select('.mnav'))- 通过id查找
print(bs.select('#u1'))- 组合查找
print(bs.select('div .bri'))- 属性查找
print(bs.select('a[class="bri"]'))print(bs.select('a[href="http://tieba.baidu.com"]'))- 直接子标签查找
t_list = bs.select("head > title")print(t_list)- 兄弟节点标签查找
t_list = bs.select(".mnav ~ .bri")print(t_list)- 获取内容
t_list = bs.select("title")print(bs.select('title')[0].get_text())
三、pyquery库
1.库简介
如果觉得Xpath有些难懂,BeautifulSoup有些难记,那pyquery一定适合你。pyquery 可让你用 jQuery 的语法来对 xml 进行操作。这和 jQuery 十分类似。如果利用 lxml,pyquery 对 xml 和 html 的处理将更快。这个库不是一个可以和 JavaScript交互的代码库,它只是非常像 jQuery API 而已。
2.入门测试
# html为上文BeautifulSoup测试实例from pyquery import PyQuery as pqdoc = pq(html)print(doc('title').text()) # '标题'print(doc('div').filter('.head_wrapper').text()) # '文字1'print(doc('a[name=tj_trnews]').text()) # 同上,只是这种方法支持除了id和class之外的属性筛选print(doc('div').filter('#u1').find('a').text()) # '列表1第1项 列表1第2项'print(doc('div#u1 a').text()) # 简化形式print(doc('div#u1 > a').text()) # 节点之间用>连接也可以,但是加>只能查找子元素,空格子孙元素3.基本方法
- 初始化
# 字符串初始化:from pyquery import PyQuery as pqdoc=pq(html)print(doc('li'))# URL初始化doc=pq(url="https://ww.baidu.com")print(doc)a = open('test.html','r',encoding='utf8')doc=pq(a.read())print(doc)- 基本css选择器
# id 为container,class为list下的所有liprint(doc('.head_wrapper #u1 a'))- 查找节点
# .find():查找所有子孙节点items = doc('#u1')print(items.find('a'))# .children():查找子节点items=doc('#u1')print(items.children('.mnav'))# 父节点doc=pq(html)items=doc('.mnav')print(items.parent())print(items.parents())# 兄弟节点doc=pq(html)li=doc('.mnav')print(li.siblings('.bri'))- 遍历
# 用items()函数生成列表生成器进行遍历doc=pq(html)lis=doc('a').items()for li in lis: print(li)- 获取信息
# 获取属性a=doc('.head_wrapper #u1 .bri')# attr只会输出第一个a节点属性,要用items()遍历print(a.attr('href'))# 获取文本# .text()a=doc('.head_wrapper #u1 .bri')# text()函数会输出所有的li文本内容print(a.text())# .html()li=doc('a')# html()只会输出第一个li节点内的HTML文本print(li.html())- 节点操作
# removeClass addClassa=doc('.head_wrapper #u1 .bri')print(a)a.removeClass('bri') # 移除active的classprint(a)a.addClass('bri') # 增加active的classprint(a)# attr text htmla.attr('name','link') # 增加属性name=linka.text('changed item') # 改变文本 changed itema.html('changed item ') # 改变HTMLprint(a) # remove()u1=doc('#u1')# 删除wrap中p节点u1.find('a').remove()print(u1.text())Python有关Xpath、BeautifulSoup、pyquery三大解析库的基本使用方法介绍至此结束,下文开始介绍动态网页数据采集的相关库与实战,前文涉及的基础知识可参考下面链接:
爬虫所要了解的基础知识,这一篇就够了!Python网络爬虫实战系列
一文带你深入了解并学会Python爬虫库!从此数据不用愁
Python爬虫有多简单?一文带你实战豆瓣电影TOP250数据爬取!