Cannot allocate memory问题
-bash: fork: Cannot allocate memory问题,进程数满了的解决办法
今天一大早来到公司就发现一台远程服务器的进程满了,无法连接上远程服务器,如下图所示:
![]()
出现这种情况,主要是因为进程跑满了,memory被消耗光了,无法为其他的操作,包括vnc操作命令和SSH连接分配内存,我们可以用两个办法:
1、init 6(重启服务器,注意,不是重启tomcat)
大家都知道,死机了就重启开机嘛,要是不行init 6 不行在使用reboot强制重启(可能需要多敲几次)
第一种比较粗暴,通常情况下我们选择第二种:
2、
free:通过free命令查看内存剩余可用情况(这个命令可能需要多敲几遍)
命令可带参数:
-b 以Byte为单位显示内存使用情况。
-k 以KB为单位显示内存使用情况。
-m 以MB为单位显示内存使用情况。
-g 以GB为单位显示内存使用情况。
-o 不显示缓冲区调节列。
-s<间隔秒数> 持续观察内存使用状况。
-t 显示内存总和列。
-V 显示版本信息。

页面显示参数解释:
total:总计物理内存的大小。
used:已使用多大。
free:可用有多少。
Shared:多个进程共享的内存总额。
Buffers/cached:磁盘缓存的大小
Swap:交换分区(虚拟内存)情况;Mem:实际内存的使用情况
sysctl kernel.pid_max:查看最大进程数
![]()
主要是查看pid_max指标的,pid_max是Linux内核用来限制进程数的一个最大指标,换言之,即最大允许进程这个多,超过了服务器就挂了
ps -eLf | wc -l:查看本服务器进程数
![]()
一般出现 -bash: fork: Cannot allocate memory 本机的进程数应该接近或等于pid_max指标值的,此处我已经重启服务器解决了这个问题,所以显示进程数较少
当我们确认是因为进程数满了导致服务器挂了,我们可以
echo 1000000 > /proc/sys/kernel/pid_max:修改pid_max值为1000000
echo "kernel.pid_max=1000000 " >> /etc/sysctl.confsysctl -p:设置永久生效
这样就可以了,保险起见 然后找到占用空间最大的进程,把它干掉就解决了
top:展示进程视图,监控服务器进程数值默认进入top时,各进程是按照CPU的占用量来排序的

第一行:
10:01:23 — 当前系统时间
126 days, 14:29 — 系统已经运行了126天14小时29分钟(在这期间没有重启过)
2 users — 当前有2个用户登录系统
load average: 1.15, 1.42, 1.44 — load average后面的三个数分别是1分钟、5分钟、15分钟的负载情况
load average数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了。
第二行:
Tasks — 任务(进程),系统现在共有183个进程,其中处于运行中的有1个,182个在休眠(sleep),stoped状态的有0个,zombie状态(僵尸)的有0个。
第三行:cpu状态
6.7% us — 用户空间占用CPU的百分比。
0.4% sy — 内核空间占用CPU的百分比。
0.0% ni — 改变过优先级的进程占用CPU的百分比
92.9% id — 空闲CPU百分比
0.0% wa — IO等待占用CPU的百分比
0.0% hi — 硬中断(Hardware IRQ)占用CPU的百分比
0.0% si — 软中断(Software Interrupts)占用CPU的百分比
在这里CPU的使用比率和windows概念不同,如果你不理解用户空间和内核空间,需要充充电了。
第四行:内存状态
8306544k total — 物理内存总量(8GB)
7775876k used — 使用中的内存总量(7.7GB)
530668k free — 空闲内存总量(530M)
79236k buffers — 缓存的内存量 (79M)
第五行:swap交换分区
2031608k total — 交换区总量(2GB)
2556k used — 使用的交换区总量(2.5M)
2029052k free — 空闲交换区总量(2GB)
4231276k cached — 缓冲的交换区总量(4GB)
第六行以下:各进程(任务)的状态监控
PID — 进程id
USER — 进程所有者
PR — 进程优先级
NI — nice值。负值表示高优先级,正值表示低优先级
VIRT — 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RES
RES — 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATA
SHR — 共享内存大小,单位kb
S — 进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
%CPU — 上次更新到现在的CPU时间占用百分比
%MEM — 进程使用的物理内存百分比
TIME+ — 进程使用的CPU时间总计,单位1/100秒
COMMAND — 进程名称(命令名/命令行)
扩展:top命令的多U多核CPU监控
1、在top基本视图中,按键盘数字“1”,可监控每个逻辑CPU的状况:
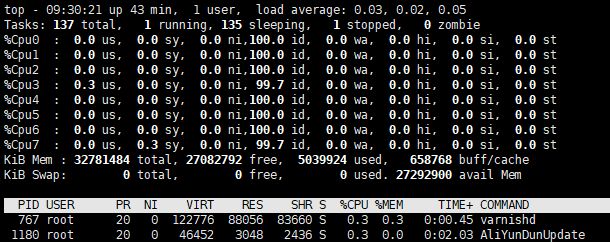
2、敲击键盘“b”(打开/关闭加亮效果),top的视图变化如下

3. 敲击键盘“x”(打开/关闭排序列的加亮效果),top的视图变化如下:
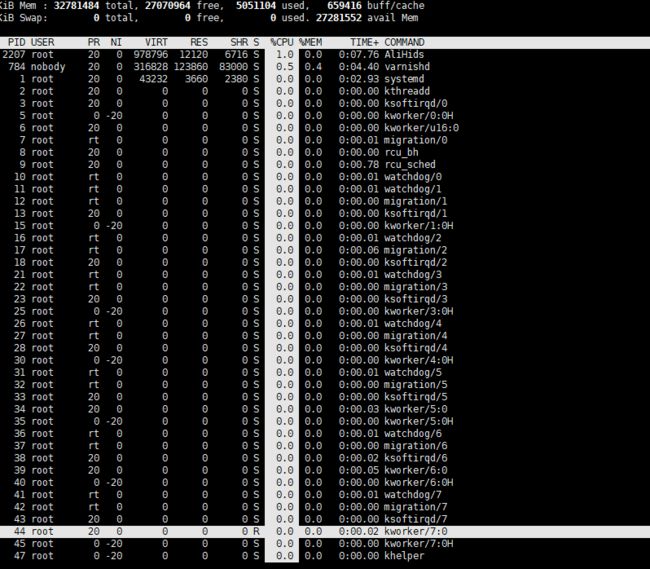
4、如果要在基本视图中显示“CODE”和“DATA”两个字段,可以通过敲击“r”和“s”键:
top命令的补充:
监控java线程数:
ps -eLf | grep java | wc -l
![]()
监控网络客户连接数:
netstat -n | grep tcp | grep 侦听端口 | wc -l
![]()
pmap PID
大家都熟悉Linux下可以通过top命令来查看所有进程的内存,CPU等信息。除此之外,还有其他一些命令,可以得到更详细的信息,例如进程相关
cat /proc/your_PID/status
通过top或ps -ef | grep '进程名' 得到进程的PID。该命令可以提供进程状态、文件句柄数、内存使用情况等信息。
内存相关
vmstat -s -S M
该可以查看包含内存每个项目的报告,通过-S M或-S k可以指定查看的单位,默认为kb。结合watch命令就可以看到动态变化的报告了。
也可用 cat /proc/meminfo
要看cpu的配置信息可用
cat /proc/cpuinfo
它能显示诸如CPU核心数,时钟频率、CPU型号等信息。
要查看cpu波动情况的,尤其是多核机器上,可使用
mpstat -P ALL 10
该命令可间隔10秒钟采样一次CPU的使用情况,每个核的情况都会显示出来,例如,每个核的idle情况等。
只需查看均值的,可用
iostat -c
IO相关
iostat -P ALL
该命令可查看所有设备使用率、读写字节数等信息。
Linux查看物理CPU个数、核数、逻辑CPU个数
# 总核数 = 物理CPU个数 X 每颗物理CPU的核数
# 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数
# 查看物理CPU个数
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
# 查看每个物理CPU中core的个数(即核数)
cat /proc/cpuinfo| grep "cpu cores"| uniq
# 查看逻辑CPU的个数
cat /proc/cpuinfo| grep "processor"| wc -l
查看CPU信息(型号)
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c