“浅”谈容灾和双活数据中心(下)
本文接续前文:“浅”谈容灾和双活数据中心(上),上 篇发布之后,瓜哥粉丝量暴涨了好几百,感谢大家关注!
第三部分:双活,看上去很美。
3.1 装逼是要付出代价的
看这标题,想必瓜哥是要开始吐槽双活了。没错。传统灾备模式下,一主一备,灾备端冷启动或者暖启动,这种方式虽然有资源浪费和 RTO 较大等缺点,但是其最大一个优点就是保险。那么说双活不保险喽?瓜哥认为是的。世上没有无代价的交换。双活的不保险,体现在灾备端对生产端是有严重影响的,或者说双活场景下,已经没有主和备的角色分别了,是对称式的,也就是两边会相互影响。这种影响,很有可能导致两边一损俱损,多活应用的多个实例之间耦合较紧,诸如“单节点无法启动 ” 、 “ 无法加入新节点 ” 等类似耦合性问题,时有发生,带来了很大的运维复杂度,尤其是异地多实例的场景下,出现问题,你咋弄?登陆到远端机器调试,甚至需要重装、重启,有时候还不得不在异地放个人配合你,俩人水平不一样沟通或许也有问题,你就得亲自来回跑,这些想想都头疼。这就好像很多单一应用主机做了 HA 双机热备一样,结果发现本来屁事没有的单机环境,自从部署了 HA 之后,反而多了很多屁事。
双活也一样,只会增加运维难度,而不会降低。双活就得预防脑裂,而“预防脑裂”本身就可能会出各种问题,徒增成本不说,远距离链路上会发生什么谁也无法预知,一旦软件做的有问题不够健壮,反而会导致更大问题甚至脑裂,也就是根本没防止脑裂而增加脑裂概率了。还有就是一旦两边、仲裁,都失去联系,那么系统只能停机,而这种情况在传统灾备架构里是不会发生的,从这一点上说,双活的可用性概率反而是下降的,因为链路闪断、故障的几率,比整个数据中心大灾难的几率那是高多了。
传统双活,一主一备,或者至少是互备,容灾端是不会影响源端的。而双活,“备份 ” 的意思更少了一些,这与传统的观念就背离的越来越远了。双活两边各自影响,搞不好一端出问题,另一端跟着遭殃,甚至两边直接全挂掉,比如一旦某个地方不一致,或者经过链路闪断之后出现了状态机混乱,全崩。其实这个已经是有前车之鉴的了。据说某用户使用了某品牌的双活之后,出现脑裂问题,导致停机数小时,高层直接被下课。从这一点上来讲,双活既可以是个略显逼格的奇葩装备,但也有可能成为一个定时炸弹。再一个例子,支付宝光纤被挖断,愣是停业务两小时,至于其到底是否部署了双活甚至多活,谁也不知道,瓜哥也不能妄加揣测,但是至少说明一点,所谓双活,可能并没有你想象中的那么健壮,虽然它看上去很美。
3.2 另一种双活,不中看但或许很适合你
业界有几个厂商也宣称自己支持双活,但机制并不是上述那样。同样 A 和 B 两个站点, A 实例访问本地数据副本, B 实例也访问 A 站点的数据副本,而 A 存储与 B 存储之间保持复制关系,在 B 站点维护一份镜像副本,镜像副本平时不能挂起给业务主机,仅当出了问题之后,比如 A 存储宕机,镜像副本才可以挂起给业务。这些厂商的这种双活方案,各自也都包装了一套名词出来,比如 “Stretched Cluster” ,意即将本来耦合在本地的主备容灾系统拓展到异地,平时备份端的主机也可以访问源端的数据,只不过要跨广域网,数据是集中访问源端副本,不需要考虑一致性问题。出现问题需要切换时,靠主机上的多路径软件将路径切换到备份端,继续业务。
下面这个拓扑是利用虚拟化网关组成的的 Stretch Cluster 结构,两台主机运行双活应用,当 A 主机当掉之后, B 主机可以继续访问 A 站点的 A 存储,路径不变化。该厂商针对这个场景做了一些优化措施:由于 B 主机访问 A 存储是跨广域网访问时延大,此时完全可以切换到 B 站点 B 存储访问,因为 A 存储上对应的卷当前只有 B 主机一人在访问了,不会发生不一致的问题,所以 B 主机上所配备的该厂商的多路径软件此时会检查 A 存储和 B 存储的镜像状态,当发现为完全同步态之后,会将 B 的访问路径切换到 B 存储,这个切换速度较快,对 IO 影响很小,切换之后 B 对 A 反向同步。
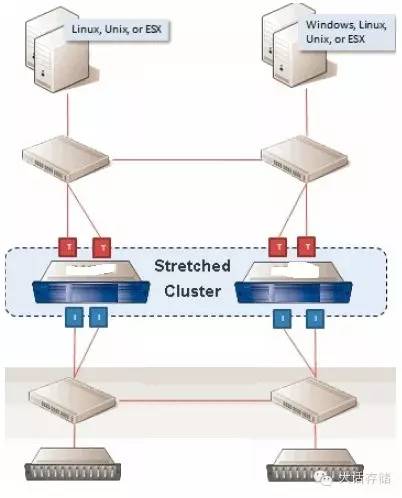
可以看到,这种双活体系,其效果接近于对称式双活,远端节点的读 IO 不能在本地完成,这一点赶不上对称式双活(当读 IO 目标地址没有被锁定时可以终结在本地),对于写 IO ,对称式双活也需要写到对端去,两者相差不太大,但是 Stretch Cluster 能避免仲裁 / 脑裂方面的风险。运维难度大大降低。
综上所述,双活与灾备的目标其实是有所背离的,他将 “ 备份 ” 这个最后保障的保险系数拉低了。从业务角度来看,传统企业的业务系统多数是由人 + 机器组成的,传统业务离不开人的接入,人没了,仅有机器,业务也跑步起来。而新兴业务尤其是互联网类业务,或者无人值守业务,人为因素介入较少,都是机器全自动化操作,只要机器活着,业务就活着。对于传统业务,一旦灾难发生,就算双活系统在对端立即处于可用状态,那么最终的操作者要切到访问对端,还得经过全面的训练演练,以及网络路径的切换,最终才能访问对端数据中心,如果是大型灾难,传统企业一般是人 + 机器处在同一位置,此时人和机器都被灾难了,对端的业务即使立即可用,也毫无意义,从这一点上来看,传统业务是否真的迫不及待需要双活,还得根据场景来考量。而对于机器自动化处理的业务系统,双活是有一定意义的。
所以,部署双活,一定要考虑清楚其到底是不是自己真正想要的东西,没那个精工钻,最好别揽瓷器活,缺乏驾驭双活的本领,就得随时承担被下课的风险,决不能为了没思考清楚的一时的风光,埋下个大坑。厂商们的 sales 和售前,都是无底限的,这一点切记,为了推广某个东西,他才不管你要的是什么或者你有多大本领来驾驭双活,很少有人会为你设身处地的着想,就算是 top sales/presales ,你所能做的,只有加强自己的功底和防忽悠能力,自己判断,才是正路。
第四部分:数据复制及一致性
4.1 存储端同步复制一定 RPO=0 ?
两个结果,业务起得来, RPO ≈ 0 ,业务起不来, RPO=RTO=∞ (无穷大),也就是再也别想起来了。为什么呢?难道连同步复制都丢数据?同步复制是可以不丢数据(其实同步复制不仅不丢数据,而且有几率可能会超前于本地站点,因为一般同步复制的实现都是先写远端,成功后在写本端,如果写完远端,远端 ack 了,结果 ack 没来得及传递到本端,链路或者本端当了,那么远端的数据反而超前于本端),但是同步复制不保证数据的一致性。说到数据一致性,需要理解 IO 路径上好几层的东西才能理解,首先应用层自己有 buffer 空间,有些东西写到这里就返回了,其次 OS 内核的 Page Cache ,如果应用打开设备 / 符号 / 文件时候没有显式指明 DirectIO ,默认也写到这里就返回了,再往下就是块层、设备驱动、 Host 驱动,但是这几层都是没有 write back 缓存的,问题不大。此时,数据并没有被刷到存储系统里,在 page cache 中留有脏数据,这些数据是没有复制到远端的,一旦系统掉电,重启就极有可能出现各种问题比如 LVM/ASM 卷挂不起来,文件系统挂不起来或者 FSCK 。可已看到,存储层的同步复制仅仅解决的是底层存储层的时序一致性问题,它能保证凡是已经下刷到存储系统里的 IO ,两边几乎是时刻一致的。但保证不了卷层、 FS 层以及应用层的一致性。
一旦卷挂不起来,或者应用起不来,很难恢复数据,这可不是数据恢复公司所能恢复的。所以,同步复制并不能保证 RPO ,需要在目标端对目标卷做多份快照,一旦发生灾难,首先尝试最新数据启动,起不来,回滚快照,再起不来,再回滚,如果都不行,那就玩完。同步复制保证两端数据几乎时刻相同,那也就意味着,灾难发生时,源端数据什么状态,灾备端的数据也是什么状态,灾难发生时,源端数据就相当于咔嚓一下子停了电,那么灾备端的数据也相当于咔嚓停了电。停电之后再启动,大家都清楚会发生什么,那就是个梦魇,一堆错误,甚者硬件都再也起不来了,重者卷挂不起来提示错误,或者数据库起不来提示数据不一致,轻者 FSCK 丢数据,所以,同步复制 + 远端快照才能降低风险。
4.2 存储端异步复制的时序一致性
再来看看异步复制如何保证数据一致性。异步复制分两种,一种是周期性异步复制,一种是连续异步复制。周期性异步复制是最常用也最简单的一种方式,在初始化同步的基础上,源端做一份快照,一段时间之后,再做一份快照,通过比对两份快照之间的数据差异,将所有差异全部传送到远端,这次差异的数据,会被分为多份小 IO 包发送到远端,只要有一份没有成功传送,那么远端就不会将这些数据真正落地到远端的卷,远端会回滚到上一个快照点,等待下次继续触发复制,这样可以保证数据的时序一致性。这样,一次差异复制的所有 IO 数据形成了一个原子 IO 组,有人又称之为 “ 一致性组 ” 。而连续异步复制是不断的向对端复制,而不是定期做快照比对差异然后批量复制。
连续异步复制又分为两种,一种是无序复制,实现起来最简单,直接在源端记录一个 bitmap ,数据直接写入源卷的同时,将对应 bitmap 中的 bit 置 1 ,后台不断读取 bitmap 中置 1 的块,读出来复制到远端,这种复制过程完全不顾 IO 发生的时序,是没有时序一致性的,远端的数据几乎是不可用的,除了早期有些厂商使用这种方式之外,现在已经没人这么干了。另一种是基于日志的有序连续复制,就是在源端,更新 IO 除了写入源卷之外,还会被复制一份写入到一个 RAM 里的 buffer 区域或者磁盘上的日志空间,按照顺序把所有更新操作 IO 数据记录下来,形成一个 FIFO 日志链,然后不断的从队首提取出 IO 复制到远端,当遇到链路阻塞或者闪断的时候,如果系统压力很大,则 buffer 或者日志空间可能会被迅速充满,此时不得不借助 bitmap 来缓解对空间的消耗,也就是转成第一种模式,当链路恢复时,远端和源端将打一个快照,然后确保要将所有未被复制过去的数据全部复制过去,才能达到同步状态,然后恢复第二种模式的连续赋值过程,因为 bitmap 中是不记录 IO 时序的。
4.3 另一种概念的“一致性组”
源端的多个 Lun 之间可能是存在关联关系的,典型的比如数据库的 online redo log 卷和数据卷,这两个 / 组卷之间,就是有先后时序关联性的,数据库 commit 的时候,一定是先写入 online 日志,然后实体数据在后台异步的刷入到数据卷。对于异步复制来说,不但要保证单个卷写 IO 的复制时序,还必须保证多个卷之间的时序不能错乱,比如基于快照的周期异步复制场景,存储系统必须保证这多个 Lun 在同一个时刻做快照,所有已经应答的写 IO ,都必须纳入这份快照中,将多个 Lun 一刀切平,同时每次触发复制,必须将这多个 Lun 的差异都复制过去,才可以保证多个 Lun 之间的时序一致性,出了一点差错,则远端这多个 Lun 统一回滚到上一个快照一致点。这多个 Lun ,组成了一个 “ 一致性组 ” ,这是目前 “ 一致性组 ” 的通用理解。
4.4 专业容灾厂商如何解决数据一致性问题
如上所说,在存储系统层进行复制,无法保证数据的应用层一致性,究其原因是系统 IO 路径上的缓存未下刷导致。所以一些专业点的存储厂商就开发了应用 Agent ,装在应用主机上,在做快照之前, Agent 会将应用至于特殊状态,然后通知阵列做快照,完成后再将应用置回正常状态,这样做出来的快照是一致的。举例来讲,数据库应用,有一种特殊的运行状态叫做 “backup mode” ,当要对数据库做备份的时候,要将对应的数据文件拷贝出来而且还不能影响在线业务,数据一边往数据文件中写入,一边还得拷贝出文件来,此时如果不加处理,拷出来的文件就是新旧数据交织在一起的一份不一致数据,而如果将数据置于 “backup mode” 的时候,数据库会在数据文件中将当前的 SCN 锁住不再更新,同时在 redo 日志中记录标记,后续的所有更新操作依然更新到数据文件中,但是同时会保留在 redo 日志中,数据 checkpoint SCN 被锁住,但是 hot backup SCN 依然不断更新。此时,备份出来的文件自身虽然是不一致的,但是加上 redo 日志之后,这份数据就是可以恢复而且一致的,在恢复之后,数据库会将 redo 日志中自从 hot backup 开始之后的所有更新重新 redo 到数据文件中并将 checkpoint SCN 与 hot backup SCN 追到一致。
各种快照 Agent for Oracle ,就是利用了个这么简单的原理, alter database begin backup ,无非就是执行这样一条命令而已,这条命令除了会将数据库置于 backup mode 之外,还会主动出发一次 checkpoint ,意味着其会调用 sync 接口将数据库应用层 buffer 内脏数据刷入底层存储,然后这条命令才会执行返回。 Agent 调用了这条命令返回之后,通知阵列对数据卷和日志卷同时做快照(基于一致性组保障),做出来的快照就可以保证一致性,所以,这种场景下,必须是数据 + 日志才能保证一致性,数据文件本身不具有一致性。对于基于快照差异复制的异步复制,也要使用这种方式来做快照。快照做完之后, Agent 再解除数据库的 backup mode ,数据库便会自动重做 redo 日志来将数据文件追赶到最新状态。所以,快照代理并不是多数人认为的 “hang 住 io” , hang 不住的,没有这种接口让你去 hang 住 io 的。
然而,看上去再保险的做法,有时候也不保险,多少数据库、文件系统号称保证一致性,掉电不 fsck 等等,现实中呢,掉电崩溃的概率其实依然比较高, IO 路径上的所有模块必须都做到强一致性,包括实现端到端的 DIF ,才有可能真的实现绝对一致性,可惜目前这只是幻想。某个部件宣称自己能保证强一致性,也白搭,最简单的例子, LVM 在一致性方面做得就欠火候,不管 linux 还是 unix ,突然拔电, lvm 首先就有很大概率不一致,重则卷都认不到了,如果数据库部署在 lvm 卷之上,本身做得在可靠也是白搭。那咋个整法?
有些看似野路子但是却很有效的方法。举个例子,如果系统可以在主机 IO 压力为 0 或者非常低的时候来做快照,那么就会有更大几率来保证一致性,主机 IO 压力为 0 ,要么证明缓存里几乎没有脏数据,要么就是位于两次 checkpoint 之间,此时做快照一致性保障几率增高。说到这里冬瓜哥不得不贴个图了,下图是飞康 CDP (连续数据保护)产品配置时的一幅图样,这张图是让用户在 CDP 录像日志中选择需要提取的历史时间点,图中明确给出了每个历史时刻的 IO 压力统计,以协助用户选择那些压力小的时间点用于回滚。
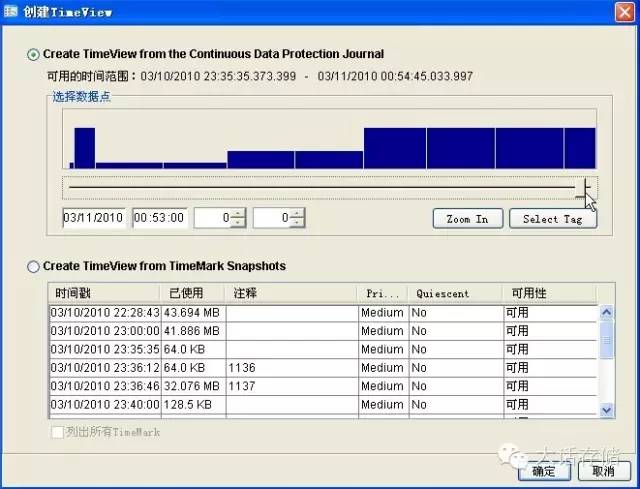
点击 zoom in 按钮之后,可以放大到该时刻附近 5 分钟内的 IO 压力图式窗口(还可以继续 zoom in ),在窗口中看到,这 5 分钟内系统发生了两波 IO 压力,比如可能是分两次写入了两个大文件,选择 IO 压力为 0 的时间点,点击确定,系统便会生成一份该历史时刻的快照卷,可以挂起给主机用于数据恢复或者回滚。
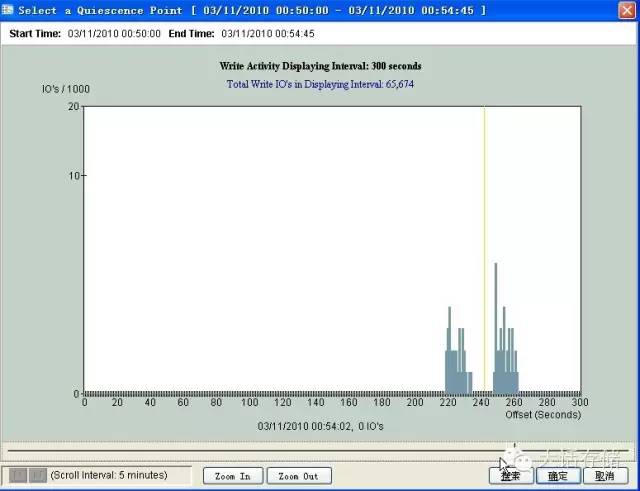
可以在第一张图上看到另外一个按钮叫做 ”Select Tag“ ,这个也是为了增加数据一致性的几率而设置的,用户可以在任意时刻,通知 CDP 系统在日志中生成一个标签,并为此标签任意取名,比如,某时刻用户做了一次手动 sync ( sync 命令) ,或者手动触发一次 checkpoint ,或者拷贝完某重要文件并 sync ,此时用户可以手动通知 CDP 系统 ” 帮我记录一下这个时间点 “ ,后续回滚的时候,在界面中使用 ”Select Tag“ 按钮弹出的 tag 列表便可以明确知道某历史时刻发生过什么事情,自己要回滚到哪个时间点处。飞康这个设计里除了使用传统快照 Agent 之外,还提供了系统 IO 压力参考、用户手工标签参考这两种方式来一定程度上提升数据一致性的概率。
4.5 应用层复制,强有力的一致性保障
数据库日志级的复制,可以从源头上保障数据的一致性。底层存储端实现复制,有它的通用性,但是数据不一致是个很大问题。应用层直接发两份 IO 或者事务给本地和远端,两边分别执行这次事务,产生的 IO 从源头上自上而下执行,是不会有一致性问题的。比如 Dataguard , GoldenGate 等等。
双活状态下,一样要以保证数据一致性为前提,双活不意味着数据一致,所以,灾备端一样要保留好多份快照以备不时之需。
第五部分:业务容灾
不谈业务的容灾都是耍流氓,这种流氓气尤其在当前的传统存储厂商里尤为严重。几大存储厂商的 ppt 里,无时无刻不再吹嘘各种复制技术,有些还搞了多个亚版本什么这个 mirror ,那个 copy 的,在冬瓜哥看来,全是鬼扯。这些 ppt 里丝毫没有提及一件事,那就是容灾来容灾去,业务到底能不能启动?这些 ppt 仿佛给人一种错觉,那就是只要数据复制过去了,容灾就高枕无忧了。容灾最关键的一步,其实是如何将业务在灾备端启动起来而且能提供服务。在数据一致性的前提下,业务容灾考虑的是如下几个方面:
5.1 业务耦合关系的梳理
传统的 HA 双机暖切换,只是个把应用,没什么大问题。但是,如果整个数据中心里的所有业务都要切换到灾备中心的话,这就是个大问题了。哦?难道不是直接在灾备中心啪啪啪(接连打开所有应用服务器开关,其实现在都是远程开机了。。)就行了么?大错特错。多个业务之间是有耦合关系的,很简单,和硬件一样,先起网络也就是交换机,再起存储系统,最后起主机,为什么?因为先得把路铺好,然后把地基打好,然后楼房才能起来,如果主机先启动,结果认不到存储,就会出问题,主机和存储起来,网络不通,主机照样认不到存储。业务之间,也是这种关系,中间件先起,包括 MQ 之类,这是业务之间的通路,然后再按照依赖关系,被依赖的一定要先启动。如果依赖别人的业务先启动,也不是不可以,比如,这个业务有可能会不断尝试连接被依赖的业务,如果这个业务程序有足够的健壮性,那么是没问题的,但是谁知道哪个业务有当初是外包给谁写的?不排除某些没有底限的外包公司比如某软之流,什么人都敢用的那种,给你弄几个坑进去,比如重连一千次内存溢出了,重启应用起得来算你走运,如果一旦由于这次崩溃,导致该业务关键元数据遭到破坏,再也起不来了,得重装应用,那就等着哭吧。尤其是对于金融、电商这种业务繁多,关系复杂的业务系统,梳理业务关系成了容灾规划中最重要的一环。
5.2 演练和切换
所谓容灾演练,有两种模式,一种是假练,一种是真练。前者就是对灾备端镜像卷做一份快照,然后把快照挂给主机,启动主机,看看业务能不能在这份快照上起得起来,起得来,演练结束。真练也分多种,比如其中一种是把源端业务停掉,然后底层对应 Lun 的复制关系做计划性切换,从备份站点,然后从备份站点启动业务主机,客户端连接灾备站点的业务主机,业务跑得起来,则演练成功,这是完全计划性的;还有一种是真拔光纤,包括前端客户端连接业务主机所用的光纤和存储之间复制所使用的光纤,远端主动探测故障发生,然后将 Lun 复制关系分裂开,远端启动主机考察能否启动。真练一般人没敢练的,因为绝对会影响业务,在业务繁忙时期,谁想真练,那是需要极大勇气的,得抱着必死的决心。因为当你决定切换复制关系之后,就已经没有退路了,这期间,一旦切换出现什么问题导致两端状态机错乱,或者卡在中间卡死,进退两难,那就哭吧。就算切过去,还有下一道考验,也就是起业务,就算业务都起来了,还有下一道考验,客户端成功重定向到新的业务服务器地址,最终业务跑起来。还有,演练完了你还得回切,又来一遍。这些动作,真不敢在白天业务忙的时候搞,要搞也是夜深人静跑完批量清算之后。
正因如此,真的发生故障之后,很少有人敢真的切到灾备中心去,都是尽力尝试把本地问题解决,重新在本地启动业务,宁肯拖半天或者一天。
5.3 半自动化业务容灾辅助工具
容灾真是个头疼的话题,灾难发生之后,流程最为重要,先干什么,后干什么,要将所有的东西串起来。当然,几乎所有案例都表明,灾难发生后,能在本地把问题解决的,宁愿等待,但是如果真的是极大的灾难,不得不切换的时候,这时候就真的靠平时演练时候获取的经验了。一般来讲,容灾管理人员会制作一张详尽的流程图和表,来规范切换步骤。然而,对于一个拥有复杂业务数量和关系的系统,在灾备端启动起来,挑战较大的就是必须得按照步骤来,靠人工极容易出错,尤其是在执行一些繁琐重复的步骤的时候,此时,如果能够有某种工具来辅助人们完成这个任务,就比较理想了。然而,在容灾体系里,机器只能起到辅助作用,如果让机器来实现全自动化容灾切换,这只能是个幻想,技术上可以做到,但是风险极大,除非你只有一个应用,做个双机 HA ,完全可以全自动化,对于复杂的耦合业务,是不敢交给机器来做全自动切换的,因为一旦出现不可预知问题,你连此时的状态卡在哪一步可能都不知道,就会处于进退两难的境地。
半自动化容灾辅助工具,其相当于先将底层一些太过繁琐的动作,封装起来,比如 “ 切换复制关系 ” ,这个动作,可能对应底层存储系统的多项检查和配置。这些过程,完全可以靠机器来辅助实现,并且将封装之后的对象、流程,展现在界面里,发生问题的时候,靠人工手动的从界面中来控制将哪些资源、按照什么顺序、切换到哪里去。对于一些大型金融、电力等企业,其容灾管理工具都是定制的。而市面上也鲜有通用场景下的商用的容灾管理工具,早期的一些双机 HA 管理工具也可以算是一种最原始的容灾工具,但其产品设计出发点仍然是少数主机少数应用的局部切换管理。目前搞范围较大的容灾管理工具的厂商比较少,因为这牵扯到太多因素。
H3C 之前有个容灾管理的产品,但是却太过注重流程步骤本土化管理方面的辅助,而在技术上没有下什么功夫。飞康有个产品叫做 RecoverTrac ,则是在技术上狠下了功夫,而流程步骤的管控上则欠缺。 RecoverTrac 是个套件,其中包含不少组件,其支持 V2P , P2V , V2V , P2P 四种本地恢复方式,以及可以配合飞康自身的 NSS/CDP 产品实现异地容灾管理,并且支持 VMware 和 Hyper-V 虚拟化环境容灾和物理机容灾融合管理。 RecoverTrac 做容灾管理的主要思路就是先把所有的东西描述成对象,比如,所有参与容灾的物理机、虚拟机、存储系统、逻辑卷资源、虚拟机资源等,都统一在管理界面中被创建为对象,然后创建容灾任务,任务中会把对应的对象包含进来,用任务来管理在什么时间,把什么对象,做什么样的操作,比如,当发生何种灾难时,把哪个或者哪几个卷挂给哪个或者哪几个主机,然后在对端起哪台或者哪几台机器,按照什么顺序启动,物理机还是虚拟机,等等诸如此类的策略。 RecoverTrac 支持 IPMI , HP 的 iLO 等远程管理协议,可以直接无人值守启动物理机。
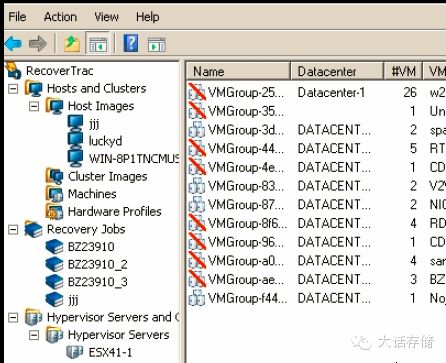
可以看到,在配置 Failover 机的时候,可以设置该主机拖延多长时间启动,以应对对业务启动顺序有严格要求的场景。
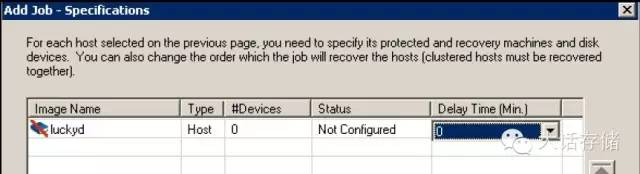
RecoverTrac在容灾的技术层面做得非常细致,其中很多更强大的功能冬瓜哥很多也不甚了解,还有待发掘。
好了,冬瓜哥在此啰嗦了一大堆,不知道大家看了是否有帮助,觉得好请点赞!
本文转载请注明出自 “ 大话存储 ” 公众号。长按识别二维码关注 “ 大话存储 ” 获取业界最高逼格的存储知识。 这篇文章如果你看到这里都不给瓜哥点小费的话,是不是有点说不过去了?平时群里发红包装逼,不如把红包猛烈的砸向冬瓜哥吧!三块五块不嫌少,三十五十不嫌多。冬瓜哥后续会有更多高逼格的东西出炉。大话存储,只出精品。


强赠冬瓜哥真容:
